Azure HDInsight 작업을 실행하여 데이터 변환
Microsoft Fabric용 데이터 팩터리의 Azure HDInsight 작업을 사용하면 다음 Azure HDInsight 작업 유형을 오케스트레이션할 수 있습니다.
- Hive 쿼리 실행
- MapReduce 프로그램 호출
- Pig 쿼리 실행
- Spark 프로그램 실행
- Hadoop Stream 프로그램 실행
이 문서에서는 데이터 팩터리 인터페이스를 사용하여 Azure HDInsight 작업을 만드는 방법을 설명하는 단계별 연습을 제공합니다.
필수 조건
시작하려면 다음 필수 조건을 완료해야 합니다.
- 활성 구독이 있는 테넌트 계정. 체험 계정을 만듭니다.
- 작업 영역이 만들어집니다.
UI를 사용하여 파이프라인에 Azure HDInsight(HDI) 작업 추가
작업 영역에서 새 데이터 파이프라인을 만듭니다.
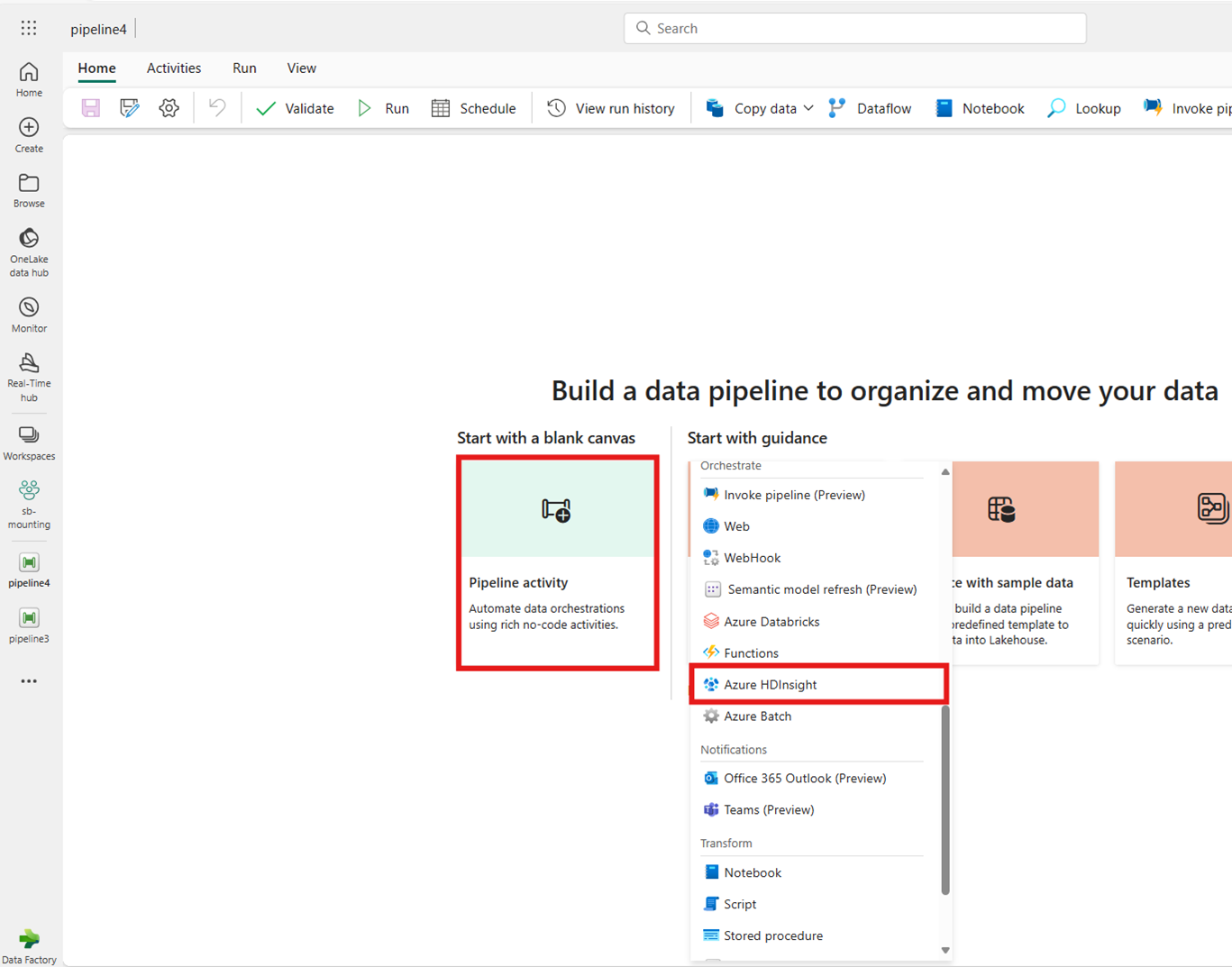
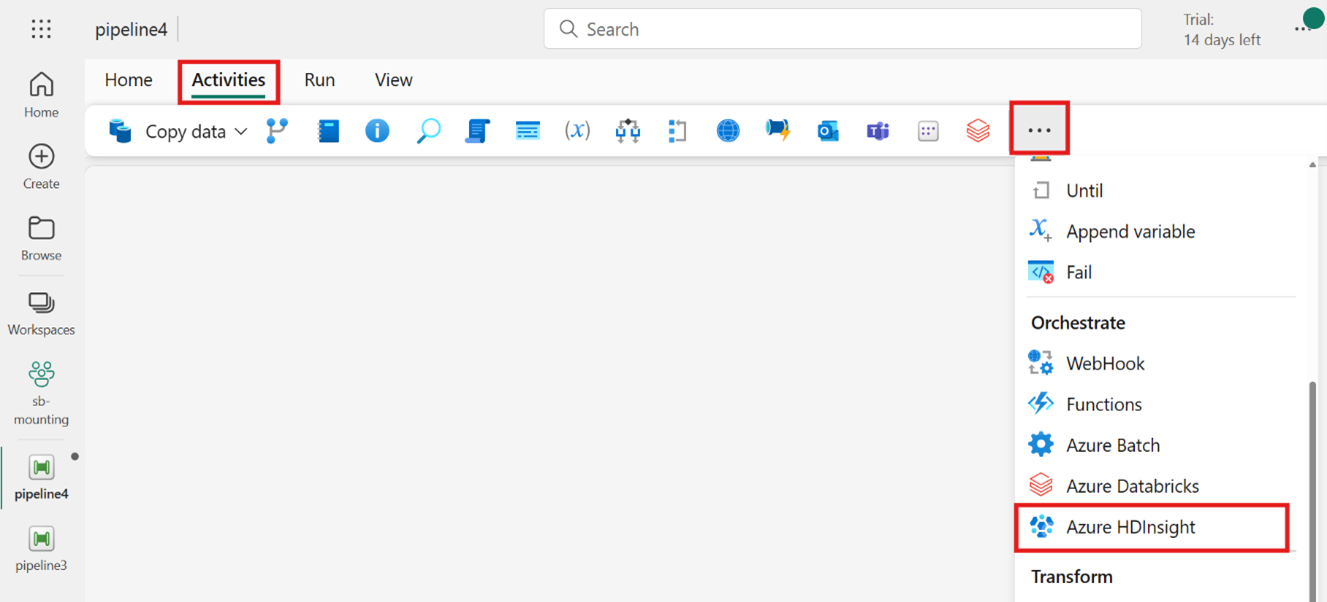
홈 화면 카드에서 Azure HDInsight를 검색하여 선택하거나 작업 표시줄에서 작업을 선택하여 파이프라인 캔버스에 추가합니다.
홈 화면 카드에서 작업 만들기:
작업 표시줄에서 작업 만들기:
아직 선택되지 않은 경우 파이프라인 편집기 캔버스에서 새 Azure HDInsight 작업을 선택합니다.
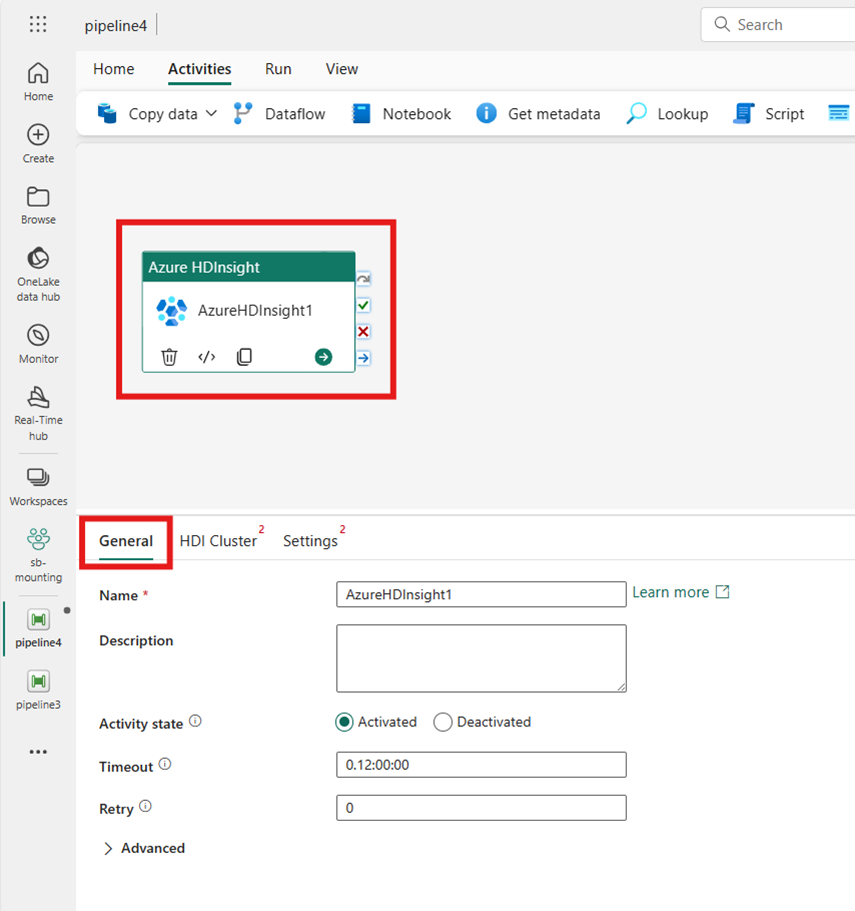
일반 설정 탭에 있는 옵션을 구성하려면 일반 설정 지침을 참조하세요.

