Azure IoT Operations에서 데이터 흐름 구성
Important
이 페이지에는 미리 보기 상태인 Kubernetes 배포 매니페스트를 사용하여 Azure IoT Operations 구성 요소를 관리하기 위한 지침이 포함되어 있습니다. 이 기능은 몇 가지 제한 사항을 제공하며 프로덕션 워크로드에 사용하면 안 됩니다.
베타, 미리 보기로 제공되거나 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 약관은 Microsoft Azure 미리 보기에 대한 추가 사용 약관을 참조하세요.
데이터 흐름은 선택적 변환을 통해 데이터가 원본에서 대상까지 이동하는 경로입니다. 데이터 흐름 사용자 지정 리소스를 만들거나 Azure IoT Operations Studio 포털을 사용하여 데이터 흐름을 구성할 수 있습니다. 데이터 흐름은 원본, 변환 및 대상의 세 부분으로 구성됩니다.

원본 및 대상을 정의하려면 데이터 흐름 엔드포인트를 구성해야 합니다. 변환은 선택 사항이며 데이터 보강, 데이터 필터링 및 데이터를 다른 필드에 매핑하는 등의 작업을 포함할 수 있습니다.
Important
각 데이터 흐름에는 원본 또는 대상으로 Azure IoT Operations 로컬 MQTT broker 기본 엔드포인트 가 있어야 합니다.
Azure IoT Operations의 작업 환경을 사용하여 데이터 흐름을 만들 수 있습니다. 작업 환경은 데이터 흐름을 구성하는 시각적 인터페이스를 제공합니다. Bicep을 사용하여 Bicep 템플릿 파일을 사용하여 데이터 흐름을 만들거나 Kubernetes를 사용하여 YAML 파일을 사용하여 데이터 흐름을 만들 수도 있습니다.
원본, 변환 및 대상을 구성하는 방법을 알아보려면 계속 읽어보세요.
필수 조건
기본 데이터 흐름 프로필 및 엔드포인트를 사용하여 Azure IoT Operations 인스턴스가 있는 즉시 데이터 흐름을 배포할 수 있습니다. 그러나 데이터 흐름을 사용자 지정하도록 데이터 흐름 프로필 및 엔드포인트를 구성할 수 있습니다.
데이터 흐름 프로필
데이터 흐름에 대해 다른 크기 조정 설정이 필요하지 않은 경우 Azure IoT Operations에서 제공하는 기본 데이터 흐름 프로필을 사용합니다. 데이터 흐름 프로필을 구성하는 방법을 알아보려면 데이터 흐름 프로필 구성을 참조 하세요.
데이터 흐름 엔드포인트
데이터 흐름의 원본 및 대상을 구성하려면 데이터 흐름 엔드포인트가 필요합니다. 빠르게 시작하려면 로컬 MQTT broker에 대한 기본 데이터 흐름 엔드포인트를 사용할 수 있습니다. Kafka, Event Hubs 또는 Azure Data Lake Storage와 같은 다른 유형의 데이터 흐름 엔드포인트를 만들 수도 있습니다. 각 유형의 데이터 흐름 엔드포인트를 구성하는 방법을 알아보려면 데이터 흐름 엔드포인트 구성을 참조 하세요.
시작하기
필수 구성 요소가 있으면 데이터 흐름을 만들기 시작할 수 있습니다.
작업 환경에서 데이터 흐름을 만들려면 데이터 흐름 만들기 데이터 흐름을> 선택합니다. 그런 다음 데이터 흐름에 대한 원본, 변환 및 대상을 구성할 수 있는 페이지가 표시됩니다.
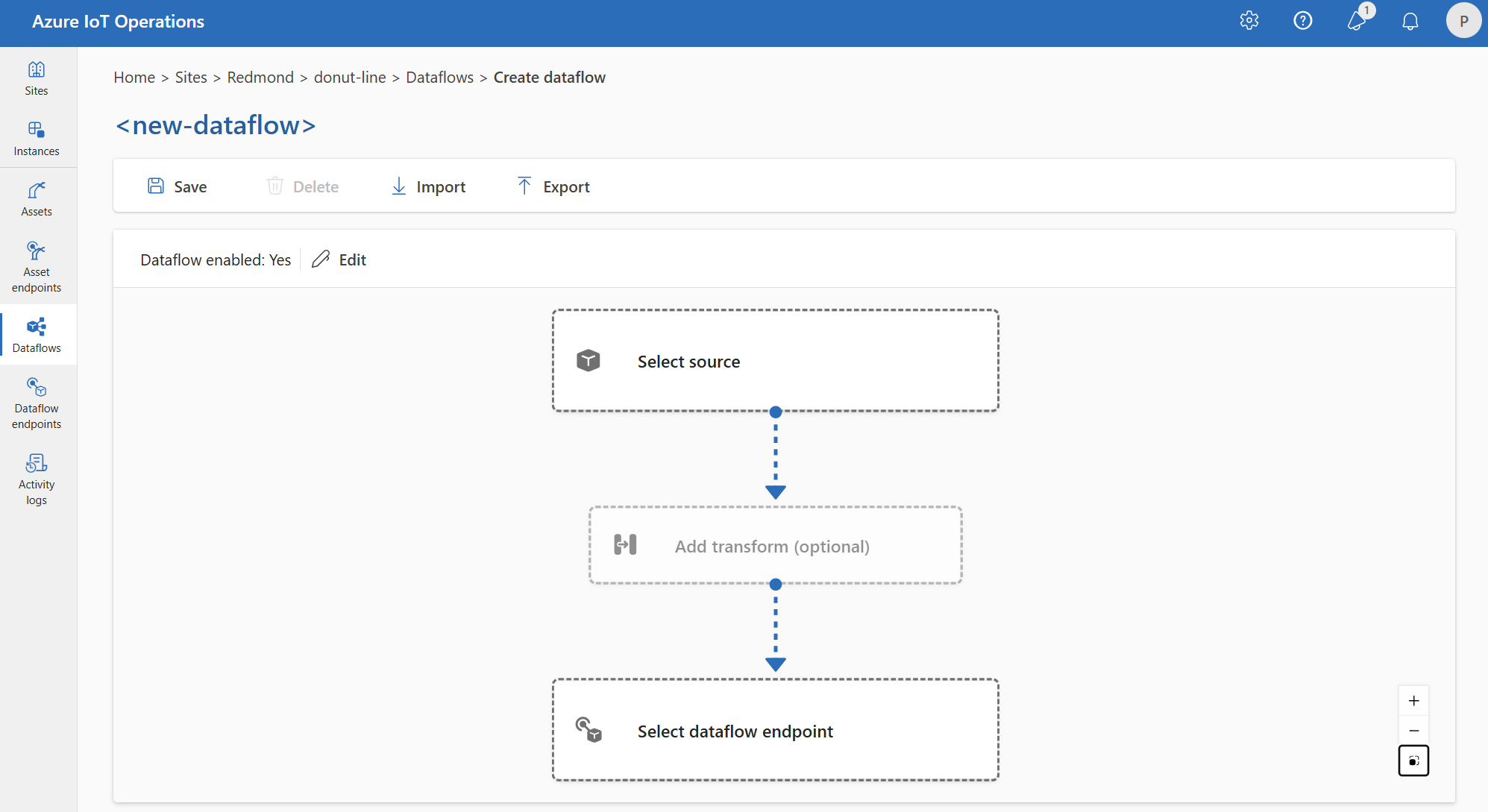
다음 섹션을 검토하여 데이터 흐름의 작업 유형을 구성하는 방법을 알아봅니다.
Source
데이터 흐름에 대한 원본을 구성하려면 엔드포인트 참조 및 엔드포인트에 대한 데이터 원본 목록을 지정합니다. 데이터 흐름의 원본으로 다음 옵션 중 하나를 선택합니다.
기본 엔드포인트가 원본으로 사용되지 않는 경우 대상으로 사용해야 합니다. 자세한 내용은 데이터 흐름이 로컬 MQTT broker 엔드포인트를 사용해야 하므로 참조하세요.
옵션 1: 기본 MQTT 엔드포인트를 원본으로 사용
원본 세부 정보에서 MQTT를 선택합니다.
