MLflow 및 Azure Machine Learning으로 Azure Databricks 기계 학습 실험 추적
MLflow는 기계 학습 실험의 수명 주기를 관리하기 위한 오픈 소스 라이브러리입니다. MLflow를 사용하여 Azure Databricks를 Azure Machine Learning과 통합하여 두 제품 모두에서 최상의 결과를 얻을 수 있습니다.
이 문서에서는 다음에 대해 알아봅니다.
- Azure Databricks 및 Azure Machine Learning에서 MLflow를 사용하는 데 필요한 필수 라이브러리입니다.
- Azure Machine Learning에서 MLflow를 사용하여 Azure Databricks 실행을 추적하는 방법입니다.
- MLflow로 모델을 기록하여 Azure Machine Learning에 등록하는 방법입니다.
- Azure Machine Learning에 등록된 모델을 배포하고 사용하는 방법입니다.
필수 조건
azureml-mlflow패키지는 인증을 포함하여 Azure Machine Learning과의 연결을 처리합니다.- Azure Databricks 작업 영역 및 클러스터
- Azure Machine Learning 작업 영역.
작업 영역을 사용하여 MLflow 작업을 수행하는 데 필요한 액세스 권한을 확인하세요.
예제 Notebook
Azure Databricks에서 모델 학습 및 Azure Machine Learning에 배포 레지스트리는 Azure Databricks에서 모델을 학습하고 Azure Machine Learning에 배포하는 방법을 보여 줍니다. 또한 Azure Databricks에서 MLflow 인스턴스를 사용하여 실험 및 모델을 추적하는 방법도 설명합니다. 배포에 Azure Machine Learning을 사용하는 방법을 설명합니다.
라이브러리 설치
클러스터에 라이브러리를 설치하려면 다음을 수행합니다.
라이브러리 탭으로 이동하고 새로 설치를 선택합니다.
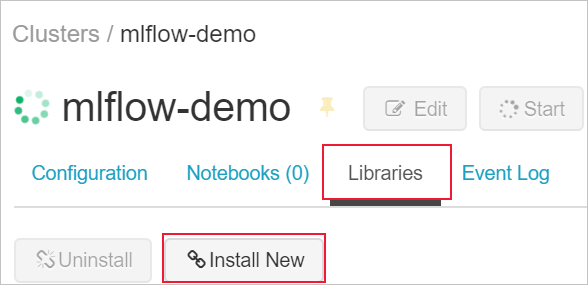
패키지 필드에 azureml-mlflow를 입력한 다음, 설치를 선택합니다. 필요에 따라 이 단계를 반복하여 실험을 위한 클러스터에 다른 패키지를 설치합니다.
MLflow를 사용하여 Azure Databricks 실행 추적
다음 두 가지 방법으로 MLflow를 사용하여 실험을 추적하도록 Azure Databricks를 구성할 수 있습니다.
기본적으로 Azure Databricks 작업 영역을 연결할 때 이중 추적이 구성됩니다.
Azure Databricks 및 Azure Machine Learning의 이중 추적
Azure Databricks 작업 영역을 Azure Machine Learning 작업 영역에 연결하면 Azure Machine Learning 작업 영역 및 Azure Databricks 작업 영역에서 동시에 실험 데이터를 추적할 수 있습니다. 이 구성을 이중 추적이라고 합니다.
프라이빗 링크 사용 Azure Machine Learning 작업 영역 의 이중 추적은 아웃바운드 규칙 구성 또는 Azure Databricks가 사용자 고유의 네트워크(VNet 삽입)에 배포되었는지 여부에 관계없이 현재 지원되지 않습니다. 대신 Azure Machine Learning 작업 영역을 사용하여 단독 추적을 구성합니다. 이것이 VNet 삽입을 의미하지는 않습니다.
이중 추적은 현재 21Vianet에서 운영하는 Microsoft Azure에서 지원되지 않습니다. 대신 Azure Machine Learning 작업 영역을 사용하여 단독 추적을 구성합니다.
Azure Databricks 작업 영역을 신규 또는 기존 Azure Machine Learning 작업 영역에 연결하려면 다음을 수행합니다.
Azure Portal에 로그인합니다.
Azure Databricks 작업 영역 개요 페이지로 이동합니다.
Azure Machine Learning 작업 영역 연결을 선택합니다.


Azure Databricks 작업 영역을 Azure Machine Learning 작업 영역에 연결하면 MLflow 추적이 다음 위치에서 자동으로 추적됩니다.
- 연결된 Azure Machine Learning 작업 영역
- 원래 Azure Databricks 작업 영역입니다.
