모델을 온라인 엔드포인트로 배포
적용 대상:  Python SDK azure-ai-ml v2(현재)
Python SDK azure-ai-ml v2(현재)
Azure Machine Learning Python SDK v2를 사용하여 온라인 엔드포인트에 모델을 배포하는 방법을 알아봅니다.
이 자습서에서는 고객이 신용 카드 결제를 불이행할 가능성을 예측하는 모델을 배포하고 사용합니다.
수행할 단계는 다음과 같습니다.
- 장치 등록
- 엔드포인트 및 첫 번째 배포 만들기
- 시험 실행 배포
- 배포에 테스트 데이터를 수동으로 보내기
- 배포 세부 정보 가져오기
- 두 번째 배포 만들기
- 두 번째 배포를 수동으로 크기 조정
- 두 배포 간의 프로덕션 트래픽 할당 업데이트
- 두 번째 배포에 대한 세부 정보 가져오기
- 새 배포를 롤아웃하고 첫 번째 배포를 삭제합니다.
이 동영상에서는 자습서의 단계를 따를 수 있도록 Azure Machine Learning 스튜디오를 시작하는 방법을 보여 줍니다. 동영상에서는 Notebook을 만들고, 컴퓨팅 인스턴스를 만들고, Notebook을 복제하는 방법을 보여 줍니다. 해당 단계는 다음 섹션에서도 설명됩니다.
필수 조건
-
Azure Machine Learning을 사용하려면 작업 영역이 필요합니다. 작업 영역이 없으면 시작하는 데 필요한 리소스 만들기를 완료하여 작업 영역을 만들고 사용 방법에 대해 자세히 알아봅니다.
Important
Azure Machine Learning 작업 영역이 관리형 가상 네트워크로 구성된 경우 공용 Python 패키지 리포지토리에 대한 액세스를 허용하도록 아웃바운드 규칙을 추가해야 할 수 있습니다. 자세한 내용은 시나리오: 공용 기계 학습 패키지에 액세스합니다.
-
아직 열려 있지 않은 경우 스튜디오에 로그인하고 작업 영역을 선택합니다.
-
작업 영역에서 Notebook을 열거나 만듭니다.
VM 할당량을 보고 온라인 배포를 만드는 데 사용할 수 있는 할당량이 충분한지 확인합니다. 이 자습서에서는
STANDARD_DS3_v2의 코어가 최소 8개,STANDARD_F4s_v2의 코어가 12개 필요합니다. VM 할당량 사용량을 확인하고 할당량 증가를 요청하려면 리소스 할당량 관리를 참조하세요.
커널을 설정하고 VS Code(Visual Studio Code)에서 엽니다.
아직 컴퓨팅 인스턴스가 없는 경우 열린 Notebook 위 상단 표시줄에서 컴퓨팅 인스턴스를 만듭니다.

컴퓨팅 인스턴스가 중지된 경우 컴퓨팅 시작을 선택하고 실행될 때까지 기다립니다.

컴퓨팅 인스턴스가 실행될 때까지 기다립니다. 그런 다음 오른쪽
Python 3.10 - SDK v2위에 있는 커널이 .인지 확인합니다. 그렇지 않은 경우 드롭다운 목록을 사용하여 이 커널을 선택합니다.
이 커널이 표시되지 않으면 컴퓨팅 인스턴스가 실행 중인지 확인합니다. 이 경우 전자 필기장 오른쪽 위에 있는 새로 고침 단추를 선택합니다.
인증이 필요하다는 배너가 표시되면 인증을 선택합니다.
여기서 Notebook을 실행하거나 Azure Machine Learning 리소스의 기능을 갖춘 전체 IDE(통합 개발 환경)를 위해 VS Code에서 열 수 있습니다. VS Code에서 열기를 선택한 다음 웹 또는 데스크톱 옵션을 선택합니다. 이러한 방식으로 시작하면 VS Code가 컴퓨팅 인스턴스, 커널 및 작업 영역 파일 시스템에 연결됩니다.





Important
이 자습서의 나머지 부분에는 자습서 Notebook의 셀이 포함되어 있습니다. 새 전자 필기장을 복사하여 붙여넣거나 복제한 경우 지금 전자 필기장으로 전환합니다.
참고 항목
- 서버리스 Spark 컴퓨팅에는 기본적으로
Python 3.10 - SDK v2가 설치되어 있지 않습니다. 자습서를 진행하기 전에 사용자가 컴퓨팅 인스턴스를 만들고 선택하는 것이 좋습니다.