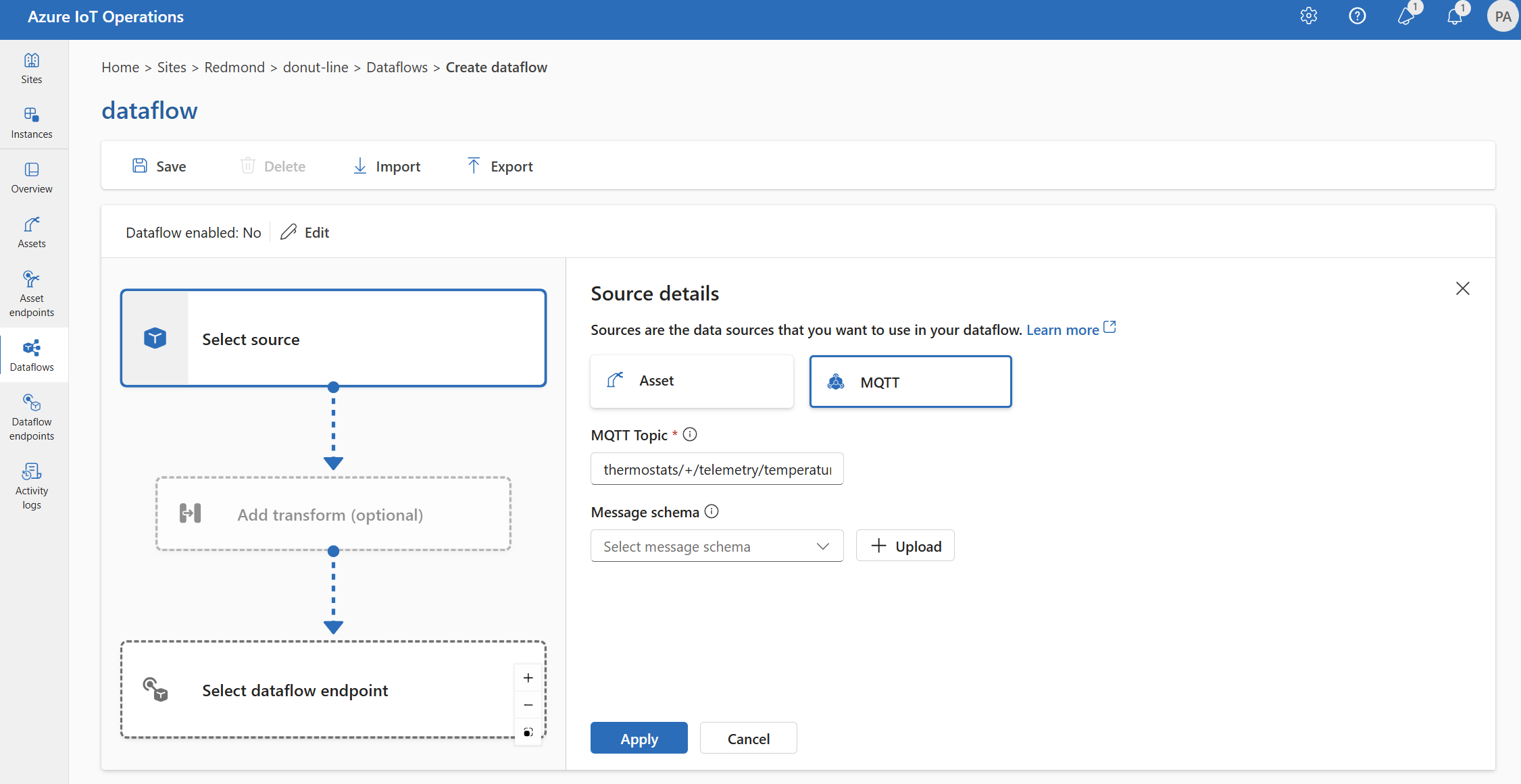
MQTT 원본에 대해 다음 설정을 입력합니다.
설정 설명 MQTT 항목 들어오는 메시지를 구독할 MQTT 토픽 필터입니다. MQTT 또는 Kafka 구성 항목을 참조 하세요. 메시지 스키마 들어오는 메시지를 역직렬화하는 데 사용할 스키마입니다. 데이터를 역직렬화하려면 스키마 지정을 참조하세요. 적용을 선택합니다.
옵션 2: 자산을 원본으로 사용
자산을 데이터 흐름의 원본으로 사용할 수 있습니다. 자산을 원본으로 사용하는 것은 작업 환경에서만 사용할 수 있습니다.
원본 세부 정보에서 자산을 선택합니다.
원본 엔드포인트로 사용할 자산을 선택합니다.
계속을 선택합니다.
선택한 자산에 대한 데이터 요소 목록이 표시됩니다.
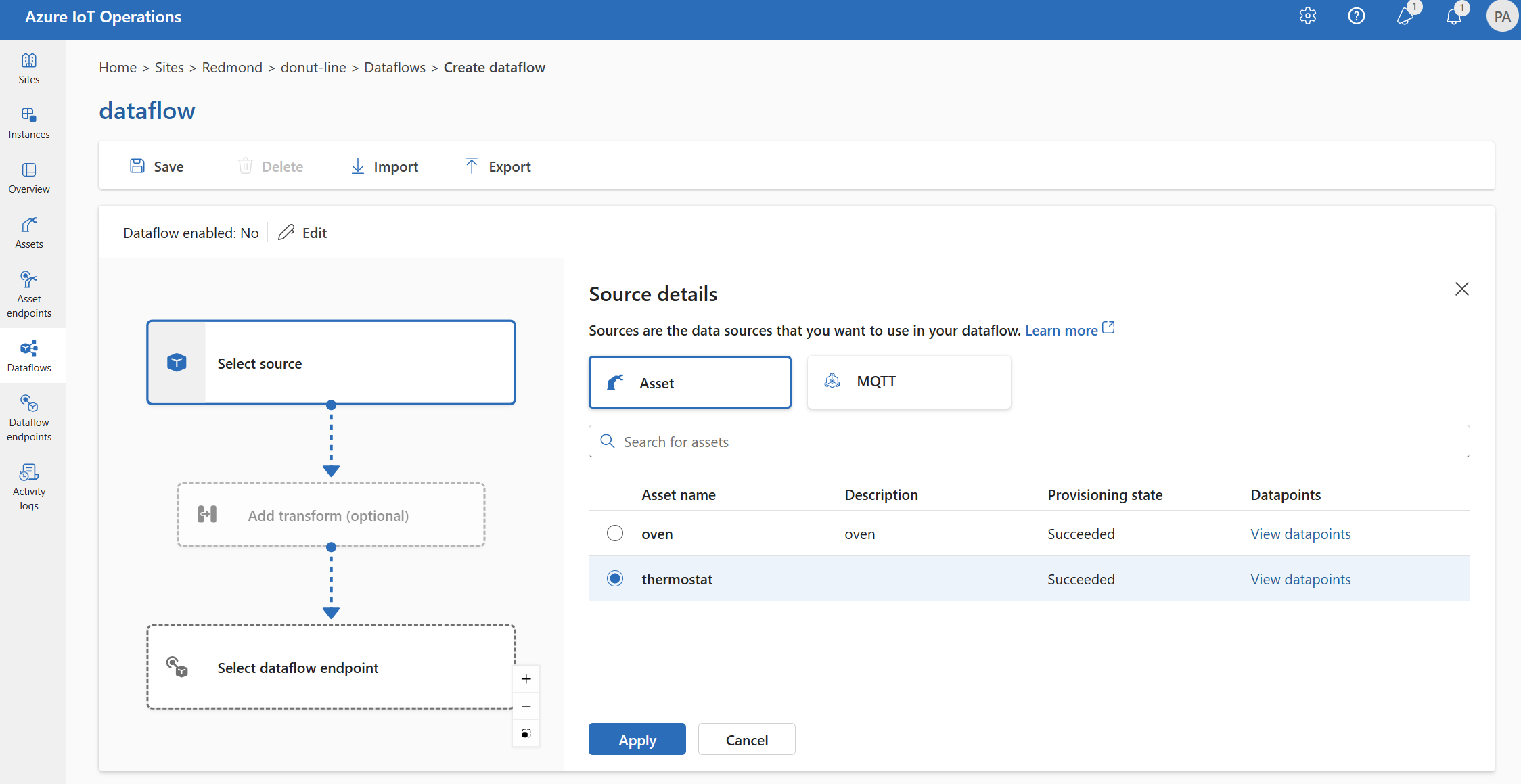
적용을 선택하여 자산을 원본 엔드포인트로 사용합니다.
자산을 원본으로 사용하는 경우 자산 정의는 데이터 흐름에 대한 스키마를 유추하는 데 사용됩니다. 자산 정의에는 자산의 데이터 요소에 대한 스키마가 포함됩니다. 자세한 내용은 자산 구성 관리를 원격으로 참조하세요.
구성되면 자산의 데이터가 로컬 MQTT 브로커를 통해 데이터 흐름에 도달했습니다. 따라서 자산을 원본으로 사용하는 경우 데이터 흐름은 로컬 MQTT broker 기본 엔드포인트를 실제 원본으로 사용합니다.
옵션 3: 사용자 지정 MQTT 또는 Kafka 데이터 흐름 엔드포인트를 원본으로 사용
사용자 지정 MQTT 또는 Kafka 데이터 흐름 엔드포인트를 만든 경우(예: Event Grid 또는 Event Hubs와 함께 사용) 데이터 흐름의 원본으로 사용할 수 있습니다. Data Lake 또는 Fabric OneLake와 같은 스토리지 유형 엔드포인트는 원본으로 사용할 수 없습니다.
구성하려면 Kubernetes YAML 또는 Bicep을 사용합니다. 자리 표시자 값을 사용자 지정 엔드포인트 이름 및 토픽으로 바꿉니다.
사용자 지정 MQTT 또는 Kafka 엔드포인트를 원본으로 사용하는 것은 현재 작업 환경에서 지원되지 않습니다.