원래 사용했던 것과 동일한 방식으로 Azure Databricks에서 MLflow를 사용할 수 있습니다. 다음 예제에서는 Azure Databricks에서 평소와 같이 실험 이름을 설정하고 일부 매개 변수 로깅을 시작합니다.
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
참고 항목
추적과 반대로 모델 레지스트리는 Azure Machine Learning 및 Azure Databricks에서 동시에 모델 등록을 지원하지 않습니다. 자세한 내용은 MLflow를 사용하여 레지스트리에서 모델 등록을 참조하세요.
Azure Machine Learning 작업 영역에서만 추적
중앙 위치에서 추적된 실험을 관리하려는 경우 Azure Machine Learning 작업 영역에서만 추적하도록 MLflow 추적을 설정할 수 있습니다. 이 구성은 Azure Machine Learning 배포 옵션을 사용하여 더 쉬운 배포 경로를 사용하도록 설정할 수 있다는 장점이 있습니다.
Warning
프라이빗 링크가 활성화된 Azure Machine Learning 작업 영역의 경우 적절한 연결을 보장하기 위해 자체 네트워크(VNet 삽입)에 Azure Databricks를 배포해야 합니다.
다음 예제와 같이 Azure Machine Learning만 가리키도록 MLflow 추적 URI를 구성합니다.
추적 URI 구성
작업 영역에 대한 추적 URI를 가져옵니다.
적용 대상:
 Azure CLI ml 확장 v2(현재)
Azure CLI ml 확장 v2(현재)작업 영역에 로그인하고 구성합니다.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>az ml workspace명령을 사용하여 추적 URI를 가져올 수 있습니다.az ml workspace show --query mlflow_tracking_uri
추적 URI를 구성합니다.
set_tracking_uri()메서드는 MLflow 추적 URI로 해당 URI를 가리킵니다.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)
팁
Azure Databricks 클러스터, Azure Synapse Analytics 클러스터 등과 같은 공유 환경으로 작업하는 경우 클러스터 수준에서 MLFLOW_TRACKING_URI 환경 변수를 설정할 수 있습니다. 이 방법을 사용하면 세션별로 수행하지 않고 클러스터에서 실행되는 모든 세션에 대해 Azure Machine Learning을 가리키도록 MLflow 추적 URI를 자동으로 구성할 수 있습니다.
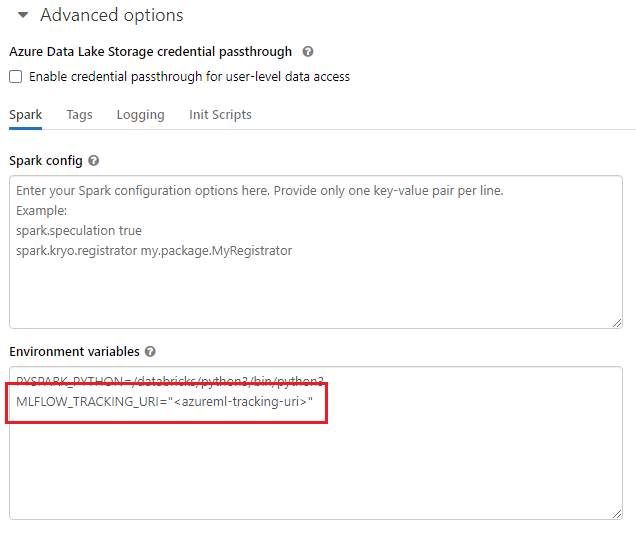
환경 변수를 구성한 후에는 해당 클러스터에서 실행 중인 모든 실험이 Azure Machine Learning에서 추적됩니다.
인증 구성
추적을 구성한 후 연결된 작업 영역에 인증하는 방법을 구성합니다. 기본적으로 MLflow용 Azure Machine Learning 플러그 인은 대화형으로 자격 증명을 요청하는 브라우저를 엽니다. Azure Machine Learning 작업 영역에서 MLflow에 대한 인증을 구성하는 다른 방법은 Azure Machine Learning용 MLflow 구성: 인증 구성을 참조하세요.
세션에 연결된 사용자가 있는 대화형 작업의 경우 대화형 인증을 사용할 수 있습니다. 추가적인 조치가 필요하지 않습니다.
Warning
대화형 브라우저 인증은 자격 증명을 묻는 메시지가 표시되면 코드 실행을 차단합니다. 이 방법은 학습 작업과 같은 무인 환경에서 인증에 적합하지 않습니다. 이러한 환경에서 다른 인증 모드를 구성하는 것이 좋습니다.
무인 실행이 필요한 시나리오의 경우 Azure Machine Learning과 통신하도록 서비스 주체를 구성해야 합니다. 서비스 주체를 만드는 방법에 대한 자세한 내용은 서비스 주체 구성을 참조하세요.
