Azure Data Box를 사용하여 온-프레미스 HDFS 저장소에서 Azure Storage로 마이그레이션
Data Box 디바이스를 사용하여 Hadoop 클러스터의 온-프레미스 HDFS 저장소에서 Azure Storage(Blob Storage 또는 Data Lake Storage)로 데이터를 마이그레이션할 수 있습니다. Data Box Disk, 80TB Data Box 또는 770TB Data Box Heavy 중에서 선택할 수 있습니다.
이 문서에서는 다음 작업을 완료하는 방법을 보여 줍니다.
- 데이터 마이그레이션 준비
- Data Box Disk, Data Box 또는 Data Box Heavy 디바이스로 데이터 복사
- 디바이스를 Microsoft에 다시 배송
- 파일 및 디렉터리에 액세스 권한 적용(Data Lake Storage에만 해당)
필수 조건
마이그레이션을 완료하려면 다음 항목이 필요합니다.
Azure 스토리지 계정입니다.
원본 데이터를 포함하는 온-프레미스 Hadoop 클러스터
-
Data Box 또는 Data Box Heavy를 주문합니다.
Data Box 또는 Data Box Heavy를 온-프레미스 네트워크에 케이블로 연결합니다.
준비가 되었으면 시작하겠습니다.
Data Box 디바이스에 데이터 복사
데이터가 단일 Data Box 디바이스에 맞는 경우 데이터를 Data Box 디바이스로 복사합니다.
데이터 크기가 Data Box 디바이스의 용량을 초과하는 경우에는 선택적 절차를 사용하여 데이터를 여러 Data Box 디바이스로 분할한 다음 이 단계를 수행합니다.
온-프레미스 HDFS 저장소에서 Data Box 장치로 데이터를 복사하려면 몇 가지를 설정하고 Distcp 도구를 사용합니다.
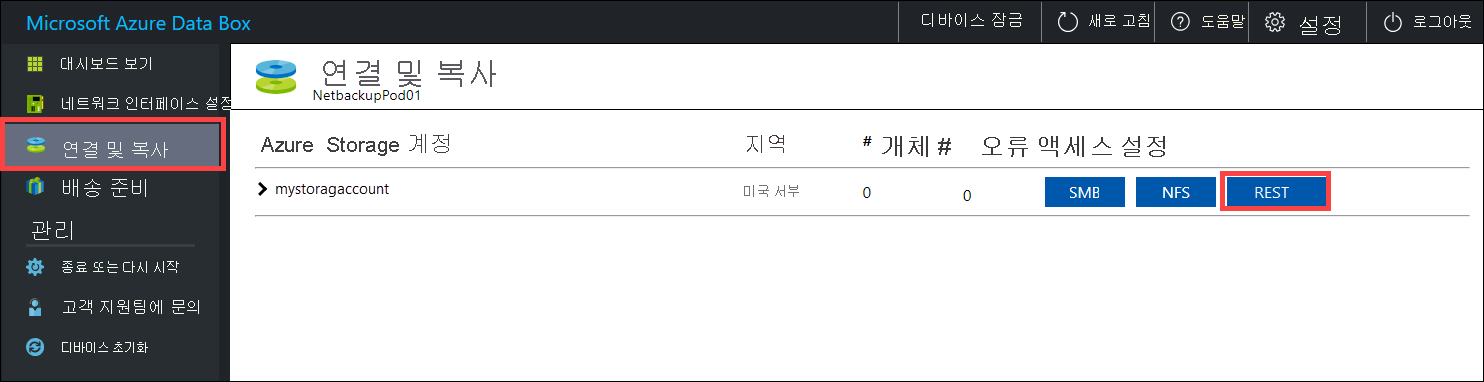
다음 단계에 따라 Blob/개체 스토리지의 REST API를 통해 데이터를 Data Box 디바이스에 복사합니다. REST API 인터페이스는 디바이스가 클러스터에 HDFS 저장소로 표시되도록 합니다.
