데이터 흐름 Gen2 데이터 대상 및 관리되는 설정
Dataflow Gen2를 사용하여 데이터를 정리하고 준비한 후에는 데이터를 대상에 배치하려고 합니다. Dataflow Gen2의 데이터 대상 기능을 사용하여 이 작업을 수행할 수 있습니다. 이 기능을 사용하면 Azure SQL, Fabric Lakehouse 등 다양한 대상에서 선택할 수 있습니다. 그런 다음 데이터 흐름 Gen2는 대상에 데이터를 쓰고, 여기에서 추가 분석 및 보고를 위해 데이터를 사용할 수 있습니다.
다음 목록에는 지원되는 데이터 대상이 포함되어 있습니다.
- Azure SQL 데이터베이스
- Azure Data Explorer(Kusto)
- Fabric Lakehouse
- Fabric 웨어하우스
- Fabric KQL 데이터베이스
- 패브릭 SQL 데이터베이스
진입점
Dataflow Gen2의 모든 데이터 쿼리에는 데이터 대상이 있을 수 있습니다. 함수 및 목록은 지원되지 않습니다. 테이블 형식 쿼리에만 적용할 수 있습니다. 모든 쿼리의 데이터 대상을 개별적으로 지정할 수 있으며 데이터 흐름 내에서 여러 다른 대상을 사용할 수 있습니다.
데이터 대상을 지정하는 세 가지 주요 진입점이 있습니다.
위쪽 리본을 통해.
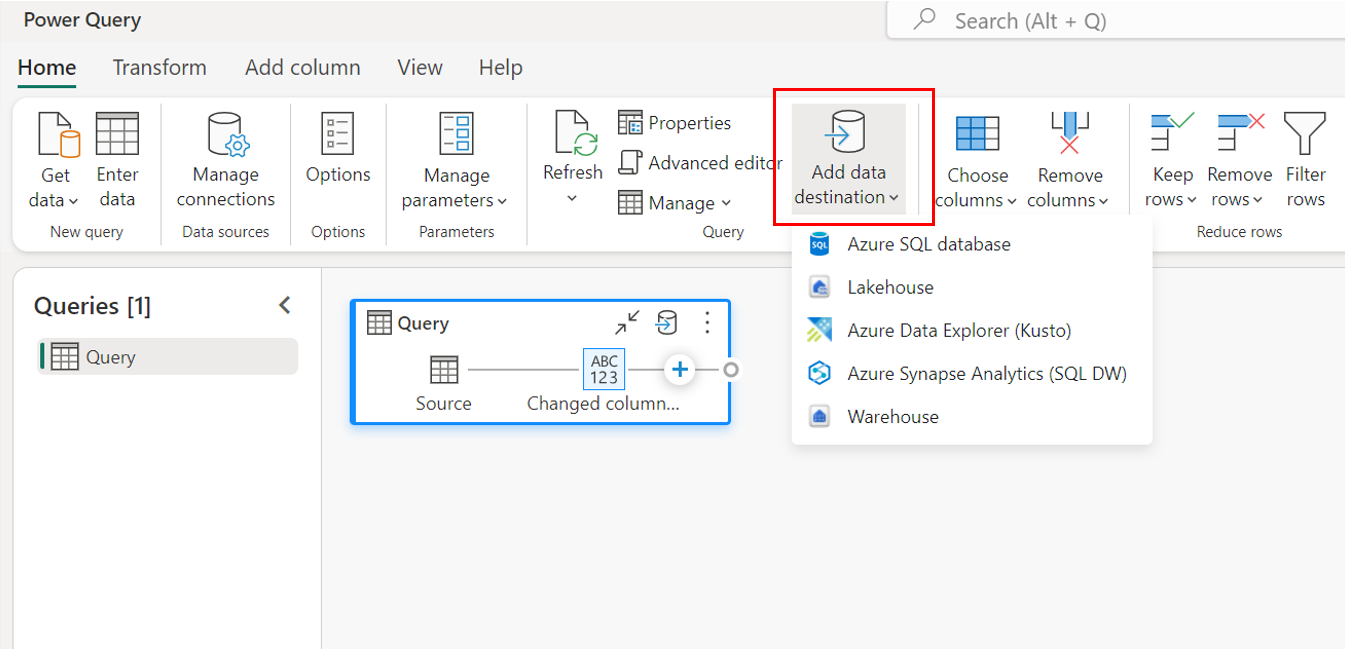
쿼리 설정을 통해
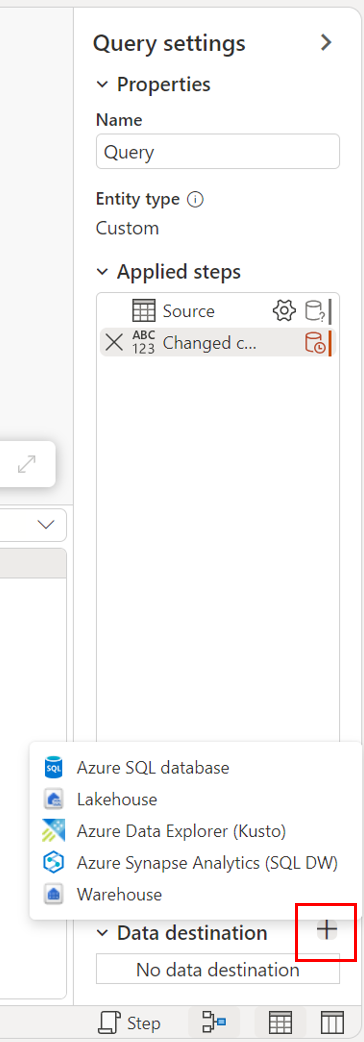
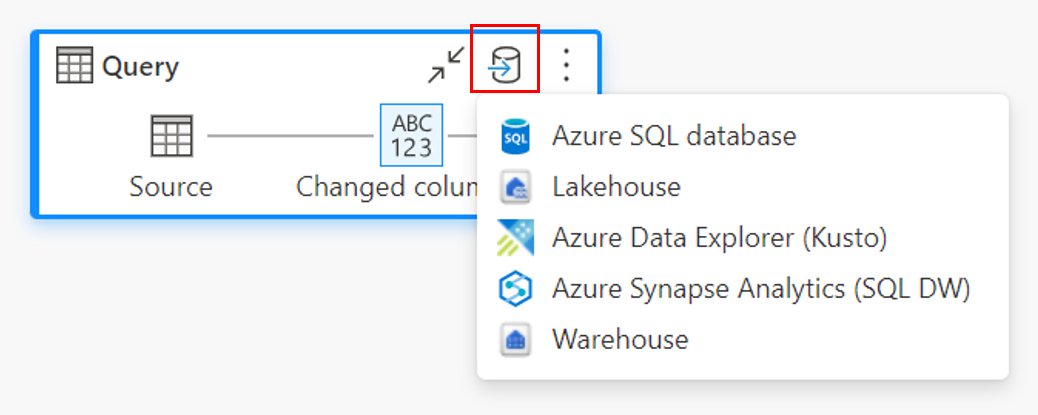
다이어그램 보기를 통해
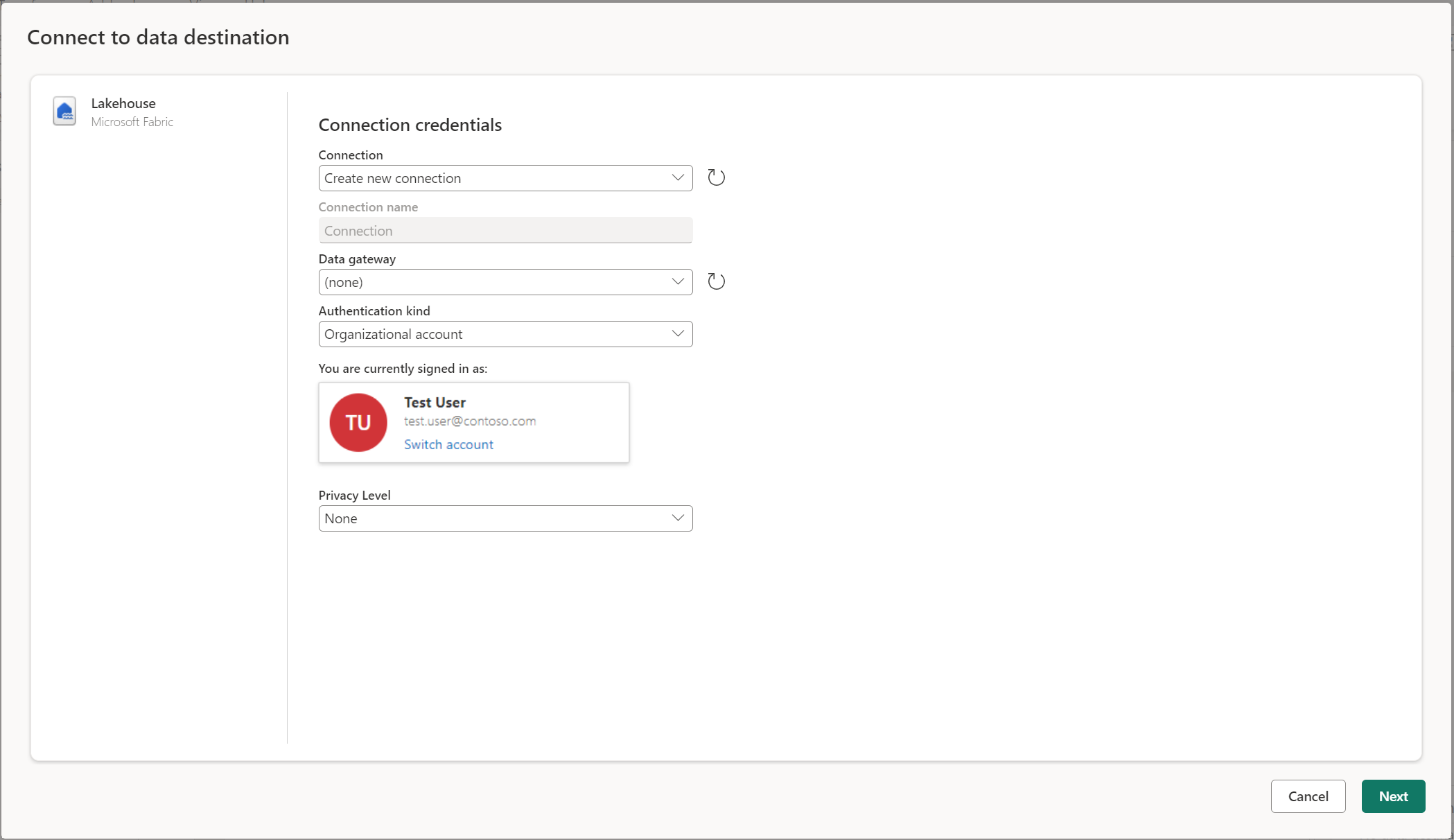
데이터 대상에 연결
데이터 대상에 연결하는 것은 데이터 원본에 연결하는 것과 비슷합니다. 데이터 원본에 대한 올바른 권한이 있는 경우 데이터를 읽고 쓰는 데 연결을 사용할 수 있습니다. 새 연결을 만들거나 기존 연결을 선택한 다음 다음을 선택해야 합니다.
