Azure AI Search에서 전체 텍스트 쿼리 만들기
전체 텍스트 검색을 위한 쿼리를 빌드하는 경우 이 문서에서는 요청 설정 단계를 제공합니다. 또한 쿼리 구조를 소개하고 필드 특성 및 언어 분석기가 쿼리 결과에 미치는 영향을 설명합니다.
필수 조건
검색 인덱스에 대한 읽기 권한입니다. 읽기 권한의 경우 요청에 쿼리 API 키를 포함하거나 호출자에게 인덱스 데이터 검색 읽기 권한자 권한을 부여합니다.
전체 텍스트 쿼리 요청의 예
Azure AI 검색에서 쿼리는 단일 검색 인덱스의 문서 컬렉션에 대한 읽기 전용 요청이며, 쿼리 실행을 알리고 반환되는 응답을 형성하는 매개 변수가 포함되어 있습니다.
전체 텍스트 쿼리는 search 매개 변수에 지정되며 용어, 따옴표로 묶인 구 및 연산자로 구성됩니다. 다른 매개 변수는 요청에 더 많은 정의를 추가합니다.
다음 검색 POST REST API 호출은 언급된 매개 변수를 사용하는 쿼리 요청을 보여 줍니다.
POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "NY +view",
"queryType": "simple",
"searchMode": "all",
"searchFields": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"select": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"top": 10,
"count": true
}
핵심 내용
search는 연산자를 포함하거나 포함하지 않는 일치 기준(일반적으로 전체 용어 또는 구문)을 제공합니다. 인덱스 스키마에서 검색 가능한 것으로 특성이 지정된 모든 필드는 이 매개 변수의 후보입니다.queryType는 파서(단순, 전체)를 설정합니다. 기본 단순 쿼리 파서는 전체 텍스트 검색에 최적입니다. 전체 Lucene 쿼리 파서는 정규식, 근접 검색, 유사 항목, 와일드카드 검색과 같은 고급 쿼리 구문을 위한 것입니다. 이 매개 변수는 쿼리 응답에서 고급 의미 체계 모델링의 의미 체계 순위에 대한 의미 체계로 설정할 수도 있습니다.searchMode는 일치 항목이 식의 모든 조건(정밀도 선호) 또는 조건 (재현율 선호)을 기반으로 하는지 여부를 지정합니다. 기본값은 any입니다. 큰 텍스트 블록(콘텐츠 필드 또는 긴 설명)이 포함된 인덱스에 부울 연산자를 많이 사용할 것으로 예상되는 경우 매개 변수를 사용하여 쿼리searchMode=Any|All를 테스트하여 해당 설정이 부울 검색에 미치는 영향을 평가해야 합니다.searchFields는 쿼리 실행을 검색 가능한 특정 필드로 제한합니다. 개발하는 동안 선택 및 검색에 동일한 필드 목록을 사용하는 것이 좋습니다. 그렇지 않으면 결과에 표시될 수 없는 필드 값을 기준으로 하여 문서가 반환된 이유가 불확실해질 수 있습니다.
응답을 형성하는 데 사용되는 매개 변수는 다음과 같습니다.
select는 응답에 반환할 필드를 지정합니다. 인덱스로 검색 가능한 것으로 표시된 필드만 select 문에서 사용할 수 있습니다.top은 지정된 수의 가장 일치하는 문서를 반환합니다. 이 예제에서는 10개의 적중 사항만 반환됩니다. top과 skip(표시되지 않음)을 사용하여 결과를 페이징할 수 있습니다.count는 전체 인덱스에서 전반적으로 일치하는 문서의 개수를 알려 줍니다. 이는 반환되는 것보다 많을 수 있습니다.orderby는 등급 또는 위치와 같은 값을 기준으로 결과를 정렬하려는 경우에 사용됩니다. 그렇지 않으면 기본값은 관련성 점수를 사용하여 결과의 순위를 지정하는 것입니다. 이 매개 변수의 후보가 되려면 필드가 정렬 가능한 상태로 지정되어야 합니다.
클라이언트 선택
초기 개발 및 개념 증명 테스트를 위해 Azure Portal 또는 REST 클라이언트로 시작합니다. 두 가지 방식 모두 대화형이며 대상 테스트에 유용하며 코드를 작성하지 않고도 다양한 속성의 효과를 평가하는 데 도움이 됩니다.