HDI 클러스터 구성
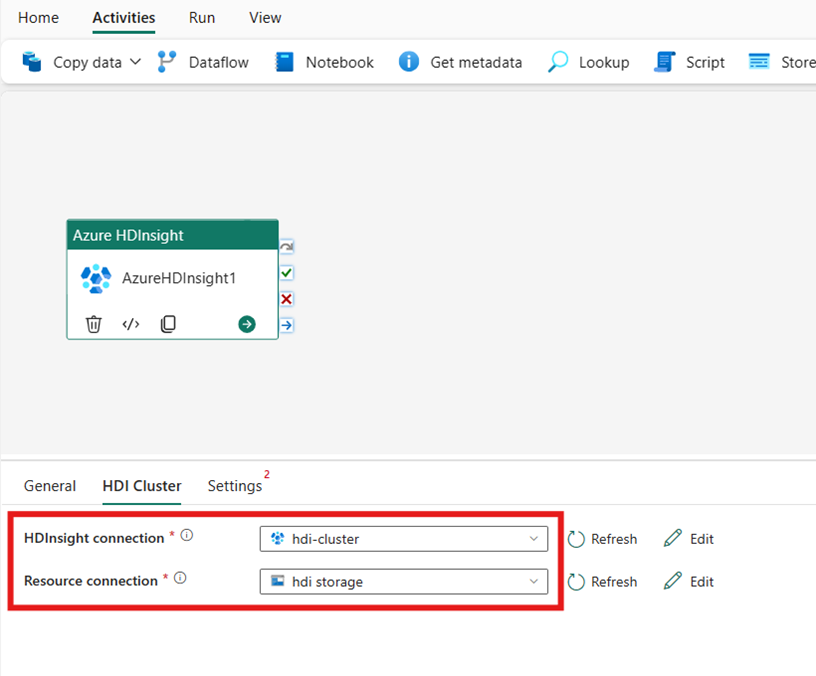
HDI 클러스터 탭을 선택합니다. 그런 다음 기존 HDInsight 연결을 선택하거나 새 HDInsight 연결을 만들 수 있습니다.
리소스 연결의 경우 Azure HDInsight 클러스터를 참조하는 Azure Blob Storage를 선택합니다. 기존 Blob 저장소를 선택하거나 새 Blob 저장소를 만들 수 있습니다.
설정 구성
설정 탭을 선택하여 작업에 대한 고급 설정을 확인합니다.
