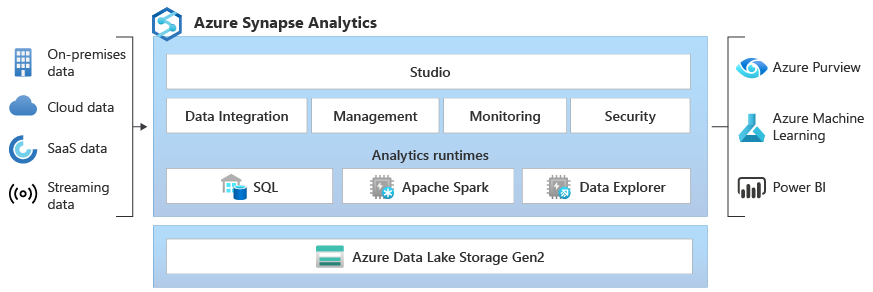
Azure Synapse Data Explorer란? (미리 보기)
Azure Synapse Data Explorer는 로그 및 원격 분석 데이터를 통해 인사이트를 확보할 수 있는 대화형 쿼리 환경을 고객에게 제공합니다. 기존 SQL 및 Apache Spark 분석 런타임 엔진을 보완하기 위해 Data Explorer 분석 런타임은 강력한 인덱싱 기술을 사용하여 효율적인 로그 분석에 최적화되어 원격 분석 데이터에서 일반적으로 제공되는 자유 텍스트 및 반구조적 데이터를 자동으로 인덱싱합니다.
자세한 내용은 다음 동영상을 참조하세요.
Azure Synapse Data Explorer만의 특성은 무엇인가요?
간편한 수집 - Data Explorer는 코드 없음/낮은 코드, 높은 처리량의 데이터 수집 및 실시간 원본으로부터의 데이터 캐싱을 위한 통합을 기본 제공합니다. Azure Event Hubs, Kafka, Azure Data Lake, 오픈 소스 에이전트(예: Fluentd/Fluent Bit), 다양한 클라우드 및 온-프레미스 데이터 원본과 같은 원본에서 데이터를 수집할 수 있습니다.
복잡한 데이터 모델링 없음 - Data Explorer를 사용하면 복잡한 데이터 모델을 빌드할 필요가 없으며, 데이터를 소비하기 전에 복잡한 스크립팅을 사용하여 데이터를 변환할 필요가 없습니다.
인덱스 유지 관리 없음 - 쿼리 성능 향상을 목적으로 데이터를 최적화하기 위한 유지 관리 작업이 필요하지 않으며 인덱스 유지 관리가 필요하지 않습니다. Data Explorer를 사용하면 모든 원시 데이터를 즉시 사용할 수 있어 스트리밍 및 영구 데이터에 대해 성능 및 동시성이 높은 쿼리를 실행할 수 있습니다. 이러한 쿼리를 사용하여 거의 실시간에 가까운 대시보드 및 경고를 빌드하고 운영 분석 데이터를 나머지 데이터 분석 플랫폼과 연결할 수 있습니다.
데이터 분석 보편화 - Data Explorer는 SQL의 표현력과 강력한 기능에 Excel의 단순성을 더해주는 직관적인 KQL(Kusto 쿼리 언어)을 사용하여 셀프 서비스 빅 데이터 분석을 보편화합니다. KQL은 효율적인 자유 텍스트 및 regex 검색을 위한 업계 최고의 Data Explorer 텍스트 인덱싱 기술과 배열 및 중첩 구조를 포함한 traces\text 데이터 및 JSON 반구조적 데이터를 쿼리하는 포괄적인 구문 분석 기능을 활용하여 원시 원격 분석 및 시계열 데이터를 탐색하는 데 고도로 최적화되어 있습니다. KQL은 모델 채점용 엔진 내 Python 실행 지원을 통해 여러 시계열을 생성, 조작, 분석하기 위한 고급 시계열 지원을 제공합니다.
페타바이트 규모의 입증된 기술 - Data Explorer는 독립적으로 스케일 인할 수 있는 컴퓨팅 리소스 및 스토리지가 있는 분산 시스템으로, 기가바이트 또는 페타바이트 단위의 데이터를 분석할 수 있습니다.
통합 - Azure Synapse Analytics는 데이터 엔지니어, 데이터 과학자 및 데이터 분석가가 데이터 레이크의 동일한 데이터에 쉽고 안전하게 액세스하고 그를 이용해 협업할 수 있도록 Data Explorer, Apache Spark 및 SQL 엔진 사이의 데이터 간 상호 운용성을 제공합니다.
Azure Synapse Data Explorer를 사용하는 경우
거의 실시간으로 로그 분석 및 IoT 분석 솔루션을 빌드하기 위한 데이터 플랫폼으로 Data Explorer를 사용하여 다음을 수행합니다.
온-프레미스, 클라우드, 타사 데이터 원본에서 로그 및 이벤트 데이터를 통합하고 상관 관계를 설정합니다.
AI Ops 경험(패턴 인식, 변칙 검색, 예측 등)을 가속화합니다.
인프라 기반 로그 검색 솔루션을 대체하여 비용을 절감하고 생산성을 높입니다.
IoT 데이터를 위한 IoT 분석 솔루션을 빌드합니다.
분석 SaaS 솔루션을 빌드하여 내부 및 외부 고객에게 서비스를 제공합니다.