작업 영역에 대한 핸들 만들기
코드에 들어가기 전에 작업 영역을 참조할 방법이 필요합니다. 작업 영역에 대한 핸들로 ml_client를 만들고 ml_client를 사용하여 리소스와 작업을 관리합니다.
다음 셀에 구독 ID, 리소스 그룹 이름 및 작업 영역 이름을 입력합니다. 이러한 값을 찾으려면 다음을 수행합니다.
- 오른쪽 위 Azure Machine Learning 스튜디오 도구 모음에서 작업 영역 이름을 선택합니다.
- 작업 영역, 리소스 그룹 및 구독 ID의 값을 코드에 복사합니다.
- 하나의 값을 복사하고 해당 영역을 닫고 붙여넣은 후 다음 값으로 돌아와야 합니다.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
참고 항목
MLClient를 만들면 작업 영역에 연결되지 않습니다. 클라이언트 초기화가 지연되어 처음 호출이 필요할 때까지 기다립니다(이는 다음 코드 셀에서 발생합니다).
모델 등록
이전 학습 자습서인 모델 학습을 이미 완료했다면 MLflow 모델을 학습 스크립트의 일부로 등록했으며 다음 섹션으로 건너뛸 수 있습니다.
학습 자습서를 완료하지 않은 경우 모델을 등록해야 합니다. 배포하기 전에 모델을 등록하는 것이 권장되는 모범 사례입니다.
다음 코드는 path(파일을 업로드할 위치)을 인라인으로 지정합니다. 자습서 폴더를 복제한 경우 다음 코드를 그대로 실행합니다. 그렇지 않으면 credit_defaults_model 폴더에서 모델에 대한 파일 및 메타데이터를 다운로드합니다. 다운로드한 파일을 컴퓨터의 credit_defaults_model 폴더의 로컬 버전에 저장하고 다음 코드의 경로를 다운로드한 파일의 위치로 업데이트합니다.
SDK는 자동으로 파일을 업로드하고 모델을 등록합니다.
모델을 자산으로 등록하는 방법에 대한 자세한 내용은 SDK를 사용하여 Machine Learning에서 모델을 자산으로 등록을 참조하세요.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
모델이 등록되었는지 확인합니다.
Azure Machine Learning 스튜디오의 모델 페이지에서 등록된 모델의 최신 버전을 확인할 수 있습니다.
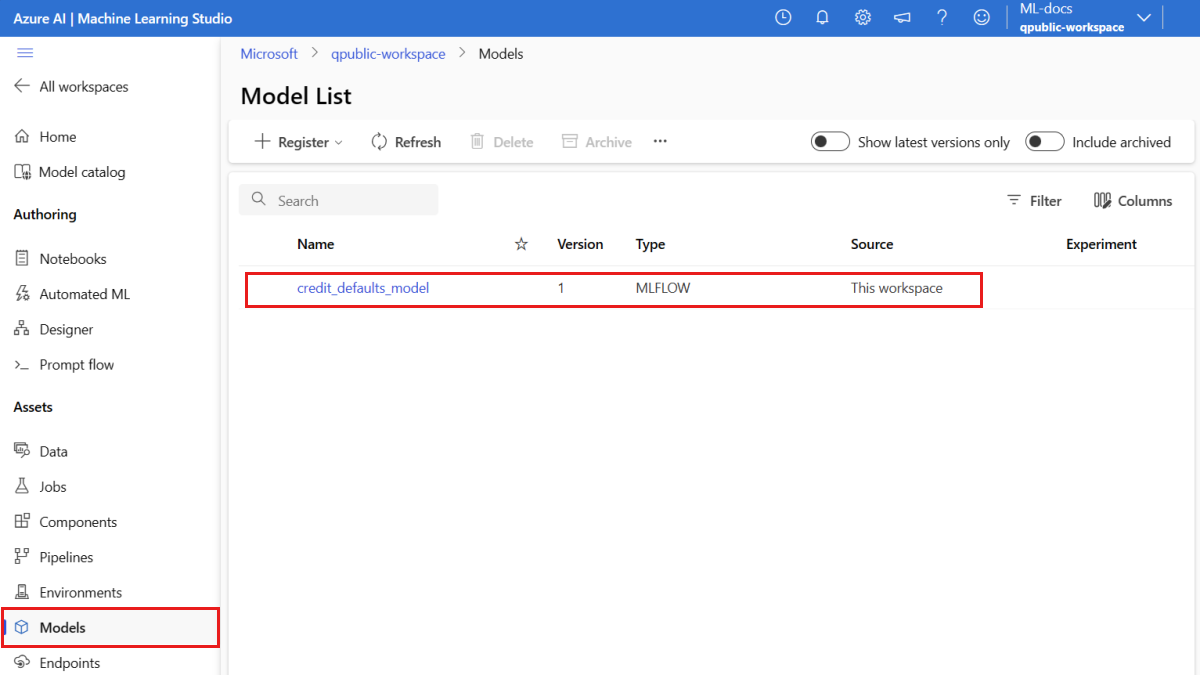
또는 다음 코드는 사용할 수 있는 최신 버전 번호를 검색합니다.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
이제 등록된 모델이 있으므로 엔드포인트 및 배포를 만들 수 있습니다. 다음 섹션에서는 이 항목에 대한 몇 가지 주요 세부 정보를 간략하게 다룹니다.