데이터 원본 구성(MQTT 또는 Kafka 항목)
데이터 흐름 엔드포인트 구성을 수정할 필요 없이 원본에서 여러 MQTT 또는 Kafka 토픽을 지정할 수 있습니다. 이러한 유연성은 토픽이 달라도 여러 데이터 흐름에서 동일한 엔드포인트를 다시 사용할 수 있습니다. 자세한 내용은 데이터 흐름 엔드포인트 재사용을 참조하세요.
MQTT 항목
원본이 MQTT(Event Grid 포함) 엔드포인트인 경우 MQTT 토픽 필터를 사용하여 들어오는 메시지를 구독할 수 있습니다. 토픽 필터에는 여러 항목을 구독하는 와일드카드가 포함될 수 있습니다. 예를 들어 자동 thermostats/+/telemetry/temperature/# 온도 조절기의 모든 온도 원격 분석 메시지를 구독합니다. MQTT 토픽 필터를 구성하려면 다음을 수행합니다.
작업 환경 데이터 흐름 원본 세부 정보에서 MQTT를 선택한 다음 MQTT 토픽 필드를 사용하여 들어오는 메시지를 구독할 MQTT 토픽 필터를 지정합니다.
참고 항목
작업 환경에서는 MQTT 토픽 필터를 하나만 지정할 수 있습니다. 여러 MQTT 토픽 필터를 사용하려면 Bicep 또는 Kubernetes를 사용합니다.
공유 구독
MQTT 원본에서 공유 구독을 사용하려면 공유 구독 토픽을 형식으로 $shared/<GROUP_NAME>/<TOPIC_FILTER>지정할 수 있습니다.
작업 환경 데이터 흐름 원본 세부 정보에서 MQTT를 선택하고 MQTT 토픽 필드를 사용하여 공유 구독 그룹 및 토픽을 지정합니다.
데이터 흐름 프로필의 인스턴스 수가 1보다 크면 MQTT 원본을 사용하는 모든 데이터 흐름에 대해 공유 구독이 자동으로 사용하도록 설정됩니다. 이 경우 $shared 접두사를 추가하고 공유 구독 그룹 이름이 자동으로 생성됩니다. 예를 들어 인스턴스 수가 3인 데이터 흐름 프로필이 있고 데이터 흐름이 토픽 topic1 topic2으로 구성된 원본으로 MQTT 엔드포인트를 사용하고 공유 구독 $shared/<GENERATED_GROUP_NAME>/topic1 $shared/<GENERATED_GROUP_NAME>/topic2으로 자동 변환되는 경우
구성에서 명명 $shared/mygroup/topic 된 토픽을 명시적으로 만들 수 있습니다. 그러나 필요할 때 접두사를 $shared 자동으로 추가하므로 항목을 명시적으로 추가하는 것은 권장 $shared 되지 않습니다. 데이터 흐름은 설정되지 않은 경우 그룹 이름으로 최적화를 수행할 수 있습니다. 예를 들어 $share 설정되지 않고 데이터 흐름은 토픽 이름에 대해서만 작동해야 합니다.
Important
인스턴스 수가 1보다 클 때 공유 구독이 필요한 데이터 흐름은 공유 구독을 지원하지 않으므로 Event Grid MQTT broker를 원본 으로 사용할 때 중요합니다. 메시지 누락을 방지하려면 Event Grid MQTT broker를 원본으로 사용할 때 데이터 흐름 프로필 인스턴스 수를 1로 설정합니다. 데이터 흐름이 구독자이고 클라우드에서 메시지를 수신하는 경우입니다.
Kafka 토픽
원본이 Kafka(Event Hubs 포함) 엔드포인트인 경우 들어오는 메시지에 대해 구독할 개별 Kafka 토픽을 지정합니다. 와일드카드는 지원되지 않으므로 각 토픽을 정적으로 지정해야 합니다.
참고 항목
Kafka 엔드포인트를 통해 Event Hubs를 사용하는 경우 네임스페이스 내의 각 개별 이벤트 허브는 Kafka 토픽입니다. 예를 들어 두 개의 이벤트 허브가 있는 Event Hubs 네임스페이스가 thermostats 있는 humidifiers경우 각 이벤트 허브를 Kafka 토픽으로 지정할 수 있습니다.
Kafka 토픽을 구성하려면 다음을 수행합니다.
Kafka 엔드포인트를 원본으로 사용하는 것은 현재 작업 환경에서 지원되지 않습니다.
원본 스키마 지정
MQTT 또는 Kafka를 원본으로 사용하는 경우 스키마를 지정하여 작업 환경 포털에 데이터 요소 목록을 표시할 수 있습니다. 스키마를 사용하여 들어오는 메시지를 역직렬화하고 유효성을 검사하는 것은 현재 지원되지 않습니다.
원본이 자산인 경우 스키마는 자산 정의에서 자동으로 유추됩니다.
팁
샘플 데이터 파일에서 스키마를 생성하려면 스키마 Gen 도우미를 사용합니다.
원본에서 들어오는 메시지를 역직렬화하는 데 사용되는 스키마를 구성하려면 다음을 수행합니다.
작업 환경 데이터 흐름 원본 세부 정보에서 MQTT를 선택하고 메시지 스키마 필드를 사용하여 스키마를 지정합니다. 업로드 단추를 사용하여 스키마 파일을 먼저 업로드할 수 있습니다. 자세한 내용은 메시지 스키마 이해를 참조하세요.
변환
변환 작업은 데이터를 대상으로 보내기 전에 원본에서 데이터를 변환할 수 있는 위치입니다. 변환은 선택 사항입니다. 데이터를 변경할 필요가 없으면 데이터 흐름 구성에 변환 작업을 포함하지 마세요. 여러 변환은 구성에 지정된 순서에 관계없이 여러 변환이 단계별로 연결됩니다. 단계의 순서는 항상 다음과 같습니다.
- 보강: 일치시킬 데이터 세트 및 조건이 지정된 원본 데이터에 추가 데이터를 추가합니다.
- 필터: 조건에 따라 데이터를 필터링합니다.
- 새 속성 매핑, 컴퓨팅, 이름 바꾸기 또는 추가: 선택적 변환을 사용하여 한 필드에서 다른 필드로 데이터를 이동합니다.
이 섹션은 데이터 흐름 변환에 대한 소개입니다. 자세한 내용은 데이터 흐름을 사용하여 데이터 매핑, 데이터 흐름 변환을 사용하여 데이터 변환 및 데이터 흐름을 사용하여 데이터 보강을 참조하세요.
작업 환경에서 데이터 흐름>변환 추가(선택 사항)를 선택합니다.
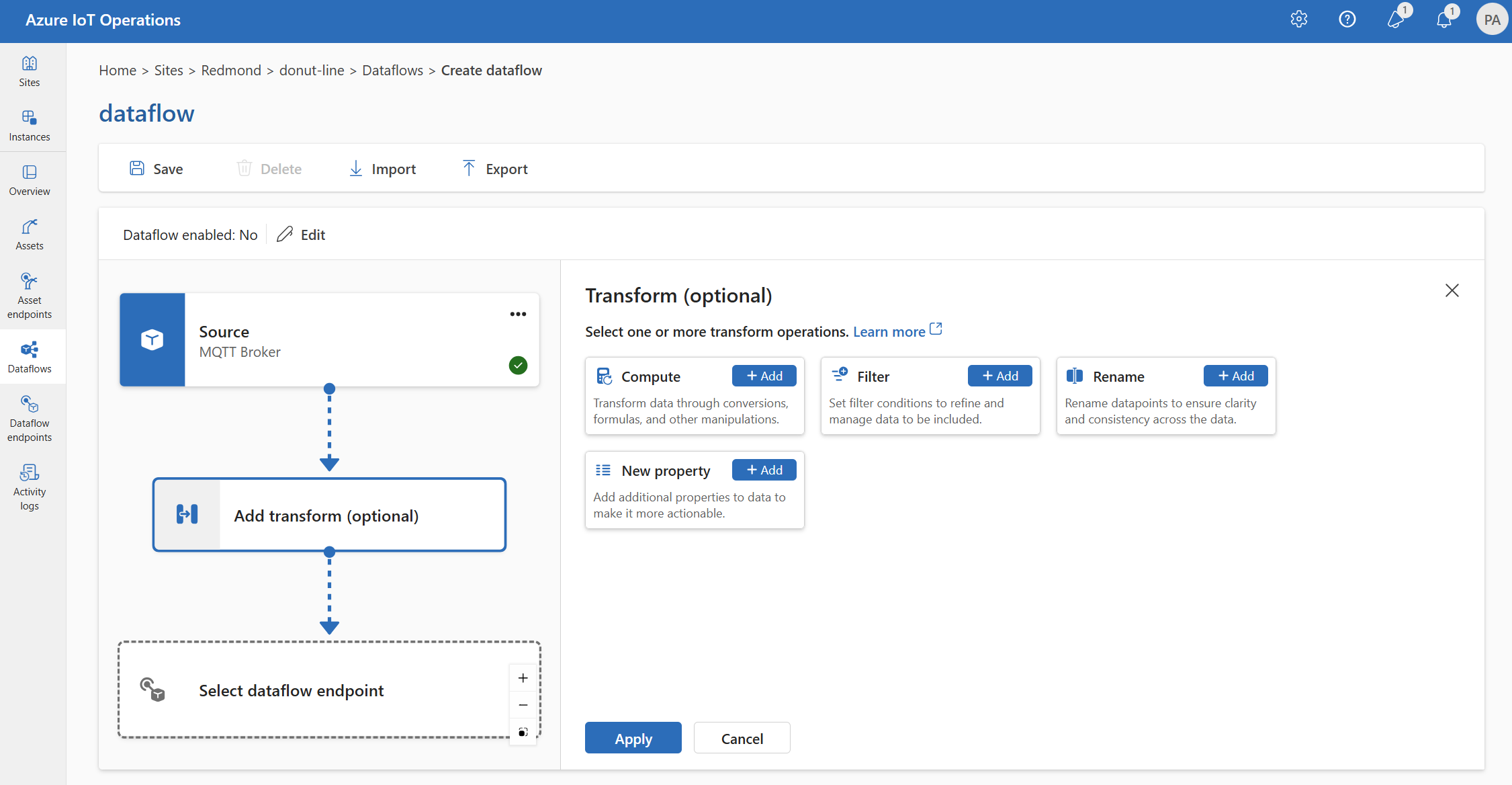
보강: 참조 데이터 추가
데이터를 보강하려면 먼저 Azure IoT Operations 상태 저장소에 참조 데이터 세트를 추가합니다. 데이터 세트는 조건에 따라 원본 데이터에 추가 데이터를 추가하는 데 사용됩니다. 조건은 데이터 세트의 필드와 일치하는 원본 데이터의 필드로 지정됩니다.