Data Explorer 풀 아키텍처
Data Explorer 풀은 컴퓨팅 리소스와 스토리지 리소스를 분리하여 스케일 아웃 아키텍처를 구현합니다. 이를 통해 각 리소스의 규모를 독립적으로 조정하고, 예를 들어, 동일한 데이터에 대해 여러 읽기 전용 컴퓨팅을 실행할 수 있습니다. 데이터 탐색기 풀은 자동 인덱싱, 압축, 캐싱 및 분산 쿼리 제공을 담당하는 엔진을 실행하는 일련의 컴퓨팅 리소스로 구성됩니다. 또한 백그라운드 시스템 작업과 관리되는 데이터 및 큐에 대기 중인 데이터 수집을 담당하는 데이터 관리 서비스를 실행하는 두 번째 컴퓨팅 집합도 있습니다. 모든 데이터는 압축된 열 형식을 사용하여 관리되는 Blob Storage 계정에 유지됩니다.
Data Explorer 풀은 커넥터, SDK, REST API 및 기타 관리되는 기능을 사용하여 데이터를 수집하는 데 도움이 되는 풍부한 에코시스템을 지원합니다. 임시 쿼리, 보고서, 대시보드, 경고, REST API 및 SDK의 데이터를 사용하는 다양한 방법을 제공합니다.
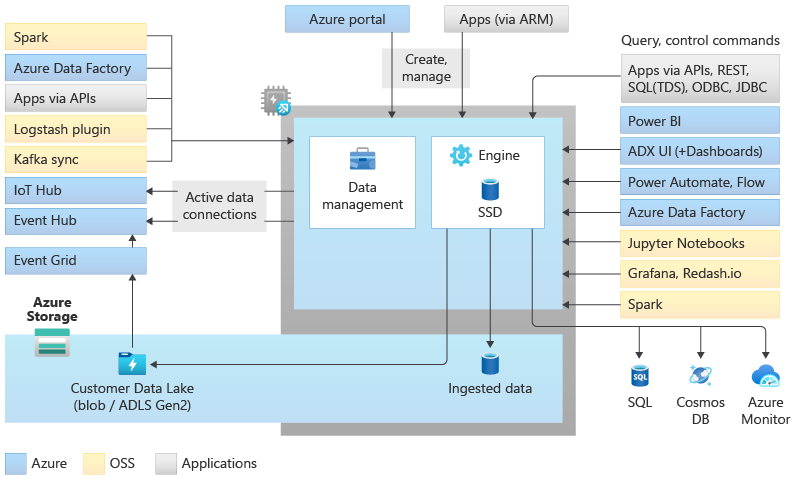
Data Explorer에는 Azure에서 로그 및 시계열 분석을 수행하기에 가장 적합한 분석 엔진이 Data Explorer임을 알 수 있는 고유한 기능이 많이 있습니다.
다음 섹션에서는 주요 차별화 요인을 중점적으로 살펴봅니다.
자유 텍스트 및 반구조화된 데이터 인덱싱을 사용하면 거의 실시간으로 성능 및 동시성이 높은 쿼리를 사용할 수 있습니다.
데이터 탐색기는 반구조화된 데이터(JSON)와 구조화되지 않은 데이터(자유 텍스트)를 인덱스화하여 실행 중인 쿼리가 이러한 형식의 데이터에 대해 잘 수행되도록 합니다. 기본적으로 모든 필드는 낮은 수준의 인코딩 정책을 사용하여 특정 필드에 대한 인덱스를 미세 조정 또는 사용하지 않도록 설정할 수 있는 옵션을 통해 데이터 수집 중에 인덱싱됩니다. 인덱스의 범위는 단일 데이터 분할입니다.
인덱스의 구현은 다음과 같이 필드의 형식에 따라 달라집니다.
| 필드 유형 | 인덱싱 구현 |
|---|---|
| String | 엔진은 문자열 열 값에 대해 반전된 용어 인덱스를 작성합니다. 각 문자열 값은 분석되어 정규화된 용어로 분할되며, 순서가 지정된 논리적 위치 목록(레코드 서수 포함)이 각 용어별로 기록됩니다. 정렬된 용어 목록 결과와 해당 위치는 변경 불가능한 B-트리로 저장됩니다. |
| 숫자 DateTime TimeSpan |
엔진은 단순한 범위 기반 포워드 인덱스를 작성합니다. 인덱스는 각 블록, 블록 그룹 및 데이터 분할 내 전체 열에 대한 최소/최대값을 기록합니다. |
| 동적 | 수집 프로세스는 속성 이름, 값 및 배열 요소와 같은 동적 값 내의 모든 "atomic" 요소를 열거하고 인덱스 작성기로 전달합니다. 동적 필드는 문자열 필드와 동일한 반전된 용어 인덱스입니다. |
이러한 효율적인 인덱싱 기능을 사용하면 Data Explorer에서 성능 및 동시성이 높은 쿼리에 거의 실시간으로 데이터를 사용할 수 있습니다. 이 시스템은 데이터 분할을 자동으로 최적화하여 성능을 더욱 향상시킵니다.
Kusto 쿼리 언어
KQL에는 Azure Monitor Log Analytics 및 Application Insights, Microsoft Sentinel, Azure Data Explore 및 기타 Microsoft 제품을 빠르게 채택하여 성장하고 있는 대규모 커뮤니티가 있습니다. 읽기 쉬운 구문으로 잘 설계된 이 언어는 간단한 한 줄짜리에서 복잡한 데이터 처리 쿼리로 원활하게 전환할 수 있습니다. 이를 통해 Data Explorer는 다양한 Intellisense 지원과 다양한 언어 구문 및 원격 분석 데이터의 신속한 탐색을 위해 SQL에서는 사용할 수 없는 집계, 시계열 및 사용자 분석 기능을 기본 제공합니다.