다음 코드에서 서비스 주체의 테넌트 ID, 클라이언트 ID 및 클라이언트 암호를 사용합니다.
import os
os.environ["AZURE_TENANT_ID"] = "<Azure-tenant-ID>"
os.environ["AZURE_CLIENT_ID"] = "<Azure-client-ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<Azure-client-secret>"
팁
공유 환경에서 작업하는 경우 컴퓨팅 수준에서 이러한 환경 변수를 구성하는 것이 좋습니다. 가능한 경우 Azure Key Vault 인스턴스에서 비밀로 관리하세요.
예를 들어 Azure Databricks 클러스터 구성에서 다음과 같은 방법으로 AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}환경 변수의 비밀을 사용할 수 있습니다. Azure Databricks에서 이 방법을 구현하는 방법에 대한 자세한 내용은 환경 변수에서 비밀 참조를 참조하거나 플랫폼에 대한 설명서를 참조하세요.
Azure Machine Learning에서 실험 명명
Azure Machine Learning 작업 영역에서만 실험을 추적하도록 MLflow를 구성하는 경우 실험 명명 규칙은 Azure Machine Learning이 사용하는 규칙을 따라야 합니다. Azure Databricks에서 실험의 이름은 실험이 저장되는 경로를 사용하여 지정됩니다(예: /Users/alice@contoso.com/iris-classifier). 그러나 Azure Machine Learning에서는 실험 이름을 직접 제공합니다. 동일한 실험에 iris-classifier라는 이름이 직접 지정됩니다.
mlflow.set_experiment(experiment_name="experiment-name")
추적 매개 변수, 메트릭, 아티팩트
이 구성 후에는 사용하던 것과 동일한 방식으로 Azure Databricks에서 MLflow를 사용할 수 있습니다. 자세한 내용은 메트릭과 로그 파일 로그 및 보기를 참조하세요.
MLflow를 사용하여 모델 로그
모델이 학습되면 mlflow.<model_flavor>.log_model() 메서드를 사용하여 추적 서버에 모델을 로그할 수 있습니다. <model_flavor>는 모델과 연결된 프레임워크를 나타냅니다. 지원되는 모델 종류에 대해 알아봅니다.
다음 예제에서는 Spark 라이브러리 MLLib로 만든 모델이 등록됩니다.
mlflow.spark.log_model(model, artifact_path = "model")
spark 버전은 Spark 클러스터에서 모델을 학습한다는 사실과 일치하지 않습니다. 대신 사용된 학습 프레임워크를 따릅니다. Spark에서 TensorFlow를 사용하여 모델을 학습시킬 수 있습니다. 사용할 버전은 tensorflow입니다.
모델은 추적 중인 실행 내부에 로그됩니다. 즉, Azure Databricks 및 Azure Machine Learning(기본값)에서 또는 Azure Machine Learning에서 단독으로 모델을 사용할 수 있습니다(이를 가리키도록 추적 URI를 구성한 경우).
Important
registered_model_name 매개 변수가 지정되지 않았습니다. 이 매개 변수 및 레지스트리에 대한 자세한 내용은 MLflow를 사용하여 레지스트리에 모델 등록을 참조하세요.
MLflow를 사용하여 레지스트리에 모델 등록
추적과 반대로, 모델 레지스트리는 Azure Databricks 및 Azure Machine Learning에서 동시에 작동할 수 없습니다. 둘 중 하나만 사용해야 합니다. 기본적으로 모델 레지스트리는 Azure Databricks 작업 영역을 사용합니다. Azure Machine Learning 작업 영역에서만 추적하도록 MLflow 추적을 설정하도록 선택하는 경우 모델 레지스트리는 Azure Machine Learning 작업 영역입니다.
기본 구성을 사용하는 경우 다음 코드는 Azure Databricks 및 Azure Machine Learning 모두의 해당 실행 내에 모델을 로그하지만 Azure Databricks에만 모델을 등록합니다.
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
- 이름이 있는 등록 모델이 없는 경우 이 메서드는 새 모델을 등록하고, 버전 1을 만들고
ModelVersionMLflow 개체를 반환합니다. - 이름이 있는 등록 모델이 이미 있는 경우 이 메서드는 새 모델 버전을 만들고 버전 개체를 반환합니다.
MLflow에서 Azure Machine Learning 레지스트리 사용
Azure Databricks 대신 Azure Machine Learning 모델 레지스트리를 사용하려는 경우 Azure Machine Learning 작업 영역에서만 추적하도록 MLflow 추적을 설정하는 것이 좋습니다. 이 방법은 모델이 등록되는 위치의 모호성을 제거하고 구성을 간소화합니다.
