Azure Synapse Analytics의 서버리스 SQL 풀에 대한 비용 관리
이 문서에서는 Azure Synapse Analytics에서 서버리스 SQL 풀의 비용을 예측하고 관리하는 방법을 설명합니다.
- 쿼리를 실행하기 전에 처리된 데이터의 예상 작업량
- 비용 제어 기능을 사용하여 예산 설정
Azure Synapse Analytics에서 서버리스 SQL 풀의 비용은 Azure 청구서의 월간 비용 중 일부일 뿐입니다. 다른 Azure 서비스를 사용하는 경우 타사 서비스를 포함하여 Azure 구독에 사용되는 모든 Azure 서비스 및 리소스에 대한 요금이 청구됩니다. 이 문서에서는 Azure Synapse Analytics에서 서버리스 SQL 풀의 비용을 계획하고 관리하는 방법을 설명합니다.
처리된 데이터
처리되는 데이터는 쿼리를 실행하면서 시스템에서 일시적으로 저장하는 데이터의 양입니다. 처리된 데이터는 다음 수량으로 구성됩니다.
- 스토리지에서 읽은 데이터의 양입니다. 이 크기는 다음과 같습니다.
- 데이터를 읽는 동안 읽은 데이터.
- 메타데이터를 읽는 동안 읽은 데이터(예: Parquet와 같은 메타데이터를 포함하는 파일 형식의 경우).
- 중간 결과의 데이터 양. 이 데이터는 쿼리가 실행되는 동안 노드 간에 전송됩니다. 여기에는 압축되지 않은 형식으로 엔드포인트에 대한 데이터 전송이 포함됩니다.
- 스토리지에 기록된 데이터의 양. CETAS를 사용하여 결과 집합을 스토리지로 내보내는 경우 기록된 데이터의 양은 CETAS의 SELECT 부분에 대해 처리되는 데이터의 양에 추가됩니다.
스토리지에서 파일을 읽는 것은 매우 최적화되어 있습니다. 이 프로세스는 다음을 사용합니다.
- 프리페치, 읽은 데이터 양에 따라 약간의 오버헤드가 발생합니다. 쿼리에서 전체 파일을 읽는 경우 오버헤드가 발생하지 않습니다. 상위 N개 쿼리와 같이 파일을 부분적으로 읽을 경우 프리페치를 사용하여 좀 더 많은 데이터를 읽습니다.
- 최적화된 CSV(쉼표로 구분된 값) 파서입니다. PARSER_VERSION='2.0'을 사용하여 CSV 파일을 읽으면 스토리지에서 읽은 데이터 양이 약간 늘어납니다. 최적화된 CSV 파서는 동일한 크기의 청크로 파일을 병렬로 읽습니다. 청크는 전체 행을 포함할 필요가 없습니다. 모든 행을 구문 분석하기 위해 최적화된 CSV 파서는 인접 청크의 작은 조각도 읽습니다. 이 프로세스를 처리하는 데 약간의 오버헤드가 발생합니다.
통계
서버리스 SQL 풀 쿼리 최적화 프로그램은 통계를 기반으로 최적의 쿼리 실행 계획을 생성합니다. 통계를 수동으로 만들 수 있습니다. 그렇지 않으면 서버리스 SQL 풀에서 자동으로 만듭니다. 어느 쪽이든, 제공된 샘플 주기에 특정 열을 반환하는 별도의 쿼리를 실행하여 통계가 생성됩니다. 이 쿼리에는 처리된 데이터 양이 관련되어 있습니다.
생성된 통계의 이점을 얻을 수 있는 동일한 쿼리 또는 다른 쿼리를 실행하면 가능한 경우 통계가 재사용됩니다. 통계 생성을 위해 처리된 추가 데이터가 없습니다.
Parquet 열에 대한 통계를 만들 때 파일에서 관련 열만 읽습니다. CSV 열에 대해 통계를 만들면 전체 파일이 읽혀지고 구문 분석됩니다.
반올림
처리되는 데이터의 양은 쿼리당 가장 가까운 MB로 반올림됩니다. 각 쿼리에는 최소한 10MB의 처리된 데이터가 있습니다.
처리된 데이터에 포함되지 않은 내용
- 서버 수준 메타데이터(예: 로그인, 역할 및 서버 수준 자격 증명).
- 엔드포인트에서 만든 데이터베이스입니다. 이러한 데이터베이스에는 메타데이터(예: 사용자, 역할, 스키마, 뷰, 인라인 TVF(테이블 반환 함수), 저장 프로시저, 데이터베이스 범위 자격 증명, 외부 데이터 원본, 외부 파일 형식 및 외부 테이블)만 포함됩니다.
