OneLake 파일 및 바로 가기에서 데이터 인덱싱
이 문서에서는 OneLake 위에 있는 Lakehouse에서 검색 가능한 데이터 및 메타데이터 데이터를 추출하기 위해 OneLake 파일 인덱서 구성 방법을 알아봅니다.
인덱서 구성 및 실행하려면 다음을 사용할 수 있습니다.
- 2024-05-01-preview REST API 또는 최신 미리 보기 REST API.
- 기능을 제공하는 Azure SDK 베타 패키지입니다.
- Azure Portal에서 데이터 가져오기 마법사
- Azure Portal에서 데이터 가져오기 및 벡터화 마법사
이 문서에서는 REST API를 사용하여 각 단계를 설명합니다.
필수 조건
패브릭 작업 영역입니다. 이 자습서에 따라 패브릭 작업 영역을 만듭니다.
패브릭 작업 영역의 레이크하우스입니다. 이 자습서에 따라 lakehouse를 만듭니다.
텍스트 데이터입니다. 이진 데이터가 있는 경우 AI 보강 이미지 분석을 사용하여 텍스트를 추출하거나 이미지에 대한 설명을 생성할 수 있습니다. 파일 콘텐츠는 검색 서비스 계층에 대한 인덱서 제한을 초과할 수 없습니다.
파일의 콘텐츠는 레이크하우스의 위치입니다. 다음을 통해 데이터를 추가할 수 있습니다.
- 레이크 하우스에 직접 업로드
- Microsoft Fabric에서 데이터 파이프라인 사용
- Amazon S3 또는 google Cloud Storage 같은 외부 데이터 원본의 바로 가기를 추가합니다.
시스템 관리 ID 또는 사용자가 할당한 관리 ID에 대해 구성된 AI Search 서비스입니다. AI Search 서비스는 Microsoft Fabric 작업 영역과 동일한 테넌트 내에 있어야 합니다.
Lakehouse가 있는 Microsoft Fabric 작업 영역의 기여자 역할 할당입니다. 단계는 이 문서의 권한 부여 섹션에 설명되어 있습니다.
REST 클라이언트 이 문서에 표시된 것과 유사한 REST 호출을 작성합니다.
지원되는 작업
이 인덱서는 다음 작업에 사용할 수 있습니다.
- 데이터 인덱싱 및 증분 인덱싱: 인덱서는 lakehouse 내의 데이터 경로에서 파일 및 관련 메타데이터를 인덱싱할 수 있습니다. 기본 제공 변경 검색을 통해 새 파일 및 업데이트된 파일 및 메타데이터를 검색합니다. 일정 또는 요청 시 데이터 새로 고침을 구성할 수 있습니다.
- 삭제 검색: 인덱서는 대부분의 파일 및 바로 가기에 대한 사용자 지정 메타데이터 통해 삭제를 검색할 수 있습니다. 이렇게 하려면 파일에 메타데이터를 추가하여 "일시 삭제됨"을 나타내고 검색 인덱스에서 제거할 수 있어야 합니다. 현재는 이러한 데이터 원본에 대해 사용자 지정 메타데이터가 지원되지 않으므로 Google Cloud Storage 또는 Amazon S3 바로 가기 파일에서 삭제를 검색할 수 없습니다.
- 기술 세트를 통해 적용된 AI: 기술 세트는 OneLake 파일 인덱서에서 완전히 지원됩니다. 여기에는 데이터 청크 및 포함 단계를 추가하는 통합 벡터화와 같은 주요 기능이 포함됩니다.
- 구문 분석 모드: JSON 배열 또는 줄을 개별 검색 문서로 구문 분석하려는 경우 JSON 구문 분석 모드를 지원합니다. Markdown 구문 분석 모드도 지원합니다.
- 다른 기능과의 호환성: OneLake 인덱서는 디버그 세션, 증분 보강 인덱서 캐시 및 지식 저장소 같은 다른 인덱서 기능과 원활하게 작동하도록 설계되었습니다.
지원되는 문서 형식
OneLake 파일 인덱서는 다음 문서 형식에서 텍스트를 추출할 수 있습니다.
- CSV(CSV Blob 인덱싱 참조)
- EML
- EPUB
- GZ
- HTML
- JSON(JSON BLOB 인덱싱 참조)
- KML(지리적 표현을 위한 XML)
- Microsoft Office 형식: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG(Outlook 메일), XML(2003 및 2006 WORD XML 모두)
- 오픈 문서 형식: ODT, ODS, ODP
- 일반 텍스트 파일(일반 텍스트 인덱싱도 참조)
- RTF
- XML
- ZIP
지원되는 바로 가기
다음 OneLake 바로 가기는 OneLake 파일 인덱서에서 지원됩니다.
OneLake 바로 가기 (다른 OneLake 인스턴스에 대한 바로 가기)
이 미리 보기의 제한 사항
Parquet(델타 parquet 포함) 파일 형식은 현재 지원되지 않습니다.
Amazon S3 및 Google Cloud Storage 바로 가기에는 파일 삭제가 지원되지 않습니다.
이 인덱서는 OneLake 작업 영역 테이블 위치 콘텐츠를 지원하지 않습니다.
이 인덱서는 SQL 쿼리를 지원하지 않지만 데이터 원본 구성에 사용되는 쿼리는 선택적으로 액세스할 폴더 또는 바로 가기를 추가하기 위한 것입니다.
