Azure Database for PostgreSQL - 유연한 서버에서 느리게 실행되는 쿼리 문제 해결 및 식별
적용 대상:  Azure Database for PostgreSQL - 유연한 서버
Azure Database for PostgreSQL - 유연한 서버
이 문서에서는 느리게 실행되는 쿼리의 근본 원인을 식별하고 진단하는 방법을 설명합니다.
이 문서에서는 다음에 대해 알아봅니다.
- 느리게 실행되는 쿼리를 식별하는 방법입니다.
- 함께 느리게 실행되는 프로시저를 식별하는 방법입니다. 느리게 실행되는 동일한 저장 프로시저에 속하는 쿼리 목록 중에서 느린 쿼리를 식별합니다.
필수 조건
문제 해결 가이드 사용에 설명된 단계에 따라 문제 해결 가이드를 사용하도록 설정합니다.
확장을 허용 목록에 추가하고 로드하여 확장을 구성합니다.
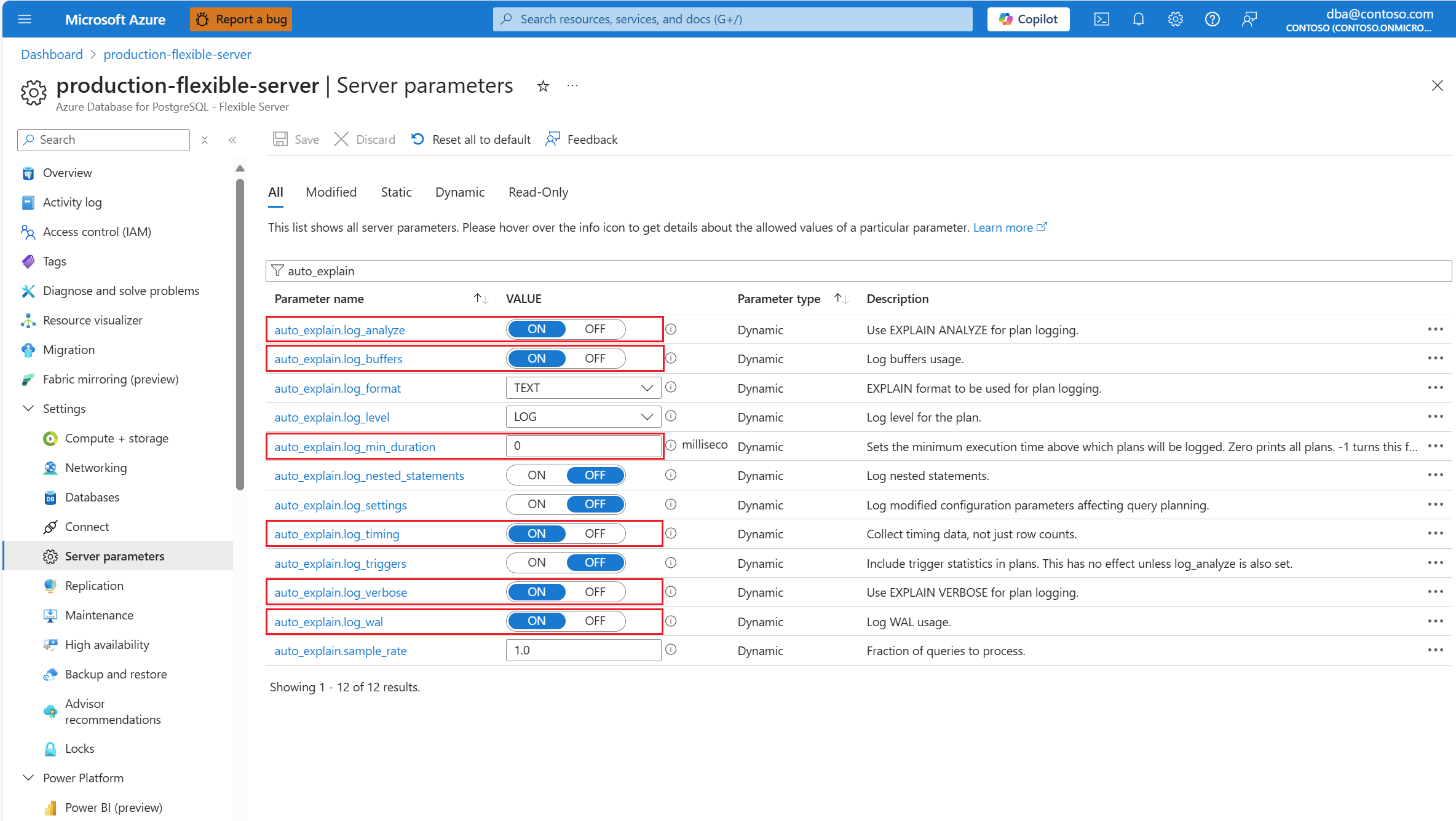
auto_explain확장을 구성한
auto_explain후 확장의 동작을 제어하는 다음 서버 매개 변수를 변경합니다.auto_explain.log_analyze가ON로 변경되었습니다.auto_explain.log_buffers가ON로 변경되었습니다.auto_explain.log_min_duration시나리오에서 합리적인 내용에 따라 다릅니다.auto_explain.log_timing가ON로 변경되었습니다.auto_explain.log_verbose가ON로 변경되었습니다.