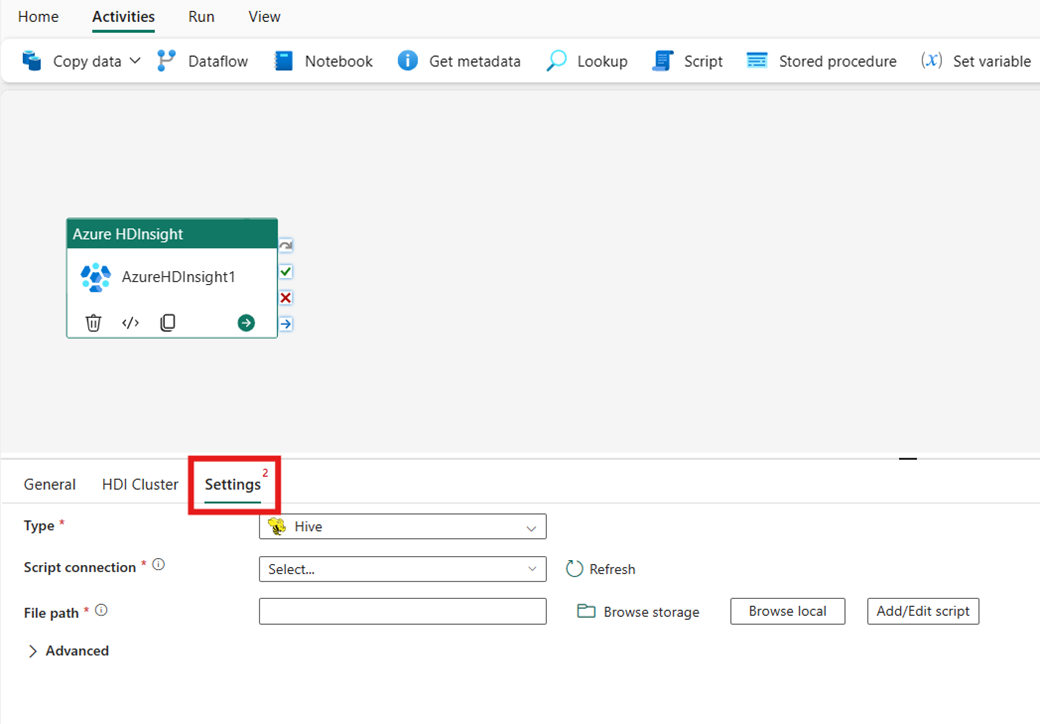
Azure Data Factory 및 Synapse Analytics HDInsight 연결된 서비스에서 지원되는 모든 고급 클러스터 속성 및 동적 식은 이제 UI의 고급 섹션에 있는 Microsoft Fabric의 데이터 팩터리용 Azure HDInsight 작업에서도 지원됩니다. 이러한 속성은 모두 동적 콘텐츠와 함께 사용하기 쉬운 사용자 지정 매개 변수화된 식을 지원합니다.
클러스터 유형
HDInsight 클러스터에 대한 설정을 구성하려면 먼저 Hive, Map Reduce, Pig, Spark 및 Streaming을 비롯한 사용 가능한 옵션에서 해당 형식을 선택합니다.
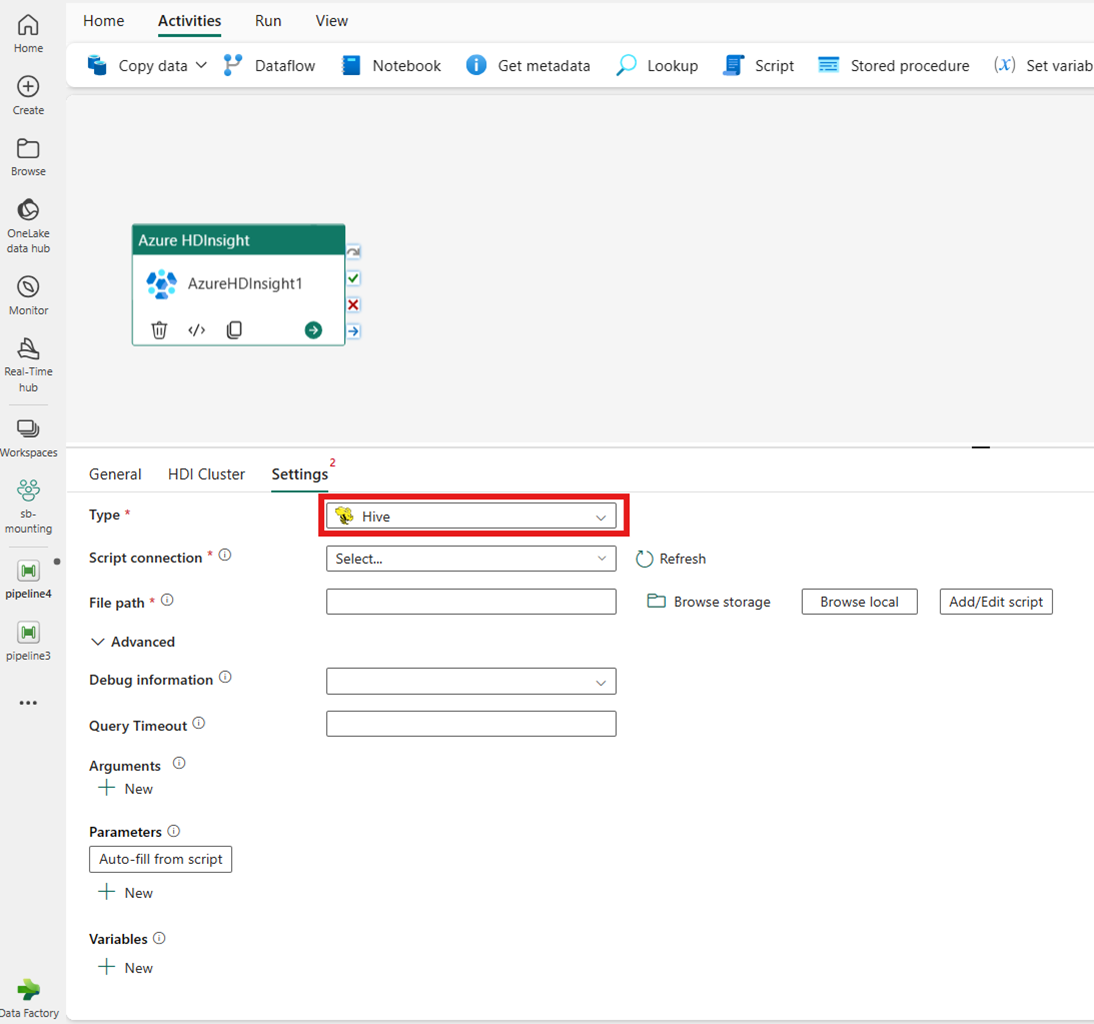
Hive
형식으로 Hive를 선택하면 작업은 Hive 쿼리를 실행합니다. 선택에 따라 Hive 유형을 보유하는 스토리지 계정을 참조하는 스크립트 연결을 지정할 수 있습니다. 