사용자별 개인 리포지토리이므로 OneLake의 내 작업 영역 작업 영역에서 파일을 수집할 수 없습니다.
인덱싱을 위한 데이터 준비
인덱싱을 설정하기 전에 원본 데이터를 검토하여 미리 변경해야 하는지 여부를 결정합니다. 인덱서는 한 번에 한 컨테이너의 콘텐츠를 인덱싱할 수 있습니다. 기본적으로 컨테이너의 모든 파일이 처리됩니다. 보다 선택적 처리를 위한 몇 가지 옵션이 있습니다.
가상 폴더에 파일을 배치합니다. 데이터 원본 정의 인덱서에는 lakehouse 하위 폴더 또는 바로 가기일 수 있는 "query" 매개 변수가 포함됩니다. 이 값을 지정하면 레이크하우스 내의 하위 폴더 또는 바로 가기에 있는 파일만 인덱싱됩니다.
파일 형식별로 파일을 포함하거나 제외합니다. 지원되는 문서 서식 목록을 제외할 파일을 결정하는 데 도움이 될 수 있습니다. 예를 들어, 검색 가능한 텍스트를 제공하지 않는 이미지 또는 오디오 파일을 제외할 수 있습니다. 이 기능은 인덱서의 구성 설정을 통해 제어됩니다.
임의 파일을 포함하거나 제외합니다. 어떤 이유로든 특정 파일을 건너뛰려면 OneLake Lakehouse의 파일에 메타데이터 속성 및 값을 추가할 수 있습니다. 인덱서가 이 속성을 발견하면 인덱싱 실행에서 파일 또는 해당 콘텐츠를 건너뜁니다.
파일 포함 및 제외는 인덱서 구성 단계에서 다룹니다. 조건을 설정하지 않으면 인덱서가 부적격 파일을 오류로 보고하고 계속 진행합니다. 충분한 오류가 발생하면 처리가 중지될 수 있습니다. 인덱서 구성 설정에서 오류 허용 범위를 지정할 수 있습니다.
인덱서는 일반적으로 파일당 하나의 검색 문서를 만듭니다. 여기서 텍스트 콘텐츠와 메타데이터는 인덱스에서 검색 가능한 필드로 캡처됩니다. 파일이 전체 파일인 경우 여러 검색 문서 구문 분석할 수 있습니다. 예를 들어, CSV 파일의 행을 구문 분석하여 행당 하나의 검색 문서를 만들 수 있습니다. 단일 문서를 작은 구절로 청크하여 데이터를 벡터화해야 하는 경우 통합 벡터화를 사용하는 것이 좋습니다.
파일 메타데이터 인덱싱
파일 메타데이터도 인덱싱할 수 있으며, 표준 또는 사용자 지정 메타데이터 속성이 필터 및 쿼리에서 유용하다고 생각하는 경우 도움이 됩니다.
사용자 지정 메타데이터 속성은 그대로 추출됩니다. 값을 받으려면 Blob의 메타데이터 키와 이름이 같은 Edm.String 형식의 검색 인덱스에 필드를 정의해야 합니다. 예를 들어, Blob의 메타데이터 키 Priority의 값이 High인 경우 검색 인덱스에 Priority라는 필드를 정의하면 High 값으로 채워집니다.
표준 파일 메타데이터 속성은 아래 나열된 대로 유사하게 명명되고 형식화된 필드로 추출할 수 있습니다. OneLake 파일 인덱서는 이러한 메타데이터 속성에 대한 내부 필드 매핑을 자동으로 만들어 원래 하이픈 처리된 이름("metadata-storage-name")을 밑줄이 그어진 해당 이름("metadata_storage_name")으로 변환합니다.
인덱스 정의에 밑줄 필드를 추가해야 하지만 인덱서가 자동으로 연결을 만들기 때문에 인덱서 필드 매핑을 생략할 수 있습니다.
metadata_storage_name(
Edm.String) - 파일 이름입니다. 예를 들어 /mydatalake/my-folder/subfolder/resume.pdf 파일이 있는 경우 이 필드의 값은resume.pdf입니다.metadata_storage_path(
Edm.String) - 스토리지 계정을 포함하는 Blob의 전체 URI입니다. 예를 들어https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type(
Edm.String) - Blob을 업로드하기 위해 사용한 코드에 지정된 콘텐츠 형식입니다. 예:application/octet-stream.metadata_storage_last_modified(
Edm.DateTimeOffset) - Blob에 대해 마지막으로 수정된 타임스탬프입니다. Azure AI Search는 이 타임스탬프로 변경된 Blob을 식별하여 초기 인덱싱 후 모든 항목을 다시 인덱싱하는 것을 방지합니다.metadata_storage_size(
Edm.Int64) - Blob 크기(바이트)입니다.metadata_storage_content_md5(
Edm.String) - Blob 콘텐츠의 MD5 해시(사용 가능한 경우)입니다.
마지막으로 인덱싱하는 파일의 문서 형식과 관련된 모든 메타데이터 속성을 인덱스 스키마에 나타낼 수도 있습니다. 콘텐츠 관련 메타데이터에 대한 자세한 내용은 콘텐츠 메타데이터 속성을 참조하세요.
검색 인덱스에서 위의 모든 속성에 대한 필드를 정의하지 않아도 되는 경우 애플리케이션에 필요한 속성만 캡처하는 것이 중요합니다.