이중 추적 기능을 계속 사용하되 모델을 Azure Machine Learning에 등록하려면 MLflow 모델 레지스트리 URI를 구성하여 모델 레지스트리에 Azure Machine Learning을 사용하도록 MLflow에 지시할 수 있습니다. 이 URI는 URI를 추적하는 MLflow와 동일한 형식과 값을 사용합니다.
mlflow.set_registry_uri(azureml_mlflow_uri)
참고 항목
azureml_mlflow_uri 값은 Azure Machine Learning 작업 영역에서만 추적하도록 MLflow 추적 설정에서 설명한 것과 동일한 방식으로 가져왔습니다.
이 시나리오의 전체 예제는 Azure Databricks에서 모델 학습 및 Azure Machine Learning에 배포를 참조하세요.
Azure Machine Learning에 등록된 모델 배포 및 사용
MLflow를 통해 Azure Machine Learning Service에 등록된 모델을 다음과 같이 사용할 수 있습니다.
- Azure Machine Learning 엔드포인트(실시간 및 일괄 처리). 이 배포를 사용하면 Azure Container Instances, Azure Kubernetes 또는 관리형 유추 엔드포인트에서 실시간 및 일괄 처리 유추 모두에 Azure Machine Learning 배포 기능을 사용할 수 있습니다.
- 스트리밍 또는 일괄 처리 파이프라인의 Azure Databricks Notebook에서 사용할 수 있는 MLFlow 모델 개체 또는 Pandas UDF(사용자 정의 함수).
Azure Machine Learning 엔드포인트에 모델 배포
azureml-mlflow 플러그 인을 사용하여 Azure Machine Learning 작업 영역에 모델을 배포할 수 있습니다. 다양한 대상에 모델을 배포하는 방법에 대한 자세한 내용은 MLflow 모델을 배포하는 방법.
Important
모델을 배포하려면 Azure Machine Learning 레지스트리에 등록해야 합니다. 모델이 Azure Databricks 내의 MLflow 인스턴스에 등록된 경우 Azure Machine Learning에 다시 등록합니다. 자세한 내용은 Azure Databricks에서 모델 학습 및 Azure Machine Learning에 배포를 참조하세요.
UDF를 사용하여 일괄 처리 채점을 위해 Azure Databricks에 모델 배포
일괄 처리 점수 매기기를 위해 Azure Databricks 클러스터를 선택할 수 있습니다. Mlflow를 사용하여 연결된 레지스트리에서 모델을 확인할 수 있습니다. 일반적으로 다음 방법 중 하나를 사용합니다.
- 모델을 Spark 라이브러리(예:
MLLib)로 학습 및 빌드한 경우mlflow.pyfunc.spark_udf를 사용하여 모델을 로드하고 이를 Spark Pandas UDF로 사용하여 새 데이터의 점수를 매깁니다. - 모델이 Spark 라이브러리를 사용하여 학습되거나 빌드되지 않은 경우
mlflow.pyfunc.load_model또는mlflow.<flavor>.load_model을 사용하여 클러스터 드라이버에 모델을 로드합니다. 클러스터에서 수행하려는 병렬 처리 또는 작업 배포를 오케스트레이션해야 합니다. MLflow는 모델을 실행하는 데 필요한 라이브러리를 설치하지 않습니다. 이러한 라이브러리는 클러스터를 실행하기 전에 클러스터에 설치해야 합니다.
다음 예제에서는 uci-heart-classifier라는 레지스트리에서 모델을 로드하고 이를 Spark Pandas UDF로 사용하여 새 데이터의 점수를 매기는 방법을 보여 줍니다.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
레지스트리에서 모델을 참조하는 더 많은 방법은 레지스트리에서 모델 로드를 참조하세요.
모델을 로드한 후 이 명령을 사용하여 새 데이터의 점수를 매깁니다.
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
리소스 정리
Azure Databricks 작업 영역을 유지하려 하지만 더 이상 Azure Machine Learning 작업 영역이 필요하지 않은 경우 Azure Machine Learning 작업 영역을 삭제할 수 있습니다. 이 작업을 수행하면 Azure Databricks 작업 영역과 Azure Machine Learning 작업 영역의 연결이 해제됩니다.
작업 영역에서 로그된 메트릭 및 아티팩트를 사용할 계획이 없는 경우 스토리지 계정 및 작업 영역이 포함된 리소스 그룹을 삭제합니다.
- Azure Portal에서 리소스 그룹을 검색합니다. 서비스에서 리소스 그룹을 선택합니다.
- 리소스 그룹 목록에서 만든 리소스 그룹을 찾아 선택하여 엽니다.
- 개요 페이지에서 리소스 그룹 삭제를 선택합니다.
- 삭제를 확인하려면 리소스 그룹의 이름을 입력합니다.