새 테이블을 만들거나 기존 테이블을 선택하세요.
데이터 대상으로 로드할 때 새 테이블을 만들거나 기존 테이블을 선택할 수 있습니다.
새 테이블 만들기
새 테이블을 만들도록 선택하면 Dataflow Gen2 새로 고침 중에 데이터 대상에 새 테이블이 만들어집니다. 나중에 수동으로 대상으로 이동하여 테이블을 삭제하면 다음 데이터 흐름 새로 고침 중에 데이터 흐름이 테이블을 다시 만듭니다.
기본적으로 테이블 이름은 쿼리 이름과 동일합니다. 대상에서 지원하지 않는 테이블 이름에 잘못된 문자가 있으면 테이블 이름이 자동으로 조정됩니다. 예를 들어 많은 대상은 공백이나 특수 문자를 지원하지 않습니다.
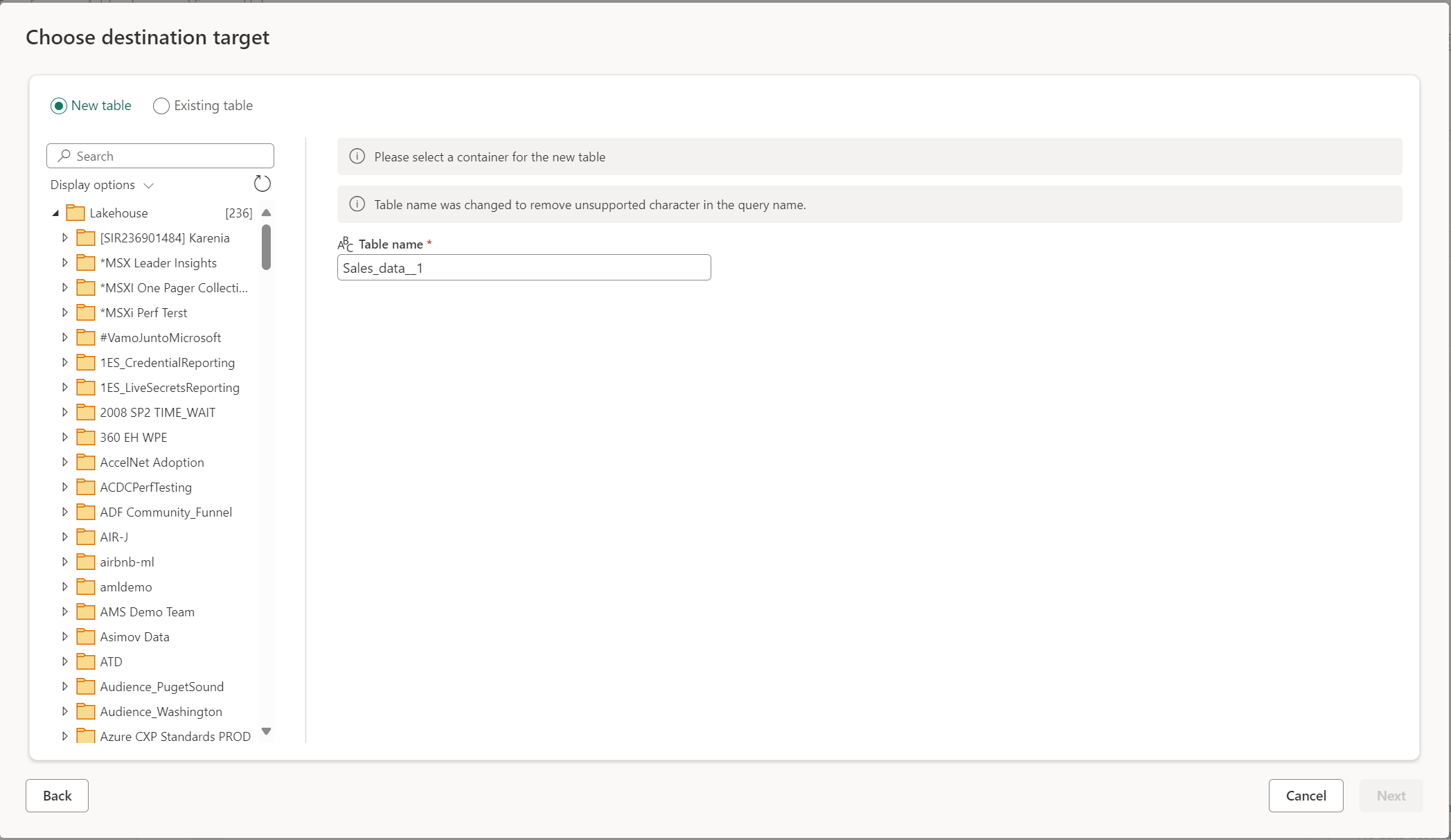
다음으로 대상 컨테이너를 선택해야 합니다. 패브릭 데이터 대상을 선택한 경우 탐색기를 사용하여 데이터를 로드할 패브릭 아티팩트 선택 Azure 대상의 경우 연결을 만드는 동안 데이터베이스를 지정하거나 탐색기 환경에서 데이터베이스를 선택할 수 있습니다.