권한 부여
OneLake 인덱서는 OneLake에 대한 연결에 토큰 인증 및 역할 기반 액세스를 사용합니다. 사용 권한은 OneLake에 할당됩니다. 바로 가기를 지원하는 물리적 데이터 저장소에 대한 사용 권한 요구 사항은 없습니다. 예를 들어 AWS에서 인덱싱하는 경우 AWS에서 검색 서비스 권한을 부여할 필요가 없습니다.
검색 서비스 ID에 대한 최소 역할 할당은 참가자입니다.
AI Search 서비스에 대한 시스템 또는 사용자 관리 ID를 구성합니다.
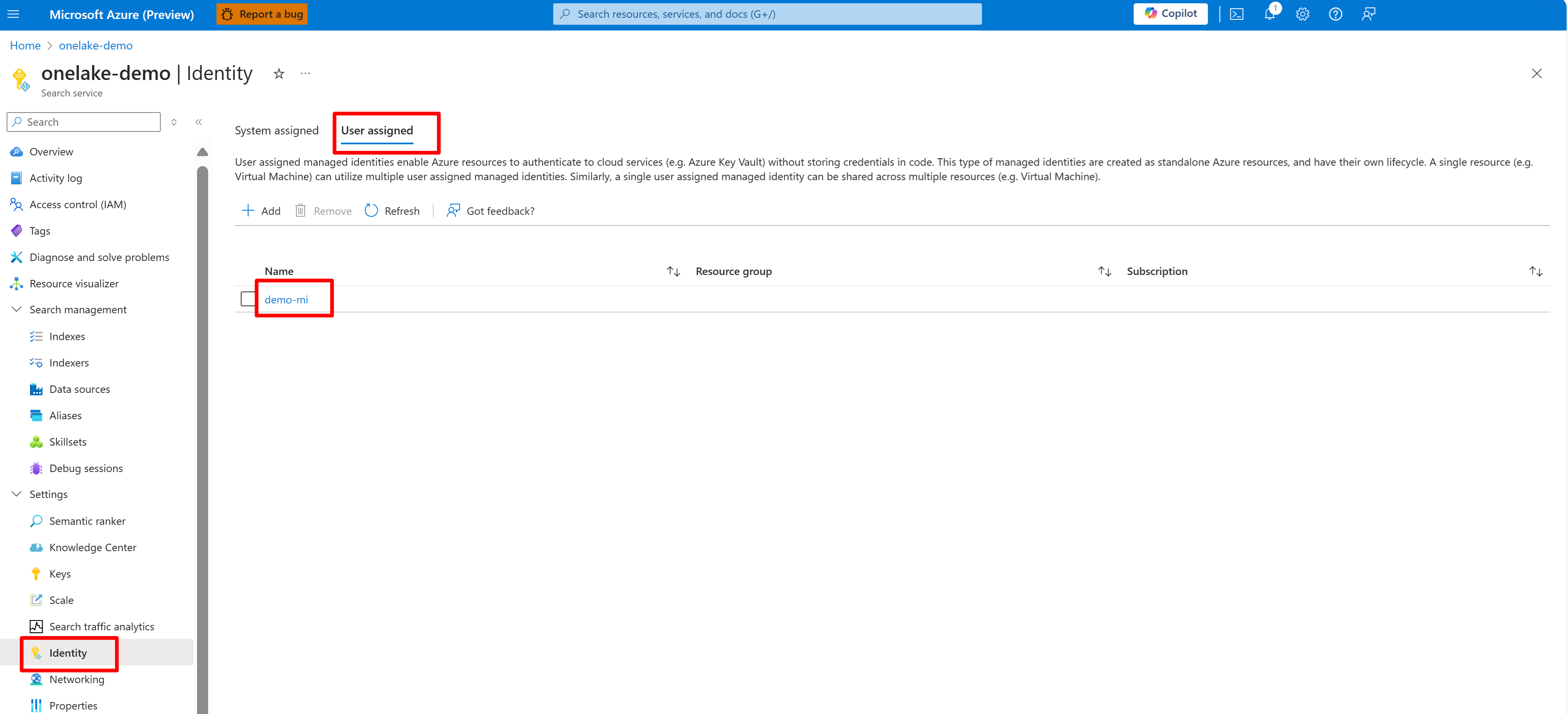
다음 스크린샷은 "onelake-demo"라는 검색 서비스에 대한 시스템 관리 ID를 보여줍니다.

이 스크린샷은 동일한 검색 서비스에 대한 사용자 관리 ID를 보여줍니다.
