Azure HDInsight를 사용하여 Apache Spark 문제 해결
Apache Ambari에서 Apache Spark 페이로드 작업 시 주요 issue 및 해결 방법을 알아봅니다.
클러스터에서 Apache Ambari를 사용하여 Apache Spark 애플리케이션을 구성하려면 어떻게 해야 하나요?
Spark 구성 값을 튜닝하여 Apache Spark 애플리케이션 OutofMemoryError 예외를 방지할 수 있습니다. 다음 단계는 Azure HDInsight의 기본 Spark 구성 값을 보여 줍니다.
https://CLUSTERNAME.azurehdidnsight.net에서 클러스터 자격 증명을 사용하여 Ambari에 로그인합니다. 초기 화면에 대시보드 개요가 표시됩니다. HDInsight 4.0 간에는 약간의 외관상 차이가 있습니다.Spark2>Configs로 이동합니다.
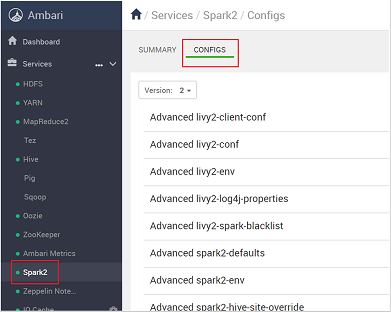
구성 목록에서 Custom-spark2-defaults를 선택하고 확장합니다.
spark.executor.memory와 같이 조정해야 하는 값 설정을 찾습니다. 이 경우 9728m의 값이 너무 높습니다.
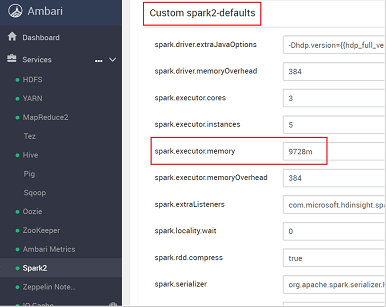
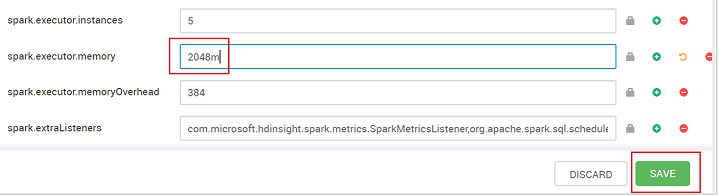
값을 권장 설정으로 지정합니다. 이 설정에는 2048m 값이 권장됩니다.
값을 저장하고 구성을 저장합니다. 저장을 선택합니다.
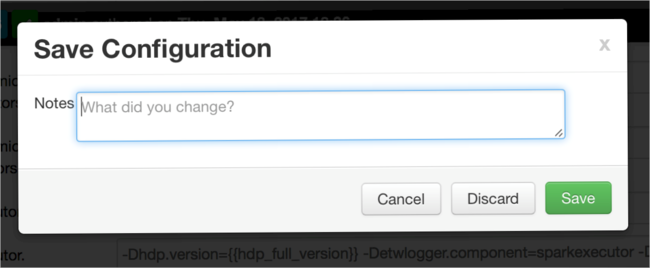
구성 변경 내용에 대한 메모를 작성하고 저장을 선택합니다.
주의할 필요가 있는 구성이면 알림이 표시됩니다. 항목을 확인한 후 계속 진행을 선택합니다.

구성이 저장될 때마다 서비스를 다시 시작하라는 메시지가 표시됩니다. 다시 시작을 선택합니다.
다시 시작을 확인합니다.
실행 중인 프로세스를 검토할 수 있습니다.
구성을 추가할 수 있습니다. 구성 목록에서 Custom-spark2-defaults를 선택하고 속성 추가를 선택합니다.