- 스키마 유추를 사용하는 경우 파일 조각을 읽어 열 이름과 데이터 형식을 유추하고 읽은 데이터 양이 처리되는 데이터의 양에 추가됩니다.
- 지정된 샘플 비율에 따라 스토리지에서 데이터를 처리하기 때문에 CREATE STATISTICS 문을 제외하고 DDL(데이터 정의 언어) 문
- 메타데이터 전용 쿼리입니다.
처리되는 데이터의 양 줄이기
처리된 데이터의 쿼리당 양을 최적화하고 데이터를 Parquet 같은 압축된 열 기반 형식으로 분할 및 변환하여 성능을 향상시킬 수 있습니다.
예제
3개의 테이블을 가정합니다.
- population_csv 테이블은 5TB의 CSV 파일까지 지원됩니다. 이러한 파일은 크기가 같은 5개의 열로 구성됩니다.
- population_parquet 테이블에는 population_csv 테이블과 동일한 데이터가 있습니다. 1TB의 Parquet 파일까지 지원됩니다. 데이터가 Parquet 형식으로 압축되기 때문에 이 테이블은 이전 테이블 보다 작습니다.
- very_small_csv 테이블은 100KB의 CSV 파일까지 지원됩니다.
쿼리 1: SELECT SUM(population) FROM population_csv
이 쿼리는 전체 파일을 읽고 구문 분석하여 모집단 열의 값을 가져옵니다. 노드는 이 테이블의 조각을 처리하고 각 조각의 모집단 합계는 노드 간에 전송됩니다. 최종 합계가 엔드포인트로 전송됩니다.
이 쿼리는 5TB의 데이터를 처리하고 조각 합계를 전송하기 위해 약간의 오버헤드가 발생합니다.
쿼리 2: SELECT SUM(population) FROM population_parquet
Parquet와 같은 압축된 열 기반 형식을 쿼리하면 쿼리 1보다 더 작은 데이터를 읽을 수 있습니다. 서버리스 SQL 풀에서 전체 파일 대신 압축된 단일 열을 읽기 때문에 이 결과가 표시됩니다. 이 경우 0.2TB를 읽습니다. (5개의 동일한 크기의 열은 각각 0.2TB입니다.) 노드는 이 테이블의 조각을 처리하고 각 조각의 채우기 합계는 노드 간에 전송됩니다. 최종 합계가 엔드포인트로 전송됩니다.
이 쿼리는 0.2TB를 처리하고 조각 합계를 전송하기 위해 약간의 오버헤드가 발생합니다.
쿼리 3: SELECT * FROM population_parquet
이 쿼리는 모든 열을 읽고 압축되지 않은 형식으로 모든 데이터를 전송합니다. 압축 형식이 5:1인 경우 쿼리는 1TB를 읽고 압축되지 않은 데이터의 5TB를 전송하기 때문에 6TB를 처리합니다.
쿼리 4: SELECT COUNT(*) FROM very_small_csv
이 쿼리는 전체 파일을 읽습니다. 이 테이블에 대한 스토리지에 있는 파일의 총 크기는 100KB입니다. 노드는 이 테이블의 조각을 처리하고 각 조각의 합계는 노드 간에 전송됩니다. 최종 합계가 엔드포인트로 전송됩니다.
이 쿼리는 100KB보다 약간 더 많은 데이터를 처리합니다. 이 쿼리에 대해 처리되는 데이터의 양은 이 도움말의 반올림 섹션에 지정된 대로 10MB로 반올림됩니다.
비용 제어
서버리스 SQL 풀의 비용 제어 기능을 사용하면 처리되는 데이터의 양에 대한 예산을 설정할 수 있습니다. 하루, 주 및 월에 처리되는 데이터의 예산(TB)을 설정할 수 있습니다. 동시에 하나 이상의 예산 집합을 설정할 수 있습니다. 서버리스 SQL 풀에 대해 비용 제어를 구성하려면 Synapse Studio 또는 T-SQL을 사용하면 됩니다.
Synapse Studio에서 서버리스 SQL 풀에 대한 비용 제어 구성
Synapse Studio에서 서버리스 SQL 풀에 대한 비용 제어를 구성하려면 왼쪽의 메뉴에서 관리 항목으로 이동하고 분석 풀에서 SQL 풀 항목을 선택합니다. 서버리스 SQL 풀을 가리키면 비용 제어 아이콘을 볼 수 있습니다.이 아이콘을 클릭합니다.
