Microsoft Fabric에서 Apache Spark 라이브러리 관리
라이브러리는 개발자가 기능을 제공하기 위해 가져올 수 있는 미리 작성된 코드 컬렉션입니다. 라이브러리를 사용하면 일반적인 작업을 수행하기 위해 코드를 처음부터 작성할 필요가 없으므로 시간과 노력을 절약할 수 있습니다. 대신 라이브러리를 가져오고 해당 함수와 클래스를 사용하여 원하는 기능을 달성합니다. Microsoft Fabric은 라이브러리를 관리하고 사용하는 데 도움이 되는 여러 메커니즘을 제공합니다.
- 기본 제공 라이브러리: 각 Fabric Spark 런타임은 널리 사용되는 미리 설치된 라이브러리 집합을 제공합니다. Fabric Spark 런타임에서 전체 기본 제공 라이브러리 목록을 찾을 수 있습니다.
- 공용 라이브러리: 공용 라이브러리는 현재 지원되는 PyPI 및 Conda와 같은 리포지토리에서 제공됩니다.
- 사용자 지정 라이브러리: 사용자 지정 라이브러리는 사용자 또는 조직에서 빌드하는 코드를 참조합니다. Fabric은 .whl, .jar 및 .tar.gz 형식으로 지원합니다. Fabric은 R 언어에 대해서만 .tar.gz 지원합니다. Python 사용자 지정 라이브러리의 경우 .whl 형식을 사용합니다.
라이브러리 관리 모범 사례 요약
다음 시나리오에서는 Microsoft Fabric에서 라이브러리를 사용할 때의 모범 사례를 설명합니다.
시나리오 1: 관리자가 작업 영역에 대한 기본 라이브러리를 설정합니다.
기본 라이브러리를 설정하려면 작업 영역의 관리자여야 합니다. 관리자는 다음 작업을 수행할 수 있습니다.
Notebook 및 Spark 작업 정의가 작업 영역 설정에 연결되면 작업 영역의 기본 환경에 설치된 라이브러리로 세션을 시작합니다.
시나리오 2: 하나 이상의 코드 항목에 대한 라이브러리 사양 유지
다른 코드 항목에 대한 공통 라이브러리가 있고 자주 업데이트 할 필요가 없는 경우 환경에 라이브러리를 설치하고 코드 항목 에 연결하는 것이 좋습니다.
게시할 때 환경의 라이브러리를 적용하는 데 다소 시간이 걸릴 수 있습니다. 일반적으로 라이브러리의 복잡성에 따라 5~15분이 걸립니다. 이 프로세스 중에 시스템은 잠재적 충돌을 해결하고 필요한 종속성을 다운로드하는 데 도움이 됩니다.
이 방법의 한 가지 이점은 Spark 세션이 연결된 환경으로 시작될 때 성공적으로 설치된 라이브러리를 사용할 수 있다는 것입니다. 프로젝트에 대한 공통 라이브러리를 유지 관리하기 위한 노력을 절약할 수 있습니다.
안정성이 있는 파이프라인 시나리오에는 매우 권장됩니다.
시나리오 3: 대화형 실행의 인라인 설치
Notebook을 사용하여 코드를 대화형으로 작성하는 경우 인라인 설치를 사용하여 새 PyPI/conda 라이브러리를 추가하거나 일회성 사용을 위해 사용자 지정 라이브러리의 유효성을 검사하는 것이 가장 좋습니다. Fabric의 인라인 명령을 사용하면 현재 Notebook Spark 세션에서 라이브러리를 적용할 수 있습니다. 빠른 설치를 허용하지만 설치된 라이브러리는 다른 세션에서 유지되지 않습니다.
%pip install 때때로 다른 종속성 트리를 생성하여 라이브러리 충돌이 발생할 수 있으므로 파이프라인 실행에서 인라인 명령이 기본적으로 해제되고 파이프라인에서 사용하지 않는 것이 좋습니다.
지원되는 라이브러리 형식 요약
| 라이브러리 유형 | 환경 라이브러리 관리 | 인라인 설치 |
|---|---|---|
| Python 공용(PyPI 및 Conda) | 지원됨 | 지원됨 |
| Python 사용자 지정(.whl) | 지원됨 | 지원됨 |
| R 공용(CRAN) | 지원되지 않음 | 지원 여부 |
| R 사용자 지정(.tar.gz) | 사용자 지정 라이브러리로 지원됨 | 지원 여부 |
| Jar | 사용자 지정 라이브러리로 지원됨 | 지원 여부 |
인라인 설치
인라인 명령은 각 Notebook 세션에서 라이브러리 관리를 지원합니다.