앱 내에서 검색을 호출하려면 .NET, Java, JavaScript 및 Python용 Azure SDK의 클라이언트 라이브러리를 사용합니다 Azure.Document.Search .
Azure Portal에서 인덱스를 열 때 필드 특성에 쉽게 액세스할 수 있도록 나란히 탭의 인덱스 JSON 정의와 함께 검색 탐색기를 사용할 수 있습니다. 쿼리를 테스트하는 동안 검색 가능, 정렬 가능, 필터링 가능 및 패싯 가능 필드를 보려면 필드 표를 확인합니다.
Azure Portal에 로그인하고 검색 서비스를 찾습니다.
서비스에서 인덱스를 선택하고 인덱스를 선택합니다.
즉시 쿼리할 수 있도록 인덱스가 검색 탐색기 탭에 열립니다. 쿼리 구문을 지정하려면 JSON 보기로 전환합니다.
다음은 Hotels 샘플 인덱스에 작동하는 전체 텍스트 검색 쿼리 식입니다.
{ "search": "pool spa +airport", "queryType": "simple", "searchMode": "any", "searchFields": "Description, Tags", "select": "HotelName, Description, Tags", "top": 10, "count": true }다음 스크린샷은 쿼리와 응답을 보여 줍니다.
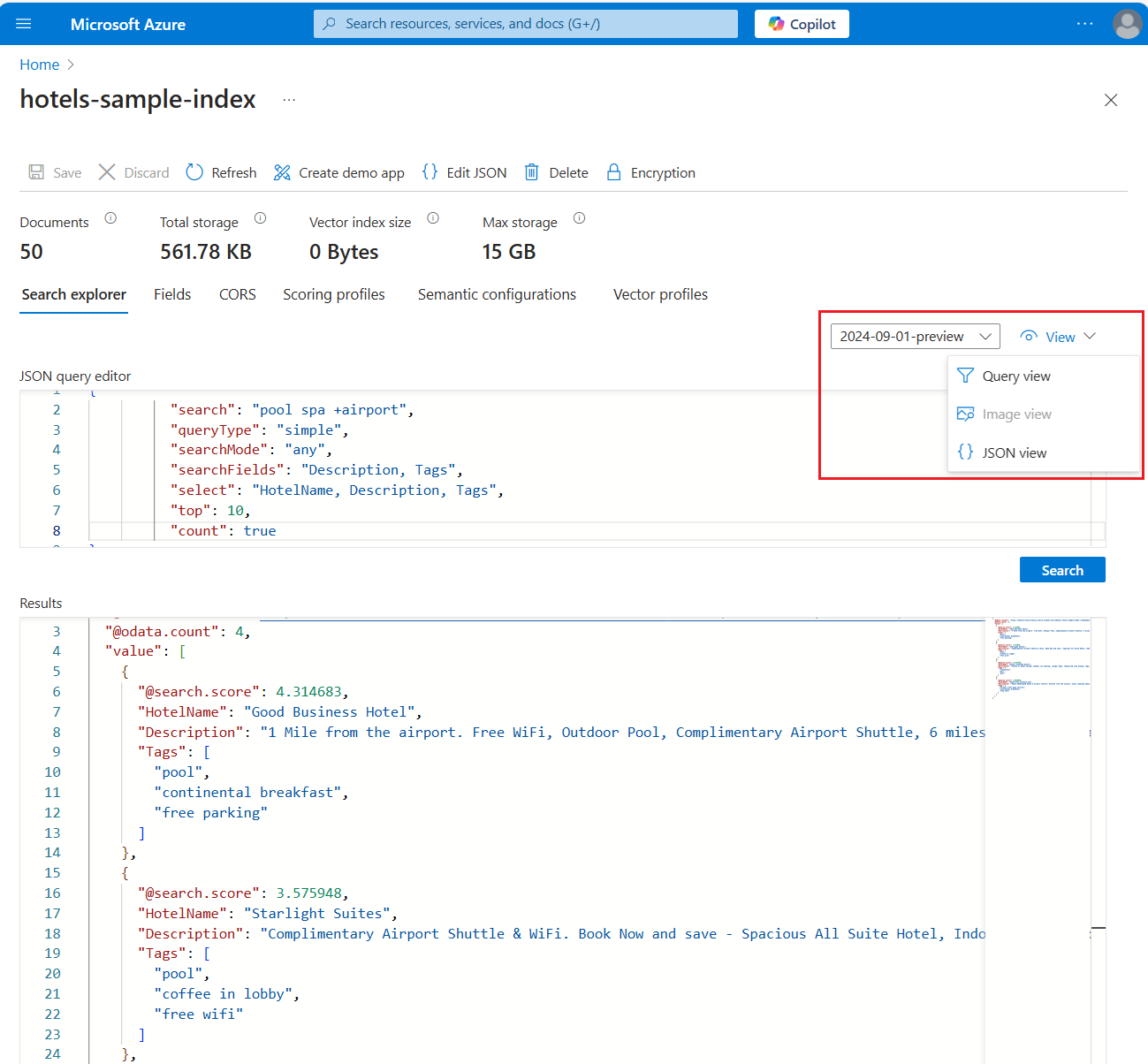
쿼리 형식 선택: 기본 | 전체
쿼리가 전체 텍스트 검색인 경우 쿼리 파서는 검색 용어 및 구로 전달되는 텍스트를 처리하는 데 사용됩니다. Azure AI 검색은 두 개의 쿼리 파서를 제공합니다.