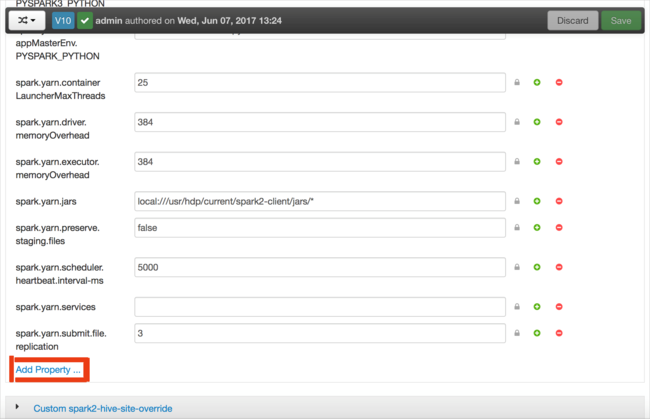
새 속성을 정의합니다. 데이터 형식과 같은 특정 설정에 대한 대화 상자를 사용하여 단일 속성을 정의할 수 있습니다. 또는 줄당 하나의 정의를 사용하여 여러 속성을 정의할 수 있습니다.
이 예제에서 spark.driver.memory 속성의 값은 4g로 정의되었습니다.
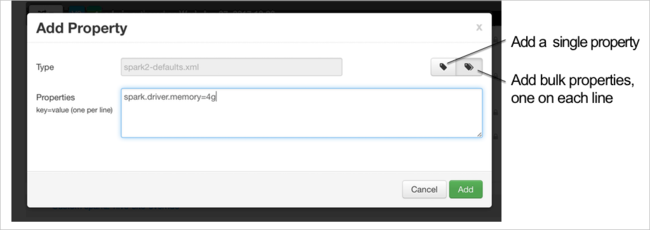
6단계와 7단계에서 설명한 대로 구성을 저장하고 서비스를 다시 시작합니다.
이러한 변경 내용은 클러스터 전체를 대상으로 하지만 Spark 작업을 제출할 때 재정의할 수 있습니다.
클러스터에서 Jupyter Notebook을 사용하여 Apache Spark 애플리케이션을 구성하려면 어떻게 할까요?
Jupyter Notebook의 첫 번째 셀에서 %%configure 지시문 뒤에 유효한 JSON 형식의 Spark 구성을 지정합니다. 필요에 따라 실제 값을 변경합니다.

클러스터에서 Apache Livy를 사용하여 Apache Spark 애플리케이션을 구성하려면 어떻게 해야 하나요?
cURL 같은 REST 클라이언트를 사용하여 Livy로 Spark 애플리케이션을 제출합니다. 다음과 유사한 명령을 사용합니다. 필요에 따라 실제 값을 변경합니다.
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
클러스터에서 spark-submit을 사용하여 Apache Spark 애플리케이션을 구성하려면 어떻게 해야 하나요?
다음과 비슷한 명령을 사용하여 spark-shell을 시작합니다. 필요에 따라 구성의 실제 값을 변경합니다.
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
추가 읽기
HDInsight 클러스터에서 Apache Spark 작업 제출
다음 단계
문제가 표시되지 않거나 문제를 해결할 수 없는 경우 다음 채널 중 하나를 방문하여 추가 지원을 받으세요.
Azure 커뮤니티 지원을 통해 Azure 전문가로부터 답변을 얻습니다.
사용자 환경을 개선하기 위한 공식 Microsoft Azure 계정인 @AzureSupport와 연결합니다. Azure 커뮤니티를 적절한 리소스(답변, 지원 및 전문가)에 연결합니다.
도움이 더 필요한 경우 Azure Portal에서 지원 요청을 제출할 수 있습니다. 메뉴 모음에서 지원을 선택하거나 도움말 + 지원 허브를 엽니다. 자세한 내용은 Azure 지원 요청을 만드는 방법을 참조하세요. 구독 관리 및 청구 지원에 대한 액세스 권한은 Microsoft Azure 구독에 포함되어 있으며, Azure 지원 플랜 중 하나를 통해 기술 지원이 제공됩니다.