Oracle 마이그레이션을 위한 디자인 및 성능
이 문서는 Oracle에서 Azure Synapse Analytics로 마이그레이션하는 방법의 지침을 제공하는 7부 시리즈 중 1부입니다. 이 문서는 디자인 및 성능에 대한 모범 사례에 중점을 두고 있습니다.
개요
많은 기존 Oracle 사용자는 레거시 온-프레미스 Oracle 환경을 유지 관리하고 업그레이드하는 데 드는 비용과 복잡성으로 인해 최신 클라우드 환경에서 제공하는 혁신을 활용하려고 합니다. IaaS(Infrastructure-as-a-Service) 및 PaaS(Platform-as-a-Service) 클라우드 환경을 사용하면 인프라 유지 관리 및 플랫폼 개발과 같은 작업을 클라우드 공급자에게 위임할 수 있습니다.
팁
단순한 데이터베이스가 아닌 Azure 환경에는 포괄적인 기능 및 도구 세트가 포함되어 있습니다.
Oracle과 Azure Synapse Analytics는 둘 다 매우 큰 데이터 볼륨에서 높은 쿼리 성능을 달성하기 위해 MPP(대규모 병렬 처리) 기술을 사용하는 SQL 데이터베이스이지만 접근 방식에서 몇 가지 기본적인 차이점이 있습니다.
레거시 Oracle 시스템은 자주 온-프레미스에 설치되고 상대적으로 고가의 하드웨어를 사용하는 반면, Azure Synapse는 클라우드 기반이며 Azure 스토리지 및 컴퓨팅 리소스를 사용합니다.
Oracle 구성 업그레이드는 추가 실제 하드웨어와 잠재적으로 긴 데이터베이스 다시 구성 또는 덤프 및 다시 로드를 포함하는 주요 작업입니다. 스토리지와 컴퓨팅 리소스는 Azure 환경에서 분리되어 있고 탄력적인 스케일링 기능이 있으므로 이러한 리소스를 독립적으로 위 또는 아래로 스케일링 기능을 활용할 수 있습니다.
리소스 사용률과 비용을 줄이기 위해 필요에 따라 Azure Synapse를 일시 중지하거나 크기를 조정할 수 있습니다.
Microsoft Azure는 Azure Synapse와 지원 도구 및 기능의 에코시스템을 포함하는 전 세계적으로 사용 가능하고 매우 안전하며 스케일링 가능한 클라우드 환경입니다. 다음은 Azure Synapse 에코시스템을 요약해서 보여주는 다이어그램입니다.
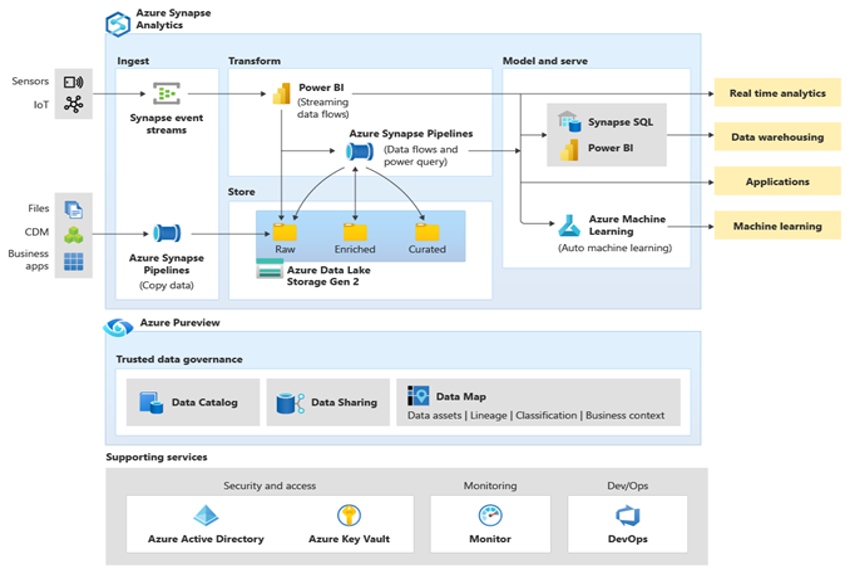
Azure Synapse는 MPP 및 자동 메모리 내 캐싱과 같은 기술을 사용하여 최상의 관계형 데이터베이스 성능을 제공합니다. Azure Synapse를 다른 자주 사용되는 클라우드 데이터 웨어하우스 제품과 비교하는 GigaOm에서 최근에 실행한 것과 같은 독립적인 벤치마크에서 이러한 기술의 결과를 확인할 수 있습니다. Azure Synapse 환경으로 마이그레이션하는 고객은 다음과 같은 많은 이점을 누릴 수 있습니다.
성능 및 가성비 향상
민첩성 증가 및 가치 창출 시간 단축
더 빠른 서버 배포 및 애플리케이션 개발.
탄력적 확장성 - 실제로 사용한 만큼만 지불합니다.
보안/규정 준수 향상
스토리지 및 재해 복구 비용 절감.
전체 TCO 감소, 보다 철저한 비용 관리, OPEX(운영 지출) 간소화
이러한 이점을 최대화하려면 신규 또는 기존 데이터 및 애플리케이션을 Azure Synapse 플랫폼으로 마이그레이션하세요. 많은 조직에서 마이그레이션에는 레거시 데이터 웨어하우스를 Oracle과 같은 레거시 온-프레미스 플랫폼에서 Azure Synapse로 이동하는 작업이 포함됩니다. 상위 수준에서 마이그레이션 프로세스에는 다음 단계가 포함됩니다.
준비 🡆
범위 정의 - 마이그레이션 대상.
마이그레이션을 위한 데이터 및 프로세스 인벤토리를 빌드합니다.
데이터 모델 변경 내용을 정의합니다(있는 경우).
원본 데이터 추출 메커니즘을 정의합니다.
사용할 적절한 Azure 및 타사 도구와 기능을 식별합니다.
새 플랫폼에서 초기에 담당자를 학습합니다.
Azure 대상 플랫폼을 설정합니다.
마이그레이션 🡆
작고 간단하게 시작합니다.
가능한 모든 곳에서 자동화합니다.
Azure 기본 제공 도구 및 기능을 활용하여 마이그레이션 활동을 줄입니다.
테이블 및 보기에 대한 메타데이터를 마이그레이션합니다.
유지 관리할 기록 데이터를 마이그레이션합니다.
저장 프로시저 및 업무 프로세스를 마이그레이션하거나 리팩터링합니다.
ETL/ELT 증분 로드 프로세스를 마이그레이션하거나 리팩터링합니다.
마이그레이션 후
프로세스의 모든 단계를 모니터링하고 문서화합니다.
얻은 환경을 사용하여 향후 마이그레이션을 위한 템플릿을 빌드합니다.
필요한 경우 데이터 모델을 다시 설계합니다(새로운 플랫폼 성능 및 확장성 사용).
애플리케이션 및 쿼리 도구를 테스트합니다.
쿼리 성능을 벤치마킹하고 최적화합니다.
