빠른 시작: Apache Spark 작업 정의를 사용하여 데이터 변환
이 빠른 시작에서는 Azure Synapse Analytics를 사용하여 Apache Spark 작업 정의를 사용하여 파이프라인을 만듭니다.
필수 조건
- Azure 구독: Azure 구독이 아직 없는 경우 시작하기 전에 Azure 체험 계정을 만듭니다.
- Azure Synapse 작업 영역: 빠른 시작: Synapse 작업 영역 만들기의 지침에 따라 Azure Portal을 사용하여 Synapse 작업 영역을 만듭니다.
- Apache Spark 작업 정의: 자습서: Synapse Studio에서 Apache Spark 작업 정의 만들기의 지침에 따라 Synapse 작업 영역에서 Apache Spark 작업 정의를 만듭니다.
Synapse Studio로 이동
Azure Synapse 작업 영역이 만들어지면 다음 두 가지 방법으로 Synapse Studio를 열 수 있습니다.
- Azure Portal에서 Synapse 작업 영역을 엽니다. 시작하기 아래의 Open Synapse Studio 카드에서 열기를 선택합니다.
- Azure Synapse Analytics를 열고, 작업 영역에 로그인합니다.
이 빠른 시작에서는 "sampletest"라는 작업 영역을 예로 사용합니다.
Apache Spark 작업 정의를 사용하여 파이프라인 만들기
파이프라인에는 일련의 활동을 실행하기 위한 논리적 흐름이 포함됩니다. 이 섹션에서는 Apache Spark 작업 정의 작업을 포함하는 파이프라인을 만듭니다.
통합 탭으로 이동합니다. 파이프라인 헤더 옆에 있는 더하기 아이콘 및 파이프라인을 차례로 선택합니다.
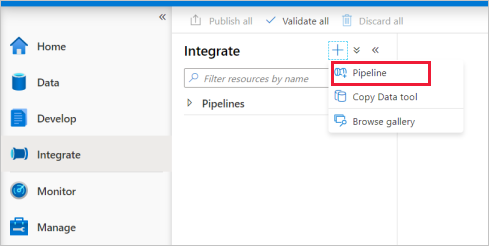
파이프라인의 속성 설정 페이지에서 이름에 demo를 입력합니다.
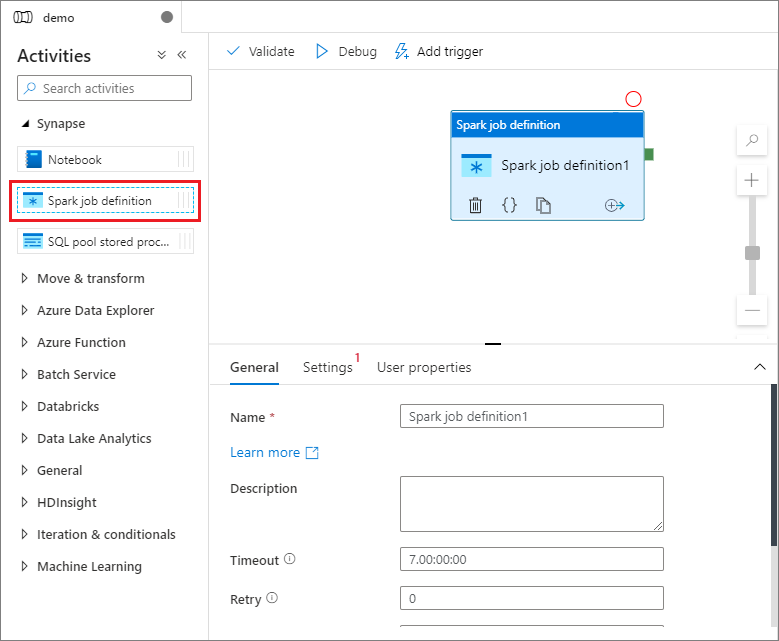
활동 창의 Synapse 아래에서 Spark 작업 정의를 파이프라인 캔버스로 끌어다 놓습니다.
Apache Spark 작업 정의 캔버스 설정
Apache Spark 작업 정의를 만들면 Spark 작업 정의 캔버스로 자동으로 전송됩니다.
일반 설정
캔버스에서 Spark 작업 정의 모듈을 선택합니다.
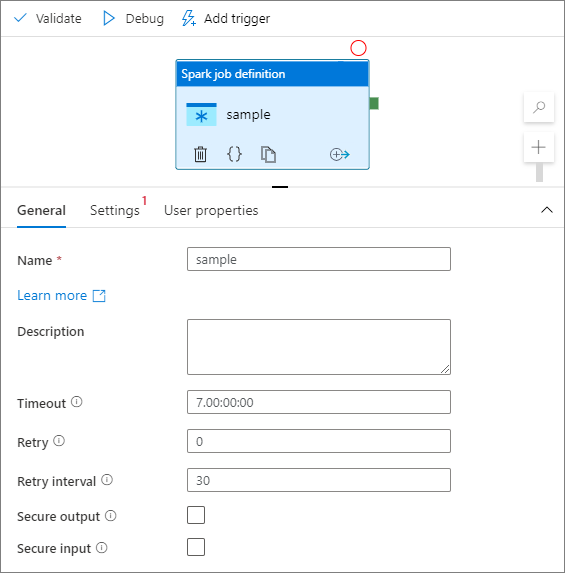
일반 탭에서 이름으로 sample을 입력합니다.
