자습서: REST를 사용하여 Azure Storage에서 중첩된 Markdown Blob 인덱싱
참고 항목
이 기능은 현재 공개 미리 보기로 제공됩니다. 이 미리 보기는 서비스 수준 계약 없이 제공되며 프로덕션 워크로드에는 사용하지 않는 것이 좋습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
Azure AI Search는 Markdown 데이터를 읽는 방법을 알고 있는 인덱서를 사용하여 Azure Blob Storage의 Markdown 문서 및 배열을 인덱싱할 수 있습니다.
이 자습서에서는 Markdown 구문 분석 모드를 사용하여 oneToMany 인덱싱된 Markdown 파일을 인덱싱하는 방법을 보여 줍니다. REST 클라이언트 및 Search REST API를 사용하여 다음 작업을 수행합니다.
- 샘플 데이터 설정 및
azureblob데이터 원본 구성 - 검색 가능한 콘텐츠를 포함하는 Azure AI 검색 인덱스 만들기
- 인덱서 만들기 및 실행하여 컨테이너를 읽고 검색 가능한 콘텐츠 추출
- 방금 만든 인덱스 검색
Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
필수 조건
참고 항목
이 자습서에서는 체험 서비스를 사용할 수 있습니다. 체험 검색 서비스에서는 인덱스, 인덱서 및 데이터 원본이 각각 3개로 제한됩니다. 이 자습서에서는 각각을 하나씩 만듭니다. 시작하기 전에 새 리소스를 수용할 수 있는 공간이 서비스에 있는지 확인하세요.
Markdown 문서 만들기
다음 Markdown을 복사하여 이름이 지정된 sample_markdown.md파일에 붙여넣습니다. 샘플 데이터는 다양한 Markdown 요소를 포함하는 단일 Markdown 파일입니다. 무료 계층의 스토리지 한도에 머물기 위해 하나의 Markdown 파일을 선택했습니다.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
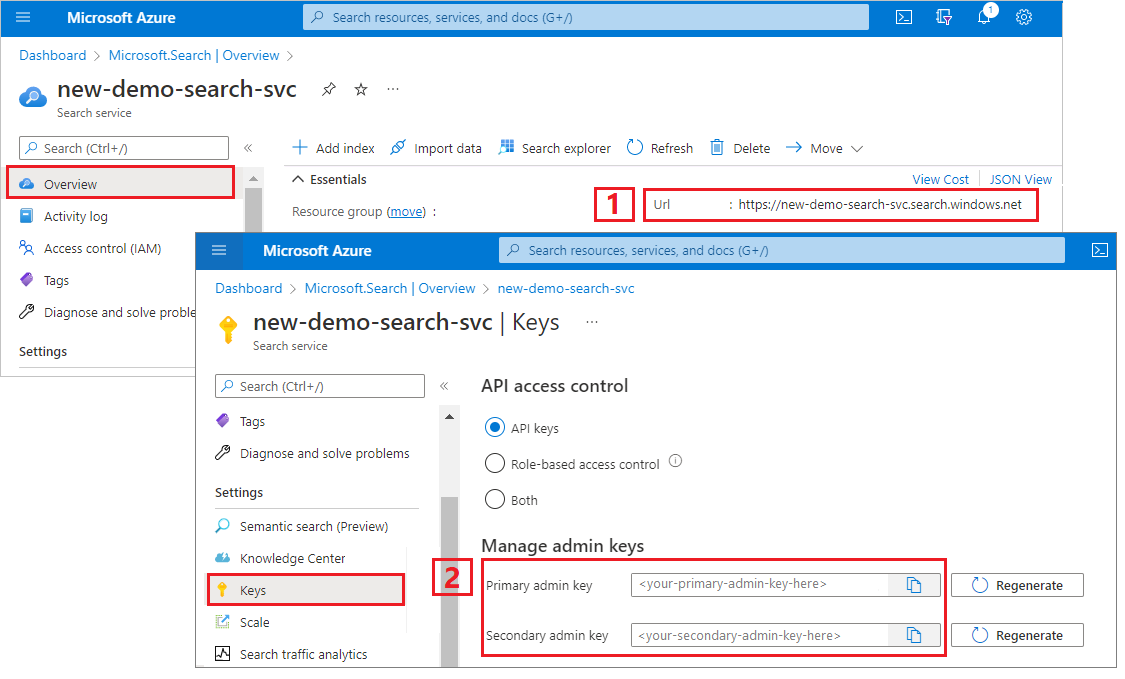
검색 서비스 URL 및 API 키 복사
이 자습서의 경우, Azure AI 검색에 연결하려면 엔드포인트와 API 키가 필요합니다. Azure Portal에서 이러한 값을 가져올 수 있습니다. 대체 연결 방법은 관리 ID를 참조 하세요.