이 문서에서는 기존 Oracle 환경에서 Azure Synapse로 데이터 웨어하우스를 마이그레이션할 때 성능 최적화를 위한 일반 정보 및 지침을 제공합니다. 성능 최적화의 목표는 마이그레이션 후 Azure Synapse에서 동일하거나 더 나은 데이터 웨어하우스 성능을 달성하는 것입니다.
디자인 고려 사항
마이그레이션 범위
Oracle 환경에서 마이그레이션을 준비할 때 다음 마이그레이션 선택 사항을 고려합니다.
초기 마이그레이션을 위한 워크로드 선택
일반적으로 레거시 Oracle 환경은 시간이 지남에 따라 여러 주제 영역과 혼합 워크로드를 포괄하도록 발전했습니다. 마이그레이션 프로젝트를 시작할 위치를 결정할 때 다음을 수행할 수 있는 영역을 선택합니다.
새로운 환경의 이점을 신속하게 제공하여 Azure Synapse로의 마이그레이션 가능성을 입증합니다.
사내 기술 담당자가 다른 영역을 마이그레이션할 때 사용할 프로세스 및 도구에 대한 관련 환경을 얻을 수 있습니다.
원본 Oracle 환경과 이미 있는 현재 도구 및 프로세스와 관련된 추가 마이그레이션을 위한 템플릿을 만듭니다.
Oracle 환경에서 초기 마이그레이션에 적합한 후보는 앞의 항목을 지원하며 다음과 같습니다.
OLTP(온라인 트랜잭션 처리) 워크로드가 아닌 BI/Analytics 워크로드를 구현합니다.
최소한의 수정으로 마이그레이션할 수 있는 별모양 또는 눈송이 스키마와 같은 데이터 모델이 있습니다.
팁
마이그레이션해야 하는 개체의 인벤토리를 만들고 마이그레이션 프로세스를 문서화합니다.
초기 마이그레이션에서 마이그레이션된 데이터의 양은 Azure Synapse 환경의 기능과 이점을 보여 주기에 충분히 커야 하지만 가치를 빠르게 보여 주기에는 너무 크지 않아야 합니다. 1-10TB 범위의 크기가 일반적입니다.
마이그레이션 프로젝트에 대한 초기 접근 방식은 Azure 클라우드 환경의 이점을 빠르게 볼 수 있도록 필요한 위험, 노력 및 시간을 최소화하는 것입니다. 다음 방법은 모두 초기 마이그레이션 범위를 데이터 마트로만 제한하고 ETL 마이그레이션 및 기록 데이터 마이그레이션과 같은 광범위한 마이그레이션 측면을 다루지 않습니다. 그러나 마이그레이션된 데이터 마트 계층이 데이터와 필요한 빌드 프로세스로 채워지면 프로젝트의 이후 단계에서 이러한 측면을 해결할 수 있습니다.
리프트 앤 시프트 마이그레이션 대 단계적 방법
일반적으로 계획된 마이그레이션의 목적과 범위에 관계없이 두 가지 형식의 마이그레이션이 있습니다. 즉, 있는 그대로의 리프트 앤 시프트와 변경 내용을 통합하는 단계적 방법입니다.
리프트 앤 시프트
리프트 앤 시프트 마이그레이션에서는 별모양 스키마와 같은 기존 데이터 모델이 변경되지 않고 새 Azure Synapse 플랫폼으로 마이그레이션됩니다. 이 방법은 Azure 클라우드 환경으로 이동하는 이점을 실현하는 데 필요한 작업을 줄여 위험과 마이그레이션 시간을 최소화합니다. 리프트 앤 시프트 마이그레이션은 다음 시나리오에 적합합니다.
- 마이그레이션할 단일 데이터 마트가 있는 기존 Oracle 환경이 있거나
- 이미 잘 설계된 별모양 또는 눈송이 스키마에 있는 데이터가 있는 기존 Oracle 환경이 있습니다.
- 최신 클라우드 환경으로 전환해야 하는 시간과 비용의 압박을 받고 있습니다.
팁
후속 단계에서 데이터 모델 변경을 구현하더라도 리프트 앤 시프트는 좋은 시작점입니다.
변화를 통합하는 단계적 접근
레거시 데이터 웨어하우스가 오랜 기간 동안 발전한 경우 필요한 성능 수준을 유지하기 위해 이를 다시 설계해야 할 수 있습니다. 또한 IoT(사물 인터넷) 스트림과 같은 새로운 데이터를 지원하기 위해 다시 엔지니어링해야 할 수도 있습니다. 재설계 프로세스의 일부로 Azure Synapse로 마이그레이션하면 확장성 있는 클라우드 환경의 이점을 얻게 됩니다. 마이그레이션에는 Inmon 모델에서 데이터 자격 증명 모음으로의 이동과 같은 기본 데이터 모델의 변경이 포함될 수 있습니다.
Microsoft는 기존 데이터 모델을 있는 그대로 Azure로 이동하고 Azure 환경의 성능과 유연성을 사용하여 리엔지니어링 변경 내용을 적용하는 것이 좋습니다. 이렇게 하면 Azure의 기능을 사용하여 기존 원본 시스템에 영향을 주지 않고 변경할 수 있습니다.
Microsoft 기능을 사용하여 메타데이터 기반 마이그레이션 구현
Azure 환경의 기능을 사용하여 마이그레이션 프로세스를 자동화하고 오케스트레이션할 수 있습니다. 이 방법은 이미 용량에 가깝게 실행되고 있는 기존 Oracle 환경의 성능 저하를 최소화합니다.
Oracle용 SSMA(SQL Server Migration Assistant)는 일부의 경우 함수와 절차 코드를 포함하여 마이그레이션 프로세스의 많은 부분을 자동화할 수 있습니다. SSMA에서는 Azure Synapse를 대상 환경으로 지원합니다.

Oracle용 SSMA는 Oracle 데이터 웨어하우스 또는 데이터 마트를 Azure Synapse로 마이그레이션하는 데 도움이 될 수 있습니다. SSMA는 기존 Oracle 환경에서 테이블, 뷰 및 데이터를 마이그레이션하는 프로세스를 자동화하도록 설계되었습니다.
Azure Data Factory는 데이터 이동 및 데이터 변환을 조정하고 자동화하는 클라우드에서 데이터 기반 워크플로 만들기를 지원하는 클라우드 기반 데이터 통합 서비스입니다. Data Factory를 사용하여 서로 다른 데이터 저장소에서 데이터를 수집하는 데이터 기반 워크플로(파이프라인)를 만들고 예약할 수 있습니다. Data Factory는 Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics 및 Azure Machine Learning과 같은 컴퓨팅 서비스를 사용하여 데이터를 처리하고 변환할 수 있습니다.
Data Factory를 사용하여 원본의 데이터를 Azure SQL 대상으로 마이그레이션할 수 있습니다. 이러한 오프라인 데이터 이동은 마이그레이션 가동 중지 시간을 크게 줄이는 데 도움이 됩니다.
Azure Database Migration Services를 사용하여 Oracle과 같은 환경에서 마이그레이션을 계획하고 수행할 수 있습니다.
Azure 기능을 사용하여 마이그레이션 프로세스를 관리하려는 경우 마이그레이션할 모든 데이터 테이블과 해당 위치를 나열하는 메타데이터를 만듭니다.