기본적으로 HDI 클러스터 탭에서 지정한 스토리지 연결이 사용됩니다. Azure HDInsight에서 실행할 파일 경로를 지정해야 합니다. 선택에 따라 고급 섹션, 디버그 정보, 쿼리 시간 제한, 인수, 매개 변수 및 변수에서 더 많은 구성을 지정할 수 있습니다.
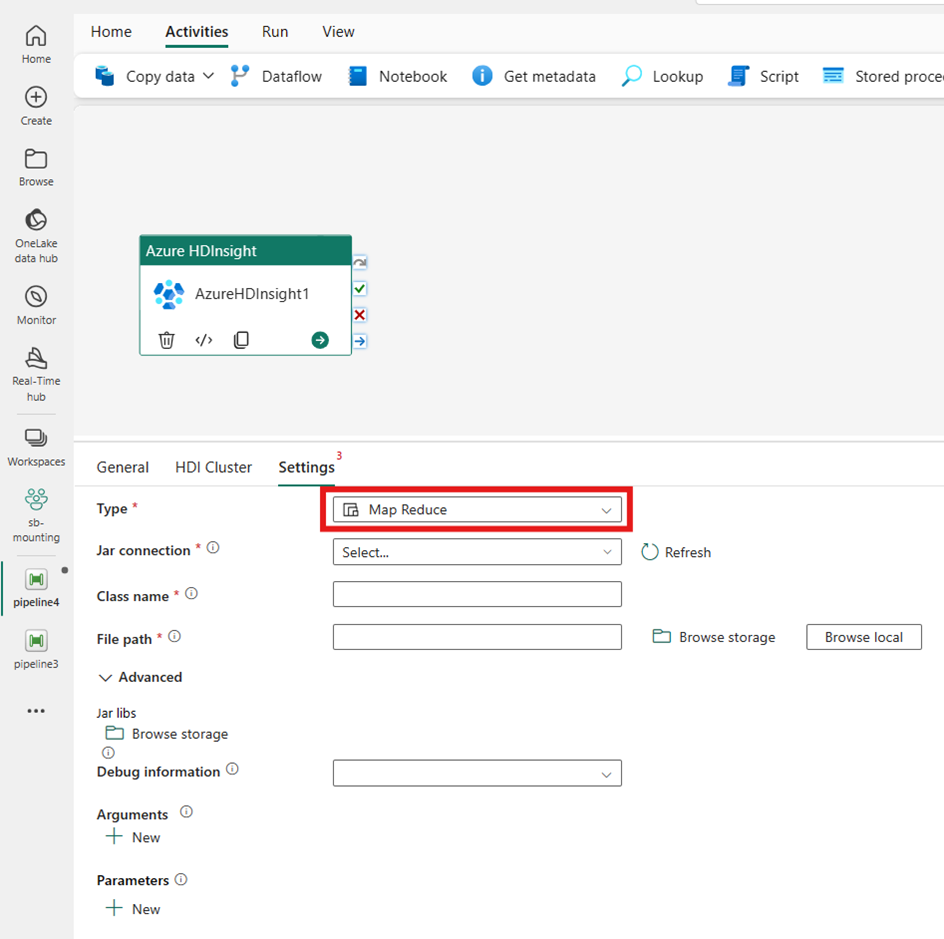
Map Reduce
형식으로 Map Reduce를 선택하면 작업이 Map Reduce 프로그램을 호출합니다. 선택에 따라 Map Reduce 형식을 보유하는 스토리지 계정을 참조하는 Jar 연결에서 지정할 수 있습니다. 기본적으로 HDI 클러스터 탭에서 지정한 스토리지 연결이 사용됩니다. Azure HDInsight에서 실행할 클래스 이름 및 파일 경로를 지정해야 합니다. 선택에 따라 고급 섹션에서 Jar 라이브러리 가져오기, 디버그 정보, 인수 및 매개 변수 등 더 많은 구성 세부 정보를 지정할 수 있습니다.