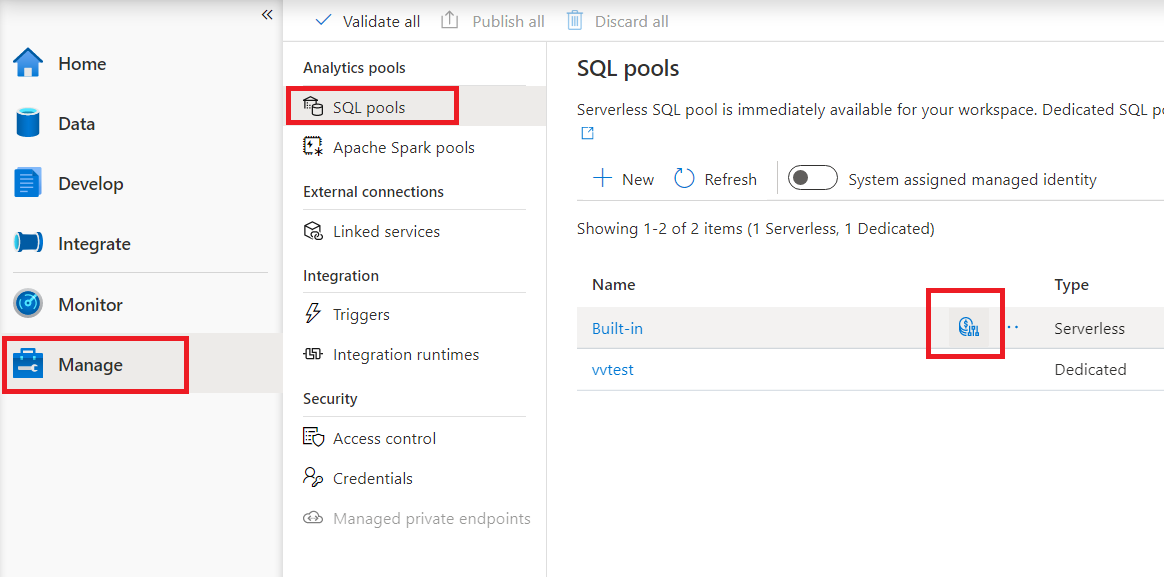
비용 제어 아이콘을 클릭하면 다음과 같은 사이드 막대가 표시됩니다.
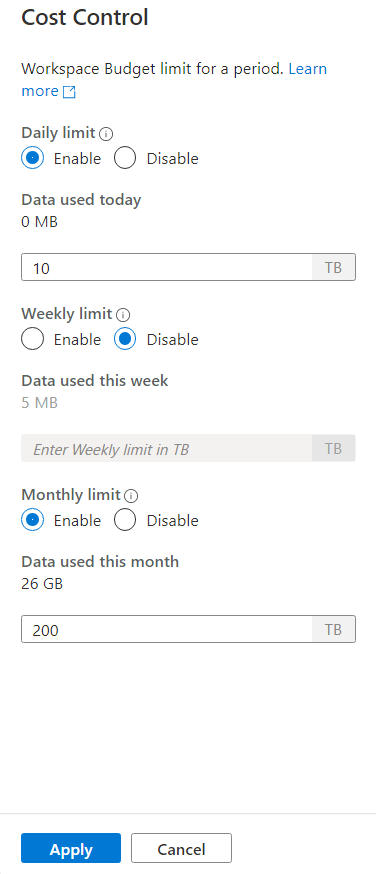
하나 이상의 예산을 설정하려면 먼저 텍스트 상자에 정수 값을 입력하는 것보다 설정하려는 예산에 대해 라디오 단추 사용을 클릭합니다. 값의 단위는 TB입니다. 예산을 구성한 후에는 사이드바의 아래쪽에 있는 적용 단추를 클릭합니다. 이제 예산이 설정되었습니다.
T-SQL에서 서버리스 SQL 풀에 대한 비용 제어 구성
T-SQL에서 서버리스 SQL 풀에 대한 비용 제어를 구성하려면 다음 저장 프로시저 중 하나 이상을 실행해야 합니다.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
현재 구성을 보려면 다음 T-SQL 문을 실행합니다.
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
현재 일, 주 또는 월에 처리된 데이터의 양을 확인하려면 다음 T-SQL 문을 실행합니다.
SELECT * FROM sys.dm_external_data_processed
비용 제어에 정의된 한도 초과
쿼리 실행 중에 한도가 초과되는 경우 쿼리가 종료되지 않습니다.
한도가 초과되면 새 쿼리가 거부되고 기간, 해당 기간에 정의된 한도 및 해당 기간 동안 처리된 데이터에 대한 세부 정보가 포함된 오류 메시지가 표시됩니다. 예를 들어 1TB로 설정된 주별 한도가 초과된 상태에서 새 쿼리가 실행되는 경우 오류 메시지는 다음과 같습니다.
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
다음 단계
성능을 위해 쿼리를 최적화하는 방법을 알아보려면 서버리스 SQL 풀에 대한 모범 사례를 참조하세요.