기존 테이블 사용
기존 테이블을 선택하려면 탐색기의 맨 위에 있는 토글을 사용합니다. 기존 테이블을 선택할 때 탐색기를 사용하여 패브릭 아티팩트/데이터베이스와 테이블을 모두 선택해야 합니다.
기존 테이블을 사용하는 경우 어떤 시나리오에서도 테이블을 다시 만들 수 없습니다. 데이터 대상에서 테이블을 수동으로 삭제하는 경우 Dataflow Gen2는 다음 새로 고침에서 테이블을 다시 만들지 않습니다.
새 테이블에 대한 관리되는 설정
새 테이블에 로드하는 경우 자동 설정은 기본적으로 설정되어 있습니다. 자동 설정을 사용하는 경우 Dataflow Gen2에서 매핑을 관리합니다. 자동 설정은 다음과 같은 동작을 제공합니다.
업데이트 방법 바꾸기: 데이터는 모든 데이터 흐름 새로 고침 시 대체됩니다. 대상의 모든 데이터가 제거됩니다. 대상의 데이터가 데이터 흐름의 출력 데이터로 대체됩니다.
관리되는 매핑: 매핑이 관리됩니다. 데이터/쿼리를 변경하여 다른 열을 추가하거나 데이터 형식을 변경해야 하는 경우 데이터 흐름을 다시 게시할 때 이 변경 내용에 맞게 매핑이 자동으로 조정됩니다. 데이터 흐름을 변경할 때마다 데이터 대상 환경으로 이동할 필요가 없으므로 데이터 흐름을 다시 게시할 때 스키마를 쉽게 변경할 수 있습니다.