Oracle과 Azure Synapse의 디자인 차이점
앞에서 설명한 것처럼 Oracle과 Azure Synapse Analytics 데이터베이스 간의 접근 방식에는 몇 가지 기본적인 차이점이 있습니다. Oracle용 SSMA는 이러한 격차를 해소하는 데 도움이 될 뿐만 아니라 마이그레이션을 자동화합니다. SSMA는 매우 많은 양의 데이터에 가장 효율적인 방법은 아니지만 작은 테이블에 유용합니다.
여러 데이터베이스와 단일 데이터베이스 및 스키마
Oracle 환경에는 여러 개의 개별 데이터베이스가 포함되어 있는 경우가 많습니다. 예를 들어, 데이터 수집 및 준비 테이블, 코어 웨어하우스 테이블, 데이터 마트(의미 체계 계층이라고도 함)를 위한 별도의 데이터베이스가 있을 수 있습니다. ETL 또는 ELT 파이프라인으로 처리하면 데이터베이스 간 조인을 구현하고 별도의 데이터베이스 간에 데이터를 이동할 수 있습니다.
대조적으로 Azure Synapse 환경은 단일 데이터베이스를 포함하고 스키마를 사용하여 테이블을 논리적으로 별도의 그룹으로 분리합니다. 대상 Azure Synapse 데이터베이스 내에서 일련의 스키마를 사용하여 Oracle 환경에서 마이그레이션된 별도의 데이터베이스를 모방하는 것이 좋습니다. Oracle 환경에서 이미 스키마를 사용하는 경우 기존 Oracle 테이블과 보기를 새 환경으로 이동할 때 새 명명 규칙을 사용해야 할 수 있습니다. 예를 들어 기존 Oracle 스키마와 테이블 이름을 새 Azure Synapse 테이블 이름에 연결하고, 새 환경에서 스키마 이름을 사용하여 원래의 별도 데이터베이스 이름을 유지할 수 있습니다. 기본 테이블 위에 SQL 보기를 사용하여 논리 구조를 유지할 수 있지만 해당 방법에는 잠재적인 단점이 있습니다.
Azure Synapse의 보기는 읽기 전용이므로 데이터에 대한 모든 업데이트가 기본 테이블에서 수행되어야 합니다.
이미 하나 이상의 보기 계층이 존재할 수 있으며 보기 계층을 추가하면 성능에 영향을 미칠 수 있습니다.
팁
Azure Synapse 내에서 여러 데이터베이스를 단일 데이터베이스로 결합하고 스키마 이름을 사용하여 테이블을 논리적으로 분리합니다.
테이블 고려 사항
서로 다른 환경 간에 테이블을 마이그레이션할 때 일반적으로 원시 데이터와 이를 설명하는 메타데이터만 실제로 마이그레이션됩니다. 인덱스와 같은 원본 시스템의 다른 데이터베이스 요소는 일반적으로 새 환경에서 불필요하거나 다르게 구현될 수 있으므로 마이그레이션되지 않습니다.
인덱스와 같은 원본 환경의 성능 최적화는 새 환경에서 성능 최적화를 추가할 수 있는 위치를 나타냅니다. 예를 들어 원본 Oracle 환경의 쿼리에서 비트 매핑 인덱스를 자주 사용하는 경우 이는 Azure Synapse 내에서 비클러스터형 인덱스를 만들어야 함을 나타냅니다. 테이블 복제와 같은 다른 네이티브 성능 최적화 기술은 유사 인덱스를 만드는 것보다 더 적합할 수 있습니다. Oracle용 SSMA를 사용하여 테이블 배포 및 인덱싱에 대한 마이그레이션 권장 사항을 제공할 수 있습니다.
팁
기존 인덱스는 마이그레이션된 웨어하우스의 인덱싱 후보를 나타냅니다.
지원되지 않는 Oracle 데이터베이스 개체 형식
Oracle 관련 기능은 종종 Azure Synapse 기능으로 대체될 수 있습니다. 그러나 일부 Oracle 데이터베이스 개체는 Azure Synapse에서 직접 지원되지 않습니다. 지원되지 않는 Oracle 데이터베이스 개체에 대한 다음 목록에서는 Azure Synapse에서 동일한 기능을 구현하는 방법을 설명합니다.
다양한 인덱싱 옵션: Oracle의 비트 매핑 인덱스, 함수 기반 인덱스 및 도메인 인덱스와 같은 여러 인덱싱 옵션에 직접적으로 해당하는 Azure Synapse 옵션은 없습니다.
인덱싱되는 열과 인덱스 형식은 다음을 통해 확인할 수 있습니다.
시스템 카탈로그 테이블 및 뷰(예:
ALL_INDEXES,DBA_INDEXES,USER_INDEXES및DBA_IND_COL) 쿼리. 다음 스크린샷과 같이 Oracle SQL Developer의 기본 제공 쿼리를 사용할 수 있습니다.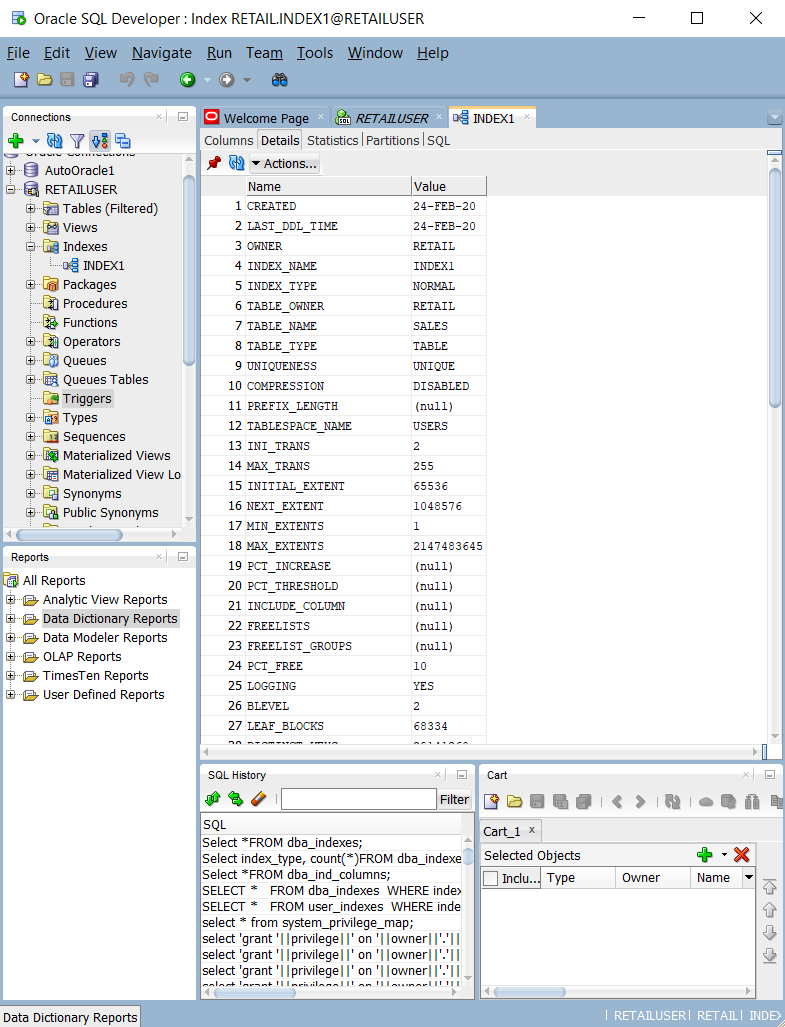
또는 다음 쿼리를 실행하여 지정된 형식의 모든 인덱스를 찾습니다.