참고 항목
0으로 설정 auto_explain.log_min_duration 하면 확장이 서버에서 실행 중인 모든 쿼리를 로깅하기 시작합니다. 이는 데이터베이스의 성능에 영향을 미칠 수 있습니다. 서버에서 느린 것으로 간주되는 값에 도달하려면 적절한 실사를 수행해야 합니다. 예를 들어 모든 쿼리가 30초 이내에 완료되고 애플리케이션에 허용되는 경우 매개 변수를 30000밀리초로 업데이트하는 것이 좋습니다. 그러면 완료하는 데 30초 이상 걸리는 모든 쿼리가 기록됩니다.
느린 쿼리 식별
문제 해결 가이드 및 auto_explain 확장을 사용하여 예제의 도움을 받아 시나리오를 설명합니다.
CPU 사용률이 90%로 급증하고 급증의 원인을 확인하려는 시나리오가 있습니다. 시나리오를 디버그하려면 다음 단계를 수행합니다.
CPU 시나리오에서 경고를 받는 즉시 Azure Database for PostgreSQL 유연한 서버의 영향을 받는 인스턴스의 리소스 메뉴에서 모니터링 섹션에서 문제 해결 가이드를 선택합니다.
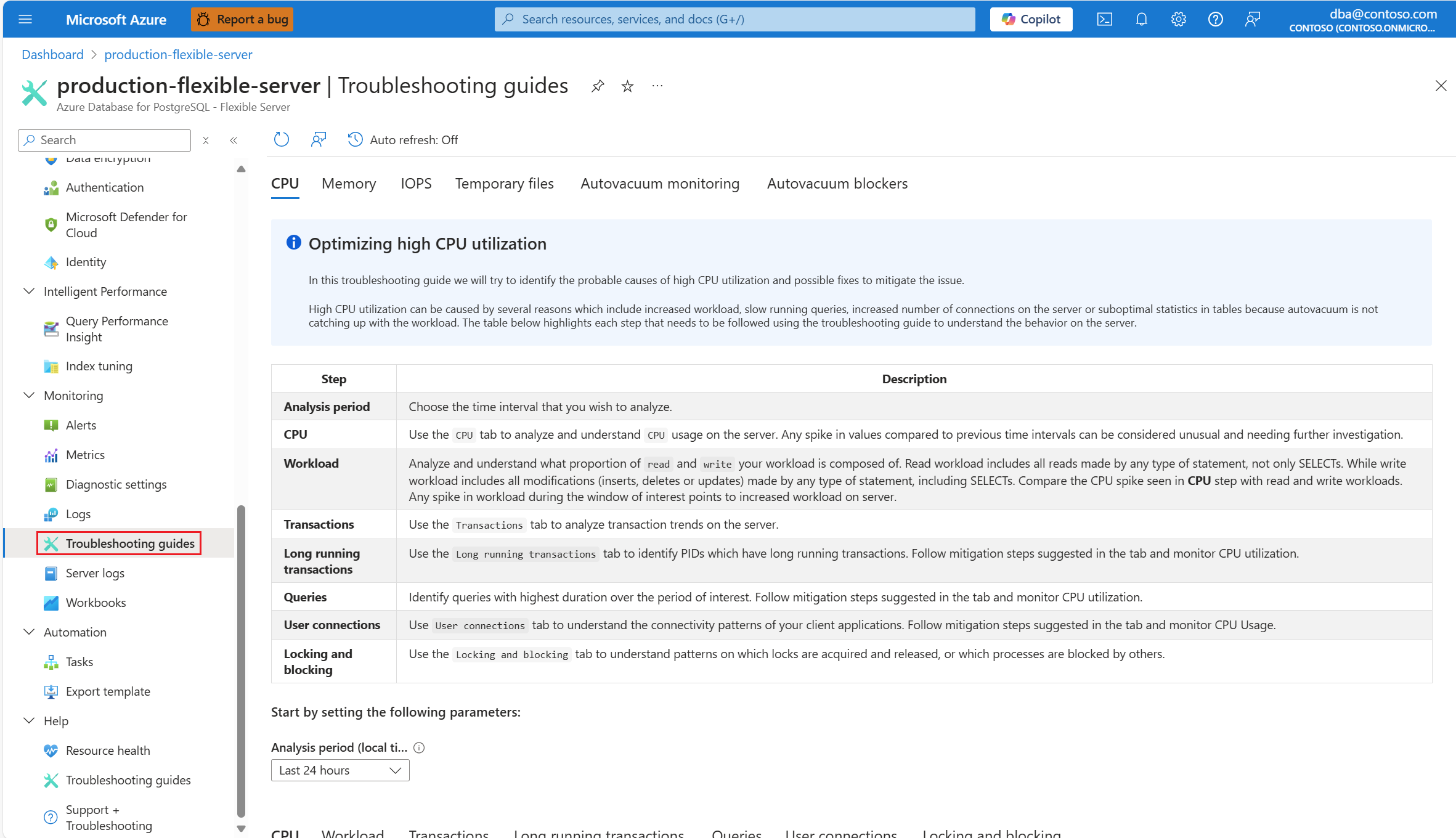
CPU 탭을 선택합니다. 높은 CPU 사용률 최적화 문제 해결 가이드가 열립니다.

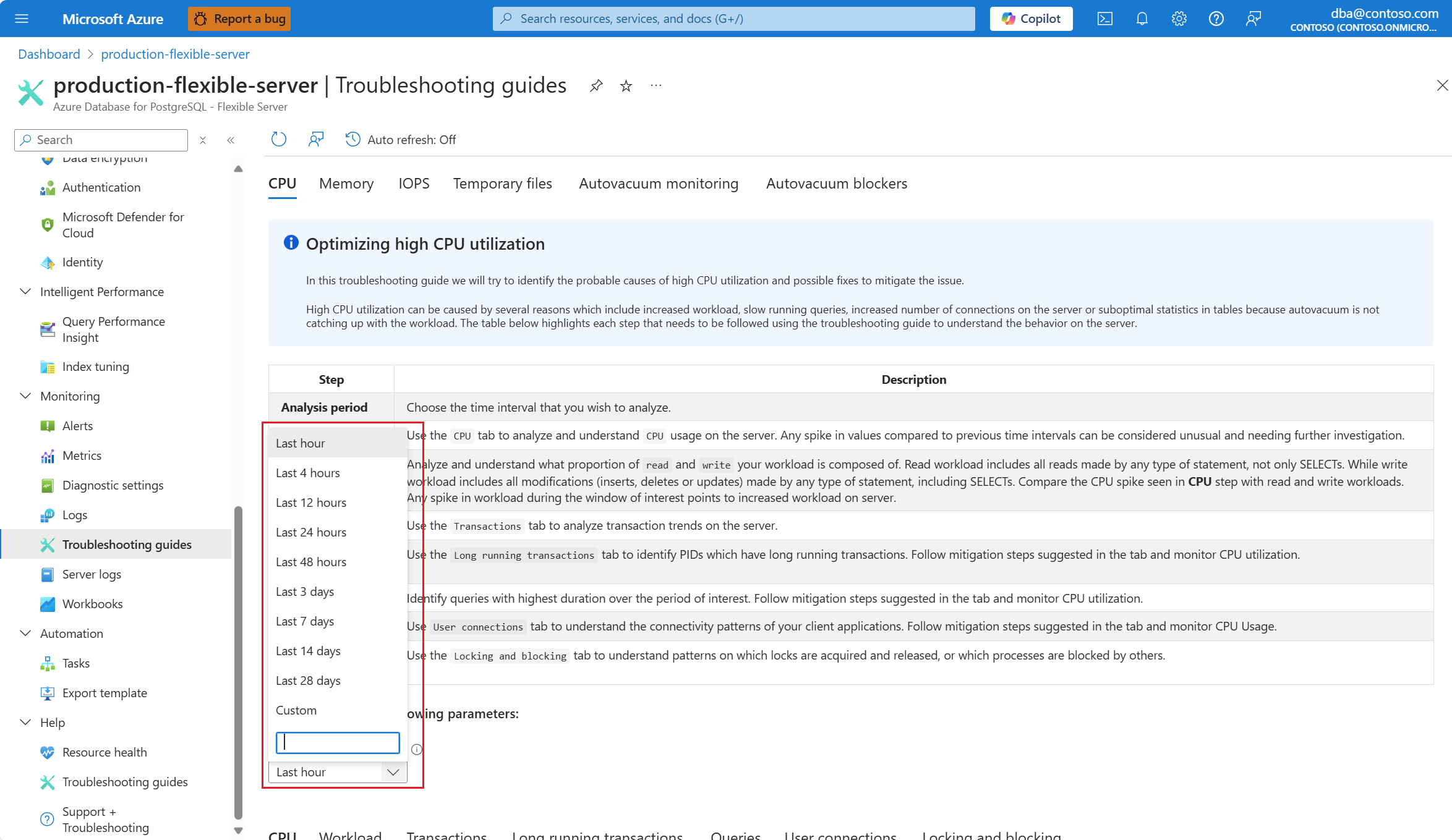
분석 기간(현지 시간) 드롭다운에서 분석에 집중할 시간 범위를 선택합니다.