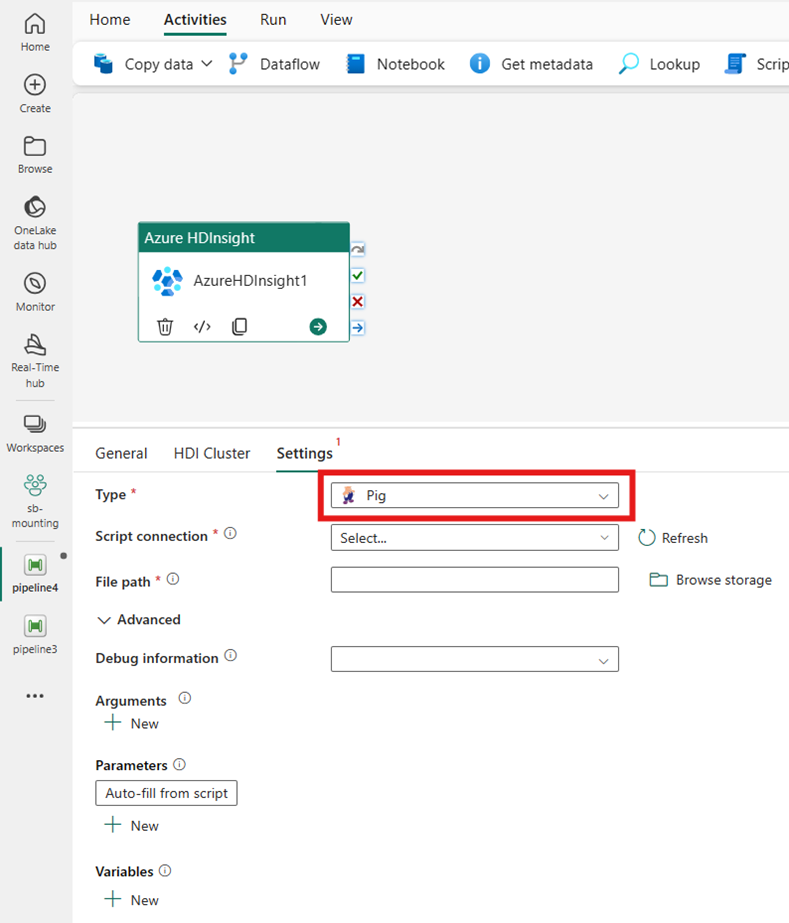
Pig
형식으로 Pig를 선택하면 작업이 Pig 쿼리를 호출합니다. 선택적으로 Pig 형식을 보유하는 스토리지 계정을 참조하는 스크립트 연결 설정을 지정할 수 있습니다. 기본적으로 HDI 클러스터 탭에서 지정한 스토리지 연결이 사용됩니다. Azure HDInsight에서 실행할 파일 경로를 지정해야 합니다. 선택에 따라 고급 섹션에서 디버그 정보, 인수, 매개 변수 및 변수 등 더 많은 구성을 지정할 수 있습니다.
