Azure Logic Apps에서 표준 워크플로에 대한 콘텐츠 구문 분석 또는 청크(미리 보기)
적용 대상: Azure Logic Apps(표준)
Important
이 기능은 미리 보기로 제공되고 Microsoft Azure 미리 보기의 추가 사용 약관이 적용됩니다.
경우에 따라 콘텐츠를 단어 또는 문자 청크인 토큰으로 변환하거나 큰 문서를 더 작은 조각으로 나눠야만 이 콘텐츠를 일부 작업과 함께 사용할 수 있습니다. 예를 들어 Azure AI Search 또는 Azure OpenAI 작업은 토큰화된 입력을 예상하며 제한된 수의 토큰만 처리할 수 있습니다.
이러한 시나리오의 경우 표준 논리 앱 워크플로에서 문서 및 청크 텍스트 구문 분석이라는 데이터 작업 작업을 사용합니다. 이러한 작업은 각각 PDF 문서, CSV 파일, Excel 파일 등의 콘텐츠를 토큰화된 문자열 출력으로 변환한 다음 토큰 수에 따라 문자열을 조각으로 분할합니다. 그런 다음 워크플로에서 후속 작업과 함께 이러한 출력을 참조하고 사용할 수 있습니다.
팁
자세한 내용은 Azure Copilot에 다음 질문을 하면 됩니다.
- AI의 토큰이란?
- 토큰화된 입력이란?
- 토큰화된 문자열 출력이란?
- AI에서 구문 분석이란?
- AI의 청크 정의
Azure Copilot을 찾으려면 Azure Portal 도구 모음에서 Copilot을 선택합니다.
이 방법 가이드에서는 워크플로에서 이러한 작업을 추가하고 설정하는 방법을 보여 줍니다.
필수 조건
Azure 계정 및 구독 Azure 구독이 없는 경우 체험 Azure 계정에 등록합니다.
문서 구문 분석 및 청크 텍스트 작업은 작업으로만 사용할 수 있으므로 기존 트리거가 있는 표준 논리 앱 워크플로입니다. 구문 분석하거나 청크하려는 콘텐츠를 검색하는 작업이 이러한 데이터 작업보다 먼저 수행되는지 확인합니다.
문서 구문 분석
문서 구문 분석 작업은 PDF 문서, CSV 파일, Excel 파일 등의 콘텐츠를 토큰화된 문자열로 변환합니다. 이 예제에서는 워크플로가 HTTP 요청을 받을 때라는 요청 트리거로 시작한다고 가정합니다. 이 트리거는 Azure 함수, 다른 논리 앱 워크플로 등과 같은 다른 구성 요소에서 보낸 HTTP 요청을 받기 위해 대기합니다. HTTP 요청에는 워크플로에서 검색하고 구문 분석하는 데 사용할 수 있는 업로드된 새 문서의 URL이 포함됩니다. HTTP 작업은 트리거 바로 뒤에 와서 HTTP 요청을 문서의 URL로 보내고 해당 스토리지 위치에서 문서 콘텐츠와 함께 반환합니다.
Azure Blob Storage, SharePoint, OneDrive, 파일 시스템, FTP 등과 같은 다른 콘텐츠 원본을 사용하는 경우 이러한 원본에 트리거를 사용할 수 있는지 여부를 확인할 수 있습니다. 이러한 원본에 대한 콘텐츠를 검색하는 데 작업을 사용할 수 있는지 여부를 확인할 수도 있습니다. 자세한 내용은 기본 제공 작업 및 관리되는 커넥터를 참조하세요.
Azure Portal의 디자이너에서 표준 논리 앱 리소스 및 워크플로를 엽니다.
기존 트리거 및 작업에서 다음 일반적인 단계에 따라 문서 구문 분석이라는 데이터 작업 작업을 워크플로에 추가합니다.
디자이너에서 문서 구문 분석 작업을 선택합니다.
작업 정보 창이 열리면 [매개 변수] 탭의 [문서 콘텐츠 ] 속성에서 다음 단계를 수행하여 구문 분석할 콘텐츠를 지정합니다.