Python 인라인 설치
시스템에서 Python 인터프리터를 다시 시작하여 라이브러리 변경 사항을 적용합니다. 명령 셀을 실행하기 전에 정의된 변수는 모두 손실됩니다. Notebook의 시작 부분에 Python 패키지를 추가, 삭제 또는 업데이트하기 위한 모든 명령을 배치하는 것이 좋습니다.
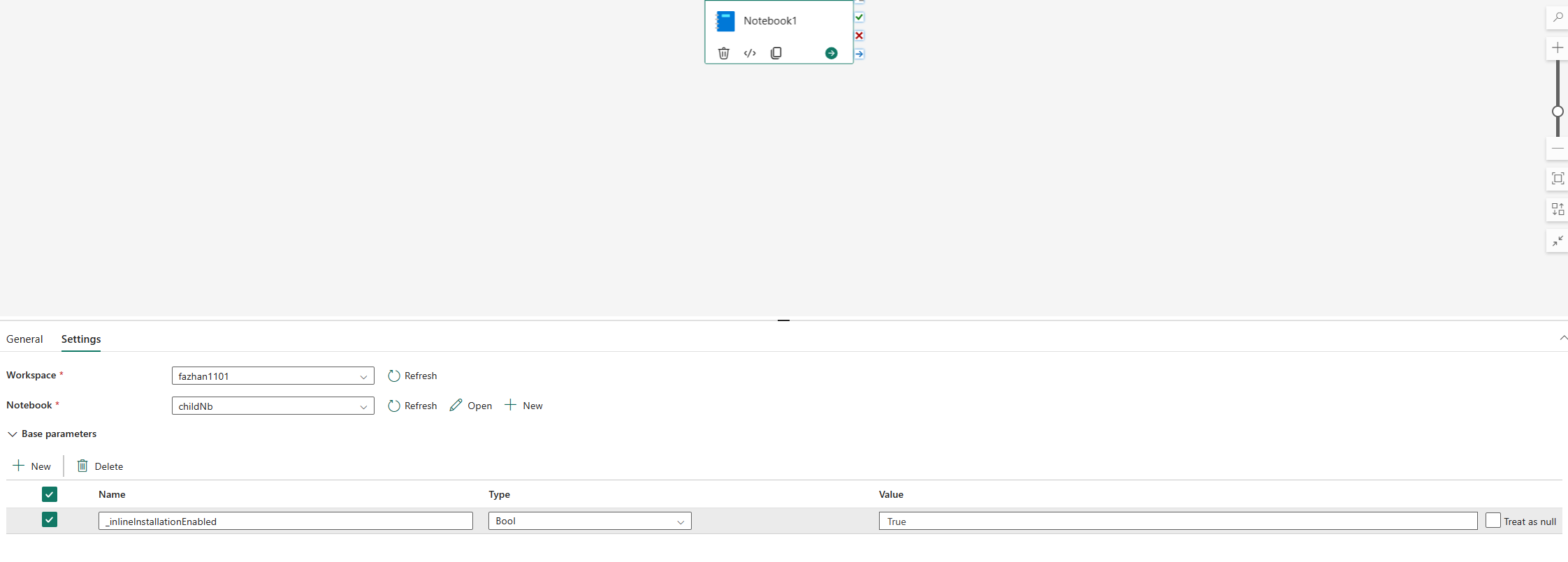
Python 라이브러리를 관리하기 위한 인라인 명령은 기본적으로 실행되는 Notebook 파이프라인에서 사용하지 않도록 설정됩니다. 파이프라인에 대해 %pip install를 활성화하려면 노트북 활동 매개변수에 “_inlineInstallationEnabled”를 True와 같은 부울 매개변수로 추가하세요.
참고 항목
%pip install로 인해 때때로 일관되지 않은 결과가 발생할 수 있습니다. 환경에 라이브러리를 설치하고 파이프라인에서 사용하는 것이 좋습니다.