SELECT * FROM dba_indexes WHERE index_type LIKE 'FUNCTION-BASED%';모니터링이 사용하도록 설정된 경우
dba_index_usage또는v$object_usage뷰 쿼리. 다음 스크린샷과 같이 Oracle SQL Developer에서 이러한 뷰를 쿼리할 수 있습니다.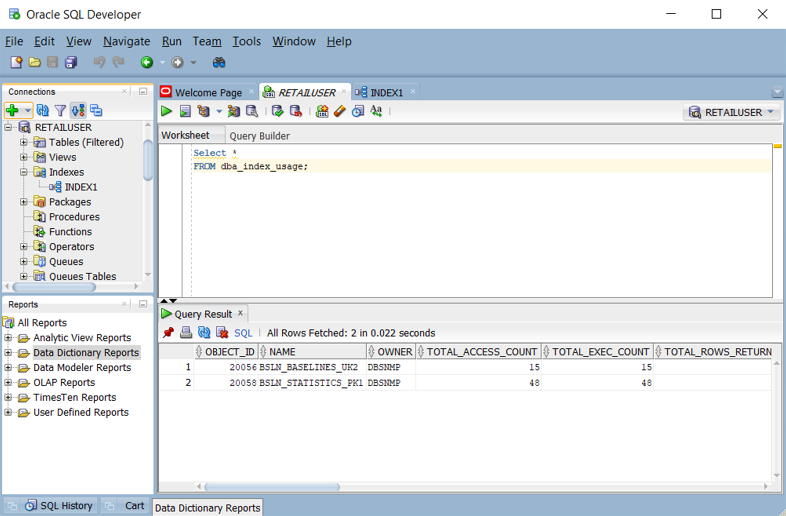
인덱스에 기본 데이터 열의 함수 결과가 포함된 함수 기반 인덱스에 직접적으로 해당하는 Azure Synapse 인덱스는 없습니다. 먼저 데이터를 마이그레이션한 다음, Azure Synapse 함수 기반 인덱스를 사용하여 성능을 측정하는 Oracle 쿼리를 실행하는 것이 좋습니다. Azure Synapse에서 해당 쿼리의 성능이 허용되지 않는 경우 미리 계산된 값이 포함된 열을 만든 다음, 해당 열을 인덱싱하는 것이 좋습니다.
Azure Synapse 환경을 구성하는 경우 사용 중인 인덱스만 구현하는 것이 좋습니다. Azure Synapse는 현재 여기에 표시된 인덱스 형식을 지원합니다.
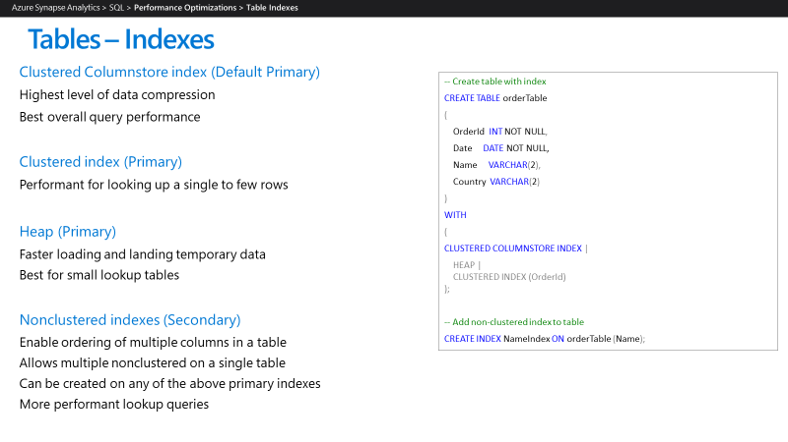
병렬 쿼리 처리 및 데이터 및 결과의 메모리 내 캐싱과 같은 Azure Synapse 기능을 사용하면 데이터 웨어하우스 애플리케이션이 성능 목표를 달성하는 데 필요한 인덱스를 줄일 수 있습니다. Azure Synapse에서 다음 인덱스 형식을 사용하는 것이 좋습니다.
클러스터형 columnstore 인덱스: 테이블에 대해 인덱스 옵션이 지정되지 않은 경우 기본적으로 Azure Synapse가 클러스터형 columnstore 인덱스를 만듭니다. 클러스터형 columnstore 테이블은 가장 높은 수준의 데이터 압축, 최상의 전반적인 쿼리 성능을 제공하며 일반적으로 클러스터형 인덱스 또는 힙 테이블의 성능을 능가합니다. 클러스터형 columnstore 인덱스는 대개 큰 테이블에 가장 적합합니다. 테이블을 생성할 때 테이블을 인덱싱하는 방법을 잘 모르는 경우 클러스터형 columnstore를 선택합니다. 그러나 클러스터형 columnstore 인덱스가 최상의 옵션이 아닌 몇 가지 시나리오가 있습니다.
- 정렬 키에 미리 정렬된 데이터가 있는 테이블은 정렬된 클러스터형 columnstore 인덱스에서 사용하도록 설정된 세그먼트 제거를 활용할 수 있습니다.
- varchar(max), nvarchar(max) 또는 varbinary(max) 데이터 형식이 있는 테이블(클러스터형 columnstore 인덱스가 이러한 데이터 형식을 지원하지 않으므로). 대신 힙 또는 클러스터형 인덱스를 사용하는 것이 좋습니다.
- 임시 데이터가 있는 테이블(columnstore 테이블은 힙 또는 임시 테이블보다 덜 효율적일 수 있으므로).
- 1억개 미만의 행이 있는 작은 테이블. 대신 힙 테이블을 사용하는 것이 좋습니다.
정렬된 클러스터형 columnstore 인덱스: 효율적인 세그먼트 제거를 사용하도록 설정함으로써 Azure Synapse 전용 SQL 풀의 정렬된 클러스터형 columnstore 인덱스는 쿼리 조건자와 일치하지 않는 대량의 정렬된 데이터를 건너뛰어 훨씬 더 빠른 성능을 제공합니다. 데이터 정렬 작업으로 인해 순서가 지정되지 않은 CCI 테이블보다 순서가 지정된 CCI 테이블에 데이터를 로드하는 데 시간이 오래 걸릴 수 있지만, 나중에 순서가 지정된 CCI를 사용하여 쿼리를 더 빠르게 실행할 수 있습니다. 순서가 지정된 클러스터형 columnstore 인덱스에 대한 자세한 내용은 순서가 지정된 클러스터형 columnstore 인덱스를 사용한 성능 조정을 참조하세요.