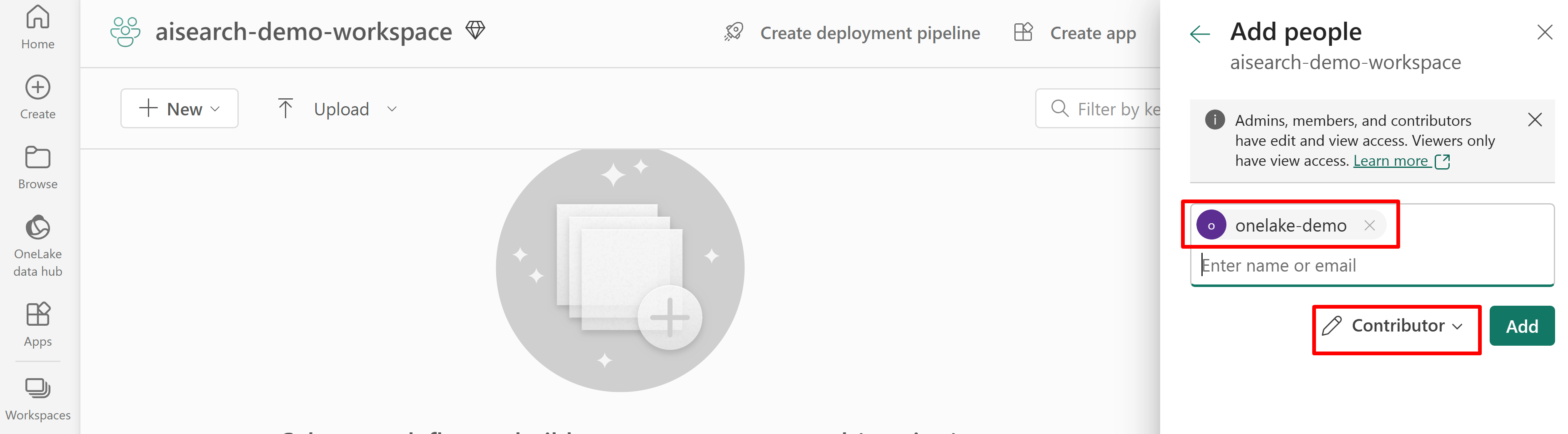
Fabric 작업 영역에 대한 검색 서비스 액세스에 대한 권한을 부여합니다. 검색 서비스는 인덱서 대신 연결을 만듭니다.
시스템 할당 관리 ID를 사용하는 경우 AI Search 서비스의 이름을 검색합니다. 사용자 할당 관리 ID의 경우 ID 리소스의 이름을 검색합니다.
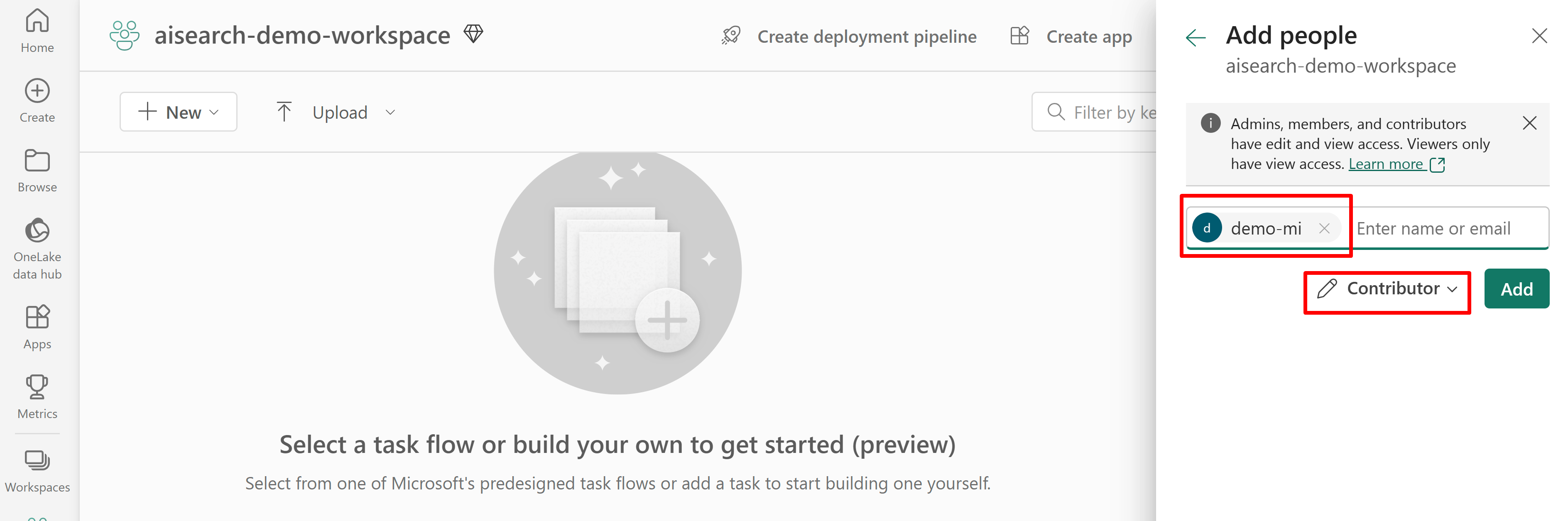
다음 스크린샷은 시스템 관리 ID를 사용하는 기여자 역할 할당을 보여줍니다.
이 스크린샷은 시스템 관리 ID를 사용하는 기여자 역할 할당을 보여줍니다.




데이터 원본 정의
데이터 원본은 여러 인덱서에서 사용할 수 있도록 독립적인 리소스로 정의됩니다. 데이터 원본을 만들려면 2024-05-01-preview REST API를 사용해야 합니다.
데이터 원본 REST API를 만들거나 업데이트하여 정의를 설정합니다. 이는 정의의 가장 중요한 단계입니다.
"type"을"onelake"로 설정합니다(필수).Microsoft Fabric 작업 영역 GUID 및 Lakehouse GUID를 가져옵니다.
URL에서 데이터를 가져오려는 레이크하우스로 이동합니다. 이 예제와 유사해야 합니다. "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". 데이터 원본 정의에 사용되는 다음 값을 복사합니다.