Notebook 참조 실행에서는 Python 라이브러리를 관리하기 위한 인라인 명령이 지원되지 않습니다. 실행의 정확성을 보장하려면 참조된 Notebook에서 이러한 인라인 명령을 제거하는 것이 좋습니다.
%pip 대신 !pip를 권장합니다. !pip는 다음과 같은 제한 사항이 있는 IPython 기본 제공 셸 명령입니다.
!pip는 실행기 노드가 아닌 드라이버 노드에만 패키지를 설치합니다.!pip를 통해 설치하는 패키지는 기본 제공 패키지와의 충돌 또는 Notebook에 이미 패키지를 가져왔는지 여부에 영향을 미치지 않습니다.
그러나, %pip가 이러한 시나리오를 처리합니다. %pip를 통해 설치된 라이브러리는 드라이버 및 실행기 노드 모두에서 사용할 수 있으며 이미 라이브러리를 가져온 경우에도 여전히 유효합니다.
팁
이 %conda install 명령은 일반적으로 새 Python 라이브러리를 설치하는 데 %pip install 명령보다 오래 걸립니다. 전체 종속성을 확인하고 충돌을 해결합니다.
안정성과 안정성을 높이는 데 %conda install를 사용할 수 있습니다. 설치하려는 라이브러리가 런타임 환경에서 미리 설치된 라이브러리와 충돌하지 않는 경우 %pip install를 사용할 수 있습니다.
사용 가능한 모든 Python 인라인 명령 및 설명은 %pip 명령 및 %conda 명령을 참조하세요.
인라인 설치를 통해 Python 공용 라이브러리 관리
이 예제에서는 인라인 명령을 사용하여 라이브러리를 관리하는 방법을 참조하세요. Python용 강력한 시각화 라이브러리인 altair를 일회성 데이터 탐색에 사용하려는 경우를 가정해 보겠습니다. 라이브러리가 작업 영역에 설치되어 있지 않다고 가정합니다. 다음 예제에서는 conda 명령을 사용하여 단계를 보여 줍니다.
인라인 명령을 사용하여 Notebook 또는 다른 항목의 다른 세션에 영향을 주지 않고 전자 필기장 세션에서 altair를 사용하도록 설정할 수 있습니다.
Notebook에서 다음 SQL 명령을 실행합니다. 첫 번째 명령은 altair 라이브러리를 설치합니다. 또한 시각화하는 데 사용할 수 있는 의미 체계 모델을 포함하는 vega_datasets 설치합니다.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda command셀의 출력은 설치 결과를 나타냅니다.
다른 Notebook 셀에서 다음 코드를 실행하여 패키지 및 의미 체계 모델을 가져옵니다.
import altair as alt from vega_datasets import data이제 세션 범위의 Altair 라이브러리를 사용하여 플레이할 수 있습니다.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
인라인 설치를 통해 Python 사용자 지정 라이브러리 관리
Python 사용자 지정 라이브러리를 Notebook 또는 연결된 환경의 리소스 폴더에 업로드할 수 있습니다. 리소스 폴더는 각 Notebook 및 환경에서 제공하는 기본 제공 파일 시스템입니다. 자세한 내용은 Notebook 리소스를 참조하세요. 업로드한 후 사용자 지정 라이브러리를 코드 셀로 끌어서 놓을 수 있습니다. 라이브러리를 설치하는 인라인 명령이 자동으로 생성됩니다. 또는 다음 명령을 사용하여 설치할 수 있습니다.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
R 인라인 설치
R 라이브러리를 관리하기 위해 Fabric은 install.packages(), remove.packages() 및 devtools:: 명령을 지원합니다. 사용 가능한 모든 R 인라인 명령 및 설명은 install.packages 명령 및 remove.package 명령을 참조하세요.
인라인 설치를 통해 R 공용 라이브러리 관리
이 예제에 따라 R 공용 라이브러리를 설치하는 단계를 안내합니다.
R 피드 라이브러리를 설치하려면 다음을 수행합니다.
Notebook 리본에서 작업 언어를 SparkR(R) 로 전환합니다.