문서 콘텐츠 상자 내에서 선택합니다.
동적 콘텐츠 목록(번개 아이콘) 및 식 편집기(함수 아이콘)에 대한 옵션이 나타납니다.
이전 작업에서 출력을 선택하려면 동적 콘텐츠 목록을 선택합니다.
이전 작업의 출력을 조작하는 식을 만들려면 식 편집기를 선택합니다.
이 예제에서는 동적 콘텐츠 목록에 대한 번개 아이콘을 선택하여 계속합니다.
동적 콘텐츠 목록이 열리면 이전 작업에서 원하는 출력을 선택합니다.
이 예제에서 문서 구문 분석 작업은 HTTP 작업의 본문 출력을 참조합니다.

이제 본문 출력이 문서 콘텐츠 상자에 표시됩니다.

문서 구문 분석 작업 아래에서 토큰화된 문자열 출력으로 작업하려는 작업(예: 청크 텍스트)을 추가합니다. 이 가이드에서는 나중에 설명합니다.


문서 구문 분석 - 참조
매개 변수
| 속성 | 값 | 데이터 형식 | 설명 | 제한 |
|---|---|---|---|---|
| 문서 콘텐츠 | <콘텐츠-구문 분석> | 모두 | 구문 분석할 콘텐츠입니다. | None |
Outputs
| 속성 | 데이터 유형 | 설명 |
|---|---|---|
| 구문 분석된 결과 텍스트 | 문자열 ARRAY | 문자열 배열입니다. |
| 구문 분석된 결과 | Object | 구문 분석된 전체 텍스트를 포함하는 개체입니다. |
청크 텍스트
청크 텍스트 작업은 현재 워크플로에서 더 쉽게 사용할 수 있도록 후속 작업을 위해 콘텐츠를 더 작은 조각으로 분할합니다. 다음 단계는 문서 구문 분석 섹션의 예제를 기반으로 하며 토큰화된 작은 콘텐츠 청크를 예상하는 Azure AI 작업에 사용할 토큰 문자열 출력을 분할합니다.
참고 항목
청크를 사용하는 이전 작업은 청크 텍스트 작업에 영향을 주지 않으며 청크 텍스트 작업은 청크를 사용하는 후속 작업에도 영향을 주지 않습니다.
Azure Portal의 디자이너에서 표준 논리 앱 리소스 및 워크플로를 엽니다.
문서 구문 분석 작업 아래에서 다음 일반 단계에 따라 청크 텍스트라는 데이터 작업 작업을 추가합니다.
디자이너에서 청크 텍스트 동작을 선택합니다.
작업 정보 창이 열리면 매개 변수 탭의 청크 분할 전략 속성에 대해 아직 선택하지 않은 경우 TokenSize를 청크링 메서드로 선택합니다.
전략 설명 TokenSize 토큰 수에 따라 지정된 콘텐츠를 분할합니다. 전략을 선택한 후 텍스트 상자 내에서 선택하여 청크 분할에 대한 콘텐츠를 지정합니다.
동적 콘텐츠 목록(번개 아이콘) 및 식 편집기(함수 아이콘)에 대한 옵션이 나타납니다.
이전 작업에서 출력을 선택하려면 동적 콘텐츠 목록을 선택합니다.
이전 작업의 출력을 조작하는 식을 만들려면 식 편집기를 선택합니다.
이 예제에서는 동적 콘텐츠 목록에 대한 번개 아이콘을 선택하여 계속합니다.
동적 콘텐츠 목록이 열리면 이전 작업에서 원하는 출력을 선택합니다.
이 예제에서 청크 텍스트 작업은 문서 구문 분석 작업의 구문 분석 결과 텍스트 출력을 참조합니다.