상태 저장소 CLI를 사용하여 샘플 데이터를 상태 저장소에 로드할 수 있습니다. 상태 저장소의 키 이름은 데이터 흐름 구성의 데이터 세트에 해당합니다.
현재 보강 단계는 작업 환경에서 지원되지 않습니다.
데이터 세트에 asset 필드가 있는 레코드가 있는 경우 다음과 같습니다.
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
필드가 일치하는 thermostat1 원본의 deviceId 데이터에는 location 필터 및 manufacturer 맵 단계에서 사용할 수 있는 필드와 필드가 있습니다.
조건 구문에 대한 자세한 내용은 데이터 흐름을 사용하여 데이터 보강 및 데이터 흐름을 사용하여 데이터 변환을 참조하세요.
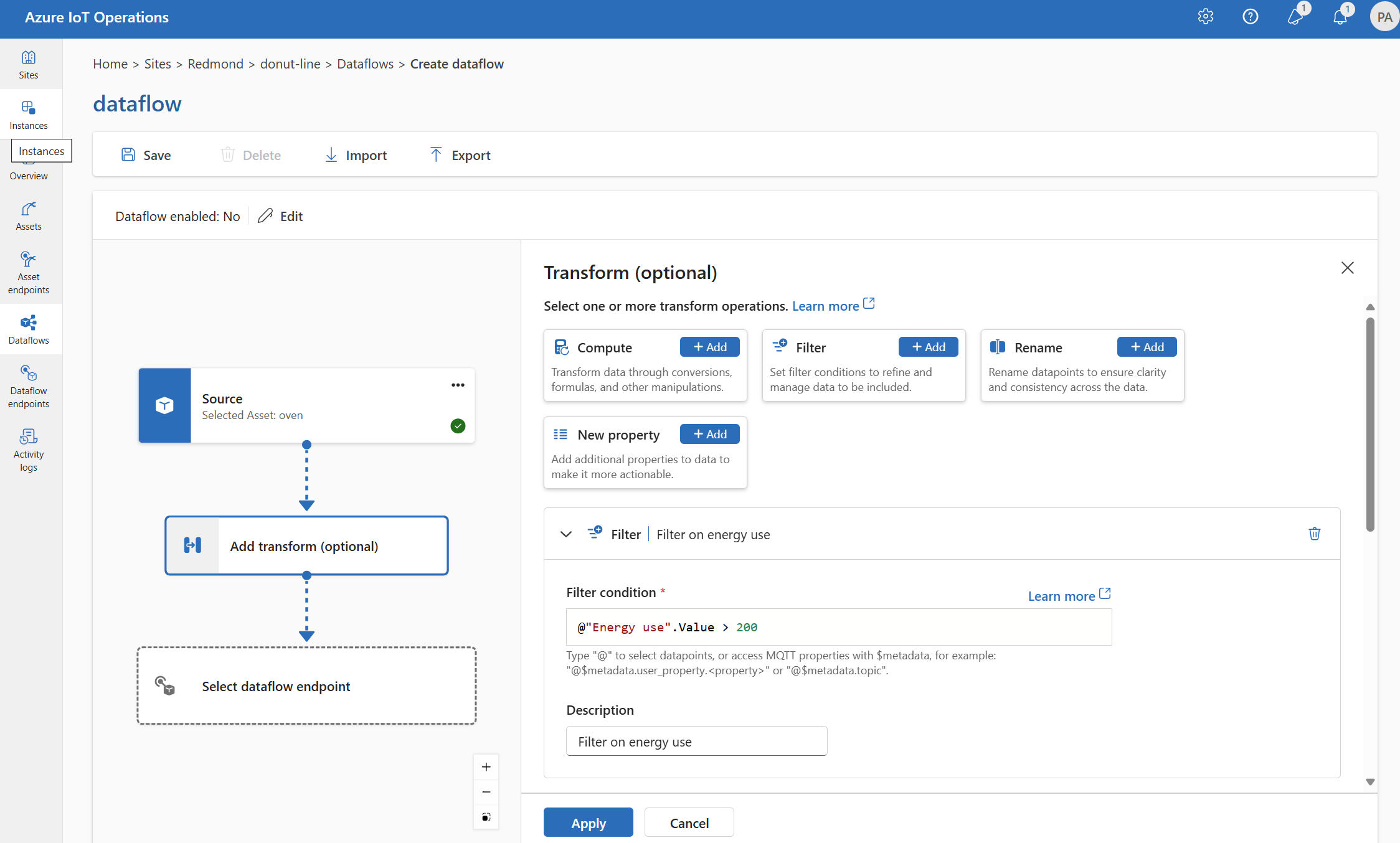
필터: 조건에 따라 데이터 필터링
조건에 따라 데이터를 필터링하려면 filter 단계를 사용할 수 있습니다. 조건은 값과 일치하는 원본 데이터의 필드로 지정됩니다.
변환(선택 사항)에서 필터>추가를 선택합니다.
필요한 설정을 입력합니다.
설정 설명 필터 조건 원본 데이터의 필드를 기반으로 데이터를 필터링하는 조건입니다. 설명 필터 조건에 대한 설명을 제공합니다. 필터 조건 필드에 Ctrl + 공백을 입력
@하거나 선택하여 드롭다운에서 데이터 포인트를 선택합니다.형식
@$metadata.user_properties.<property>을 사용하여 MQTT 메타데이터 속성을 입력할 수 있습니다@$metadata.topic. 형식@$metadata.<header>을 사용하여 $metadata 헤더를 입력할 수도 있습니다. 구문은$metadata메시지 헤더의 일부인 MQTT 속성에만 필요합니다. 자세한 내용은 필드 참조를 참조 하세요.조건은 원본 데이터의 필드를 사용할 수 있습니다. 예를 들어 온도 필드를 기준으로 20보다 작거나 같은 데이터를 필터링하는 필터
@temperature > 20조건을 사용할 수 있습니다.적용을 선택합니다.
맵: 한 필드에서 다른 필드로 데이터 이동
선택적 변환을 통해 데이터를 다른 필드에 매핑하려면 map 연산을 사용할 수 있습니다. 변환은 원본 데이터의 필드를 사용하는 수식으로 지정됩니다.
작업 환경에서는 현재 컴퓨팅, 이름 바꾸기 및 새 속성 변환을 사용하여 매핑이 지원됩니다.
Compute
컴퓨팅 변환을 사용하여 원본 데이터에 수식을 적용할 수 있습니다. 이 작업은 원본 데이터에 수식을 적용하고 결과 필드를 저장하는 데 사용됩니다.
변환(선택 사항)에서 컴퓨팅 추가를>선택합니다.