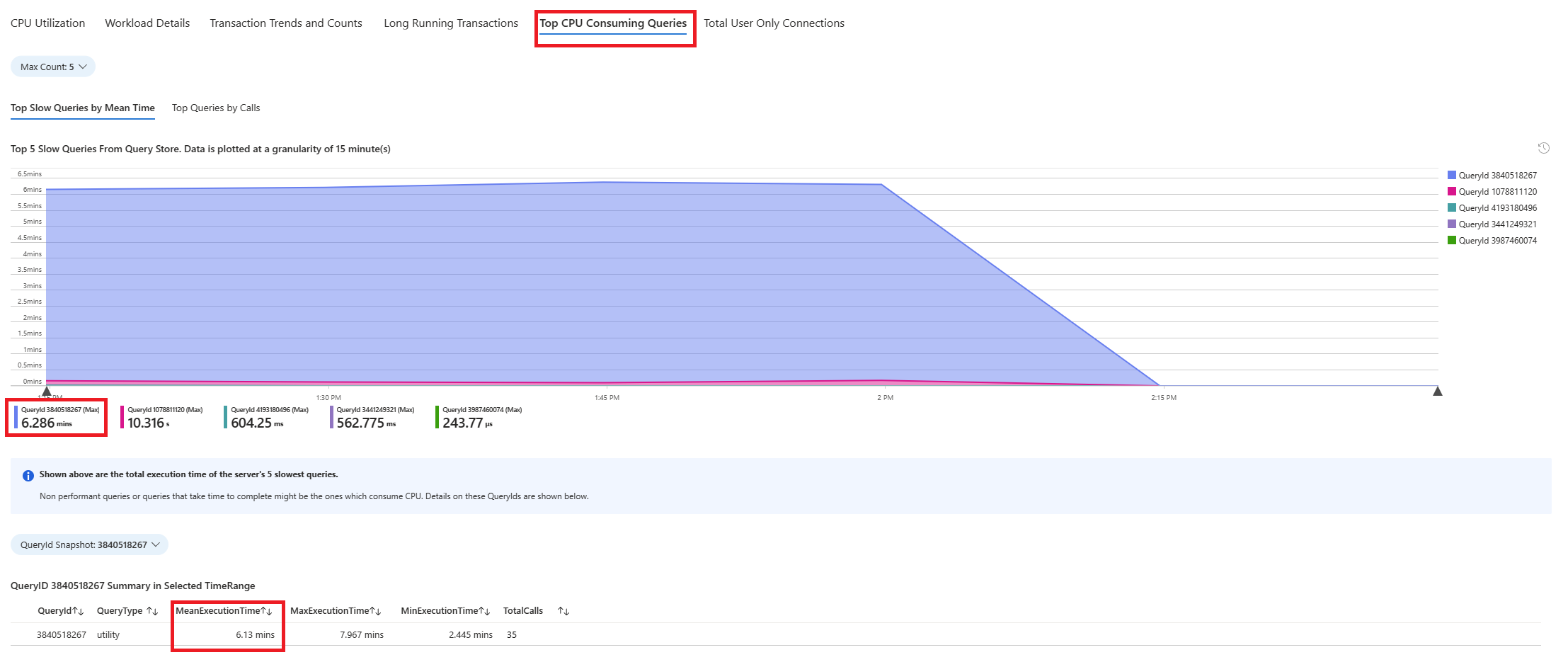
쿼리 탭을 선택합니다. CPU 사용률이 90%인 간격으로 실행된 모든 쿼리의 세부 정보를 보여 줍니다. 스냅샷을 보면 해당 시간 간격 동안 평균 실행 시간이 가장 느린 쿼리는 ~2.6분이었고 해당 간격 동안 쿼리가 22번 실행된 것으로 보입니다. 이 쿼리는 CPU 급증의 원인일 가능성이 큽니다.