클러스터형 및 비클러스터형 인덱스: 단일 행을 빠르게 검색해야 하는 경우 클러스터형 인덱스가 클러스터형 columnstore 인덱스의 성능을 능가할 수 있습니다. 단일 행 조회 또는 단 몇 개의 행 조회를 극단적인 속도로 수행해야 하는 쿼리의 경우 클러스터 인덱스 또는 비클러스터형 보조 인덱스를 사용하는 것이 좋습니다. 클러스터형 인덱스를 사용할 때의 단점은 클러스터형 인덱스 열의 고선택적 필터를 사용하는 쿼리에만 도움이 된다는 것입니다. 다른 열에 대한 필터링을 개선하기 위해 다른 열에 비클러스터형 인덱스를 추가할 수 있습니다. 그러나 테이블에 인덱스를 추가할 때마다 더 많은 공간이 사용되고 로드 처리 시간이 늘어납니다.
힙 테이블: Azure Synapse의 데이터를 일시적으로 방문하면 힙 테이블을 사용할 경우 전체 프로세스가 더 빨라진다는 사실을 알 수 있습니다. 힙 테이블에 데이터를 로드하는 것이 인덱스 테이블에 데이터를 로드하는 것보다 빠르며, 경우에 따라 캐시에서 후속 읽기를 수행할 수 있기 때문입니다. 더 많은 변환을 실행하기 전에 준비만을 위해 데이터를 로드하는 경우 클러스터형 columnstore 테이블보다는 힙 테이블에 로드하는 것이 훨씬 더 빠릅니다. 또한 데이터를 임시 테이블에 로드하는 것이 테이블을 영구 스토리지에 로드하는 것보다 빠릅니다. 행이 1억 개 미만인 작은 조회 테이블의 경우 일반적으로 힙 테이블이 적합한 선택입니다. 클러스터 columnstore 테이블은 1억 개가 넘는 행을 포함하는 경우 최적의 압축을 달성하기 시작합니다.
클러스터형 테이블: 데이터가 검색될 때 디스크 I/O를 줄이기 위해 공통 값에 따라 자주 함께 액세스하는 테이블 행이 물리적으로 함께 저장되도록 Oracle 테이블을 구성할 수 있습니다. 또한 Oracle은 클러스터 키에 해시 값을 적용하고 동일한 해시 값을 가진 행을 물리적으로 함께 저장하는 해시 클러스터 옵션을 개별 테이블에 제공합니다. Oracle 데이터베이스 내의 클러스터를 나열하려면
SELECT * FROM DBA_CLUSTERS;쿼리를 사용합니다. 테이블이 클러스터 내에 있는지 확인하려면 각 테이블의 테이블 이름 및 클러스터 ID를 표시하는SELECT * FROM TAB;쿼리를 사용합니다.Azure Synapse에서 구체화된 테이블 및/또는 복제된 테이블을 사용하여 비슷한 결과를 얻을 수 있습니다. 이러한 테이블 형식은 쿼리 런타임에 필요한 I/O를 최소화하기 때문입니다.
구체화된 뷰: Oracle은 구체화된 뷰를 지원하며, 많은 열 중 몇 개만 쿼리에서 정기적으로 사용되는 대형 테이블에 이를 하나 이상 사용할 것을 권장합니다. 기본 테이블의 데이터가 업데이트될 때 시스템에서 자동으로 구체화된 뷰를 새로 고칩니다.
2019년에 Microsoft는 Azure Synapse에서 Oracle과 동일하게 작동하는 구체화된 뷰를 지원한다고 발표했습니다. 현재 구체화된 뷰는 Azure Synapse에서 미리 보기 기능입니다.
데이터베이스 내 트리거: Oracle에서는 트리거 이벤트가 발생할 때 트리거가 자동으로 실행되도록 구성할 수 있습니다. 트리거 이벤트는 다음과 같습니다.
DML(데이터 조작 언어) 문(예:
INSERT,UPDATE또는DELETE)이 테이블에서 실행됩니다. 고객 테이블의INSERT문 앞에서 실행되는 트리거를 정의한 경우 새 행이 고객 테이블에 삽입되기 전에 트리거가 한 번 실행됩니다.DDL 문(예:
CREATE또는ALTER)이 실행됩니다. 이 트리거는 종종 감사 목적으로 스키마 변경 내용을 기록하는 데 사용됩니다.Oracle 데이터베이스의 시작 또는 종료와 같은 시스템 이벤트.
로그인 또는 로그아웃과 같은 사용자 이벤트
ALL_TRIGGERS,DBA_TRIGGERS또는USER_TRIGGERS뷰를 쿼리하여 Oracle 데이터베이스에 정의된 트리거 목록을 가져올 수 있습니다. 다음 스크린샷은 Oracle SQL Developer의DBA_TRIGGERS쿼리를 보여줍니다.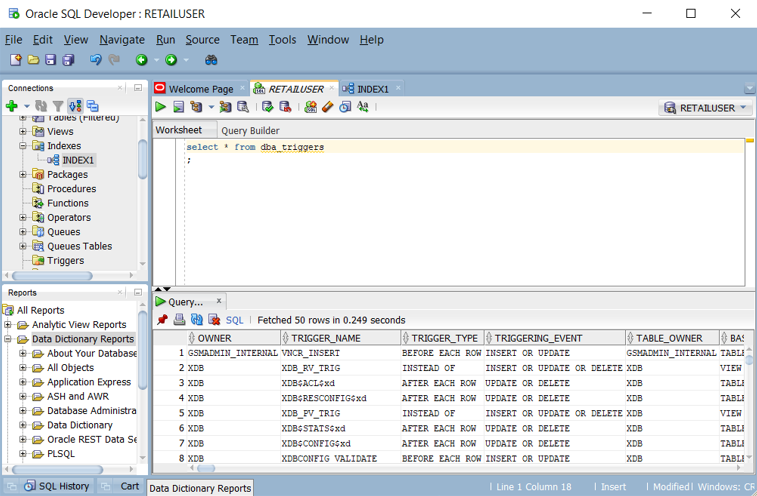
Azure Synapse에서는 Oracle 데이터베이스 트리거를 지원하지 않습니다. 그러나 Data Factory를 사용하여 동등한 기능을 추가할 수 있습니다. 이렇게 하려면 트리거를 사용하는 프로세스를 리팩터링해야 합니다.
동의어: Oracle에서는 여러 데이터베이스 개체 형식의 대체 이름으로 동의어 정의를 지원합니다. 이러한 개체 형식에는 테이블, 뷰, 시퀀스, 프로시저, 저장 함수, 패키지, 구체화된 뷰, Java 클래스 스키마 개체, 사용자 정의 개체 또는 다른 동의어가 포함됩니다.
현재 Azure Synapse에서는 동의어를 정의할 수 없지만 Oracle의 동의어가 테이블이나 뷰를 참조하는 경우 Azure Synapse에서 뷰를 대체 이름과 일치하도록 정의할 수 있습니다. Oracle의 동의어가 함수 또는 저장 프로시저를 참조하는 경우 Azure Synapse에서 대상을 호출하는 동의어와 일치하는 이름을 사용하여 다른 함수 또는 저장 프로시저를 만들 수 있습니다.