테이블 삭제 및 다시 만들기: 이러한 스키마 변경을 허용하려면 모든 데이터 흐름 새로 고침 시 테이블이 삭제되고 다시 만들어집니다. 데이터 흐름 새로 고침으로 인해 이전에 테이블에 추가된 관계 또는 측정값이 제거될 수 있습니다.
참고 항목
현재 자동 설정은 Lakehouse 및 Azure SQL 데이터베이스에 대해서만 데이터 대상으로 지원됩니다.
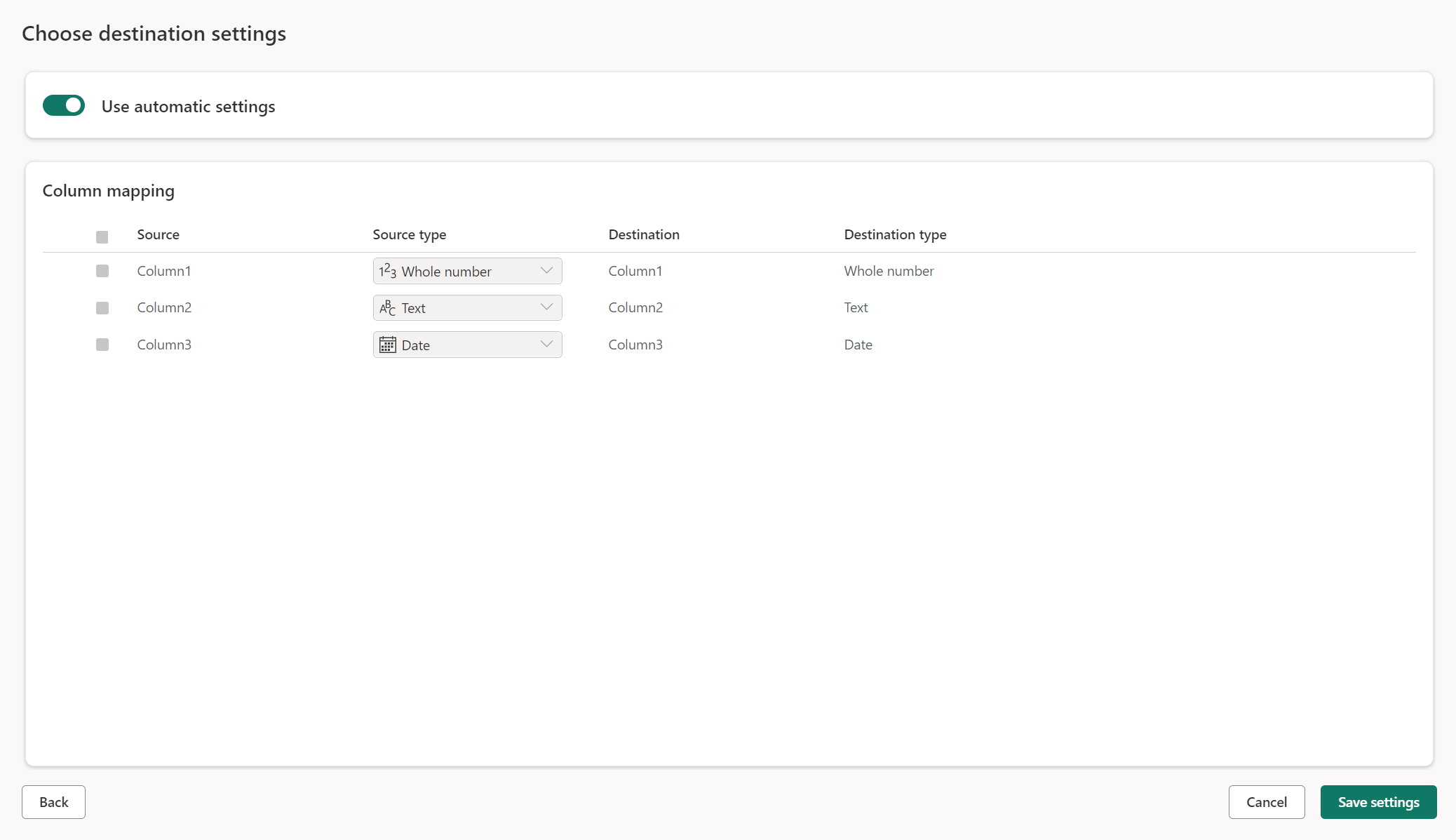
수동 설정
자동 설정 사용 설정을 해제하면 데이터 대상에 데이터를 로드하는 방법을 완전히 제어할 수 있습니다. 원본 형식을 변경하거나 데이터 대상에 필요하지 않은 열을 제외하여 열 매핑을 변경할 수 있습니다.
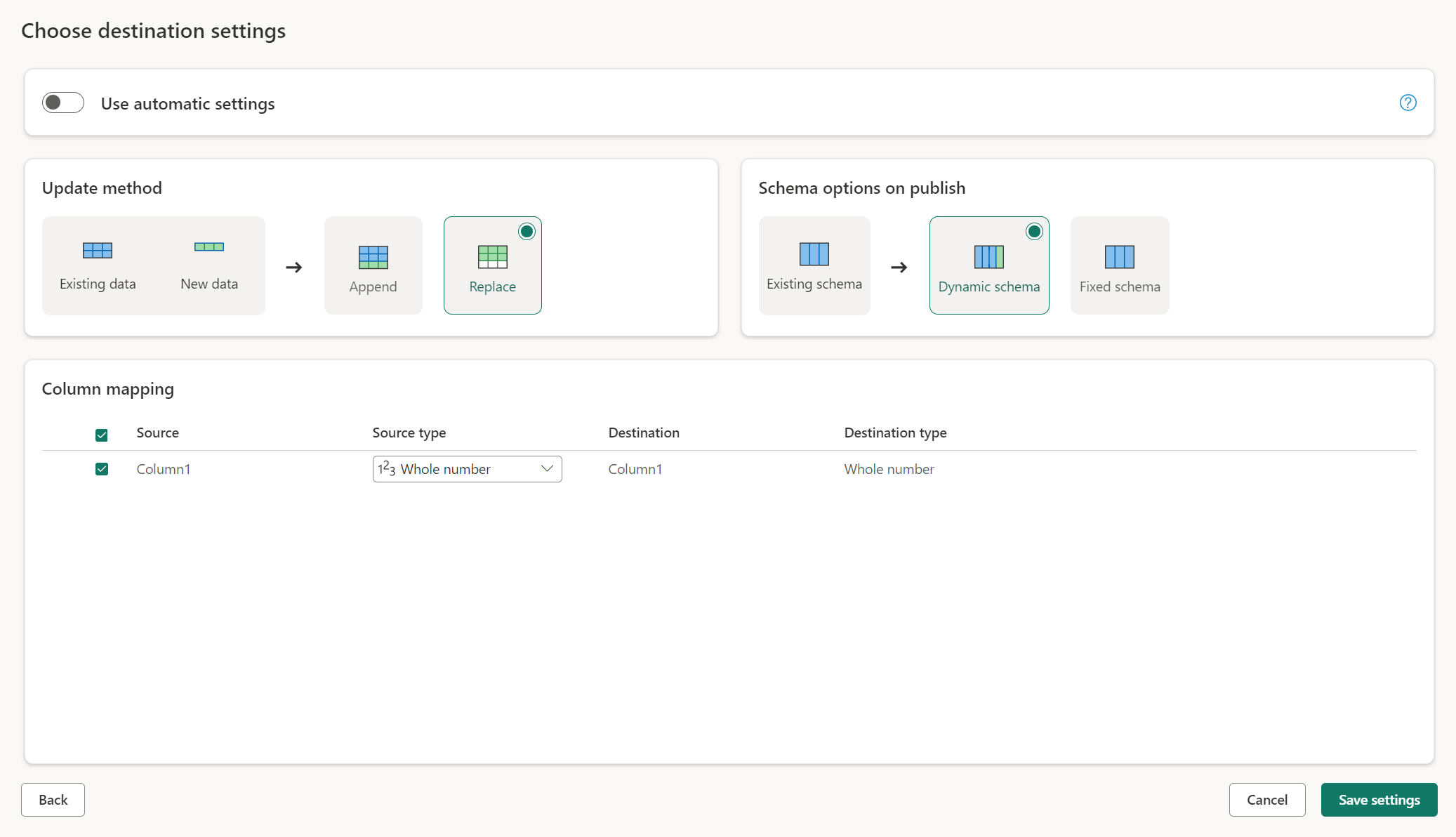
업데이트 메서드
대부분의 대상은 업데이트 메서드로 추가 및 바꾸기를 모두 지원합니다. 그러나 패브릭 KQL 데이터베이스 및 Azure Data Explorer는 업데이트 방법으로 대체를 지원하지 않습니다.