REST를 통해 데이터를 복사하기 전에 Data Box 또는 Data Box Heavy에서 REST 인터페이스에 연결할 보안 및 연결 기본 형식을 식별합니다. Data Box의 로컬 웹 UI에 로그인하고 연결 및 복사 페이지로 이동합니다. 디바이스의 Azure Storage 계정에 대해 액세스 설정에서 REST를 찾아 선택합니다.
스토리지 계정 액세스 및 데이터 업로드 대화 상자에서 Blob 서비스 엔드포인트 및 스토리지 계정 키를 복사합니다. Blob 서비스 엔드포인트에서
https://및 후행 슬래시를 생략합니다.이 경우 엔드포인트는
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/입니다. 사용할 URI의 호스트 부분은mystorageaccount.blob.mydataboxno.microsoftdatabox.com입니다. 예를 보려면 http를 통해 REST에 연결하는 방법을 참조하세요.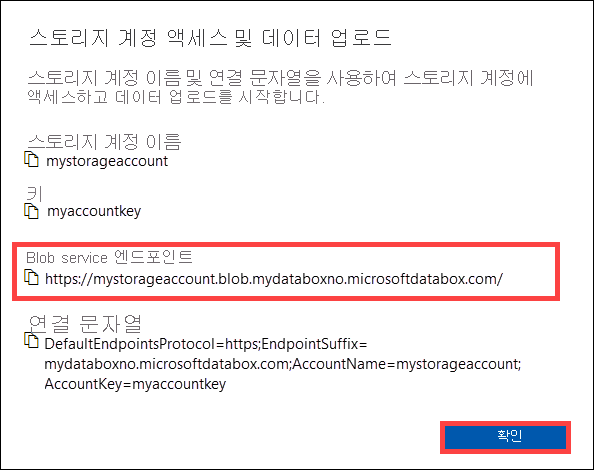
엔드포인트와 Data Box 또는 Data Box Heavy 노드 IP 주소를 각 노드의
/etc/hosts에 추가합니다.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comDNS에 다른 메커니즘을 사용하는 경우 Data Box 엔드포인트를 확인할 수 있는지 확인해야 합니다.
셸 변수
azjars를hadoop-azure및azure-storagejar 파일의 위치로 설정합니다. 이러한 파일은 Hadoop 설치 디렉터리에서 찾을 수 있습니다.이러한 파일이 있는지 확인하려면 다음 명령을 사용합니다.
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure.<hadoop_install_dir>자리 표시자를 Hadoop을 설치한 디렉터리 경로로 바꿉니다. 정규화된 경로를 사용해야 합니다.예:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jar데이터 복사에 사용하려는 스토리지 컨테이너를 만듭니다. 또한 이 명령의 일부로 대상 디렉터리를 지정해야 합니다. 이 시점에서 더미 대상 디렉터리가 될 수 있습니다.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory><blob_service_endpoint>자리 표시자를 Blob 서비스 엔드포인트의 이름으로 바꿉니다.<account_key>자리 표시자를 계정의 액세스 키로 바꿉니다.<container-name>자리 표시자를 컨테이너의 이름으로 바꿉니다.<destination_directory>자리 표시자를 데이터를 복사할 디렉터리 이름으로 바꿉니다.
list 명령을 실행하여 컨테이너 및 디렉터리를 만들었는지 확인합니다.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/<blob_service_endpoint>자리 표시자를 Blob 서비스 엔드포인트의 이름으로 바꿉니다.<account_key>자리 표시자를 계정의 액세스 키로 바꿉니다.<container-name>자리 표시자를 컨테이너의 이름으로 바꿉니다.