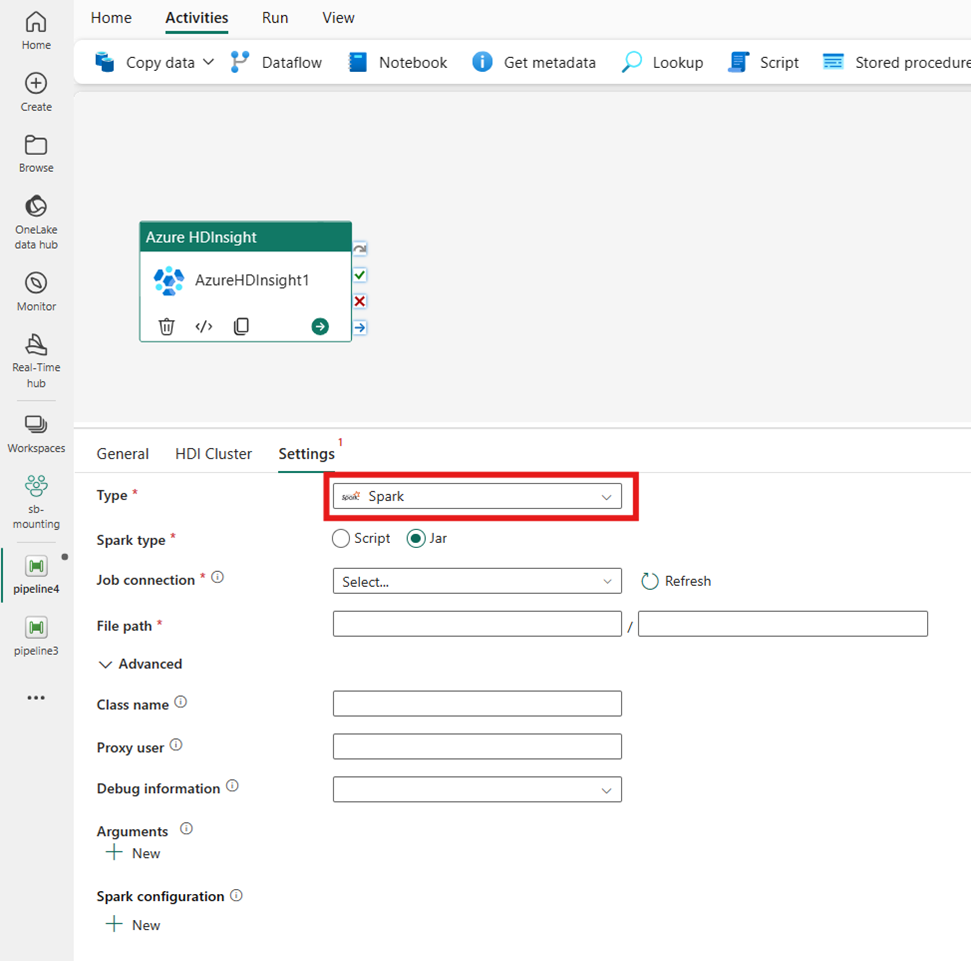
Spark
형식에 대해 Spark를 선택하는 경우 활동은 Spark 프로그램을 호출합니다. Spark 유형에 대해 스크립트 또는 Jar를 선택합니다. 선택적으로 Spark 형식을 보유하는 스토리지 계정을 참조하는 작업 연결 설정을 지정할 수 있습니다. 기본적으로 HDI 클러스터 탭에서 지정한 스토리지 연결이 사용됩니다. Azure HDInsight에서 실행할 파일 경로를 지정해야 합니다. 선택에 따라 고급 섹션에서 클래스 이름, 프록시 사용자, 디버그 정보, 인수 및 spark 구성 등 더 많은 구성을 지정할 수 있습니다.
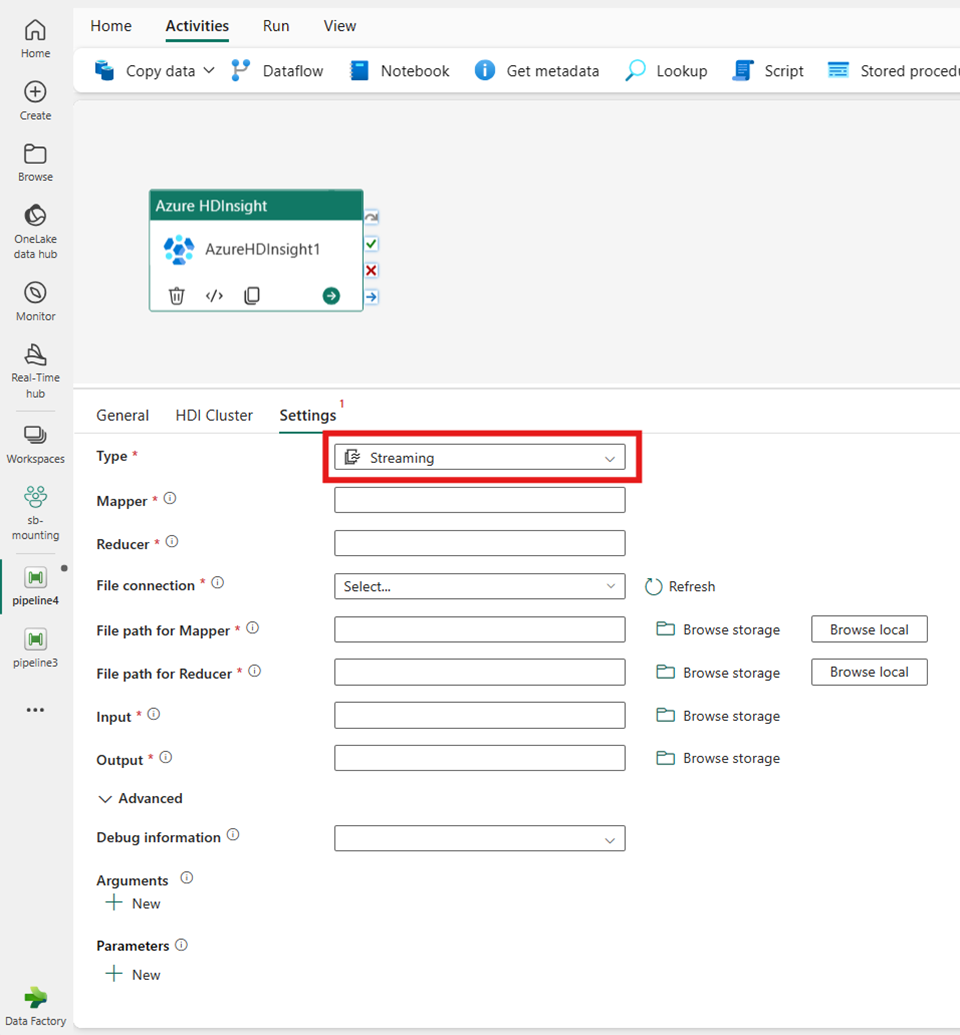
Streaming
형식으로 Streaming을 선택히먄 스트리밍 프로그램을 호출합니다. Mapper 및 Reducer 이름을 지정하고, 선택에 따라 스트리밍 유형을 보유하는 스토리지 계정을 참조하는 파일 연결을 지정할 수 있습니다. 기본적으로 HDI 클러스터 탭에서 지정한 스토리지 연결이 사용됩니다. Azure HDInsight에서 실행할 Mapper에 대한 파일 경로 및 Reducer에 대한 파일 경로를 지정해야 합니다. WASB 경로에 대한 입력 및 출력 옵션도 포함합니다. 선택에 따라 고급 섹션에서 디버그 정보, 인수 및 매개 변수 등 더 많은 구성을 지정할 수 있습니다.
속성 참조
| 속성 | 설명 | 필수 |
|---|---|---|
| type | Hadoop 스트리밍 작업의 경우 작업 유형은 HDInsightStreaming입니다. | 예 |
| mapper | mapper 실행 파일의 이름을 지정합니다. | 예 |
| reducer | reducer 실행 파일의 이름을 지정합니다. | 예 |