바꾸기: 모든 데이터 흐름 새로 고침에서 데이터는 대상에서 삭제되고 데이터 흐름의 출력 데이터로 대체됩니다.
추가: 모든 데이터 흐름 새로 고침에서 데이터 흐름의 출력 데이터가 데이터 대상 테이블의 기존 데이터에 추가됩니다.
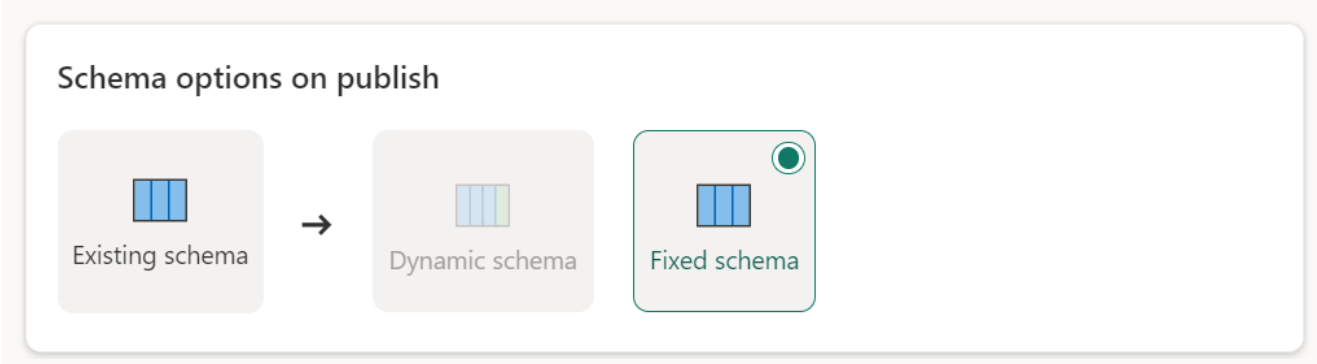
게시의 스키마 옵션
게시의 스키마 옵션은 업데이트 메서드가 바뀐 경우에만 적용됩니다. 데이터를 추가하면 스키마를 변경할 수 없습니다.
동적 스키마: 동적 스키마를 선택할 때 데이터 흐름을 다시 게시할 때 데이터 대상의 스키마 변경을 허용합니다. 관리되는 매핑을 사용하지 않으므로 쿼리를 변경할 때 데이터 흐름 대상 흐름에서 열 매핑을 업데이트해야 합니다. 데이터 흐름을 새로 고치면 테이블이 삭제되고 다시 만들어집니다. 데이터 흐름 새로 고침으로 인해 이전에 테이블에 추가된 관계 또는 측정값이 제거될 수 있습니다.
고정 스키마: 고정 스키마를 선택하면 스키마 변경이 불가능합니다. 데이터 흐름을 새로 고치면 테이블의 행만 삭제되고 데이터 흐름의 출력 데이터로 바뀝니다. 테이블의 모든 관계 또는 측정값은 그대로 유지됩니다. 데이터 흐름에서 쿼리를 변경하면 쿼리 스키마가 데이터 대상 스키마와 일치하지 않는 것을 감지하면 데이터 흐름 게시가 실패합니다. 스키마를 변경할 계획이 없고 대상 테이블에 관계 또는 측정값을 추가할 계획이 없는 경우 이 설정을 사용합니다.
참고 항목
Warehouse에 데이터를 로드하는 경우 고정 스키마만 지원됩니다.
대상별로 지원되는 데이터 원본 형식
| 저장소별 지원되는 데이터 유형 | DataflowStagingLakehouse | Azure DB(SQL) 출력 | Azure Data Explorer 출력 | Fabric Lakehouse(LH) 출력 | Fabric Warehouse(WH) 출력 | Fabric SQL Database(SQL) 출력 |
|---|---|---|---|---|---|---|
| 작업 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 | 없음 |
| 모두 | 없음 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
| 이진 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
| 통화 | 예 | 예 | 예 | 예 | 아니요 | 예 |
| DateTimeZone | 예 | 예 | 예 | 아니요 | 아니요 | 예 |
| 길이 | 아니요 | 아니요 | 예 | 아니요 | 아니요 | 아니요 |
| 함수 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
| None | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
| Null | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
| Time | 예 | 예 | 아니요 | 아니요 | 아니요 | 예 |
| Type | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
| 구조조 (리스트, 레코드, 테이블) | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 | 아니요 |
고급 항목
대상에 로드하기 전에 스테이징 사용
쿼리 처리 성능을 향상시키기 위해 Dataflows Gen2 내에서 스테이징을 사용하여 패브릭 컴퓨팅을 사용하여 쿼리를 실행할 수 있습니다.