사용자 정의 형식: Oracle에서는 각각 고유한 정의와 기본값이 있는 일련의 개별 필드를 포함할 수 있는 사용자 정의 개체를 지원합니다. 이러한 개체는
NUMBER또는VARCHAR같은 기본 제공 데이터 형식 동일한 방식으로 테이블 정의 내에서 참조할 수 있습니다.ALL_TYPES,DBA_TYPES또는USER_TYPES뷰를 쿼리하여 Oracle 데이터베이스에 사용자 정의 형식의 목록을 가져올 수 있습니다.현재 Azure Synapse에서는 사용자 정의 형식을 지원하지 않습니다. 마이그레이션해야 하는 데이터에 사용자 정의 데이터 형식이 포함된 경우 이를 기존 테이블 정의로 "평면화"하거나 데이터 배열인 경우 별도의 테이블에서 정규화합니다.




Oracle 데이터 형식 매핑
대부분의 Oracle 데이터 형식은 Azure Synapse에 직접 대응되는 형식이 있습니다. 다음 표는 Oracle 데이터 형식을 Azure Synapse에 매핑하는 데 권장하는 방법을 보여줍니다.
| Oracle 데이터 형식 | Azure Synapse 데이터 형식 |
|---|---|
| BFILE | 지원되지 않습니다. VARBINARY(MAX)에 매핑합니다. |
| BINARY_FLOAT | 지원되지 않습니다. FLOAT에 매핑합니다. |
| BINARY_DOUBLE | 지원되지 않습니다. DOUBLE에 매핑합니다. |
| BLOB | 직접 지원되지 않습니다. VARBINARY(MAX)로 바꿉니다. |
| CHAR | CHAR |
| CLOB | 직접 지원되지 않습니다. VARCHAR(MAX)로 바꿉니다. |
| DATE | Oracle의 DATE에는 시간 정보도 포함될 수 있습니다. 사용법에 따라 DATE 또는 TIMESTAMP에 매핑됩니다. |
| DECIMAL | DECIMAL |
| DOUBLE | PRECISION DOUBLE |
| FLOAT | FLOAT |
| INTEGER | INT |
| INTERVAL YEAR TO MONTH | INTERVAL 데이터 형식은 지원되지 않습니다. DATEDIFF 또는 DATEADD와 같은 날짜 비교 함수를 날짜 계산에 사용합니다. |
| INTERVAL DAY TO SECOND | INTERVAL 데이터 형식은 지원되지 않습니다. DATEDIFF 또는 DATEADD와 같은 날짜 비교 함수를 날짜 계산에 사용합니다. |
| LONG | 지원되지 않습니다. VARCHAR(MAX)에 매핑합니다. |
| LONG RAW | 지원되지 않습니다. VARBINARY(MAX)에 매핑합니다. |
| NCHAR | NCHAR |
| NVARCHAR2 | NVARCHAR |
| NUMBER | FLOAT |
| NCLOB | 직접 지원되지 않습니다. NVARCHAR(MAX)로 바꿉니다. |
| NUMERIC | NUMERIC |
| ORD 미디어 데이터 형식 | 지원되지 않음 |
| RAW | 지원되지 않습니다. VARBINARY에 매핑합니다. |
| REAL | REAL |
| ROWID | 지원되지 않습니다. 비슷한 GUID에 매핑합니다. |
| SDO 지리 공간적 데이터 형식 | 지원되지 않음 |
| SMALLINT | SMALLINT |
| timestamp | DATETIME2 또는 CURRENT_TIMESTAMP() 함수 |
| TIMESTAMP WITH LOCAL TIME ZONE | 지원되지 않습니다. DATETIMEOFFSET에 매핑합니다. |
| TIMESTAMP WITH TIME ZONE | TIME은 표준 시간대 오프셋 없이 벽시계 시간을 사용하여 저장되므로 지원되지 않습니다. |
| URIType | 지원되지 않습니다. VARCHAR에 저장합니다. |
| UROWID | 지원되지 않습니다. 비슷한 GUID에 매핑합니다. |
| VARCHAR | VARCHAR |
| VARCHAR2 | VARCHAR |
| XMLType | 지원되지 않습니다. VARCHAR에 XML 데이터를 저장합니다. |
Oracle도 각각 고유한 정의 및 기본값을 가진 일련의 개별 필드를 포함할 수 있는 사용자 정의 개체 정의를 지원합니다. 그러면 NUMBER 또는 VARCHAR와 같은 기본 제공 데이터 형식과 동일한 방식으로 테이블 정의 내에서 이러한 개체를 참조할 수 있습니다. 현재 Azure Synapse에서는 사용자 정의 형식을 지원하지 않습니다. 마이그레이션해야 하는 데이터에 사용자 정의 데이터 형식이 포함된 경우 이를 기존 테이블 정의로 "평면화"하거나 데이터 배열인 경우 별도의 테이블에서 정규화합니다.
팁
마이그레이션 준비 단계에서 지원되지 않는 데이터 형식의 수와 유형을 평가합니다.
타사 공급업체에서 데이터 형식 매핑을 포함하여 마이그레이션을 자동화하는 도구와 서비스를 제공합니다. 이미 Oracle 환경에서 타사 ETL 도구를 사용하고 있으면 필요한 모든 데이터 변환을 구현하는 도구를 사용합니다.
SQL DML 구문 차이점
Oracle SQL과 Azure Synapse T-SQL의 SQL DML 구문에는 차이가 있습니다. 이러한 차이점은 Oracle 마이그레이션에 대한 SQL 문제 최소화에 자세히 설명되어 있습니다. 경우에 따라 Oracle용 SSMA 및 Azure Database Migration Service와 같은 Microsoft 도구 또는 타사 마이그레이션 제품 및 서비스를 사용하여 DML 마이그레이션을 자동화할 수 있습니다.
함수, 저장 프로시저 및 시퀀스
Oracle과 같은 성숙한 환경에서 데이터 웨어하우스를 마이그레이션할 때 간단한 테이블과 뷰 이외의 요소를 마이그레이션해야 할 수도 있습니다. 일반적으로 기본 제공 Azure 도구를 사용하는 것이 Azure Synapse용으로 이를 다시 코딩하는 것보다 더 효율적이므로 Azure 환경 내의 도구가 기능, 저장 프로시저 및 시퀀스의 기능을 바꿀 수 있는지 확인합니다.
준비 단계의 일부로 마이그레이션해야 하는 개체의 인벤토리를 만들고, 개체를 처리하는 방법을 정의하고, 마이그레이션 계획에 적절한 리소스를 할당합니다.
Oracle용 SSMA 및 Azure Database Migration Service와 같은 Microsoft 도구나 타사 마이그레이션 제품 및 서비스는 함수, 저장 프로시저 및 시퀀스의 마이그레이션을 자동화할 수 있습니다.
다음 섹션에서는 함수, 저장 프로시저 및 시퀀스의 마이그레이션에 대해 자세히 설명합니다.
함수
대부분의 데이터베이스 제품과 마찬가지로 Oracle에서는 SQL 구현 내에서 시스템 함수와 사용자 정의 함수를 지원합니다. 레거시 데이터베이스 플랫폼을 Azure Synapse로 마이그레이션할 때 일반적인 시스템 함수는 일반적으로 변경 없이 마이그레이션될 수 있습니다. 일부 시스템 함수는 구문이 약간 다를 수 있지만 필요한 변경 내용은 자동화할 수 있습니다. 적절한 WHERE 절로 ALL_OBJECTS 뷰를 쿼리하여 Oracle 데이터베이스 내의 함수 목록을 가져올 수 있습니다. 다음 스크린샷과 같이 Oracle SQL Developer를 사용하여 함수 목록을 가져올 수 있습니다.