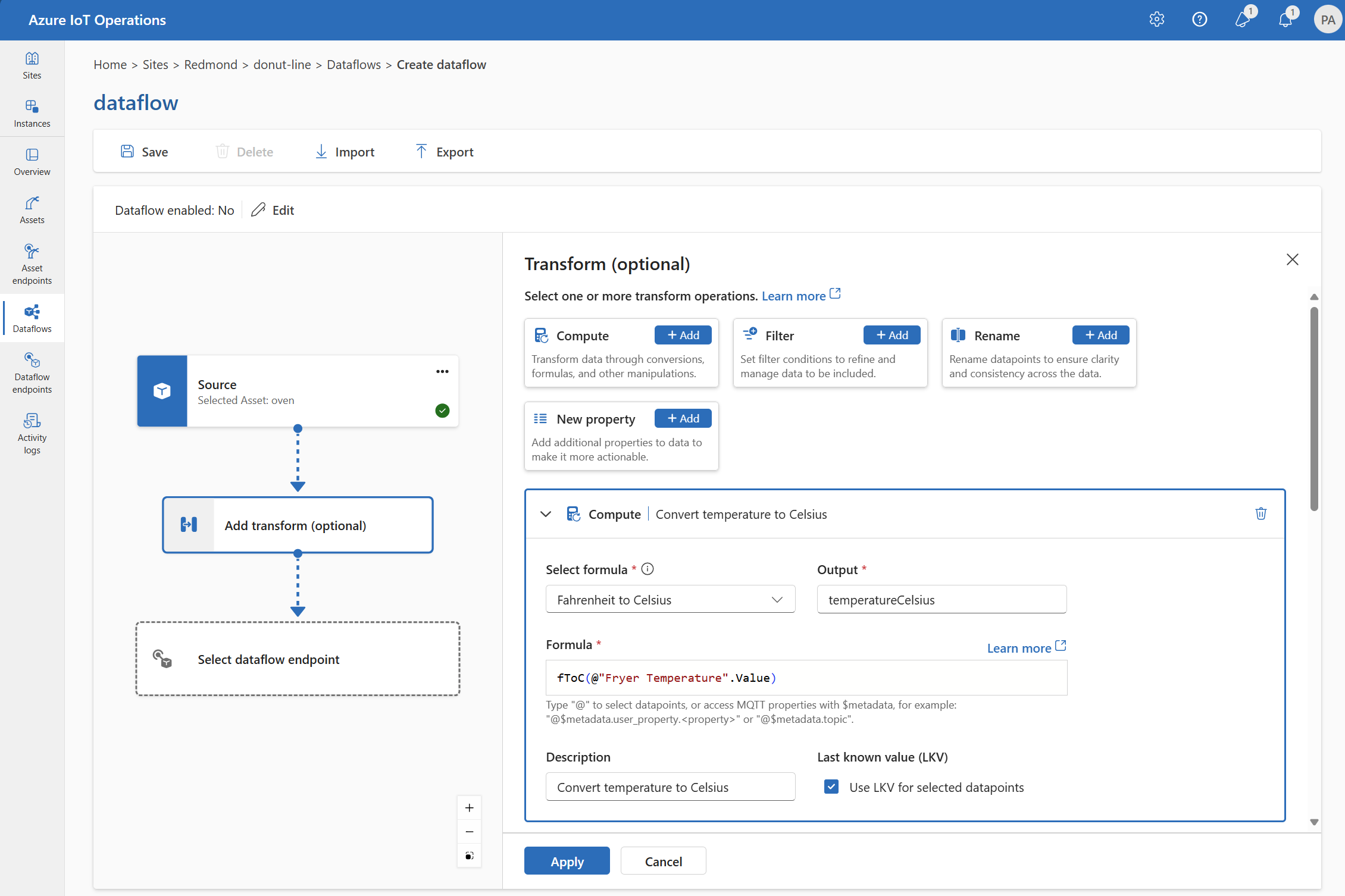
필요한 설정을 입력합니다.
설정 설명 수식 선택 드롭다운에서 기존 수식을 선택하거나 사용자 지정을 선택하여 수식을 수동으로 입력합니다. 출력 결과의 출력 표시 이름을 지정합니다. 수식 원본 데이터에 적용할 수식을 입력합니다. 설명 변환에 대한 설명을 제공합니다. 마지막으로 알려진 값 필요에 따라 현재 값을 사용할 수 없는 경우 마지막으로 알려진 값을 사용합니다. 수식 필드에 수식을 입력하거나 편집할 수 있습니다. 수식은 원본 데이터의 필드를 사용할 수 있습니다. 드롭다운에서 데이터 포인트를 선택하려면 Ctrl+스페이스바를 입력
@하거나 선택합니다.형식
@$metadata.user_properties.<property>을 사용하여 MQTT 메타데이터 속성을 입력할 수 있습니다@$metadata.topic. 형식@$metadata.<header>을 사용하여 $metadata 헤더를 입력할 수도 있습니다. 구문은$metadata메시지 헤더의 일부인 MQTT 속성에만 필요합니다. 자세한 내용은 필드 참조를 참조 하세요.수식은 원본 데이터의 필드를 사용할 수 있습니다. 예를 들어 원본 데이터의 필드를 사용하여
temperature온도를 섭씨로 변환하고 출력 필드에 저장할 수 있습니다temperatureCelsius.적용을 선택합니다.
이름 바꾸기
이름 바꾸기 변환을 사용하여 데이터 포인트의 이름을 바꿀 수 있습니다. 이 작업은 원본 데이터의 데이터 포인트 이름을 새 이름으로 바꾸는 데 사용됩니다. 새 이름은 데이터 흐름의 후속 단계에서 사용할 수 있습니다.
변환(선택 사항)에서 추가 이름 바꾸기>를 선택합니다.
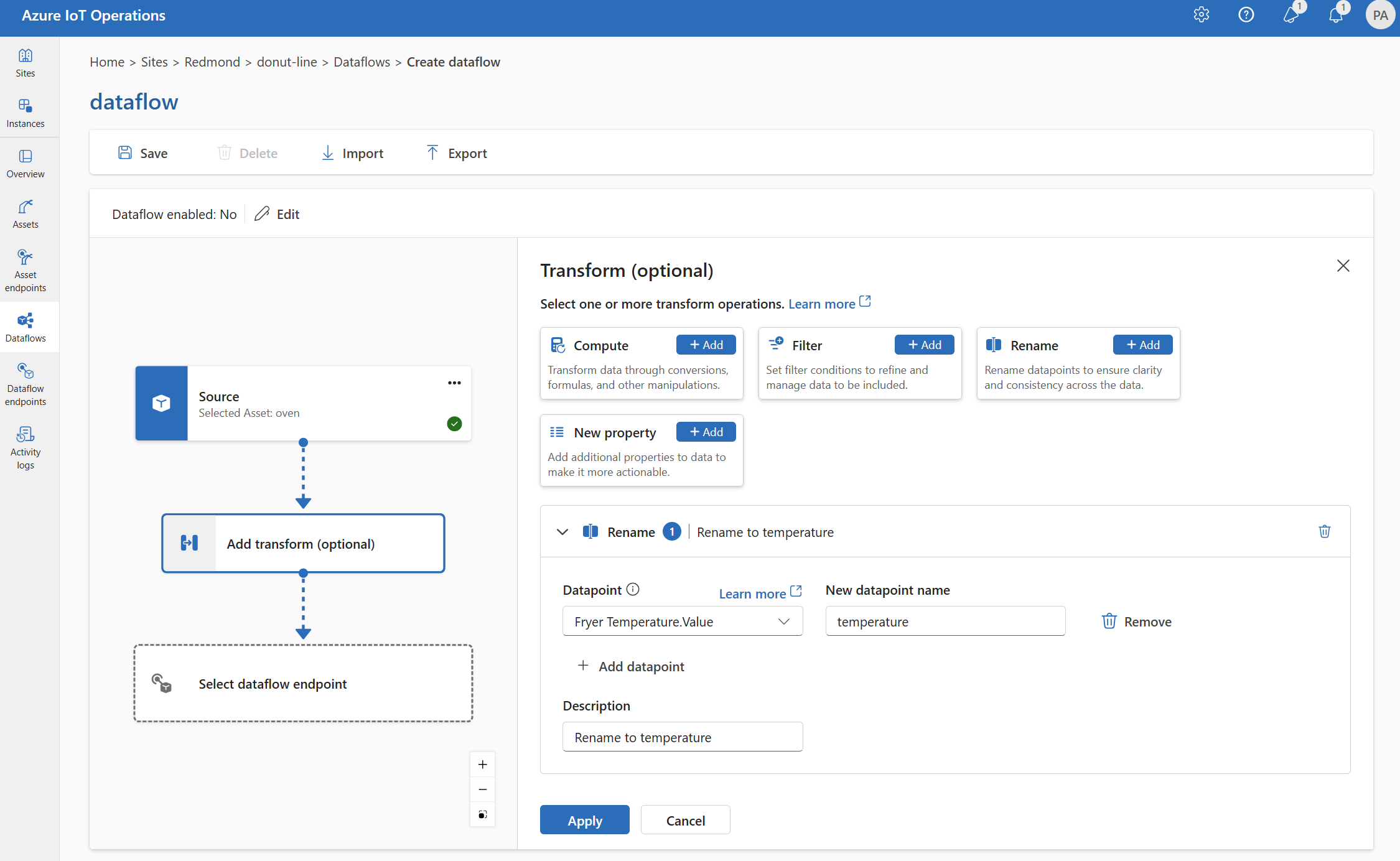
필요한 설정을 입력합니다.
설정 설명 데이터 포인트 드롭다운에서 데이터 포인트를 선택하거나 $metadata 헤더를 입력합니다. 새 데이터 포인트 이름 데이터 포인트의 새 이름을 입력합니다. 설명 변환에 대한 설명을 제공합니다. 드롭다운에서 데이터 포인트를 선택하려면 Ctrl+스페이스바를 입력
@하거나 선택합니다.형식
@$metadata.user_properties.<property>을 사용하여 MQTT 메타데이터 속성을 입력할 수 있습니다@$metadata.topic. 형식@$metadata.<header>을 사용하여 $metadata 헤더를 입력할 수도 있습니다. 구문은$metadata메시지 헤더의 일부인 MQTT 속성에만 필요합니다. 자세한 내용은 필드 참조를 참조 하세요.적용을 선택합니다.
