복사 작업에서 MongoDB 구성
이 문서에서는 Azure 데이터 팩터리 Synapse Analytics 파이프라인에서 복사 작업을 사용하여 MongoDB 데이터베이스에서 데이터를 복사하는 방법을 간략하게 설명합니다.
지원되는 구성
복사 작업 아래의 각 탭을 구성하려면 각각 다음 섹션으로 이동합니다.
일반
일반 설정 탭을 구성하려면 일반 설정 지침을 참조하세요.
원본
원본 탭으로 이동하여 복사 작업 원본을 구성합니다. 자세한 구성은 다음 내용을 참조하세요.
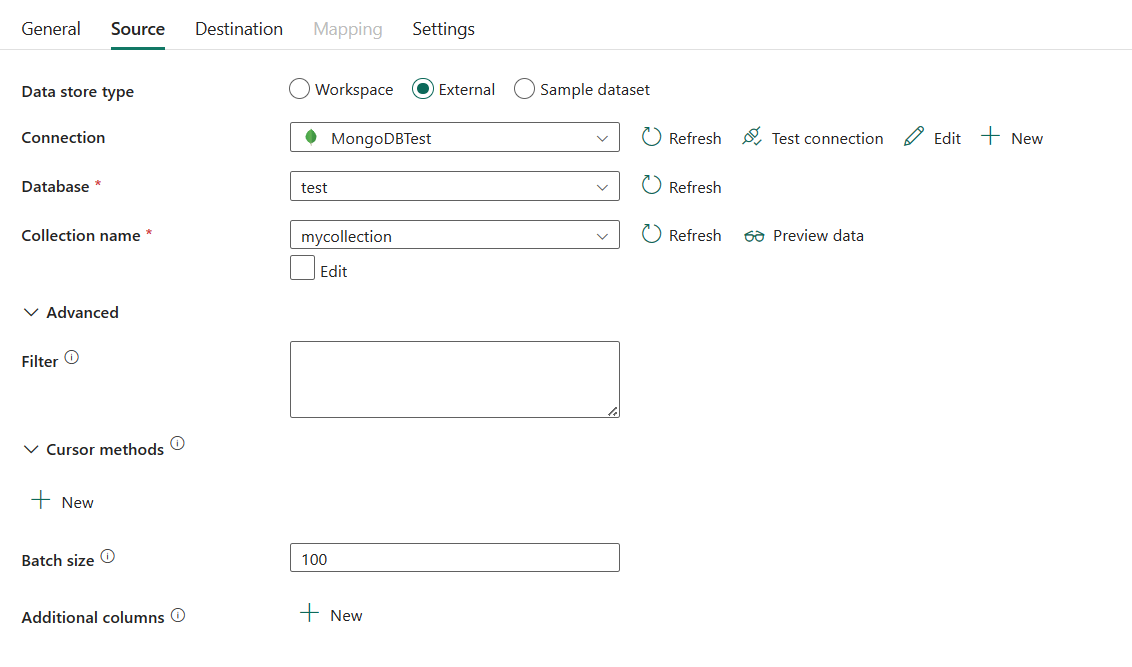
다음 속성은 필수입니다.
- 데이터 저장소 유형: 외부를 선택합니다.
- 연결: 연결 목록에서 MongoDB 연결을 선택합니다. 연결이 없으면 새로 만들기를 선택하여 새 MongoDB 연결을 만듭니다.
- 데이터베이스: 드롭다운 목록에서 데이터베이스를 선택합니다.
- 컬렉션 이름: MongoDB 데이터베이스에서 컬렉션의 이름을 지정합니다. 드롭다운 목록에서 컬렉션을 선택하거나 편집을 선택하여 수동으로 입력할 수 있습니다.
고급에서 다음 필드를 지정할 수 있습니다.
- 필터: 쿼리 연산자를 사용하여 선택 영역 필터를 지정합니다. 컬렉션의 모든 문서를 반환하려면 이 매개 변수를 생략하거나 빈 문서({})를 전달합니다.
- 커서 방식: + 새로 만들기를 선택하여 기본 쿼리가 실행되는 방식을 지정합니다. 쿼리를 실행하는 방법은 다음과 같습니다.
- 프로젝트: 프로젝션에 대한 문서에서 반환할 필드를 지정합니다. 일치하는 문서에서 모든 필드를 반환하려면 이 매개 변수를 생략합니다.