URL의 "그룹" 바로 다음에 나열되는
{FabricWorkspaceGuid}을(를) 호출할 작업 영역 GUID를 복사합니다. 이 예제에서는 00000000-0000-0000-0000-000000000000입니다.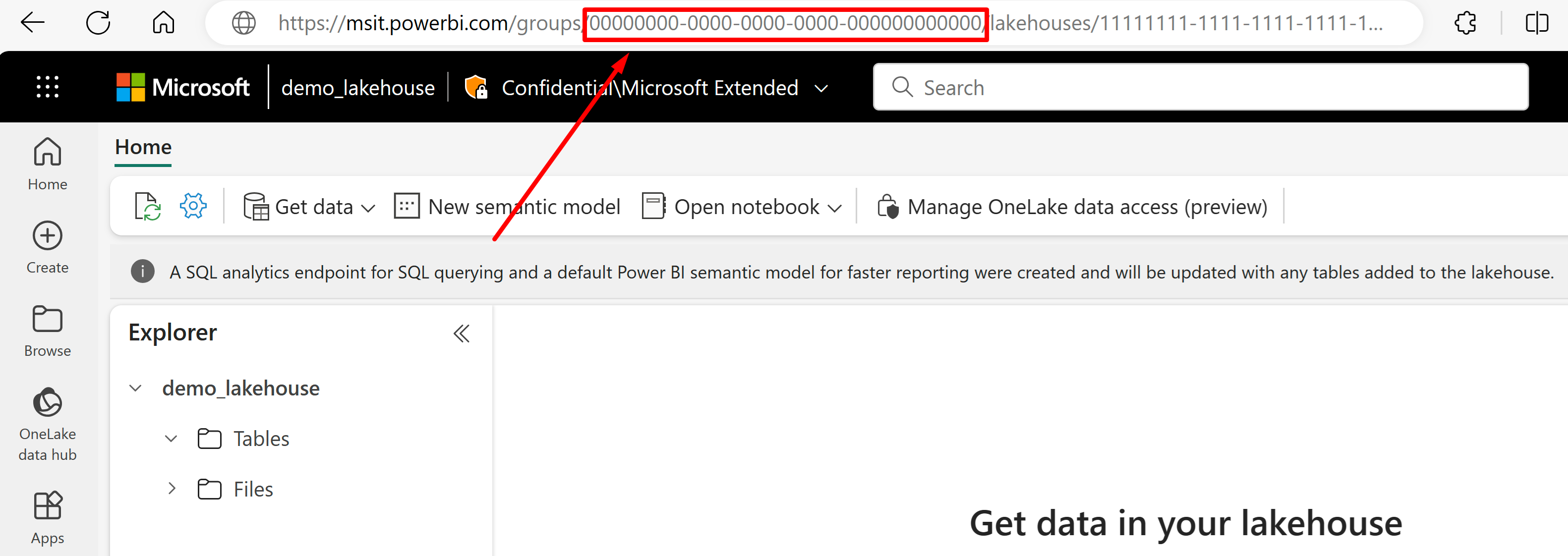
URL의 "lakehouses" 바로 다음에 나열되는
{lakehouseGuid}을(를) 호출할 Lakehouse GUID를 복사합니다. 이 예제에서는 11111111-1111-1111-1111-111111111111입니다.
이전 단계에서 복사한 값으로
{FabricWorkspaceGuid}을(를) 바꿔 Microsoft Fabric 작업 영역 GUID로"credentials"을(를) 설정합니다. 이 가이드의 뒷부분에서 설정할 관리 ID를 사용하여 액세스할 수 있는 OneLake입니다."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }"container.name"레이크하우스 GUID로 설정하고{lakehouseGuid}이전 단계에서 복사한 값으로 바꿉니다."query"을(를) 사용하여 필요에 따라 lakehouse 하위 폴더 또는 바로 가기를 지정합니다."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }사용자 할당 관리 ID를 사용하여 인증 방법을 설정하거나 시스템 관리 ID에 대한 다음 단계로 건너뜁니다.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }userAssignedIdentity값은 속성 아래에서{userAssignedManagedIdentity}리소스에 액세스하여 찾을 수 있으며 이를Id(이)라고 합니다.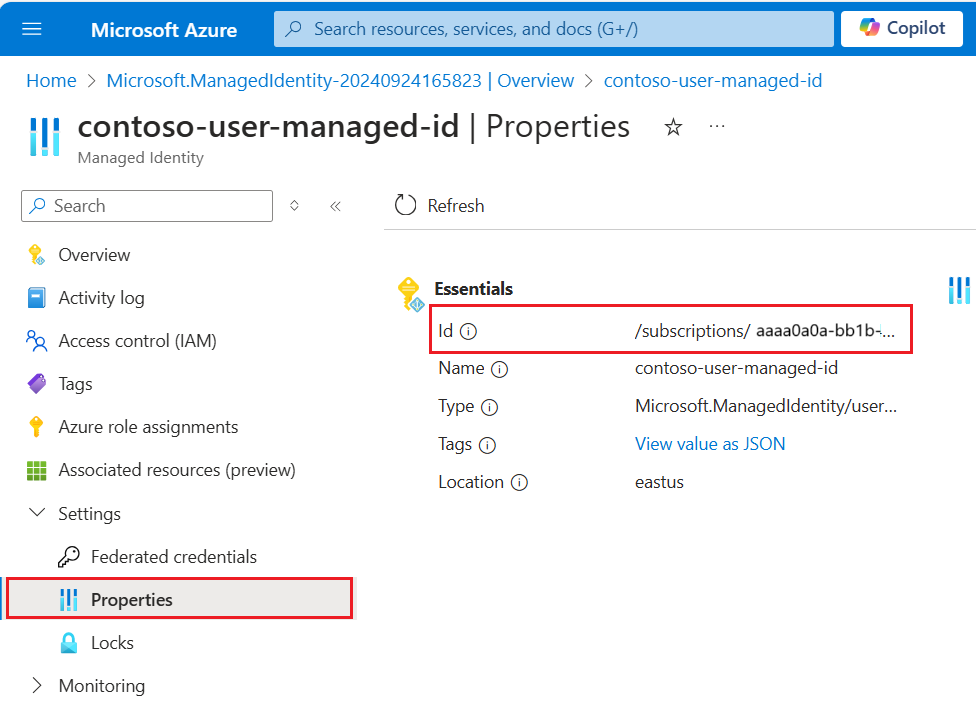
예시:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }필요에 따라 시스템 할당 관리 ID를 대신 사용합니다. 시스템 할당 관리 ID를 사용하는 경우 "ID"가 정의에서 제거됩니다.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }예시:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



사용자 지정 메타데이터를 통해 삭제 검색
원본 문서 삭제 플래그가 지정될 때 인덱서가 검색 문서를 삭제하도록 하려면 OneLake 파일 인덱서 데이터 원본 정의에 일시 삭제 정책이 포함될 수 있습니다.