새 속성
New 속성 변환을 사용하여 원본 데이터에 새 속성을 추가할 수 있습니다. 이 작업은 원본 데이터에 새 속성을 추가하는 데 사용됩니다. 새 속성은 데이터 흐름의 후속 단계에서 사용할 수 있습니다.
변환(선택 사항)에서 새 속성>추가를 선택합니다.
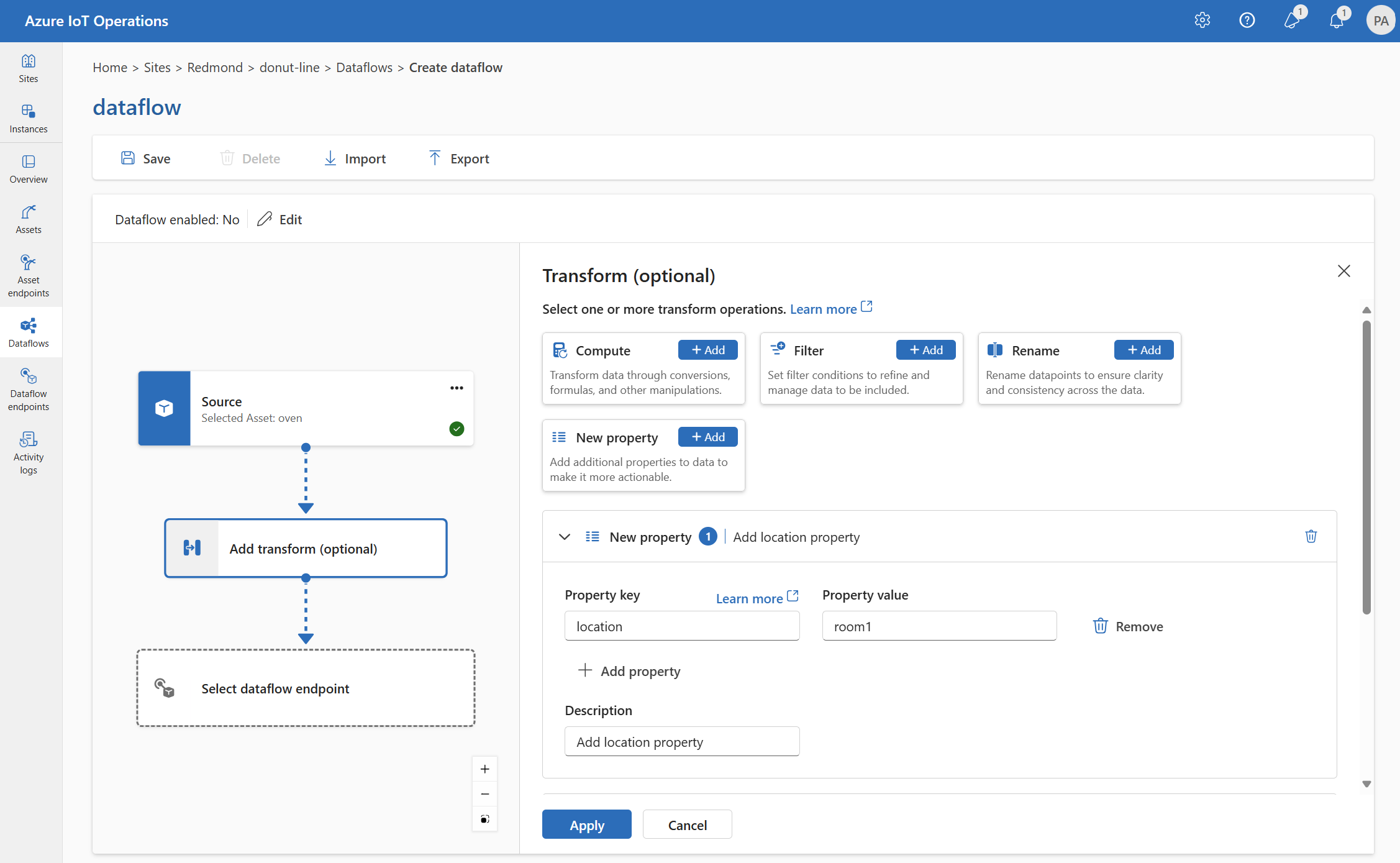
필요한 설정을 입력합니다.
설정 설명 속성 키 새 속성의 키를 입력합니다. 속성 값 새 속성의 값을 입력합니다. 설명 새 속성에 대한 설명을 제공합니다. 적용을 선택합니다.
자세한 내용은 데이터 흐름을 사용하여 데이터 매핑 및 데이터 흐름을 사용하여 데이터 변환을 참조하세요.
스키마에 따라 데이터 직렬화
데이터를 대상으로 보내기 전에 직렬화하려면 스키마 및 serialization 형식을 지정해야 합니다. 그렇지 않으면 데이터가 유추된 형식을 사용하여 JSON으로 직렬화됩니다. Microsoft Fabric 또는 Azure Data Lake와 같은 스토리지 엔드포인트에는 데이터 일관성을 보장하기 위한 스키마가 필요합니다. 지원되는 serialization 형식은 Parquet 및 Delta입니다.
팁
샘플 데이터 파일에서 스키마를 생성하려면 스키마 Gen 도우미를 사용합니다.
작업 환경의 경우 데이터 흐름 엔드포인트 세부 정보에서 스키마 및 serialization 형식을 지정합니다. serialization 형식을 지원하는 엔드포인트는 Microsoft Fabric OneLake, Azure Data Lake Storage Gen 2 및 Azure Data Explorer입니다. 예를 들어 델타 형식으로 데이터를 직렬화하려면 스키마 레지스트리에 스키마를 업로드하고 데이터 흐름 대상 엔드포인트 구성에서 참조해야 합니다.
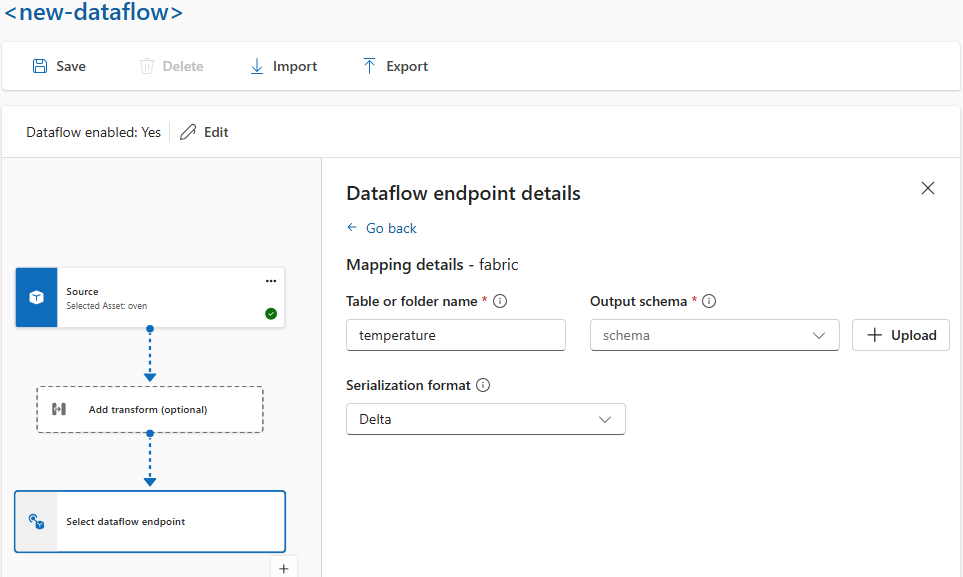
스키마 레지스트리에 대한 자세한 내용은 메시지 스키마 이해를 참조 하세요.
대상
데이터 흐름의 대상을 구성하려면 엔드포인트 참조 및 데이터 대상을 지정합니다. 엔드포인트에 대한 데이터 대상 목록을 지정할 수 있습니다.
로컬 MQTT broker 이외의 대상으로 데이터를 보내려면 데이터 흐름 엔드포인트를 만듭니다. 방법을 알아보려면 데이터 흐름 엔드포인트 구성을 참조 하세요. 대상이 로컬 MQTT broker가 아닌 경우 원본으로 사용해야 합니다. 자세한 내용은 데이터 흐름이 로컬 MQTT broker 엔드포인트를 사용해야 하므로 참조하세요.
Important
스토리지 엔드포인트에는 serialization을 위한 스키마가 필요합니다. Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer 또는 Local Storage에서 데이터 흐름을 사용하려면 스키마 참조를 지정해야 합니다.
대상으로 사용할 데이터 흐름 엔드포인트를 선택합니다.