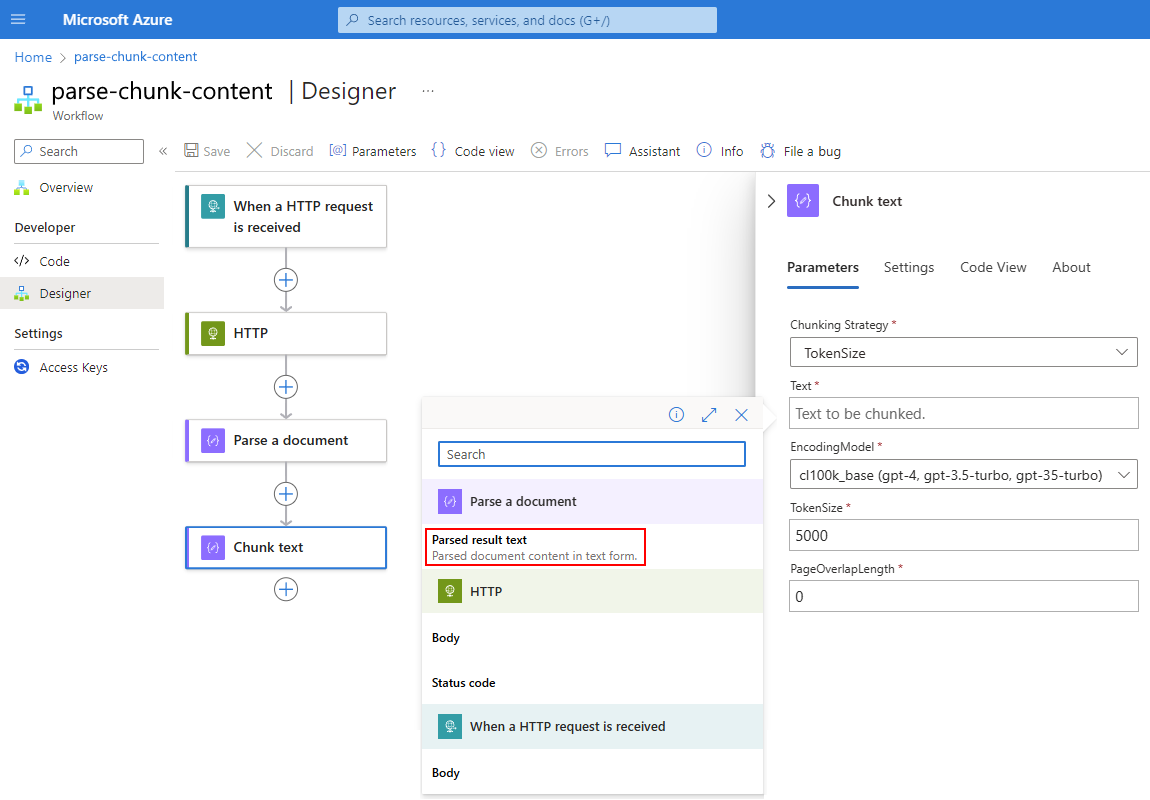
이제 구문 분석된 결과 작업 출력이 텍스트 상자에 표시됩니다.

선택한 전략 및 시나리오에 따라 청크 텍스트 작업에 대한 설정을 완료합니다. 자세한 내용은 청크 텍스트 - 참조를 참조 하세요.


이제 Azure AI 작업과 같이 토큰화된 입력을 예상 및 사용하는 다른 작업을 추가하면 입력 콘텐츠의 형식이 더 쉽게 지정됩니다.
청크 텍스트 - 참조
매개 변수
| 속성 | 값 | 데이터 형식 | 설명 | 제한 |
|---|---|---|---|---|
| 청크 분할 전략 | TokenSize | 문자열 열거형 | 토큰 수에 따라 콘텐츠를 분할합니다. 기본값: TokenSize |
해당 없음 |
| Text | <콘텐츠-청크> | 모두 | 청크할 콘텐츠입니다. | 제한 및 구성 참조 가이드 참조 |
| EncodingModel | <encoding-method> | 문자열 열거형 | 사용할 인코딩 모델: - 기본값: cl100k_base(gpt4, gpt-3.5-turbo, gpt-35-turbo) - r50k_base(gpt-3) - p50k_base(gpt-3) - p50k_edit(gpt-3) - cl200k_base(gpt-4o) 자세한 내용은 OpenAI - 모델 개요를 참조하세요. |
해당 없음 |
| TokenSize | <max-tokens-per-chunk> | 정수 | 콘텐츠 청크당 최대 토큰 수입니다. 기본값: None |
최소: 1 최대: 8000 |
| PageOverlapLength | <겹치는 문자 수> | 정수 | 다음 청크에 포함할 이전 청크 끝의 문자 수입니다. 이 설정을 사용하면 콘텐츠를 청크로 분할할 때 중요한 정보가 손실되는 것을 방지하고 청크 간에 연속성과 컨텍스트를 유지할 수 있습니다. 기본값: 0 - 겹치는 문자가 없습니다. |
최소: 0 |
팁
자세한 내용은 Azure Copilot에 다음 질문을 하면 됩니다.