| combiner | combiner 실행 파일의 이름을 지정합니다. | 아니요 |
| 파일 연결 | 실행할 Mapper, Combiner 및 Reducer 프로그램을 저장하는 데 사용되는 Azure Storage 연결된 서비스에 대한 참조입니다. | 아니요 |
| 여기서는 Azure Blob Storage 및 ADLS Gen2 연결만 지원됩니다. 이 연결을 지정하지 않으면 HDInsight 연결에 정의된 스토리지 연결이 사용됩니다. | ||
| filePath | 파일 연결에서 참조하는 Azure Storage에 저장된 Mapper, Combiner 및 Reducer 프로그램의 경로 배열을 제공합니다. | 예 |
| input | Mapper에 대한 입력 파일의 WASB 경로를 지정합니다. | 예 |
| output | Reducer에 대한 출력 파일의 WASB 경로를 지정합니다. | 예 |
| getDebugInfo | scriptLinkedService에 지정되었거나 HDInsight 클러스터에 사용된 Azure Storage에 로그 파일을 언제 복사할지 지정합니다. | 아니요 |
| 허용되는 값: None, Always 또는 Failure. 기본값은 None입니다. | ||
| arguments | Hadoop 작업에 대한 인수 배열을 지정합니다. 인수는 각 작업에 대한 명령줄 인수로 전달됩니다. | 아니요 |
| defines | Hive 스크립트 내에서 참조하기 위해 매개 변수를 키/값 쌍으로 지정합니다. | 아니요 |
파이프라인 저장 및 실행 또는 예약
파이프라인에 필요한 다른 작업을 구성한 후 파이프라인 편집기 맨 위에 있는 홈 탭으로 전환하고 저장 버튼을 선택하여 파이프라인을 저장합니다. 실행을 선택하여 직접 실행하거나 예약을 선택해 일정을 잡습니다. 여기에서 실행 기록을 보거나 다른 설정을 구성할 수도 있습니다.