- 정렬: 쿼리가 일치하는 문서를 반환하는 순서를 지정합니다. 자세한 내용은 cursor.sort()로 이동합니다.
- 한도: 서버에서 반환하는 문서의 최대 수를 지정합니다. 자세한 내용은 cursor.limit()로 이동합니다.
- 건너뛰기: MongoDB가 결과를 반환하기 시작하는 위치에서 건너뛸 문서 수를 지정합니다. 자세한 내용은 cursor.skip()로 이동합니다.
- 일괄 처리 크기: MongoDB 인스턴스의 응답을 각각 일괄 처리로 반환할 문서 수를 지정합니다. 대부분의 경우 일괄 처리 크기를 수정해도 사용자 또는 애플리케이션에 영향이 없습니다.
- 추가 열: 데이터 열을 추가하여 원본 파일의 상대 경로 또는 정적 값을 저장하세요. 식은 정적 값에 대해 지원됩니다.
대상
대상 탭으로 이동하여 복사 작업 대상을 구성합니다. 자세한 구성은 다음 내용을 참조하세요.
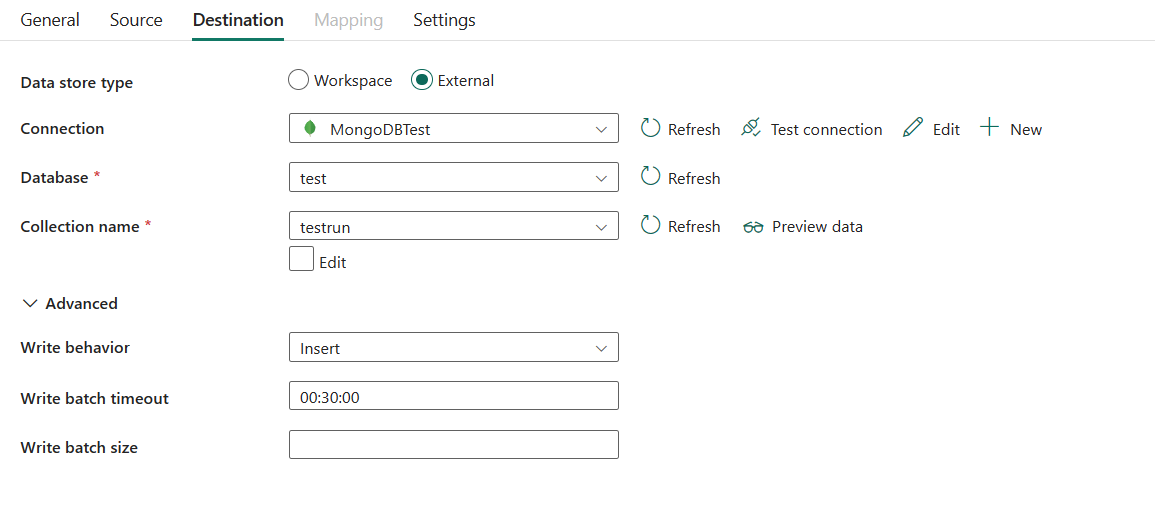
다음 속성은 필수입니다.
- 데이터 저장소 유형: 외부를 선택합니다.
- 연결: 연결 목록에서 MongoDB 연결을 선택합니다. 연결이 없으면 새로 만들기를 선택하여 새 MongoDB 연결을 만듭니다.
- 데이터베이스: 드롭다운 목록에서 데이터베이스를 선택합니다.
- 컬렉션 이름: MongoDB 데이터베이스에서 컬렉션의 이름을 지정합니다. 드롭다운 목록에서 컬렉션을 선택하거나 편집을 선택하여 수동으로 입력할 수 있습니다.
고급에서 다음 필드를 지정할 수 있습니다.
쓰기 동작: MongoDB에 데이터를 쓰는 방법을 설명합니다. 허용되는 값: insert 및 upsert.
Upsert 동작은 동일한
_id의 문서가 이미 존재하는 경우 문서를 바꾸는 것으로, 존재하지 않는 경우 문서를 삽입하는 것입니다.참고 항목
원본 문서 또는 열 매핑을 통해
_id이(가) 지정되지 않은 경우 이 서비스는 자동으로 문서에 대한_id을(를) 생성합니다. 즉, Upsert가 예상대로 작동하려면 문서에 ID가 있는지 확인해야 합니다.쓰기 일괄 처리 시간 제한: 일괄 처리 삽입 작업이 시간 초과되기 전에 완료될 때까지의 대기 시간을 지정합니다. 허용되는 값은 시간 간격입니다.