실제 쿼리 텍스트를 검색하려면 데이터베이스에
azure_sys연결하고 다음 쿼리를 실행합니다.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- 고려된 예제에서 느리게 발견된 쿼리는 다음과 같습니다.
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
생성된 정확한 설명 계획을 이해하려면 Azure Database for PostgreSQL 유연한 서버 로그를 사용합니다. 쿼리가 해당 기간 동안 실행을 완료할 때마다 확장은
auto_explain로그에 항목을 작성해야 합니다. 리소스 메뉴의 모니터링 섹션에서 로그를 선택합니다.
CPU 사용률이 90%인 시간 범위를 선택합니다.
다음 쿼리를 실행하여 식별된 쿼리에 대한 EXPLAIN ANALYZE의 출력을 검색합니다.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
메시지 열은 다음 출력에 표시된 대로 실행 계획을 저장합니다.
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
쿼리는 문제 해결 가이드에 표시된 대로 2.5분 동안 실행되었습니다. duration 가져온 실행 계획 출력에서 150692.864ms의 값이 확인됩니다. EXPLAIN ANALYZE의 출력을 사용하여 추가 문제를 해결하고 쿼리를 튜닝합니다.
참고 항목
쿼리가 간격 동안 22번 실행되었으며 표시된 로그에는 해당 간격 동안 캡처된 이러한 항목 중 하나가 포함되어 있음을 확인합니다.
저장 프로시저에서 느리게 실행되는 쿼리 식별
문제 해결 가이드 및 auto_explain 확장을 통해 예제의 도움을 받아 시나리오를 설명합니다.
CPU 사용률이 90%로 급증하고 급증의 원인을 확인하려는 시나리오가 있습니다. 시나리오를 디버그하려면 다음 단계를 수행합니다.
CPU 시나리오에서 경고를 받는 즉시 Azure Database for PostgreSQL 유연한 서버의 영향을 받는 인스턴스의 리소스 메뉴에서 모니터링 섹션에서 문제 해결 가이드를 선택합니다.
CPU 탭을 선택합니다. 높은 CPU 사용률 최적화 문제 해결 가이드가 열립니다.
분석 기간(현지 시간) 드롭다운에서 분석에 집중할 시간 범위를 선택합니다.

쿼리 탭을 선택합니다. CPU 사용률이 90%인 간격으로 실행된 모든 쿼리의 세부 정보를 보여 줍니다. 스냅샷을 보면 해당 시간 간격 동안 평균 실행 시간이 가장 느린 쿼리는 ~2.6분이었고 해당 간격 동안 쿼리가 22번 실행된 것으로 보입니다. 이 쿼리는 CPU 급증의 원인일 가능성이 큽니다.
azure_sys 데이터베이스에 연결하고 쿼리를 실행하여 아래 스크립트를 사용하여 실제 쿼리 텍스트를 검색합니다.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- 고려된 예제에서 느리게 발견된 쿼리는 저장 프로시저였습니다.
call autoexplain_test ();
- 생성된 정확한 설명 계획을 이해하려면 Azure Database for PostgreSQL 유연한 서버 로그를 사용합니다. 쿼리가 해당 기간 동안 실행을 완료할 때마다 확장은
auto_explain로그에 항목을 작성해야 합니다. 리소스 메뉴의 모니터링 섹션에서 로그를 선택합니다. 그런 다음 시간 범위:에서 분석에 집중할 시간 창을 선택합니다.

- 다음 쿼리를 실행하여 식별된 쿼리의 분석 설명 출력을 검색합니다.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
프로시저에는 아래에 강조 표시된 여러 쿼리가 있습니다. 저장 프로시저에 사용되는 모든 쿼리의 분석 설명 출력은 추가 분석 및 문제 해결을 위해 로그됩니다. 기록된 쿼리의 실행 시간을 사용하여 저장 프로시저의 일부인 가장 느린 쿼리를 식별할 수 있습니다.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
참고 항목
데모를 위해 프로시저에 사용된 몇 가지 쿼리의 EXPLAIN ANALYZE 출력만 표시됩니다. 이 아이디어는 로그에서 모든 쿼리의 EXPLAIN ANALYZE 출력을 수집하고 가장 느린 쿼리를 식별하고 튜닝을 시도할 수 있다는 것입니다.
Azure Database for PostgreSQL 제품 팀과 제안 및 버그를 공유합니다.