컴퓨터에 Jupyter Notebook을 설치하고 HDInsight에서 Apache Spark에 연결
이 문서에서는 Spark Magic을 사용하여 사용자 지정 PySpark(Python용) 및 Apache Spark(Scala용) 커널로 Jupyter Notebook을 설치하는 방법을 알아봅니다. 그런 다음, 노트북을 HDInsight 클러스터에 연결합니다.
Jupyter를 설치하고 HDInsight에서 Apache Spark에 연결하는 4가지 주요 단계가 있습니다.
- Spark 클러스터를 구성합니다.
- Jupyter Notebook을 설치합니다.
- Spark Magic과 함께 PySpark 및 Spark 커널을 설치합니다.
- HDInsight에서 Spark 클러스터에 액세스하도록 Spark Magic을 구성합니다.
사용자 지정 커널 및 Spark Magic에 대한 자세한 내용은 HDInsight의 Apache Spark Linux 클러스터에서 Jupyter Notebook에 사용할 수 있는 커널을 참조하세요.
필수 조건
HDInsight의 Apache Spark. 자세한 내용은 Azure HDInsight에서 Apache Spark 클러스터 만들기를 참조하세요. 로컬 노트북은 HDInsight 클러스터에 연결합니다.
HDInsight의 Spark에서 Jupyter Notebook을 사용하는 방법 이해.
컴퓨터에 Jupyter Notebook 설치
Jupyter Notebook을 설치하려면 먼저 Python을 설치합니다. Anaconda 배포는 Python 및 Jupyter Notebook를 모두 설치합니다.
사용하는 플랫폼용 Anaconda 설치 관리자 를 다운로드하고 설치 프로그램을 실행합니다. 설치 마법사를 실행하는 동안 PATH 변수에 Anaconda를 추가하는 옵션을 선택해야 합니다. Anaconda를 사용하여 Jupyter 설치도 참조하세요.
Spark Magic 설치
pip install sparkmagic==0.13.1명령을 입력하여 HDInsight 클러스터 버전 3.6 및 4.0용 Spark Magic을 설치합니다. sparkmagic 설명서도 참조하세요.다음 명령을 실행하여
ipywidgets가 제대로 설치되었는지 확인합니다.jupyter nbextension enable --py --sys-prefix widgetsnbextension
PySpark 및 Spark 커널 설치
다음 명령을 입력하여
sparkmagic이 설치되는 위치를 식별합니다.pip show sparkmagic그런 다음, 작업 디렉터리를 위의 명령으로 식별된 위치로 변경합니다.
새 작업 디렉터리에서 원하는 커널을 설치하려면 아래 명령 중 하나 이상 입력합니다.
커널 명령 Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel선택 사항. 서버 확장을 사용하려면 아래 명령을 입력합니다.
jupyter serverextension enable --py sparkmagic
HDInsight Spark 클러스터에 연결하도록 Spark Magic 구성
이 섹션에서는 이전에 설치한 Spark Magic이 Apache Spark 클러스터에 연결되도록 구성합니다.
다음 명령을 사용하여 Python 셸을 시작합니다.
pythonJupyter 구성 정보는 일반적으로 사용자 홈 디렉터리에 저장됩니다. 다음 명령을 입력하여 홈 디렉터리를 식별하고 .sparkmagic이라는 폴더를 만듭니다. 전체 경로가 출력됩니다.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit().sparkmagic폴더에 config.json이라는 파일을 만들고 그 안에 다음 JSON 코드 조각을 추가합니다.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }파일을 다음과 같이 편집합니다.
템플릿 값 새로운 값 {USERNAME} 클러스터 로그인, 기본값은 admin입니다.{CLUSTERDNSNAME} 클러스터 이름 {BASE64ENCODEDPASSWORD} 실제 암호에 대한 base64 인코딩 암호입니다. https://www.url-encode-decode.com/base64-encode-decode/에서 base64 암호를 생성할 수 있습니다. "livy_server_heartbeat_timeout_seconds": 60sparkmagic 0.12.7(클러스터 v3.5 및 v3.6)을 사용하는 경우 유지합니다.sparkmagic 0.2.3(클러스터 v 3.4)을 사용하는 경우"should_heartbeat": true로 바꿉니다.sample config.json에서 전체 예제 파일을 볼 수 있습니다.