쓰기 일괄 처리 크기: 이 속성은 각 일괄 처리에 기록할 문서의 크기를 제어합니다. 성능을 개선하기 위해 값을 늘리고 문서 크기가 커지는 경우 값을 줄여 볼 수 있습니다.
매핑
매핑 탭 구성에 대해서는 매핑 탭에서 매핑 구성을 참조하세요. 데이터 원본과 대상이 모두 계층적 데이터인 경우에는 매핑이 지원되지 않습니다.
설정
설정 탭을 구성하려면 설정 탭에서 기타 설정 구성으로 이동합니다.
표 요약
다음 표에는 MongoDB의 복사 활동에 대한 자세한 정보가 포함되어 있습니다.
원본 정보
| 이름 | 설명 | 값 | 필수 | JSON 스크립트 속성 |
|---|---|---|---|---|
| 데이터 저장소 유형 | 데이터 저장소 유형입니다. | 외부 | 예 | / |
| 연결 | 원본 데이터 저장소에 대한 연결입니다. | < MongoDB 연결 > | 예 | 연결 |
| 데이터베이스 | 원본으로 사용하는 데이터베이스입니다. | < 데이터베이스 > | 예 | 데이터베이스 |
| 컬렉션 이름 | MongoDB 데이터베이스에 있는 컬렉션의 이름입니다. | < 컬렉션 > | 예 | 컬렉션 |
| Filter | 쿼리 연산자를 사용한 선택 필터입니다. 컬렉션의 모든 문서를 반환하려면 이 매개 변수를 생략하거나 빈 문서({})를 전달합니다. | < 선택 필터 > | 아니요 | 필터링 |
| 커서 방식 | 기본 쿼리가 실행되는 방식입니다. | • project • 정렬 • 한도 • 건너뛰기 |
아니요 | cursorMethods: • project • 정렬 • 한도 • 건너뛰기 |
| Batch 크기 | MongoDB 인스턴스의 응답을 각각 일괄 처리로 반환할 문서 수입니다. | < 쓰기 일괄 처리 크기 > (기본값은 100) |
아니요 | batchSize |
| 추가 열 | 데이터 열을 추가하여 원본 파일의 상대 경로 또는 정적 값을 저장하세요. 식은 정적 값에 대해 지원됩니다. | • 이름 • 값 |
아니요 | additionalColumns: • 이름 • 값 |
대상 정보
| 이름 | 설명 | 값 | 필수 | JSON 스크립트 속성 |
|---|---|---|---|---|
| 데이터 저장소 유형 | 데이터 저장소 유형입니다. | 외부 | 예 | / |
| 연결 | 대상 데이터 저장소에 대한 연결입니다. | < MongoDB 연결 > | 예 | 연결 |
| 데이터베이스 | 대상으로 사용하는 데이터베이스입니다. | < 데이터베이스 > | 예 | 데이터베이스 |
| 컬렉션 이름 | MongoDB 데이터베이스에 있는 컬렉션의 이름입니다. | < 컬렉션 > | 예 | 컬렉션 |
| 쓰기 동작 | MongoDB에 데이터를 쓰는 방법을 설명합니다. 허용되는 값: insert 및 upsert. Upsert 동작은 동일한 _id의 문서가 이미 존재하는 경우 문서를 바꾸는 것으로, 존재하지 않는 경우 문서를 삽입하는 것입니다.참고: 원본 문서 또는 열 매핑을 통해 _id이(가) 지정되지 않은 경우 서비스에서 문서에 대한 _id을(를) 자동으로 생성합니다. 즉, Upsert가 예상대로 작동하려면 문서에 ID가 있는지 확인해야 합니다. |
• 삽입(기본값) • Upsert |
아니요 | writeBehavior: • 삽입 • upsert |
| 쓰기 일괄 처리 시간 제한 | 시간 초과되기 전에 배치 삽입 작업을 완료하기 위한 대기 시간입니다. | 시간 범위 (기본값은 00:30:00 - 30분) |
아니요 | writeBatchTimeout |
| 쓰기 일괄 처리 크기 | 각 일괄 처리에서 작성할 문서의 크기를 제어합니다. 이 값을 늘려 성능을 개선하고 문서 크기가 큰 경우 값을 줄일 수 있습니다. | < 쓰기 일괄 처리 크기 > | 아니요 | writeBatchSize |