쿼리(기본 동작)에서 스테이징을 사용하도록 설정하면 데이터가 스테이징 위치로 로드됩니다. 이 위치는 데이터 흐름 자체에서만 액세스할 수 있는 내부 Lakehouse입니다.
스테이징 위치를 사용하면 쿼리를 SQL 분석 엔드포인트로 접는 것이 메모리 처리보다 더 빠른 경우에 성능을 향상시킬 수 있습니다.
Lakehouse 또는 다른 non-warehouse 대상에 데이터를 로드하는 경우 기본적으로 스테이징 기능을 사용하지 않도록 설정하여 성능을 향상시킵니다. 데이터 대상에 데이터를 로드하는 경우 데이터는 스테이징을 사용하지 않고 데이터 대상에 직접 기록됩니다. 쿼리에 스테이징을 사용하려면 다시 사용하도록 설정할 수 있습니다.
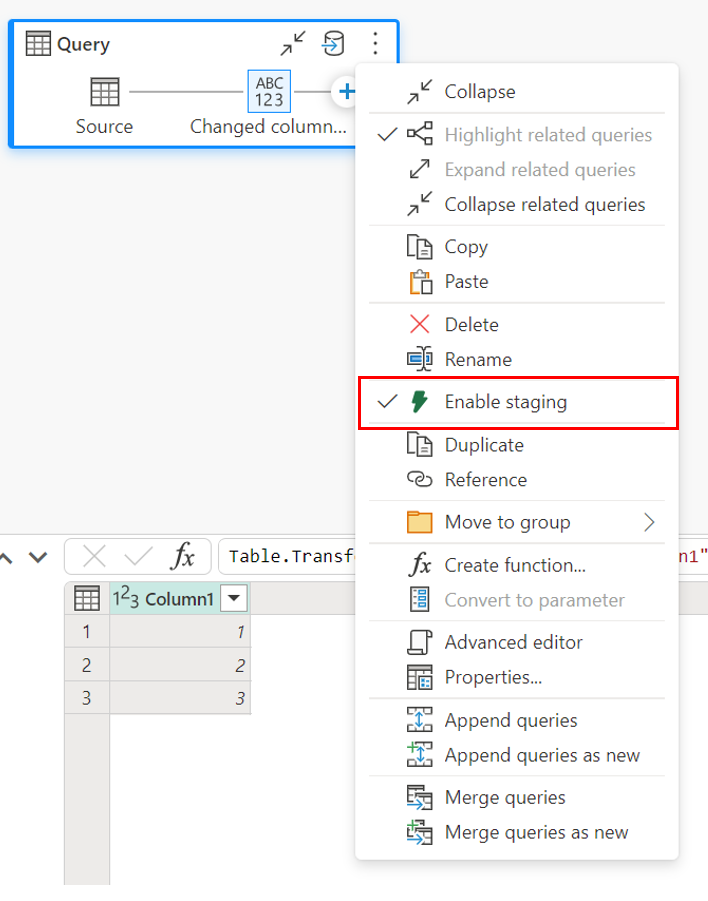
스테이징을 사용하도록 설정하려면 쿼리를 마우스 오른쪽 단추로 클릭하고 스테이징 사용 단추를 선택하여 스테이징을 사용하도록 설정합니다. 그러면 쿼리가 파란색으로 바뀝니다.
Warehouse에 데이터 로드