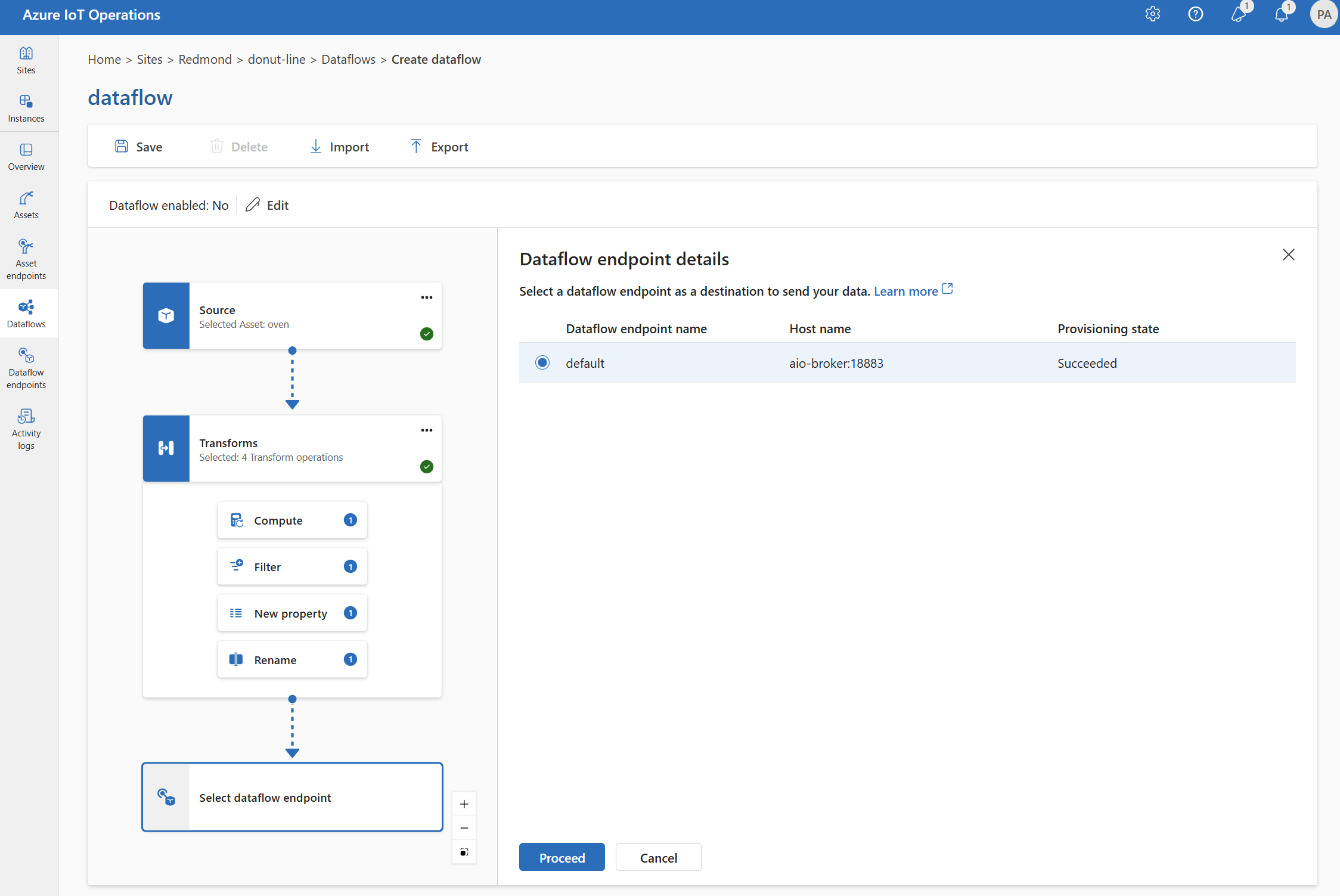
스토리지 엔드포인트에는 serialization을 위한 스키마가 필요합니다. Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer 또는 로컬 스토리지 대상 엔드포인트를 선택하는 경우 스키마 참조를 지정해야 합니다. 예를 들어 데이터를 델타 형식으로 Microsoft Fabric 엔드포인트로 직렬화하려면 스키마 레지스트리에 스키마를 업로드하고 데이터 흐름 대상 엔드포인트 구성에서 참조해야 합니다.
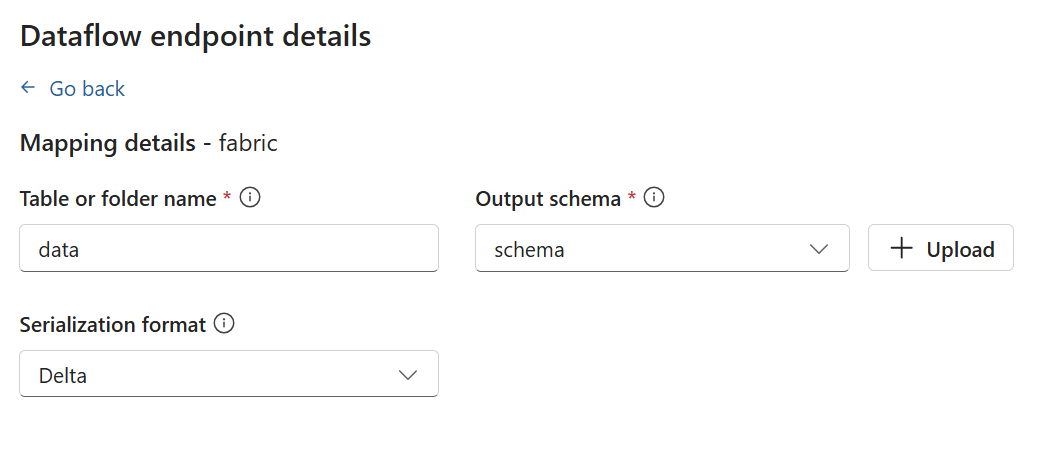
[진행]을 선택하여 대상을 구성합니다.
데이터를 보낼 토픽 또는 테이블을 포함하여 대상에 필요한 설정을 입력합니다. 자세한 내용은 데이터 대상 구성(토픽, 컨테이너 또는 테이블)을 참조하세요.
데이터 대상 구성(토픽, 컨테이너 또는 테이블)
데이터 원본과 마찬가지로 데이터 대상은 여러 데이터 흐름에서 데이터 흐름 엔드포인트를 재사용 가능한 상태로 유지하는 데 사용되는 개념입니다. 기본적으로 데이터 흐름 엔드포인트 구성의 하위 디렉터리를 나타냅니다. 예를 들어 데이터 흐름 엔드포인트가 스토리지 엔드포인트인 경우 데이터 대상은 스토리지 계정의 테이블입니다. 데이터 흐름 엔드포인트가 Kafka 엔드포인트인 경우 데이터 대상은 Kafka 토픽입니다.
| 엔드포인트 유형 | 데이터 대상 의미 | 설명 |
|---|---|---|
| MQTT(또는 Event Grid) | 항목 | 데이터가 전송되는 MQTT 항목입니다. 정적 토픽만 지원되며 와일드카드는 지원되지 않습니다. |
| Kafka(또는 Event Hubs) | 항목 | 데이터가 전송되는 Kafka 토픽입니다. 정적 토픽만 지원되며 와일드카드는 지원되지 않습니다. 엔드포인트가 Event Hubs 네임스페이스인 경우 데이터 대상은 네임스페이스 내의 개별 이벤트 허브입니다. |
| Azure Data Lake Storage | 컨테이너 | 스토리지 계정의 컨테이너입니다. 테이블이 아닙니다. |
| Microsoft Fabric OneLake | 테이블 또는 폴더 | 엔드포인트에 대해 구성된 경로 형식에 해당합니다. |
| Azure Data Explorer | 테이블 | Azure Data Explorer 데이터베이스의 테이블입니다. |
| 로컬 스토리지 | 폴더 | 로컬 스토리지 영구 볼륨 탑재의 폴더 또는 디렉터리 이름입니다. Azure Arc Cloud Ingest Edge 볼륨에서 사용하도록 설정된 Azure Container Storage를 사용하는 경우 만든 하위 명령의 spec.path 매개 변수와 일치해야 합니다. |
데이터 대상을 구성하려면 다음을 수행합니다.
작업 환경을 사용하는 경우 데이터 대상 필드는 엔드포인트 유형에 따라 자동으로 해석됩니다. 예를 들어 데이터 흐름 엔드포인트가 스토리지 엔드포인트인 경우 대상 세부 정보 페이지에서 컨테이너 이름을 입력하라는 메시지를 표시합니다. 데이터 흐름 엔드포인트가 MQTT 엔드포인트인 경우 대상 세부 정보 페이지에서 토픽을 입력하라는 메시지를 표시합니다.