단순 파서는 간단한 쿼리 구문을 이해합니다. 이 파서는 자유 형식 텍스트 쿼리에서 속도와 효율성의 기본값으로 선택됩니다. 구문은 용어 및 구 검색에 대한 일반 검색 연산자(AND, OR, NOT) 및 접두사() 검색(
*sea*시애틀 및 시사이드)을 지원합니다. 일반적인 권장 사항은 간단한 파서를 먼저 시도한 후 애플리케이션 요구 사항에 따라 더 강력한 쿼리가 필요한 경우 전체 파서로 이동하는 것입니다.요청에
queryType=full을 추가할 때 사용되는 전체 Lucene 쿼리 구문은 Apache Lucene 파서를 기반으로 합니다.
전체 구문과 단순 구문은 모두 동일한 접두사와 부울 연산을 지원하는 범위와 겹치지만 전체 구문은 더 많은 연산자를 제공합니다. 전체적으로 부울 식에 대한 연산자가 더 많고 유사 항목 검색, 와일드카드 검색, 근접 검색 및 정규식과 같은 고급 쿼리에 대한 연산자가 더 많이 있습니다.
쿼리 메서드 선택
검색은 기본적으로 사용자 중심 활동으로 검색 상자에서 용어나 구가 수집되거나 페이지의 클릭 이벤트에서 수집됩니다. 다음 표에는 예상 검색 환경과 함께 사용자 입력을 수집할 수 있는 메커니즘이 요약되어 있습니다.
| 입력 | 환경 |
|---|---|
| Search 메서드 | 사용자는 용어 또는 구를 연산자 유의 여부에 관계없이 검색 상자에 입력하고 검색을 선택하여 요청을 보냅니다. 검색은 동일한 요청에 대해 필터와 함께 사용할 수 있지만 자동 완성이나 제안 사항과는 함께 사용할 수 없습니다. |
| Autocomplete 메서드 | 사용자가 몇 개의 문자를 입력하면 각각의 새 문자를 입력한 후에 쿼리가 시작됩니다. 응답은 인덱스에서 완성된 문자열입니다. 제공된 문자열이 유효한 경우 사용자는 검색을 선택하여 해당 쿼리를 서비스로 보냅니다. |
| Suggestions 메서드 | Autocomplete 메서드와 마찬가지로 사용자가 몇 개의 문자를 입력하면 증분 쿼리가 생성됩니다. 응답은 일반적으로 고유하거나 설명 필드로 표시되는 일치하는 문서의 드롭다운 목록입니다. 선택 영역 중 하나가 유효한 경우 사용자는 하나를 선택하고 일치하는 문서가 반환됩니다. |
| 패싯 탐색 | 페이지에는 클릭 가능한 탐색링크나 검색 범위를 좁히는 이동 경로가 표시됩니다. 패싯 탐색구조는 초기 쿼리를 기반으로 하여 동적으로 구성됩니다. 예를 들어 search=*를 사용하여 가능한 모든 범주로 구성된 패싯 탐색 트리를 채울 수 있습니다. 패싯 탐색 구조는 쿼리 응답에서 생성되지만 다음 쿼리를 표현하는 메커니즘이기도 합니다. REST API 참조에서 facets은 문서 검색 작업의 쿼리 매개 변수로 설명되지만 search 매개 변수 없이 사용할 수 있습니다. |
| Filter 메서드 | 필터는 패싯에서 결과의 범위를 좁히는 데 사용됩니다. 페이지 이면의 필터를 구현할 수도 있습니다. 예를 들어 언어별 필드를 사용하면 페이지를 초기화할 수 있습니다. REST API 참조에서 $filter은 문서 검색 작업의 쿼리 매개 변수로 설명되지만 search 매개 변수 없이 사용할 수 있습니다. |
쿼리에 대한 필드 특성의 효과
쿼리 유형과 컴퍼지션에 대해 잘 알고 있는 경우 쿼리 요청의 매개 변수는 인덱스의 필드 특성에 따라 달라집니다. 예를 들어 검색 가능 및 조회 가능으로 표시된 필드만 쿼리 및 검색 결과에 사용할 수 있습니다. 요청에서 search, filter 및 orderby 매개 변수를 설정할 때 예기치 않은 결과를 방지하기 위해 특성을 확인해야 합니다.