Azure Synapse에 동등한 함수가 없는 Oracle 시스템 함수 또는 임의의 사용자 정의 함수의 경우 대상 환경 언어를 사용하여 해당 함수를 다시 코딩합니다. Oracle 사용자 정의 함수는 PL/SQL, Java 또는 C로 코딩됩니다. Azure Synapse는 Transact-SQL 언어를 사용하여 사용자 정의 함수를 구현합니다.
저장 프로시저
대부분의 최신 데이터베이스 제품은 데이터베이스 내 저장 프로시저를 지원합니다. Oracle은 이를 위해 PL/SQL 언어를 제공합니다. 저장 프로시저는 일반적으로 SQL 문과 프로시저 논리를 모두 포함하며 데이터 또는 상태를 반환합니다. 적절한 WHERE 절로 ALL_OBJECTS 뷰를 쿼리하여 Oracle 데이터베이스 내의 저장 프로시저 목록을 가져올 수 있습니다. 다음 스크린샷과 같이 Oracle SQL Developer를 사용하여 저장 프로시저 목록을 가져올 수 있습니다.

Azure Synapse는 T-SQL을 사용하는 저장 프로시저를 지원하므로 마이그레이션된 저장 프로시저를 해당 언어로 다시 코딩해야 합니다.
시퀀스
Oracle에서 시퀀스는 CREATE SEQUENCE를 사용하여 만든 명명된 데이터베이스 개체입니다. 시퀀스는 CURRVAL 및 NEXTVAL 메서드를 통해 고유한 숫자 값을 제공합니다. 생성된 고유 번호를 기본 키의 대리 키 값으로 사용할 수 있습니다.
Azure Synapse는 CREATE SEQUENCE를 구현하지 않지만 계열에서 다음 시퀀스 번호를 생성하는 IDENTITY 열 또는 SQL 코드를 사용하여 시퀀스를 구현할 수 있습니다.
Oracle 환경에서 메타데이터 및 데이터 추출
데이터 정의 언어 생성
ANSI SQL 표준은 DDL(데이터 정의 언어) 명령의 기본 구문을 정의합니다. CREATE TABLE 및 CREATE VIEW와 같은 일부 DDL 명령은 Oracle과 Azure Synapse 모두에 공통적이지만 인덱싱, 테이블 배포 및 분할 옵션과 같은 구현별 기능도 제공합니다.
기존 Oracle CREATE TABLE 및 CREATE VIEW 스크립트를 편집하여 Azure Synapse에서 동등한 정의를 얻을 수 있습니다. 이렇게 하려면 수정된 데이터 형식을 사용하고 TABLESPACE과 같은 Oracle 관련 절을 제거하거나 수정해야 할 수 있습니다.
Oracle 환경 내에서 시스템 카탈로그 테이블은 현재 테이블과 뷰 정의를 지정합니다. 사용자가 관리하는 설명서와 달리 시스템 카탈로그 정보는 항상 완전하며 현재 테이블 정의와 동기화됩니다. Oracle SQL Developer와 같은 유틸리티를 사용하여 시스템 카탈로그 정보에 액세스할 수 있습니다. Oracle SQL Developer는 CREATE TABLE DDL 문을 생성할 수 있으며, 사용자는 이를 편집하여 해당하는 Azure Synapse 테이블을 만들 수 있습니다.
또는 Oracle용 SSMA를 사용하여 기존 Oracle 환경에서 Azure Synapse로 테이블을 마이그레이션할 수 있습니다. Oracle용 SSMA는 다음 스크린샷과 같이 적절한 데이터 형식 매핑과 권장 테이블 및 배포 유형을 적용합니다.

유사한 결과를 가져오기 위해 시스템 카탈로그 정보를 처리하는 타사 마이그레이션 및 ETL 도구를 사용할 수도 있습니다.
Oracle에서 데이터 추출
Oracle SQL Developer, SQL*Plus 및 SCLcl과 같은 표준 Oracle 유틸리티를 사용하여 Oracle 테이블에서 CSV 파일과 같은 평면 구분 파일로 원시 테이블 데이터를 추출할 수 있습니다. 그런 다음, gzip을 사용하여 평면 구분 파일을 압축하고 AzCopy 또는 Azure Data Box와 같은 Azure 데이터 전송 도구를 사용하여 압축된 파일을 Azure Blob Storage에 업로드할 수 있습니다.
특히 큰 팩트 테이블을 마이그레이션할 때 테이블 데이터를 최대한 효율적으로 추출할 수 있습니다. Oracle 테이블의 경우 병렬 처리를 사용하여 추출 처리량을 최대화합니다. 불연속 데이터 세그먼트를 개별적으로 추출하는 여러 프로세스를 실행하거나 분할을 통해 병렬 추출을 자동화할 수 있는 도구를 사용하여 병렬 처리를 구현할 수 있습니다.
팁
가장 효율적인 데이터 추출을 위해 병렬 처리를 사용합니다.
충분한 네트워크 대역폭을 사용할 수 있는 경우 온-프레미스 Oracle 시스템에서 Azure Synapse 테이블 또는 Azure Blob Data Storage로 바로 데이터를 추출할 수 있습니다. 이렇게 하려면 Data Factory 프로세스, Azure Database Migration Service 또는 타사 데이터 마이그레이션 또는 ETL 제품을 사용합니다.
추출된 데이터 파일에는 CSV, ORC(Optimized Row Columnar) 또는 Parquet 형식으로 구분된 텍스트가 포함되어야 합니다.
Oracle 환경에서 데이터 및 ETL을 마이그레이션하는 방법에 대한 자세한 내용은 Oracle 마이그레이션을 위한 데이터 마이그레이션, ETL 및 로드를 참조하세요.
Oracle 마이그레이션의 성능 권장 사항
성능 최적화의 목표는 Azure Synapse로 마이그레이션한 후 동일하거나 더 나은 데이터 웨어하우스 성능입니다.
성능 튜닝 방식 개념의 유사성
Oracle 데이터베이스에 대한 많은 성능 튜닝 개념은 Azure Synapse 데이터베이스에 유효합니다. 예시:
데이터 배포를 사용하여 조인할 데이터를 동일한 처리 노드에 배치합니다.
특정 열에 가장 작은 데이터 형식을 사용하면 스토리지 공간이 절약되고 쿼리 처리 속도가 빨라집니다.
조인 처리를 최적화하고 데이터 변환의 필요성을 줄이기 위해 조인할 열의 데이터 형식이 동일한지 확인합니다.
최적화 프로그램이 최상의 실행 계획을 생성할 수 있도록 하려면 통계가 최신 상태인지 확인합니다.
기본 제공 데이터베이스 기능을 사용하여 성능을 모니터링하여 리소스가 효율적으로 사용되고 있는지 확인합니다.
팁
마이그레이션 시작 시 Azure Synapse 튜닝 옵션에 대해 우선적으로 숙지합니다.
성능 튜닝 방법의 차이점
이 섹션에서는 Oracle과 Azure Synapse 간의 낮은 수준의 성능 튜닝 구현 차이점을 강조합니다.