엔드포인트 및 배포
기계 학습 모델을 학습한 후에는 다른 사람이 유추에 사용할 수 있도록 배포해야 합니다. 이를 위해 Azure Machine Learning을 사용하면 엔드포인트를 만들고 여기에 배포를 추가할 수 있습니다.
이 컨텍스트에서 엔드포인트는 클라이언트가 학습된 모델에 요청(입력 데이터)을 보내고 모델에서 유추(점수) 결과를 받을 수 있는 인터페이스를 제공하는 HTTPS 경로입니다. 엔드포인트는 다음을 제공합니다.
- "키 또는 토큰" 기반 인증을 사용한 인증
- TLS(SSL) 종료
- 안정적인 채점 URI(endpoint-name.region.inference.ml.azure.com)
배포는 실제 유추를 수행하는 모델을 호스팅하는 데 필요한 리소스의 세트입니다.
단일 엔드포인트는 여러 배포를 포함할 수 있습니다. 엔드포인트 및 배포는 Azure Portal에 표시되는 독립적인 Azure Resource Manager 리소스입니다.
Azure Machine Learning을 사용하면 클라이언트 데이터에 대한 실시간 유추를 위한 온라인 엔드포인트와 일정 기간 동안 대량의 데이터에 대한 유추를 위한 일괄 처리 엔드포인트를 구현할 수 있습니다.
이 자습서에서는 관리형 온라인 엔드포인트를 구현하는 단계를 살펴보겠습니다. 관리되는 온라인 엔드포인트는 기본 배포 인프라를 설정하고 관리하는 오버헤드에서 벗어나 확장 가능한 완전 관리되는 방식으로 Azure의 강력한 CPU 및 GPU 컴퓨터와 함께 작동합니다.
온라인 엔드포인트 만들기
이제 등록된 모델이 있으므로 온라인 엔드포인트를 만들 차례입니다. 엔드포인트 이름은 전체 Azure 지역에서 고유해야 합니다. 이 자습서에서는 UUID(Universally Unique Identifier) UUID를 사용하여 고유 이름을 만듭니다. 엔드포인트 명명 규칙에 대한 자세한 내용은 엔드포인트 제한을 참조하세요.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
먼저 ManagedOnlineEndpoint 클래스를 사용하여 엔드포인트를 정의합니다.
팁
auth_mode: 키 기반 인증의 경우key를 사용합니다. Azure Machine Learning 토큰 기반 인증에 대해aml_token을 사용합니다.key는 만료되지 않지만aml_token은 만료됩니다. 인증에 대한 자세한 내용은 온라인 엔드포인트에 대한 클라이언트 인증을 참조하세요.필요에 따라 엔드포인트에 설명과 태그를 추가할 수 있습니다.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
이전에 만들어진 MLClient를 사용하여 작업 영역에 엔드포인트를 만듭니다. 이 명령은 엔드포인트 만들기를 시작하고 엔드포인트 만들기가 계속되는 동안 확인 응답을 반환합니다.
참고 항목
엔드포인트 만들기에는 약 2분 정도 걸릴 것으로 예상됩니다.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
엔드포인트를 만든 후 다음과 같이 검색할 수 있습니다.