호텔 샘플 인덱스의 다음 스크린샷에서는 LastRenovationDate 및 Rating의 마지막 두 필드만 정렬할 수 있으며 유일한 절에서 "$orderby" 사용하기 위한 요구 사항입니다.
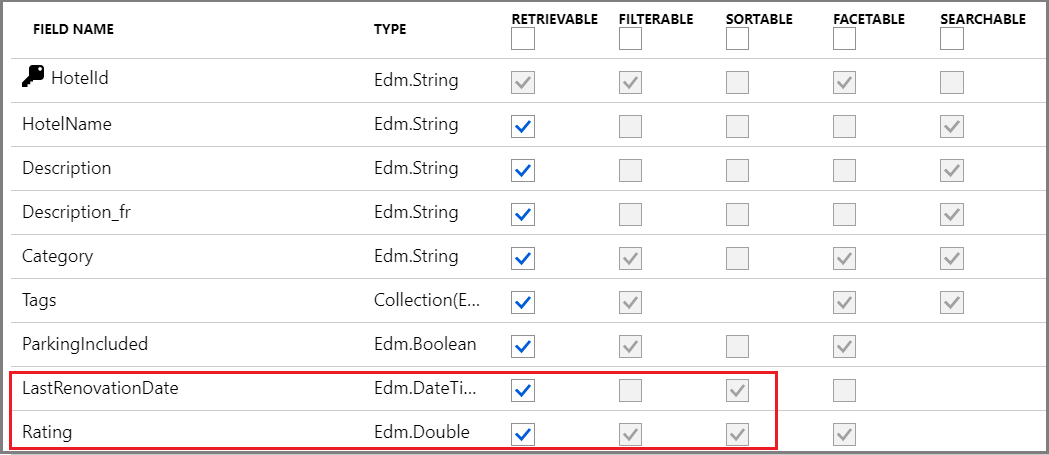
필드 특성 정의는 인덱스 만들기(REST API)를 참조하세요.
토큰이 쿼리에 미치는 영향
인덱싱하는 동안 검색 엔진은 문자열에 텍스트 분석기를 사용하여 쿼리 시 일치 항목을 찾을 가능성을 최대화합니다. 최소한 소문자 문자열이지만 분석기에 따라 분류 정리 및 중지 단어 제거를 수행할 수도 있습니다. 일반적으로 큰 문자열이나 복합 단어는 공백, 하이픈 또는 대시로 구분되며 별도의 토큰으로 인덱싱됩니다.
핵심은 인덱스에 포함된 내용과 인덱스에 실제로 포함된 내용이 다를 수 있다는 것입니다. 쿼리에서 예상된 결과가 반환되지 않는 경우 텍스트 분석(REST API)을 통해 분석기에서 생성한 토큰을 검사할 수 있습니다. 토큰화 및 쿼리에 미치는 영향에 대한 자세한 내용은 부분 용어 검색 및 특수 문자가 있는 패턴을 참조하세요.
관련 콘텐츠
이제 쿼리 요청의 작동 방식에 대한 이해도가 높아졌으므로 실습 환경에 대해 다음 빠른 시작을 시도합니다.