Azure Portal에 로그인하고 검색 서비스 개요 페이지로 이동한 다음, URL을 복사합니다. 엔드포인트의 예는 다음과 같습니다.
https://mydemo.search.windows.net설정>키에서 관리자 키를 복사합니다. 관리자 키는 개체를 추가, 수정, 삭제하는 데 사용됩니다. 교환 가능한 관리자 키는 2개입니다. 둘 중 하나를 복사합니다.
REST 파일 설정
Visual Studio Code를 시작하고 새 파일을 만듭니다.
요청에 사용되는 변수에 대한 값을 제공합니다.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERE.rest또는.http파일 확장자를 사용하여 파일을 저장합니다.
REST 클라이언트에 대한 도움이 필요한 경우 빠른 시작: REST를 사용하여 텍스트 검색을 참조하세요.
데이터 원본 만들기
REST(데이터 원본 만들기)에 인덱싱할 데이터를 지정하는 데이터 원본 연결을 만듭니다.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
요청을 보냅니다. 응답은 다음과 같아야 합니다.
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
인덱스 만들기
인덱스 만들기(REST) 검색 서비스에 검색 인덱스가 만들어집니다. 인덱스는 모든 필드와 해당 특성을 지정합니다.
일대다 구문 분석에서 검색 문서는 관계의 '다' 측면을 정의합니다. 인덱스에서 지정하는 필드에 따라 검색 문서의 구조가 결정됩니다.
파서가 지원하는 Markdown 요소에 대한 필드만 필요합니다. 이러한 필드는 다음과 같습니다.
content: 문서의 해당 지점에서 헤더 메타데이터를 기반으로 특정 위치에 있는 원시 Markdown을 포함하는 문자열입니다.sections: 원하는 헤더 수준까지 헤더 메타데이터의 하위 필드를 포함하는 개체입니다. 예를 들어 , 로 설정된 경우markdownHeaderDepth문자열 필드h1h2및h3.h3이러한 필드는 인덱스에 이 구조를 미러링하거나 형식/sections/h1sections/h2의 필드 매핑 등을 통해 인덱싱됩니다. 컨텍스트 내 예제는 다음 샘플에서 인덱스 및 인덱서 구성을 참조하세요. 포함된 하위 필드는 다음과 같습니다.h1- h1 헤더 값을 포함하는 문자열입니다. 문서의 이 시점에서 설정되지 않은 경우 빈 문자열입니다.- (선택 사항)
h2- h2 헤더 값을 포함하는 문자열입니다. 문서의 이 시점에서 설정되지 않은 경우 빈 문자열입니다. - (선택 사항)
h3- h3 헤더 값을 포함하는 문자열입니다. 문서의 이 시점에서 설정되지 않은 경우 빈 문자열입니다. - (선택 사항)
h4- h4 헤더 값을 포함하는 문자열입니다. 문서의 이 시점에서 설정되지 않은 경우 빈 문자열입니다. - (선택 사항)
h5- h5 헤더 값을 포함하는 문자열입니다. 문서의 이 시점에서 설정되지 않은 경우 빈 문자열입니다. - (선택 사항)
h6- h6 헤더 값을 포함하는 문자열입니다. 문서의 이 시점에서 설정되지 않은 경우 빈 문자열입니다.
ordinal_position: 문서 계층 구조 내의 구역 위치를 나타내는 정수 값입니다. 이 필드는 서수 위치 1부터 시작하여 각 콘텐츠 블록에 대해 순차적으로 증가하여 문서에 나타나는 대로 원래 시퀀스의 섹션 순서를 지정하는 데 사용됩니다.
이 구현은 인덱서의 필드 매핑을 활용하여 보강된 콘텐츠에서 인덱스로 매핑합니다. 구문 분석된 일대다 문서 구조에 대한 자세한 내용은 인덱스 markdown Blob을 참조 하세요.