Hadoop HDFS의 데이터를 Data Box Blob Storage에서 이전에 만든 컨테이너로 복사합니다. 복사할 디렉터리를 찾을 수 없는 경우 이 명령은 자동으로 만듭니다.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory><blob_service_endpoint>자리 표시자를 Blob 서비스 엔드포인트의 이름으로 바꿉니다.<account_key>자리 표시자를 계정의 액세스 키로 바꿉니다.<container-name>자리 표시자를 컨테이너의 이름으로 바꿉니다.<exclusion_filelist_file>자리 표시자를 파일 제외 목록을 포함하는 파일의 이름으로 바꿉니다.<source_directory>자리 표시자를 복사할 데이터가 포함된 디렉터리 이름으로 바꿉니다.<destination_directory>자리 표시자를 데이터를 복사할 디렉터리 이름으로 바꿉니다.
-libjars옵션은hadoop-azure*.jar및 종속azure-storage*.jar파일을distcp에서 사용할 수 있도록 하는 데 사용됩니다. 일부 클러스터에 대해 이 문제가 이미 발생했을 수 있습니다.다음 예에서는
distcp명령을 사용하여 데이터를 복사하는 방법을 보여 줍니다.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/data복사 속도를 향상시키려면 다음을 수행합니다.
매퍼 수를 변경해보세요. (기본 매퍼 수는 20입니다. 위의 예는
m= 4 매퍼를 사용합니다.)-D fs.azure.concurrentRequestCount.out=<thread_number>를 체험해 보세요.<thread_number>를 매퍼당 스레드 수로 바꿉니다. 매퍼 수와 매퍼당 스레드 수의 곱m*<thread_number>는 32를 초과해서는 안 됩니다.여러
distcp를 병렬로 실행해 보세요.규모가 큰 파일은 규모가 작은 파일보다 성능이 더 좋습니다.
200GB보다 큰 파일이 있는 경우 다음 매개 변수를 사용하여 블록 크기를 100MB로 변경하는 것이 좋습니다.
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Microsoft에 Data Box 배송
Data Box 디바이스를 준비하고 Microsoft에 배송하려면 다음 단계를 수행합니다.
디바이스 준비가 완료되면 BOM 파일을 다운로드합니다. 나중에 이러한 BOM 또는 매니페스트 파일을 사용하여 Azure에 업로드된 데이터를 확인합니다.
디바이스를 종료하고 케이블을 제거합니다.
UPS를 사용하여 픽업을 예약합니다.
Data Box 디바이스의 경우 Data Box 배송을 참조하세요.
Data Box Heavy 디바이스의 경우 Data Box Heavy 배송을 참조하세요.
Microsoft에서는 디바이스를 받은 후에 데이터 센터 네트워크에 연결되고 디바이스를 주문할 때 지정한 스토리지 계정에 데이터가 업로드됩니다. 모든 데이터가 Azure에 업로드되었는지 BOM 파일에 대해 확인합니다.
파일 및 디렉터리에 액세스 권한 적용(Data Lake Storage에만 해당)
이미 Azure Storage 계정에 데이터가 있습니다. 이제 파일 및 디렉터리에 대한 액세스 권한을 적용합니다.
참고 항목
이 단계는 Azure Data Lake Storage를 데이터 저장소로 사용하는 경우에만 필요합니다. 계층적 네임스페이스가 없는 Blob Storage 계정만 데이터 저장소로 사용하는 경우 이 섹션을 건너뛸 수 있습니다.
Azure Data Lake Storage 사용 계정에 대한 서비스 주체 만들기
서비스 주체를 만들려면 포털을 사용하여 리소스에 액세스할 수 있는 Microsoft Entra 애플리케이션 및 서비스 주체 만들기를 참조하세요.
문서의 애플리케이션을 역할에 할당 섹션에 있는 단계를 수행할 때 Storage Blob 데이터 참가자 역할을 서비스 주체에 할당해야 합니다.
문서의 로그인을 위한 값 가져오기 섹션에 있는 단계를 수행하는 경우 애플리케이션 ID 및 클라이언트 비밀 값을 텍스트 파일에 저장합니다. 곧 이 값들이 필요합니다.
권한이 있는 복사된 파일의 목록 생성
온-프레미스 Hadoop 클러스터에서 다음 명령을 실행합니다.
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
이 명령은 해당 권한이 있는 복사된 파일의 목록을 생성합니다.