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
온라인 배포 이해
배포의 주요 측면은 다음과 같습니다.
name- 배포의 이름입니다.endpoint_name- 배포를 포함할 엔드포인트의 이름입니다.model- 배포에 사용할 모델입니다. 이 값은 작업 영역에서 기존 버전의 모델에 대한 참조 또는 인라인 모델 사양일 수 있습니다.environment- 배포(또는 모델 실행)에 사용할 환경입니다. 이 값은 작업 영역에서 기존 버전의 환경에 대한 참조 또는 인라인 환경 사양일 수 있습니다. 환경은 Conda 종속성이 있는 Docker 이미지 또는 Dockerfile일 수 있습니다.code_configuration- 소스 코드 및 채점 스크립트에 대한 구성입니다.path- 모델을 채점하는 소스 코드 디렉터리의 로컬 경로scoring_script- 소스 코드 디렉터리에 있는 채점 파일의 상대 경로 이 스크립트는 지정된 입력 요청에 따라 모델을 실행합니다. 채점 스크립트의 예는 "온라인 엔드포인트를 사용하여 ML 모델 배포" 문서의 채점 스크립트 이해를 참조하세요.
instance_type- 배포에 사용할 VM 크기입니다. 지원되는 크기 목록은 관리되는 온라인 엔드포인트 SKU 목록을 참조하세요.instance_count- 배포에 사용할 인스턴스 수
MLflow 모델을 사용한 배포
Azure Machine Learning은 MLflow를 사용하여 만들어지고 기록된 모델의 코드 없는 배포를 지원합니다. 즉, MLflow 모델을 학습할 때 채점 스크립트와 환경이 자동으로 생성되므로 모델 배포 중에 채점 스크립트나 환경을 제공할 필요가 없습니다. 그러나 사용자 지정 모델을 사용하는 경우 배포 중에 환경과 채점 스크립트를 지정해야 합니다.
Important
일반적으로 채점 스크립트와 사용자 지정 환경을 사용하여 모델을 배포하고 MLflow 모델을 사용하여 동일한 기능을 구현하려는 경우 MLflow 모델 배포 안내를 읽어보는 것이 좋습니다.
엔드포인트에 모델 배포
수신 트래픽을 100% 처리하는 단일 배포를 만드는 것부터 시작할 예정입니다. 배포에 대해 임의의 색 이름(파란색)을 선택합니다. 엔드포인트에 대한 배포를 만들려면 ManagedOnlineDeployment 클래스를 사용합니다.
참고 항목
배포할 모델이 MLflow 모델이므로 환경이나 채점 스크립트를 지정할 필요가 없습니다.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
이전에 만든 MLClient를 사용하여 이제 작업 영역에 배포를 만듭니다. 이 명령은 배포 만들기를 시작하고 배포 만들기가 계속되는 동안 확인 응답을 반환합니다.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
클러스터의 상태를 확인합니다.
엔드포인트의 상태를 확인하여 모델이 오류 없이 배포되었는지 확인할 수 있습니다.
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
샘플 데이터로 엔드포인트 테스트
이제 모델이 엔드포인트에 배포되었으므로 이를 사용하여 유추를 실행할 수 있습니다. 채점 스크립트에 있는 실행 메서드에서 예상되는 디자인을 따르는 샘플 요청 파일을 만드는 것으로 시작합니다.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
이제 배포 디렉터리에 파일을 만듭니다. 다음 코드 셀은 IPython의 기능을 사용하여 방금 만든 디렉터리에 파일을 씁니다.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
이전에 만들어진 MLClient를 사용하여 엔드포인트에 대한 핸들을 가져옵니다. 다음 매개 변수와 함께 invoke 명령을 사용하여 엔드포인트를 호출할 수 있습니다.
endpoint_name- 엔드포인트 이름request_file- 요청 데이터가 있는 파일입니다.deployment_name- 엔드포인트에서 테스트할 특정 배포 이름
샘플 데이터로 파란색 배포를 테스트합니다.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
배포 로그 가져오기
로그를 확인하여 엔드포인트/배포가 성공적으로 호출되었는지 확인합니다. 오류가 발생하면 온라인 엔드포인트 배포 문제 해결을 참조하세요.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
두 번째 배포 만들기
모델을 green이라는 두 번째 배포로 배포합니다. 실제로 여러 배포를 만들고 성능을 비교할 수 있습니다. 이러한 배포에는 동일한 모델의 다른 버전, 다른 모델 또는 더 강력한 컴퓨팅 인스턴스가 사용될 수 있습니다.