자동 파일 삭제를 사용하도록 설정하려면 사용자 지정 메타데이터를 사용하여 검색 문서를 인덱스에서 제거해야 하는지 여부를 나타냅니다.
워크플로에는 다음 세 가지 개별 작업이 필요합니다.
- OneLake에서 파일 "일시 삭제"
- 인덱서가 인덱스의 검색 문서를 삭제합니다.
- OneLake의 파일을 "하드 삭제"합니다.
"일시 삭제"는 인덱서에 수행할 작업을 알려줍니다(검색 문서 삭제). 먼저 OneLake에서 물리적 파일을 삭제하는 경우 인덱서를 읽을 수 있는 항목이 없으며 인덱스의 해당 검색 문서가 분리됩니다.
OneLake와 Azure AI Search 모두에 따라야 하는 단계가 있지만 다른 기능 종속성은 없습니다.
Lakehouse 파일에서 파일에 사용자 지정 메타데이터 키-값 쌍을 추가하여 파일이 삭제 플래그가 지정되었음을 나타냅니다. 예를 들어 속성 이름을 “IsDeleted”로 지정하고 false로 설정할 수 있습니다. 파일을 삭제하려면 true로 변경합니다.
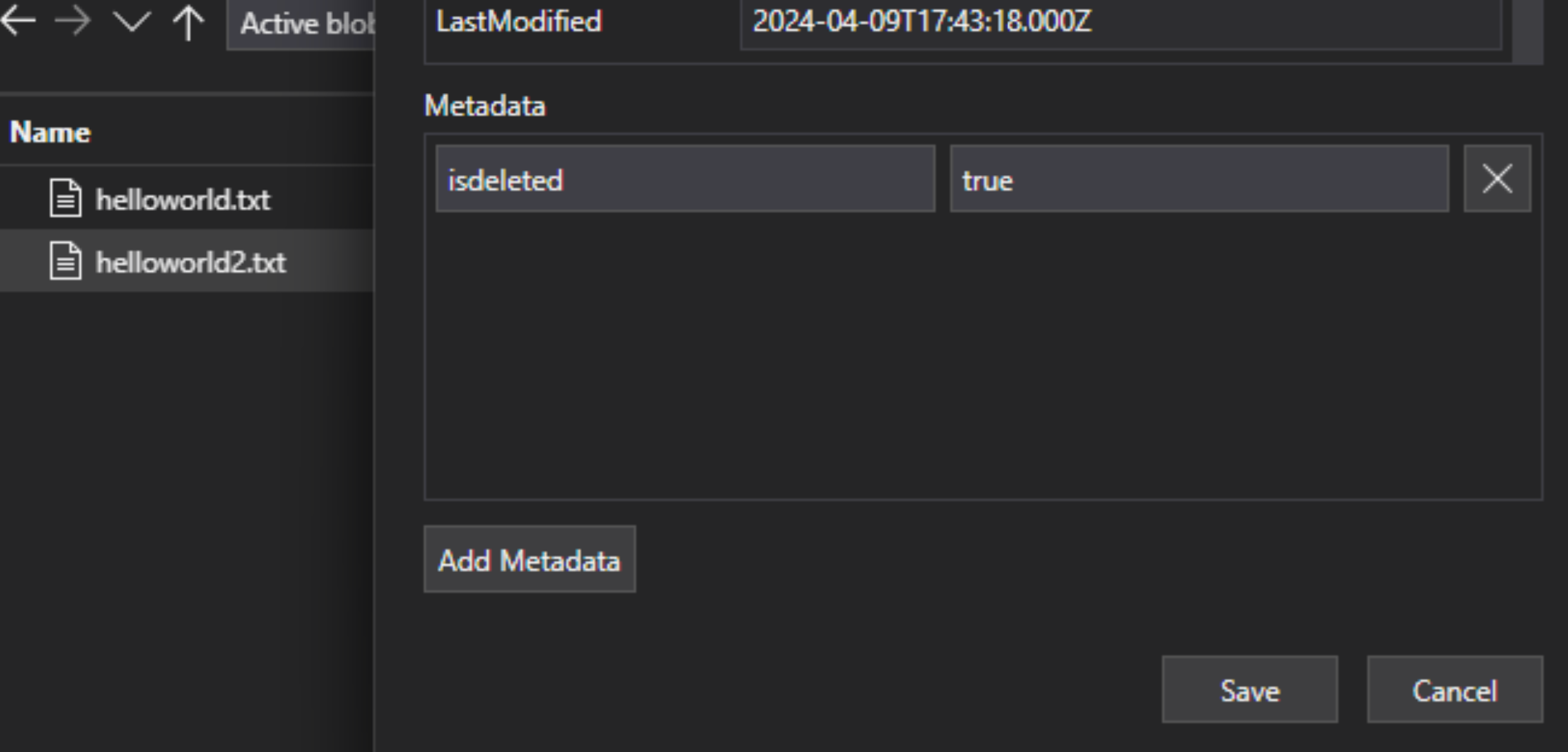
Azure AI Search에서 데이터 원본 정의를 편집하여 “dataDeletionDetectionPolicy” 속성을 포함합니다. 예를 들어 다음 정책은 값이 true인 메타데이터 속성 "IsDeleted"가 있는 경우 파일을 삭제할 것으로 간주합니다.