데이터 배포 옵션
성능을 위해 Azure Synapse는 다중 노드 아키텍처로 설계되었으며 병렬 처리를 사용합니다. Azure Synapse에서 테이블 성능을 최적화하기 위해 DISTRIBUTION 문을 사용하여 CREATE TABLE 문에서 데이터 배포 옵션을 정의할 수 있습니다. 예를 들어, 결정적 해시 함수를 사용하여 컴퓨팅 노드에 테이블 행을 분산하는 해시 분산 테이블을 지정할 수 있습니다. 많은 Oracle 구현, 특히 오래된 온-프레미스 시스템은 이 기능을 지원하지 않습니다.
Oracle과 달리 Azure Synapse는 작은 테이블 복제를 통해 작은 테이블과 큰 테이블 간의 로컬 조인을 지원합니다. 예를 들어, 별모양 스키마 모델 내의 작은 차원 테이블과 큰 사실 테이블을 고려합니다. Azure Synapse는 모든 노드에서 더 작은 차원 테이블을 복제하여 큰 테이블의 모든 조인 키 값에 일치하는 로컬에서 사용 가능한 차원 행이 있는지 확인할 수 있습니다. 차원 테이블 복제의 오버헤드는 작은 차원 테이블에 대해 상대적으로 낮습니다. 큰 차원 테이블의 경우 해시 분포 방법이 더 적합합니다. 데이터 배포 옵션에 대한 자세한 내용은 복제 테이블 사용을 위한 디자인 지침 및 분산 테이블 디자인 지침을 참조하세요.
팁
해시 배포는 대형 팩트 테이블의 쿼리 성능을 향상시킵니다. 라운드 로빈 분산은 로드 속도를 향상시키는 데 유용합니다.
기본 테이블의 더 균등한 분포를 위해 해시 분포를 여러 열에 적용할 수 있습니다. 다중 열 배포를 사용하면 최대 8개의 열을 선택하여 배포할 수 있습니다. 이렇게 하면 시간이 지남에 따라 데이터 기울이기가 감소할 뿐만 아니라 쿼리 성능도 향상됩니다.
참고 항목
다중 열 배포는 현재 Azure Synapse Analytics의 미리 보기 상태입니다. CREATE MATERIALIZED VIEW, CREATE TABLE 및 CREATE TABLE AS SELECT와 함께 다중 열 배포를 사용할 수 있습니다.
배포 관리자
Azure Synapse SQL에서 각 테이블이 배포되는 방식을 사용자 지정할 수 있습니다. 테이블 배포 전략은 쿼리 성능에 상당한 영향을 줍니다.
배포 관리자는 고객 쿼리를 분석하고 쿼리 성능을 개선시키기 위해 테이블에 대한 최상의 배포 전략을 권장하는 Synapse SQL의 새 기능입니다. 관리자가 고려할 쿼리는 사용자가 제공하거나 DMV에서 사용할 수 있는 기록 쿼리에서 가져올 수 있습니다.
배포 관리자를 사용하는 방법에 대한 자세한 내용과 예제를 보려면 Azure Synapse SQL의 배포 관리자를 방문하세요.
데이터 인덱싱
Azure Synapse는 Oracle의 시스템 관리 영역 맵과 작동법 및 사용법이 다른 여러 사용자 정의 인덱싱 옵션을 지원합니다. Azure Synapse의 다양한 인덱싱 옵션에 대한 자세한 내용은 전용 SQL 풀 테이블의 인덱스를 참조하세요.
원본 Oracle 환경 내의 인덱스 정의는 Azure Synapse 환경에서 인덱싱을 위한 후보 열 및 데이터 사용량에 대한 유용한 표시를 제공합니다. 일반적으로 레거시 Oracle 환경에서 모든 인덱스를 마이그레이션할 필요는 없습니다. Azure Synapse는 인덱스에 지나치게 의존하지 않고 다음 기능을 구현하여 뛰어난 성능을 달성하기 때문입니다.
병렬 쿼리 처리.
메모리 내 데이터 및 결과 집합 캐싱.
I/O를 줄이기 위한 데이터 배포(예: 작은 차원 테이블 복제).
데이터 분할
엔터프라이즈 데이터 웨어하우스에서 팩트 테이블에는 수십억 개의 행이 포함될 수 있습니다. 분할은 처리된 데이터의 양을 줄이기 위해 테이블을 별도의 부분으로 분할하여 이러한 테이블의 유지 관리 및 쿼리를 최적화합니다. Azure Synapse에서 CREATE TABLE 문은 테이블에 대한 분할 사양을 정의합니다.
분할에는 테이블당 하나의 필드만 사용할 수 있습니다. 많은 쿼리가 날짜 또는 날짜 범위로 필터링되기 때문에 해당 필드는 날짜 필드인 경우가 많습니다. CTAS(CREATE TABLE AS) 문을 사용하여 새 배포로 테이블을 다시 만들어 초기 로드 후 테이블의 분할을 변경할 수 있습니다. Azure Synapse의 분할에 대한 자세한 내용은 전용 SQL 풀에서 테이블 분할을 참조하세요.
데이터 로드를 위한 PolyBase 또는 COPY INTO
PolyBase는 병렬 로드 스트림을 사용하여 데이터 웨어하우스에 대용량 데이터를 효율적으로 로드할 수 있도록 지원합니다. 자세한 내용은 PolyBase 데이터 로드 전략을 참조하세요.
COPY INTO는 또한 처리량이 많은 데이터 수집을 지원하며 다음을 수행합니다.
- 폴더 및 하위 폴더 내의 모든 파일에서 데이터 검색.
- 동일한 스토리지 계정의 여러 위치에서 데이터 검색. 쉼표로 구분된 경로를 사용하여 여러 위치를 지정할 수 있습니다.
- Azure Data Lake Storage(ADLS) 및 Azure Blob Storage.
- CSV, PARQUET 및 ORC 파일 형식.
팁
데이터 로드에 권장되는 방법은 COPY INTO를 PARQUET 파일 형식과 함께 사용하는 것입니다.
워크로드 관리
혼합된 워크로드를 실행하면 사용량이 많은 시스템에서 리소스 문제가 발생할 수 있습니다. 성공적인 워크로드 관리 체계는 리소스를 효과적으로 관리하고, 매우 효율적인 리소스 사용률을 보장하며, ROI(투자 수익률)를 극대화합니다. 워크로드 분류, 워크로드 중요도 및 워크로드 격리를 통해 워크로드가 시스템 리소스를 활용하는 방법을 더 잘 제어할 수 있습니다.
워크로드 관리 가이드에서는 워크로드를 분석하고 워크로드 중요도를 관리 및 모니터링하는 기술 및 리소스 클래스를 작업 그룹으로 변환하는 단계를 설명합니다. Azure Portal 및 DMV의 T-SQL 쿼리를 사용하여 해당 리소스가 효율적으로 활용되도록 워크로드를 모니터링합니다.
다음 단계
Oracle 마이그레이션에 대한 ETL 및 로드에 대한 자세한 내용은 이 시리즈의 다음 문서인 Oracle 마이그레이션을 위한 데이터 마이그레이션, ETL, 로드를 참조하세요.