참고 항목
HDFS의 파일 수에 따라 이 명령을 실행하는 데 시간이 오래 걸릴 수 있습니다.
ID 목록 생성 및 Microsoft Entra ID에 매핑
copy-acls.py스크립트를 다운로드합니다. 이 도움말의 도우미 스크립트 다운로드 및 실행을 위한 에지 노드 설정 섹션을 참조하세요.이 명령을 실행하여 고유한 ID 목록을 생성합니다.
./copy-acls.py -s ./filelist.json -i ./id_map.json -g이 스크립트는 ADD 기반 ID에 맵핑해야 하는 ID가 포함된
id_map.json파일을 생성합니다.텍스트 편집기에서
id_map.json파일을 엽니다.파일에 나타나는 각 JSON 개체에 대해 Microsoft Entra UPN(사용자 계정 이름) 또는 OID(ObjectId)의
target속성을 적절한 매핑 ID를 사용하여 업데이트합니다. 작업을 완료한 후 파일을 저장합니다. 다음 단계에서 이 파일이 필요합니다.
복사한 파일에 권한 적용 및 ID 매핑 적용
Data Lake Storage 사용 계정에 복사한 데이터에 권한을 적용하려면 다음 명령을 실행합니다.
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
<storage-account-name>자리 표시자를 스토리지 계정 이름으로 바꿉니다.<container-name>자리 표시자를 컨테이너의 이름으로 바꿉니다.<application-id>및<client-secret>자리 표시자를 서비스 주체를 만들 때 수집한 애플리케이션 ID 및 클라이언트 비밀로 바꿉니다.
부록: 여러 Data Box 디바이스에서 데이터 분할
데이터를 Data Box 디바이스로 이동하기 전에 일부 도우미 스크립트를 다운로드하고, 데이터가 Data Box 디바이스에 맞게 구성되어 있는지 확인하고, 불필요한 파일을 제외해야 합니다.
도우미 스크립트를 다운로드하고 에지 노드를 설정하여 실행합니다.
온-프레미스 Hadoop 클러스터의 에지 또는 헤드 노드에서 다음 명령을 실행합니다.
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loader이 명령은 도우미 스크립트가 포함된 GitHub 리포지토리를 복제합니다.
로컬 컴퓨터에 jq 패키지가 설치되어 있는지 확인합니다.
sudo apt-get install jq요청 python 패키지를 설치합니다.
pip install requests필요한 스크립트에 대한 실행 권한을 설정합니다.
chmod +x *.py *.sh
데이터가 Data Box 디바이스에 맞게 구성되어 있는지 확인
데이터 크기가 단일 Data Box 디바이스의 크기를 초과하는 경우 여러 Data Box 디바이스에 저장할 수 있는 그룹으로 파일을 분할할 수 있습니다.
데이터가 단일 Data Box 디바이스의 크기를 초과하지 않으면 다음 섹션으로 진행할 수 있습니다.
상승된 권한으로 이전 섹션의 지침에 따라 다운로드한
generate-file-list스크립트를 실행합니다.명령 매개 변수에 대한 설명은 다음과 같습니다.
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Distcp 작업에 액세스할 수 있도록 생성된 파일 목록을 HDFS에 복사합니다.
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
불필요한 파일 제외
DisCp 작업에서 일부 디렉터리를 제외해야 합니다. 예를 들어 클러스터를 계속 실행하는 상태 정보를 포함하는 디렉터리를 제외합니다.
DistCp 작업을 시작하려는 온-프레미스 Hadoop 클러스터에서 제외하려는 디렉터리 목록을 지정하는 파일을 만듭니다.
예를 들면 다음과 같습니다.
.*ranger/audit.*
.*/hbase/data/WALs.*
다음 단계
Data Lake Storage가 HDInsight 클러스터에서 작동하는 방법을 알아봅니다. 자세한 내용은 Azure HDInsight 클러스터에서 Azure Data Lake Storage 사용을 참조 하세요.