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

인덱서가 실행되고 검색 인덱스에서 문서를 삭제한 후 데이터 레이크에서 실제 파일을 삭제할 수 있습니다.
몇 가지 핵심 사항은 다음과 같습니다.
인덱서 실행을 예약하면 이 프로세스를 자동화할 수 있습니다. 모든 증분 인덱싱 시나리오에 대한 일정을 권장합니다.
첫 번째 인덱서 실행에서 삭제 검색 정책이 설정되지 않은 경우 업데이트된 구성을 읽도록 인덱서 다시 설정을 해야 합니다.
삭제 검색은 사용자 지정 메타데이터에 대한 종속성으로 인해 Amazon S3 및 Google Cloud Storage 바로 가기에서 지원되지 않습니다.
인덱스에 검색 필드 추가
검색 인덱스 OneLake 데이터 레이크 파일의 콘텐츠 및 메타데이터를 허용하는 필드를 추가합니다.
인덱스를 만들거나 업데이트하여 파일 콘텐츠 및 메타데이터를 저장하는 검색 필드를 정의합니다.
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }문서 키 필드("key": true)를 만듭니다. 파일 콘텐츠의 경우 가장 적합한 후보는 메타데이터 속성입니다.
metadata_storage_path(기본값) 개체 또는 파일의 전체 경로입니다. 키 필드(이 예제의 "ID")는 기본값이므로 metadata_storage_path 값으로 채워집니다.metadata_storage_name, 이름이 고유한 경우에만 사용할 수 있습니다. 이 필드를 키로 사용하려면"key": true를 이 필드 정의로 이동합니다.파일에 추가하는 사용자 지정 메타데이터 속성입니다. 이 옵션을 사용하려면 파일 업로드 프로세스에서 해당 메타데이터 속성을 모든 Blob에 추가해야 합니다. 키가 필수 속성이므로 값이 누락된 파일은 인덱싱되지 않습니다. 사용자 지정 메타데이터 속성을 키로 사용하는 경우 해당 속성을 변경하지 마세요. 키 속성이 변경되면 인덱서는 동일한 파일에 대해 중복 문서를 추가합니다.
메타데이터 속성에는 종종 문서 키에 유효하지 않은
/및-와 같은 문자가 포함됩니다. 인덱서에는 "base64EncodeKeys" 속성(기본적으로 true)이 있으므로 구성이나 필드 매핑이 필요하지 않고 메타데이터 속성을 자동으로 인코딩합니다.파일의 "content" 속성을 통해 각 파일에서 추출된 텍스트를 저장할 "콘텐츠" 필드를 추가합니다. 이 이름을 반드시 사용해야 하는 것은 아니지만 이렇게 하면 암시적 필드 매핑을 활용할 수 있습니다.
표준 메타데이터 속성에 대한 필드를 추가합니다. 인덱서는 사용자 지정 메타데이터 속성, 표준 메타데이터 속성 및 콘텐츠 관련 메타데이터 속성을 읽을 수 있습니다.
OneLake 파일 인덱서 구성 및 실행
인덱스 및 데이터 원본이 만들어지면 인덱서 만들 준비가 된 것입니다. 인덱서 구성은 런타임 동작을 제어하는 입력, 매개 변수 및 속성을 지정합니다. 인덱싱할 Blob 부분을 지정할 수도 있습니다.
이름을 지정하고 데이터 원본 및 대상 인덱스를 참조하여 인덱서를 만들거나 업데이트합니다.
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }기본값(문서 10개)이 사용 가능한 리소스를 충분히 활용하지 못하거나 초과하는 경우 "batchSize"를 설정합니다. 기본 일괄 처리 크기는 데이터 원본에 따라 다릅니다. 파일 인덱싱은 더 큰 평균 문서 크기를 인식하여 일괄 처리 크기를 10 문서로 설정합니다.
"구성"에서 파일 형식에 따라 인덱싱되는 파일을 제어하거나 모든 파일을 검색하기 위해 지정되지 않은 상태로 둡니다.