(옵션) 설명을 입력할 수도 있습니다.
시간 제한: 활동을 실행할 수 있는 최대 시간입니다. 기본값은 최대 허용 시간인 7일입니다. 형식은 D.HH:MM:SS입니다.
재시도: 최대 재시도 횟수입니다.
재시도 간격: 각 연결 재시도 간의 시간(초)을 지정합니다.
보안 출력: 선택하면 작업의 출력이 로깅에 캡처되지 않습니다.
보안 입력: 선택하면 활동의 입력이 로깅에 캡처되지 않습니다.
설정 탭
이 패널에서 실행할 Spark 작업 정의를 참조할 수 있습니다.
Spark 작업 정의 목록을 확장하면 기존 Apache Spark 작업 정의를 선택할 수 있습니다. 실행할 Spark 작업 정의를 참조하는 신규 단추를 클릭하여 새 Apache Spark 작업 정의를 생성할 수도 있습니다.
(선택 사항) Apache Spark 작업 정의에 대한 정보를 입력할 수 있습니다. 다음 설정이 비어 있으면 Spark 작업 정의 자체의 설정이 실행되는 데 사용됩니다. 다음 설정이 비어 있지 않으면 이러한 설정은 Spark 작업 정의 자체의 설정을 대체합니다.
속성 설명 주 정의 파일 작업에 사용되는 주 파일입니다. 스토리지에서 PY/JAR/ZIP 파일을 선택합니다. 파일 업로드를 선택하여 스토리지 계정에 파일을 업로드할 수 있습니다.
샘플:abfss://…/path/to/wordcount.jar하위 폴더의 참조 기본 정의 파일의 루트 폴더에서 하위 폴더를 검사하면 이러한 파일이 참조 파일로 추가됩니다. "jars", "pyFiles", "files" 또는 "archives"라는 폴더가 검색되고 폴더 이름은 대/소문자를 구분합니다. 주 클래스 이름 주 정의 파일에 있는 주 클래스 또는 정규화된 식별자입니다.
샘플:WordCount명령줄 인수 새로 만들기 단추를 클릭하여 명령줄 인수를 추가할 수 있습니다. 명령줄 인수를 추가하면 Spark 작업 정의에 정의된 명령줄 인수가 재정의됩니다.