팁
세션이 유출되지 않도록 하트 비트가 전송됩니다. 컴퓨터가 절전 모드로 전환되거나 종료되면, 하트비트가 전송되지 않으므로 세션이 삭제됩니다. 클러스터 v3.4의 경우, 이 동작을 사용하지 않도록 설정하려면 Ambari UI에서 Livy 구성
livy.server.interactive.heartbeat.timeout를0로 설정할 수 있습니다. 클러스터 v 3.5의 경우, 위의 3.5 구성을 설정하지 않으면 세션이 삭제되지 않습니다.Jupyter를 시작합니다. 명령 프롬프트에서 다음 명령을 사용합니다.
jupyter notebook커널에서 사용할 수 있는 Spark Magic을 사용할 수 있는지 확인합니다. 다음 단계를 완료합니다.
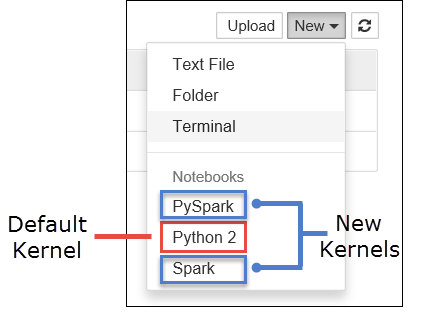
a. 새 Notebook을 만듭니다. 오른쪽 구석에서 새로 만들기를 선택합니다. 기본 커널 Python 2 또는 Python 3 및 사용자가 설치한 커널이 표시되어야 합니다. 실제 값은 설치 선택 사항에 따라 달라질 수 있습니다. PySpark를 선택합니다.
Important
새로 만들기를 선택한 후 오류에 대한 셸을 검토합니다.
TypeError: __init__() got an unexpected keyword argument 'io_loop'오류가 표시되는 경우 특정 버전의 Tornado에서 알려진 문제가 발생할 수 있습니다. 그렇다면 커널을 중지한 후pip install tornado==4.5.3명령을 사용하여 Tornado 설치를 다운그레이드합니다.b. 다음 코드 조각을 실행합니다.
%%sql SELECT * FROM hivesampletable LIMIT 5출력을 검색할 수 있으면 HDInsight 클러스터에 대한 연결이 테스트됩니다.
다른 클러스터에 연결하도록 노트북 구성을 업데이트하려는 경우 위의 3단계와 같이 새 값 집합으로 config.json을 업데이트합니다.
내 컴퓨터에 Jupyter를 설치해야 해야 이유는 무엇인가요?
컴퓨터에 Jupyter를 설치한 다음, HDInsight의 Apache Spark 클러스터에 연결하는 이유:
- 로컬로 노트북을 생성하고 실행 중인 클러스터에 대해 애플리케이션을 테스트한 다음, 해당 노트북을 클러스터에 업로드하는 옵션을 제공합니다. 노트북에 클러스터를 업로드하려면 클러스터에서 실행되는 Jupyter Notebook을 사용하여 업로드하거나 클러스터와 연결된 스토리지 계정의
/HdiNotebooks폴더에 저장할 수 있습니다. 클러스터에 Notebook을 저장하는 방법에 대한 자세한 내용은 Jupyter Notebook이 저장되는 위치를 참조하세요. - 로컬에서 사용할 수 있는 Notebook을 사용하여 애플리케이션 요구 사항에 따라 다른 Spark 클러스터에 연결할 수 있습니다.
- GitHub를 사용하여 원본 제어 시스템을 구현하고 Notebook에 대한 버전을 제어할 수 있습니다. 여러 사용자가 동일한 Notebook으로 작업할 수 있는 공동 작업 환경이 있을 수도 있습니다.
- 클러스터 없이 로컬로 Notebook을 사용할 수 있습니다. Notebook 또는 개발 환경을 수동으로 관리하기 위해서가 아니라 Notebook을 테스트하기 위해 클러스터가 필요합니다.
- 클러스터에서 Jupyter 설치를 구성하는 것보다 자체 로컬 개발 환경을 구성하는 것이 더 쉬울 수 있습니다. 하나 이상의 원격 클러스터를 구성하지 않고 로컬로 설치한 모든 소프트웨어를 모두 활용할 수 있습니다.
Warning
로컬 컴퓨터에 설치된 Jupyter를 사용하면 여러 사용자가 동일한 Spark 클러스터에서 동시에 동일한 Notebook을 실행할 수 있습니다. 이러한 상황에서 여러 Livy 세션이 생성됩니다. 문제가 발생하여 디버깅하려는 경우 어떤 사용자에게 어떤 Livy 세션이 속하는지를 추적하는 복잡한 작업이 됩니다.