이 예에서는 더욱 강력한 컴퓨팅 인스턴스를 사용하여 동일한 모델 버전을 배포하는데, 이를 통해 잠재적으로 성능이 개선될 수 있습니다.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
더 많은 트래픽을 처리하도록 배포 크기 조정
이전에 만든 MLClient를 사용하면 green 배포에 대한 핸들을 가져올 수 있습니다. 그런 다음 instance_count를 늘리거나 줄여서 크기를 조정할 수 있습니다.
다음 코드에서는 VM 인스턴스를 수동으로 늘립니다. 하지만 온라인 엔드포인트를 자동으로 크기 조정하는 것도 가능합니다. 자동 크기 조정은 애플리케이션의 로드를 처리하기 위해 적절한 양의 리소스를 자동으로 실행합니다. 관리되는 온라인 엔드포인트는 Azure Monitor 자동 크기 조정 기능과의 통합을 통해 자동 크기 조정을 지원합니다. 자동 크기 조정을 구성하려면 온라인 엔드포인트 자동 크기 조정을 참조하세요.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
배포를 위한 트래픽 할당 업데이트
배포 간에 프로덕션 트래픽을 분할할 수 있습니다. blue 배포에서와 마찬가지로 먼저 샘플 데이터로 green 배포를 테스트할 수 있습니다. 녹색 배포를 테스트한 후에는 여기에 소량의 트래픽을 할당합니다.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
엔드포인트를 여러 번 호출하여 트래픽 할당을 테스트합니다.
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
green 배포의 로그를 표시하여 들어오는 요청이 있었고 모델의 점수가 성공적으로 매겨졌는지 확인합니다.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Azure Monitor를 사용하여 메트릭 보기
스튜디오에 있는 엔드포인트의 세부 정보 페이지에 있는 링크를 따라 가면 온라인 엔드포인트 및 해당 배포에 대한 다양한 메트릭(요청 수, 요청 대기 시간, 네트워크 바이트, CPU/GPU/디스크/메모리 활용도 등)을 볼 수 있습니다. 이러한 링크 중 하나를 따르면 Azure Portal에서 엔드포인트 또는 배포에 대한 정확한 메트릭 페이지로 이동합니다.

온라인 엔드포인트에 대한 메트릭을 열면 다음 그림과 같이 평균 요청 대기 시간과 같은 메트릭을 볼 수 있도록 페이지를 설정할 수 있습니다.

온라인 엔드포인트 메트릭을 보는 방법에 대한 자세한 내용은 온라인 엔드포인트 모니터링을 참조하세요.
모든 트래픽을 새 배포로 보냅니다.
green 배포가 완전히 만족스러우면 모든 트래픽을 여기로 전환합니다.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
이전 배포 삭제
이전(파란색) 배포를 제거합니다.
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
리소스 정리
이 자습서를 완료한 후 엔드포인트 및 배포를 사용하지 않을 경우 삭제해야 합니다.
참고 항목
전체 삭제에는 약 20분 정도 소요됩니다.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
모든 항목 삭제
다음 단계를 사용하여 Azure Machine Learning 작업 영역 및 모든 컴퓨팅 리소스를 삭제합니다.
Important
사용자가 만든 리소스는 다른 Azure Machine Learning 자습서 및 방법 문서의 필수 구성 요소로 사용할 수 있습니다.
사용자가 만든 리소스를 사용하지 않으려면 요금이 발생하지 않도록 해당 리소스를 삭제합니다.
Azure Portal의 검색 상자에 리소스 그룹을 입력하고 결과에서 선택합니다.
목록에서 만든 리소스 그룹을 선택합니다.
개요 페이지에서 리소스 그룹 삭제를 선택합니다.
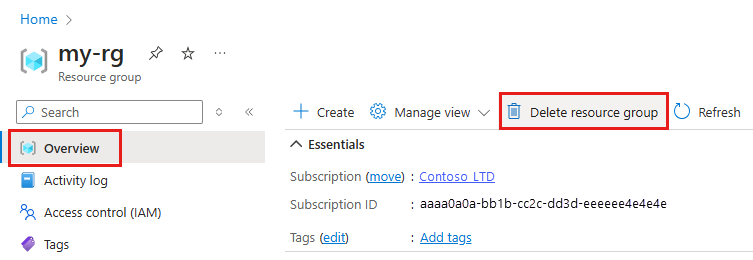
리소스 그룹 이름을 입력합니다. 그런 다음 삭제를 선택합니다.