Notebook 셀에서 다음 명령을 실행하여 caesar 라이브러리를 설치합니다.
install.packages("caesar")이제 Spark 작업으로 세션 범위 Caesar 라이브러리를 사용해 플레이할 수 있습니다.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
인라인 설치를 통해 Jar 라이브러리 관리
.jar 파일은 다음 명령을 사용하여 Notebook 세션에서 지원됩니다.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
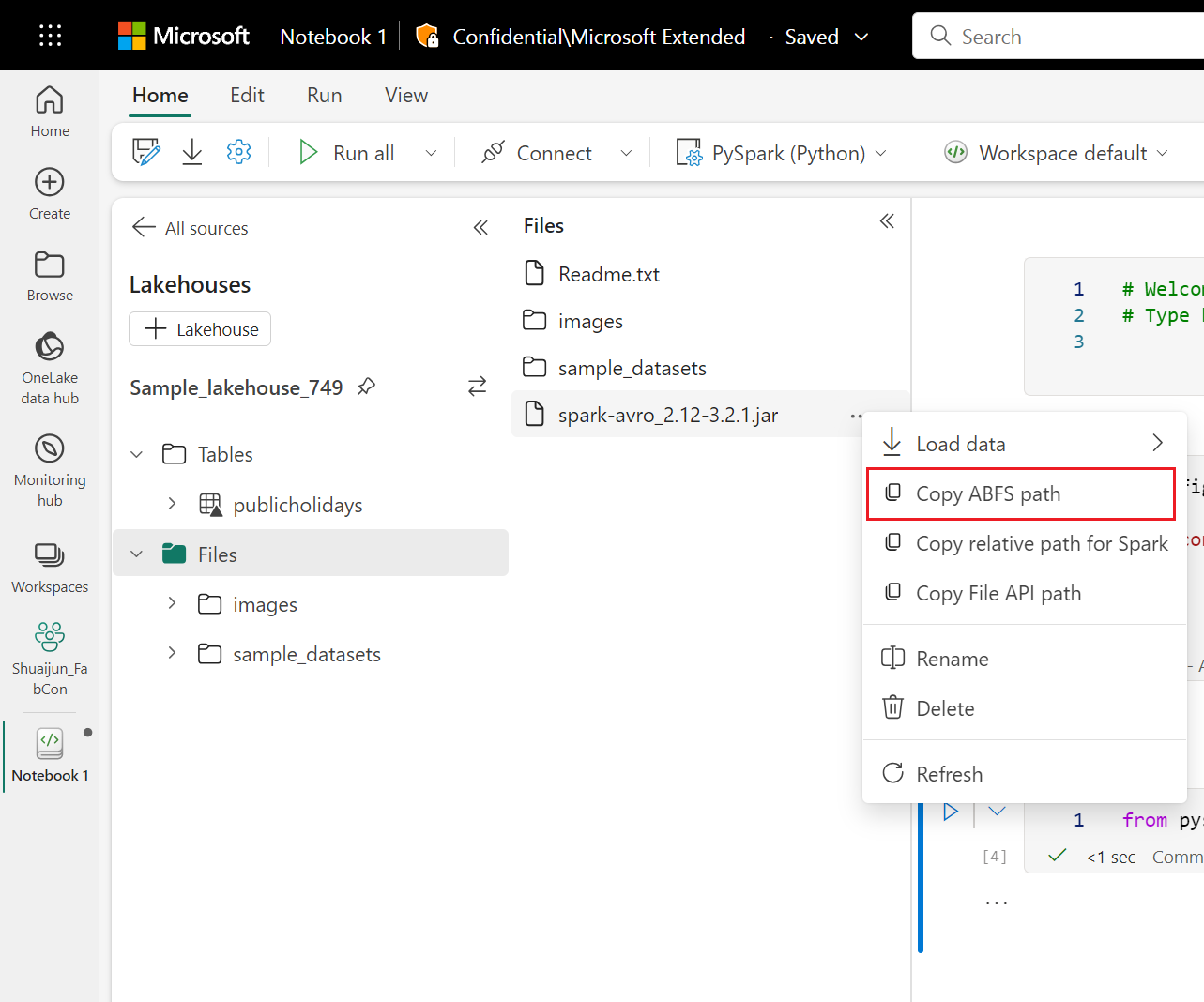
코드 셀은 Lakehouse의 스토리지를 예로 사용합니다. Notebook 탐색기에서 전체 파일 ABFS 경로를 복사하고 코드에서 바꿀 수 있습니다.