견본:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultApache Spark 풀 목록에서 Apache Spark 풀을 선택할 수 있습니다. Python 코드 참조 기본 정의 파일에서 참조에 사용되는 다른 Python 코드 파일입니다.
파일(.py, .py3, .zip)을 "pyFiles" 속성에 전달할 수 있습니다. Spark 작업 정의에 정의된 "pyFiles" 속성을 재정의합니다.참조 파일 기본 정의 파일에서 참조에 사용되는 다른 파일입니다. 동적으로 실행기를 할당 이 설정은 Spark 애플리케이션 실행기 할당을 위해 Spark 구성의 동적 할당 속성에 매핑됩니다. 최소 실행기 작업에 대해 지정된 Spark 풀에 할당할 최소 실행기 수입니다. 최대 실행기 작업에 대해 지정된 Spark 풀에 할당할 최대 실행기 수입니다. 드라이버 크기 작업에 대해 지정된 Apache Spark 풀에 제공된 드라이버에 사용할 코어 및 메모리의 수입니다. Spark 구성 Spark 구성 - 애플리케이션 속성 문서에 나열된 Spark 구성 속성의 값을 지정합니다. 사용자는 기본 구성 및 사용자 지정된 구성을 사용할 수 있습니다. 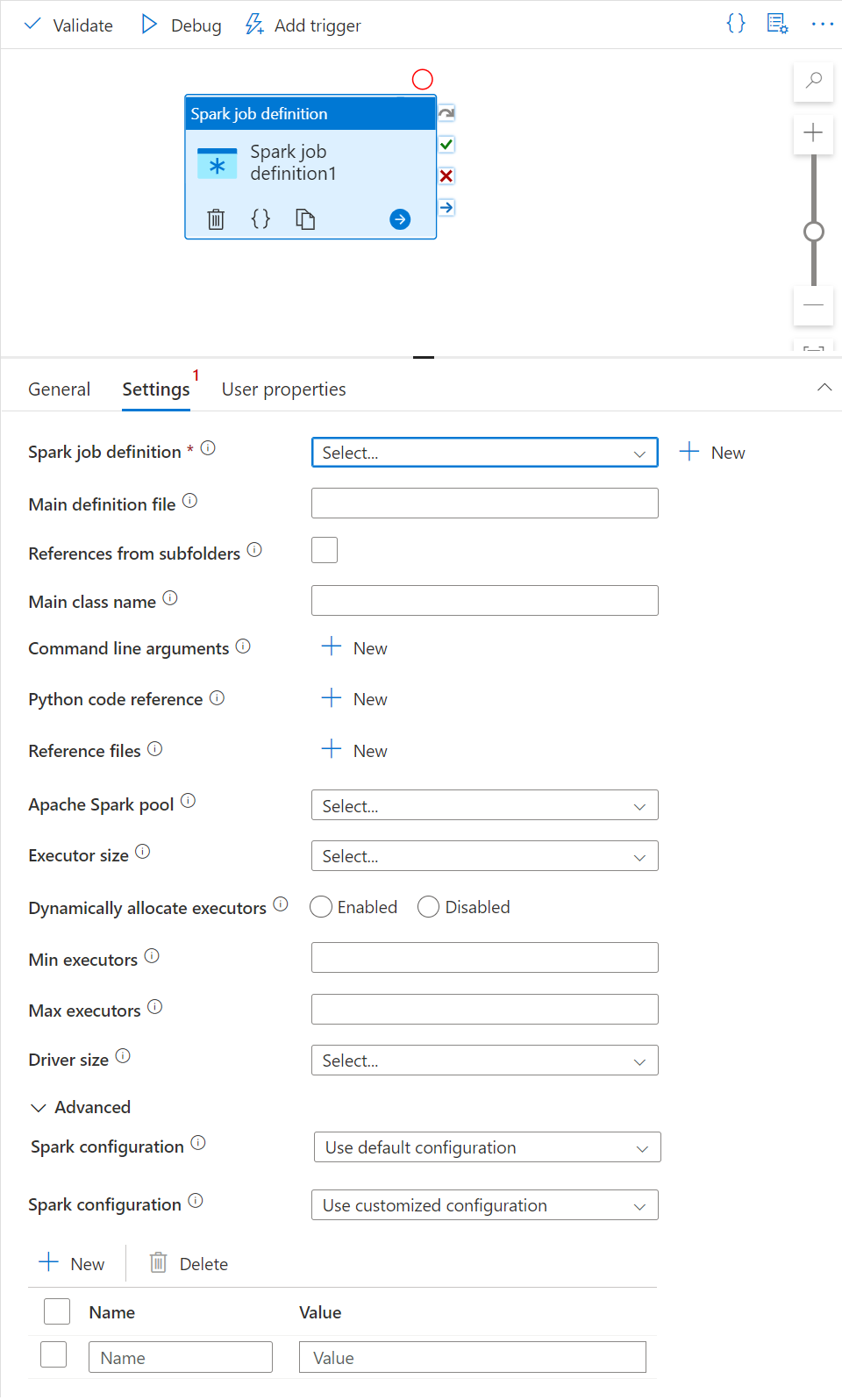
동적 콘텐츠 추가 단추를 클릭하거나 바로 가기 키 Alt+Shift+D를 눌러 동적 콘텐츠를 추가할 수 있습니다. 동적 콘텐츠 추가 페이지에서 식, 함수 및 시스템 변수 조합을 사용하여 동적 콘텐츠에 추가할 수 있습니다.
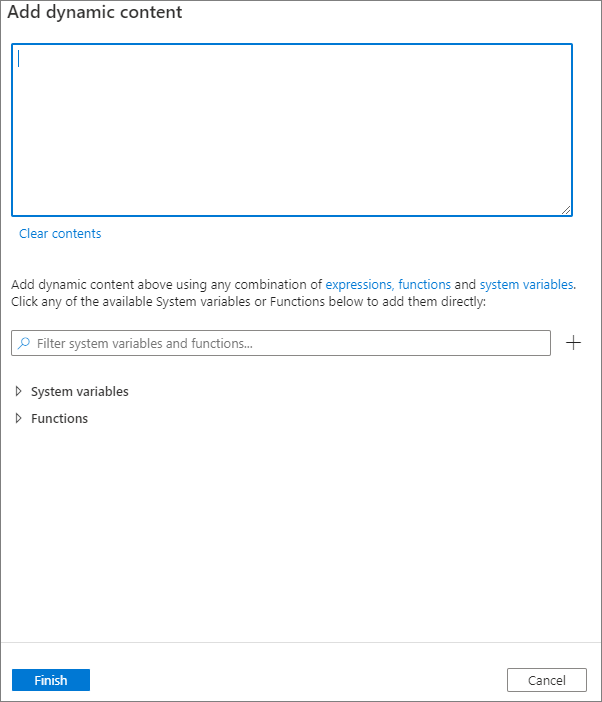
사용자 속성 탭
이 패널에서 Apache Spark 작업 정의 활동에 대한 속성을 추가할 수 있습니다.

관련 콘텐츠
Azure Synapse Analytics 지원에 대해 알아보려면 다음 문서로 계속 진행하세요.