"indexedFileNameExtensions"의 경우 쉼표로 구분된 파일 확장명 목록(선행 점이 있음)을 제공합니다."excludedFileNameExtensions"에 대해 동일한 작업을 수행하여 건너뛰어야 하는 확장을 나타냅니다. 동일한 확장명이 두 목록에 있으면 인덱싱에서 제외됩니다."구성"에서 "dataToExtract"를 설정하여 인덱싱되는 파일의 일부를 제어합니다.
"contentAndMetadata"가 기본값입니다. 파일에서 추출된 모든 메타데이터 및 텍스트 콘텐츠가 인덱싱되도록 지정합니다.
"storageMetadata"는 표준 파일 속성 및 사용자 지정 메타데이터가 인덱싱되도록 지정합니다. 속성은 Azure Blob에 대해 문서화되어 있지만 SAS 관련 메타데이터를 제외하고 파일 속성은 OneLkae에 대해 동일합니다.
"allMetadata"는 찾은 콘텐츠 형식에 대한 표준 파일 속성 및 메타데이터가 파일 콘텐츠에서 추출되고 인덱싱되도록 지정합니다.
"구성"에서 파일을 여러 검색 문서를 매핑해야 하거나 일반 텍스트, JSON 문서또는 CSV 파일로 구성되는 경우 "parsingMode"를 설정합니다.
필드 이름 또는 형식이 다르거나 검색 인덱스에서 여러 버전의 원본 필드가 필요한 경우 필드 매핑을 지정합니다.
파일 인덱싱에서는 인덱서가 “content” 및 메타데이터 속성을 인덱스의 유사한 이름 및 형식 필드에 매핑하는 기능을 기본 제공하므로 필드 매핑을 종종 생략할 수 있습니다. 메타데이터 속성의 경우 인덱서는
-하이픈을 검색 인덱스의 밑줄로 자동으로 바꿉니다.
다른 속성에 대한 자세한 내용은 인덱서 만듭니다. 매개 변수 설명의 전체 목록은 REST API의 인덱서 만들기(REST)를 참조하세요. 매개 변수는 OneLake에 대해 동일합니다.
기본적으로 인덱서는 만들 때 자동으로 실행됩니다. "disabled"를 true로 설정하여 이 동작을 변경할 수 있습니다. 인덱서 실행을 제어하려면 요청 시 인덱서를 실행하거나 일정에 배치합니다.
인덱서 상태 확인
여기에서 인덱서 상태 및 실행 기록을 모니터링하기 위한 여러 가지 방법을 알아봅니다.
오류 처리
인덱싱 중에 일반적으로 발생하는 오류에는 지원되지 않는 콘텐츠 형식, 누락된 콘텐츠 또는 대형 파일이 포함됩니다. 기본적으로 OneLake 파일 인덱서는 지원되지 않는 콘텐츠 형식의 파일을 발견하면 즉시 중지됩니다. 그러나 오류가 발생한 경우에도 인덱싱을 진행하고, 나중에 개별 문서를 디버그하려고 할 수 있습니다.
일시적인 오류는 여러 플랫폼 및 제품과 관련된 솔루션에 일반적입니다. 그러나 인덱서가 일정하게 유지되는 경우(예: 5분마다) 인덱서는 다음 실행에서 해당 오류에서 복구할 수 있어야 합니다.
오류가 발생할 때 인덱서의 응답을 제어하는 다섯 가지 인덱서 속성이 있습니다.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| 매개 변수 | 유효한 값 | 설명 |
|---|---|---|
| "maxFailedItems" | -1, null 또는 0, 양의 정수 | 또한 Blob을 구문 분석하거나 문서를 인덱스를 추가할 때 임의 처리 지점에서 오류가 발생하는 경우에도 인덱싱을 계속 진행합니다. 이러한 속성을 허용 가능한 오류 수로 설정합니다. -1 값을 사용하면 오류가 발생하는 횟수에 관계 없이 처리를 수행할 수 있습니다. 그렇지 않으면 이 값은 양의 정수입니다. |
| "maxFailedItemsPerBatch" | -1, null 또는 0, 양의 정수 | 위와 동일하지만 일괄 처리 인덱싱에 사용됩니다. |
| "failOnUnsupportedContentType" | true 또는 false | 인덱서가 콘텐츠 형식을 결정할 수 없는 경우 작업을 계속할지 또는 실패 처리할지 지정합니다. |
| "failOnUnprocessableDocument" | true 또는 false | 인덱서가 지원되는 콘텐츠 형식의 문서를 처리할 수 없는 경우 작업을 계속할지 또는 실패 처리할지 지정합니다. |
| "indexStorageMetadataOnlyForOversizedDocuments" | true 또는 false | 너무 큰 Blob은 기본적으로 오류로 처리됩니다. 이 매개 변수를 true로 설정하면 콘텐츠를 인덱싱할 수 없는 경우에도 인덱서가 메타데이터를 인덱싱하려고 합니다. Blob 크기에 제한은 서비스 제한을 참조하세요. |
다음 단계
데이터 가져오기 및 벡터화 마법사를 작동하는 방식을 검토하고 이 인덱서에 대해 사용해 보세요. 통합 벡터화를 사용하여 기본 스키마를 사용하여 벡터 또는 하이브리드 검색에 대한 포함을 청크하고 만들 수 있습니다.