- 청크에서 PageOverlapLength란?
- Azure AI의 인코딩이란?
Azure Copilot을 찾으려면 Azure Portal 도구 모음에서 Copilot을 선택합니다.
Outputs
| 속성 | 데이터 유형 | 설명 |
|---|---|---|
| 청크 결과 텍스트 항목 | 문자열 ARRAY | 문자열 배열입니다. |
| 청크 결과 텍스트 항목 항목 | 문자열 | 배열의 단일 문자열입니다. |
| 청크 결과 | Object | 전체 청크 텍스트가 들어 있는 개체입니다. |
예시 워크플로
다음 예제에는 모든 원본에서 데이터를 수집하는 전체 워크플로 패턴을 만드는 다른 작업이 포함되어 있습니다.

| Step | 작업 | 기본 작업 | 설명 |
|---|---|---|---|
| 1 | 새 콘텐츠를 기다리거나 확인합니다. | HTTP 요청이 수신되는 경우 | 예약된 되풀이 또는 특정 이벤트에 대한 응답으로 새 데이터가 도착할 때까지 폴링하거나 기다리는 트리거입니다. 이러한 이벤트는 Azure Blob Storage, SharePoint, OneDrive, 파일 시스템, FTP 등과 같은 특정 스토리지 시스템에 업로드되는 새 파일일 수 있습니다. 이 예제 에서 요청 트리거 작업은 다른 엔드포인트에서 보낸 HTTP 또는 HTTPS 요청을 기다립니다. 요청에는 업로드된 새 문서의 URL이 포함됩니다. |
| 2 | 콘텐츠를 가져옵니다. | HTTP | 트리거 출력에서 파일 URL을 사용하여 업로드된 문서를 검색하는 HTTP 작업입니다. |
| 3 | 문서 세부 정보를 작성합니다. | Compose | 다양한 항목을 연결하는 데이터 작업 작업입니다. 다음은 문서에 대한 키-값 정보를 연결하는 예제입니다. |
| 4 | 토큰 문자열을 만듭니다. | 문서 구문 분석 | 작성 작업의 출력을 사용하여 토큰화된 문자열을 생성하는 데이터 작업 작업입니다. |
| 5 | 콘텐츠 청크를 만듭니다. | 청크 텍스트 | 콘텐츠 청크당 토큰 수에 따라 토큰 문자열을 조각으로 분할하는 데이터 작업 작업입니다. |
| 6 | 토큰화된 텍스트와 청크 분할된 텍스트를 JSON으로 변환합니다. | JSON 구문 분석 | 청크 분할된 출력을 JSON 배열로 변환하는 데이터 작업 작업입니다. |
| 7 | JSON 배열 항목을 선택합니다. | 선택 | JSON 배열에서 여러 항목을 선택하는 데이터 작업 작업입니다. |
| 8 | 포함을 생성합니다. | 여러 포함 가져오기 | 각 JSON 배열 항목에 대한 포함을 만드는 Azure OpenAI 작업입니다. |
| 9 | 포함 및 기타 정보를 선택합니다. | 선택 | 포함 및 기타 문서 정보를 선택하는 데이터 작업 작업입니다. |
| 10 | 데이터를 인덱싱합니다. | 문서 인덱싱 | 선택한 각 포함을 기반으로 데이터를 인덱싱하는 Azure AI Search 작업입니다. |