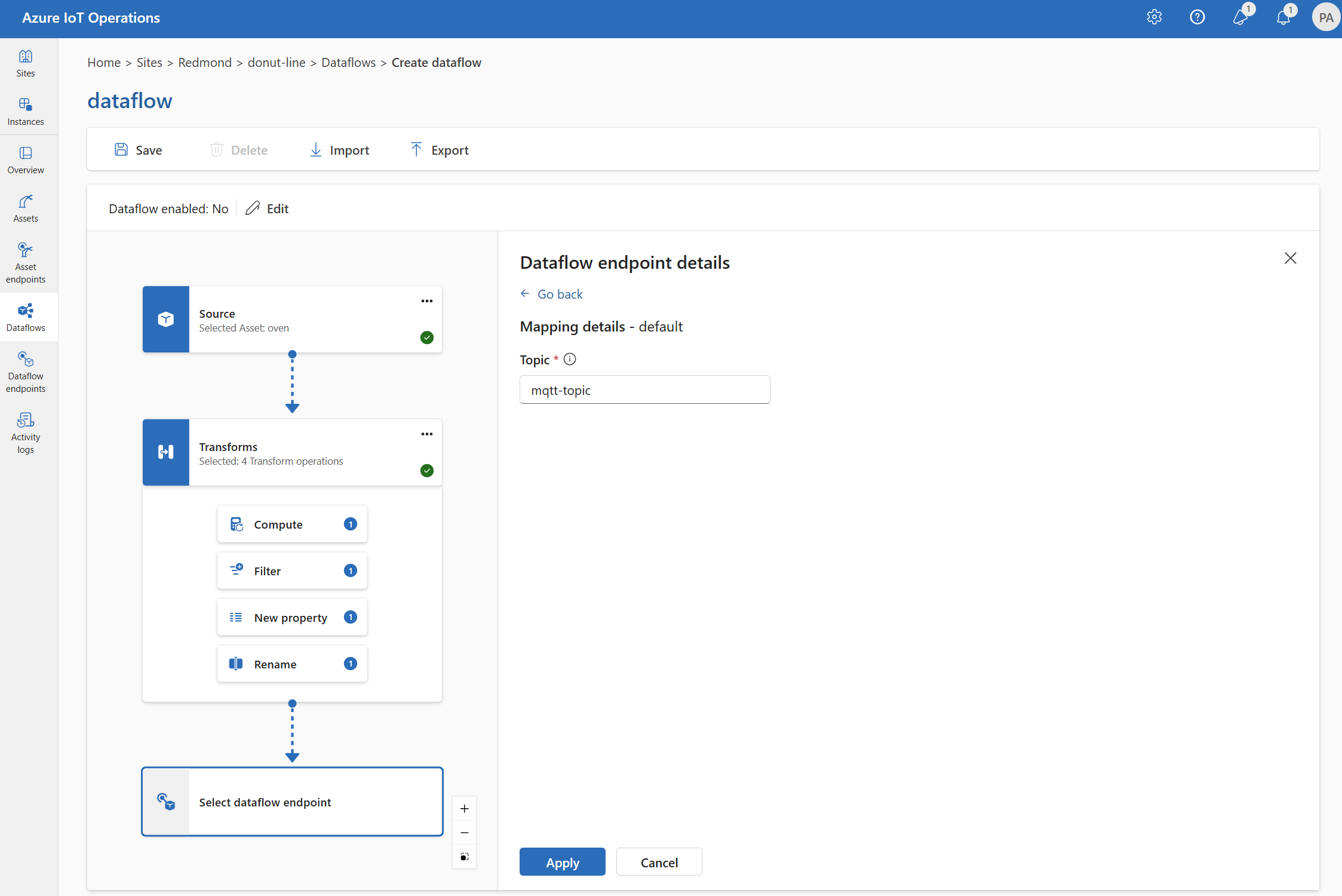
예시
다음 예제는 원본 및 대상에 MQTT 엔드포인트를 사용하는 데이터 흐름 구성입니다. 원본은 MQTT 토픽에서 데이터를 필터링합니다 azure-iot-operations/data/thermostat. 변환은 온도를 화씨로 변환하고 습도를 곱한 온도가 1000000보다 작은 데이터를 필터링합니다. 대상은 MQTT 토픽 factory으로 데이터를 보냅니다.
구성 예제는 Bicep 또는 Kubernetes 탭을 참조하세요.
데이터 흐름 구성의 더 많은 예제를 보려면 Azure REST API - 데이터 흐름 및 빠른 시작 Bicep을 참조하세요.
데이터 흐름이 작동하는지 확인
자습서: Azure Event Grid 에 양방향 MQTT 브리지를 연결하여 데이터 흐름이 작동하는지 확인합니다.
데이터 흐름 내보내기 구성
데이터 흐름 구성을 내보내려면 작업 환경을 사용하거나 데이터 흐름 사용자 지정 리소스를 내보낼 수 있습니다.
내보낼 데이터 흐름을 선택하고 도구 모음에서 내보내기를 선택합니다.
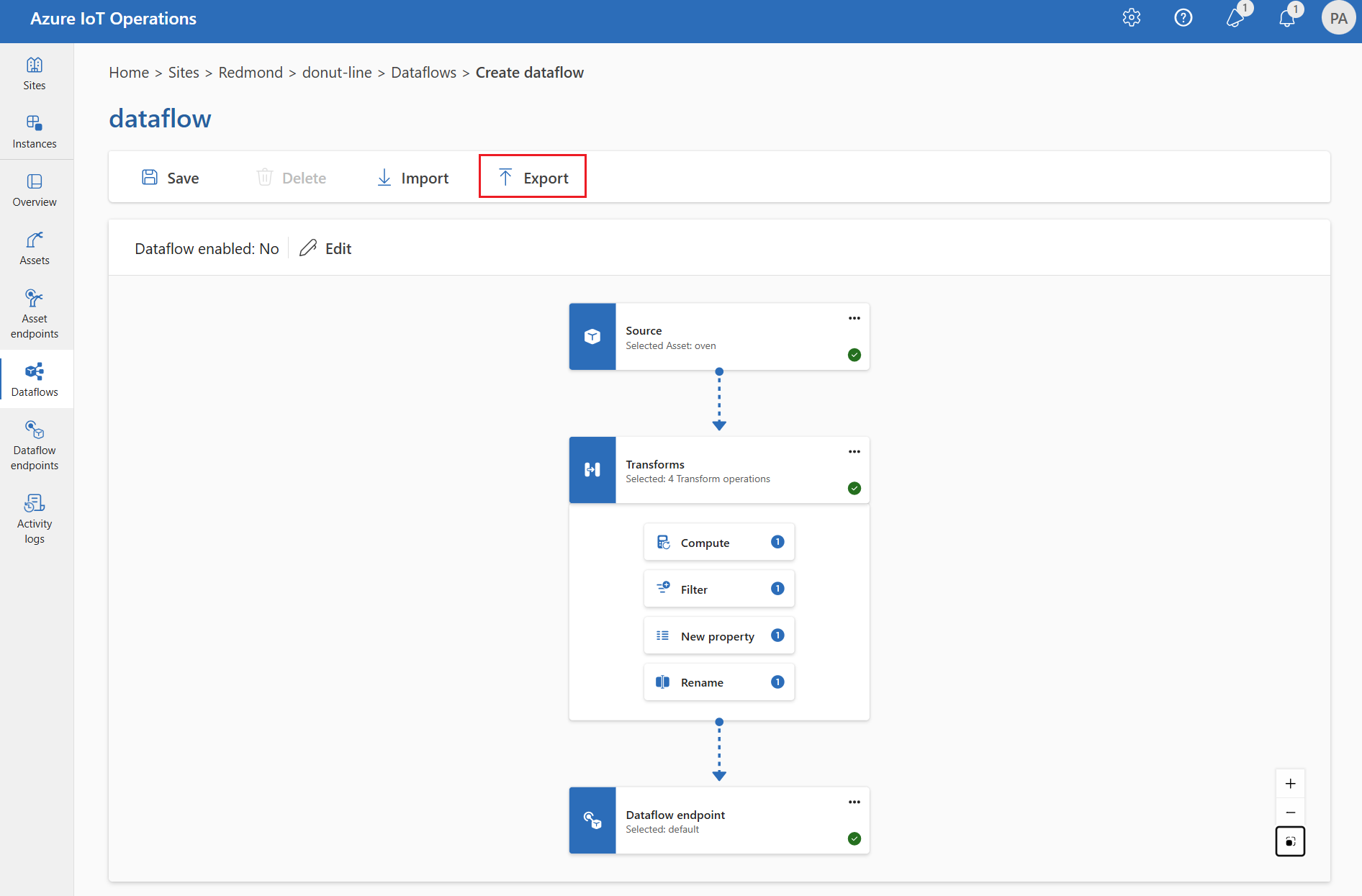
적절한 데이터 흐름 구성
데이터 흐름이 예상대로 작동하는지 확인하려면 다음을 확인합니다.
- 기본 MQTT 데이터 흐름 엔드포인트 는 원본 또는 대상으로 사용해야 합니다.
- 데이터 흐름 프로필이 존재하며 데이터 흐름 구성에서 참조됩니다.
- 원본은 MQTT 엔드포인트, Kafka 엔드포인트 또는 자산입니다. 스토리지 유형 엔드포인트는 원본으로 사용할 수 없습니다.
- Event Grid를 원본 으로 사용하는 경우 Event Grid MQTT 브로커는 공유 구독을 지원하지 않으므로 데이터 흐름 프로필 인스턴스 수가 1로 설정됩니다.
- Event Hubs를 원본으로 사용하는 경우 네임스페이스의 각 이벤트 허브는 별도의 Kafka 토픽이며 데이터 원본으로 지정해야 합니다.
- 변환은 사용되는 경우 특수 문자의 적절한 이스케이프를 포함하여 적절한 구문으로 구성됩니다.
- 스토리지 유형 엔드포인트를 대상으로 사용하는 경우 스키마가 지정됩니다.