이 예제에서는 필드 매핑을 사용 또는 사용하지 않고 데이터를 인덱싱하는 방법에 대한 샘플을 제공합니다. 이 경우 문서의 제목이 포함된 것을 h1 알고 있으므로 이 문서의 제목을 명명된 title필드에 매핑할 수 있습니다. 또한 필드와 필드를 각각 매핑 h2 합니다 h2_subheader h3_subheader.h3 content Markdown에서 해당 이름을 사용하여 필드로 직접 추출되므로 필드와 ordinal_position 필드를 매핑할 필요가 없습니다. 필드 매핑이 필요하지 않은 전체 인덱스 스키마의 예는 이 섹션의 끝을 참조하세요.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
필드 매핑이 없는 구성의 인덱스 스키마
필드 매핑을 사용하면 원하는 인덱스 셰이프에 맞게 보강된 콘텐츠를 조작하고 필터링할 수 있지만 보강된 콘텐츠를 직접 사용할 수 있습니다. 이 경우 스키마는 다음과 같습니다.
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
다시 말해, 섹션 개체 markdownHeaderDepth h3에 하위 h3 필드가 있습니다.
이 스키마를 사용하도록 선택하는 경우 나중에 요청을 적절하게 조정해야 합니다. 이렇게 하려면 인덱서 구성에서 필드 매핑을 제거하고 해당 필드 이름을 사용하도록 검색 쿼리를 업데이트해야 합니다.
인덱서 만들기 및 실행
인덱서 만들기 검색 서비스에 인덱서가 만들어집니다. 인덱서는 데이터 원본에 연결하고, 데이터를 로드 및 인덱싱하며, 선택적으로 데이터 새로 고침을 자동화하는 일정을 제공합니다.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
주요 정보:
인덱서는 헤더만 구문 분석합니다
h3. 하위 수준 머리글(h4,,h5h6)은 일반 텍스트로 처리되고 필드에 표시됩니다content. 이 때문에 인덱스 및 필드 매핑은 깊이h3까지만 존재합니다.content및ordinal_position필드는 보강된 콘텐츠의 해당 이름과 함께 존재하기 때문에 필드 매핑이 필요하지 않습니다.
쿼리 실행
첫 번째 문서를 로드하는 즉시 검색을 시작할 수 있습니다.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
요청을 보냅니다. 이것은 인덱스에 검색 가능으로 표시된 모든 필드를 문서 수와 함께 반환하는 지정되지 않은 전체 텍스트 검색 쿼리입니다. 응답은 다음과 같아야 합니다.
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
문자열을 검색할 search 매개 변수를 추가합니다.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
요청을 보냅니다. 응답은 다음과 같아야 합니다.
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
주요 정보:
로
markdownHeaderDepth설정h3h4되기 때문에 , ,h5및h6헤더는 일반 텍스트로 처리되므로 필드에 표시됩니다content.서수 위치는 다음과 같습니다
4. 이 콘텐츠는 총 22개 콘텐츠 섹션 중 네 번째로 표시됩니다.
select 매개 변수를 추가하여 결과를 더 적은 필드로 제한합니다. filter을(를) 추가하여 검색 범위를 더 좁힐 수 있습니다.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
필터의 경우 논리 연산자(및, 그렇지 않음) 및 비교 연산자(eq, ne, gt, lt, ge, le)를 사용할 수도 있습니다. 문자열 비교는 대/소문자를 구분합니다. 자세한 내용 및 예제는 쿼리 만들기를 참조하세요.
참고 항목
$filter 매개 변수는 인덱스 생성 시 필터링 가능한 것으로 표시된 필드에서만 작동합니다.
다시 설정하고 다시 실행
인덱서를 다시 설정하여 실행 기록을 지울 수 있으므로 전체 다시 실행할 수 있습니다. 다음 GET 요청은 다시 설정한 다음 다시 실행합니다.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
리소스 정리
사용자 고유의 구독에서 작업하는 경우 프로젝트의 끝에서 더 이상 필요하지 않은 리소스를 제거하는 것이 좋습니다. 계속 실행되는 리소스에는 요금이 부과될 수 있습니다. 리소스를 개별적으로 삭제하거나 리소스 그룹을 삭제하여 전체 리소스 세트를 삭제할 수 있습니다.
Azure Portal을 사용하여 인덱스, 인덱서 및 데이터 원본을 삭제할 수 있습니다.
다음 단계
Azure Blob 인덱싱의 기본 사항에 익숙해졌으므로 이제 Azure Storage의 Markdown Blob에 대한 인덱서 구성을 좀 더 자세히 살펴보겠습니다.