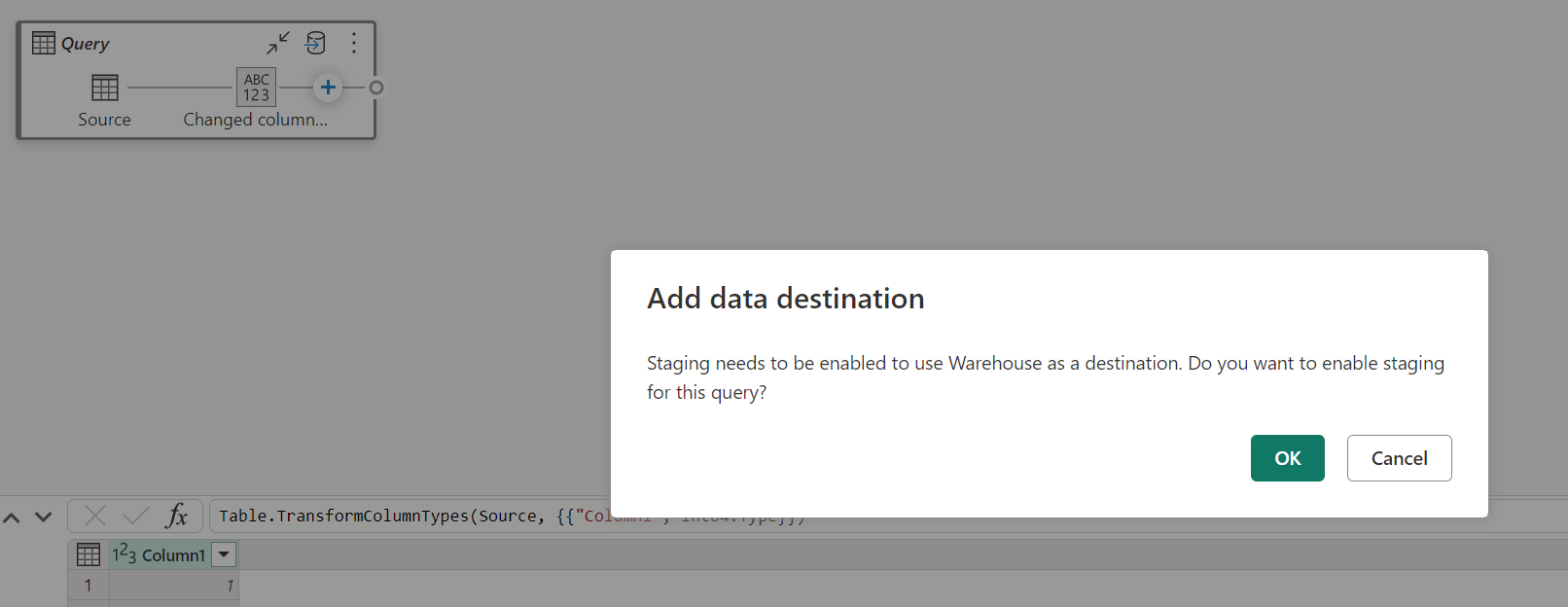
Warehouse에 데이터를 로드하는 경우 데이터 대상에 쓰기 작업을 하기 전에 스테이징이 필요합니다. 이 요구 사항은 성능을 향상시킵니다. 현재 데이터 흐름과 동일한 작업 영역에만 로드가 지원됩니다. Warehouse에 로드되는 모든 쿼리에 대해 스테이징이 사용하도록 설정되어 있는지 확인합니다.
스테이징을 사용하지 않도록 설정하고 Warehouse를 출력 대상으로 선택하면 데이터 대상을 구성하기 전에 먼저 스테이징을 사용하도록 설정하라는 경고가 표시됩니다.
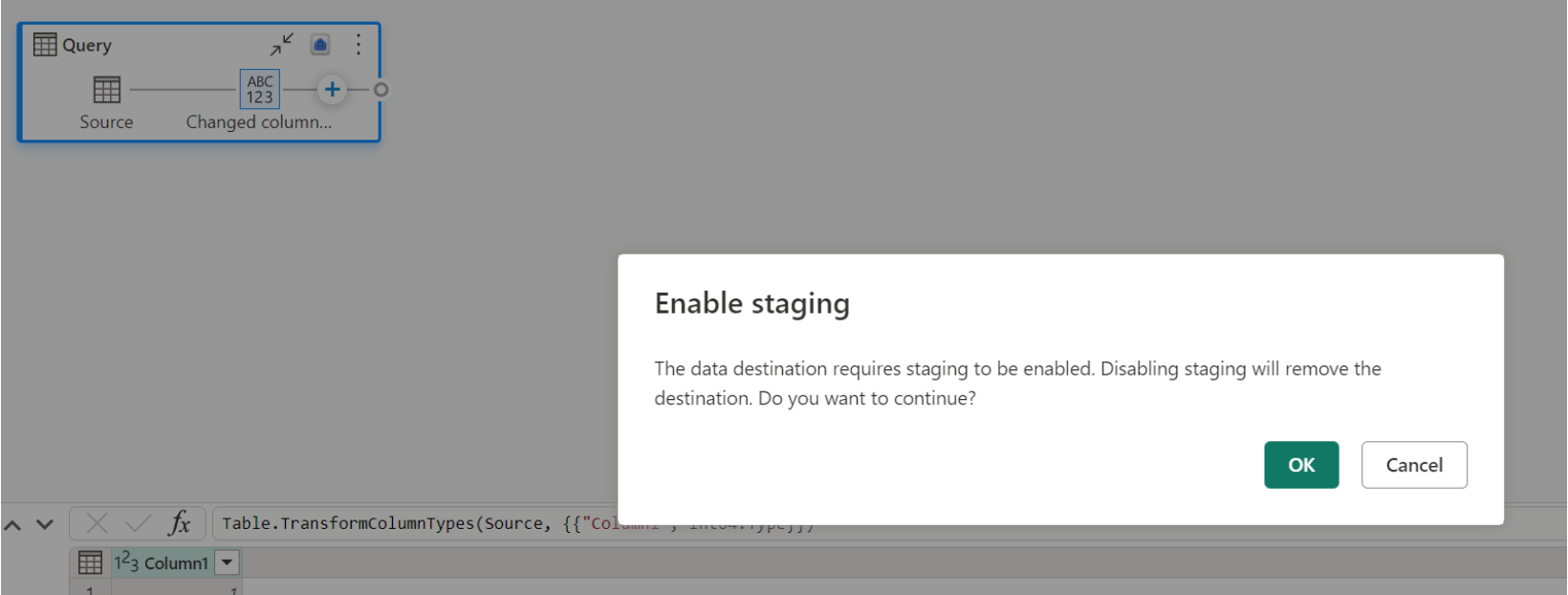
Warehouse가 대상으로 이미 있고 스테이징을 사용하지 않도록 설정하려고 하면 경고가 표시됩니다. Warehouse를 대상으로 제거하거나 준비 작업을 해제할 수 있습니다.
Lakehouse 데이터 대상 진공 처리
Microsoft Fabric에서 Dataflow Gen2의 대상으로 Lakehouse를 사용하는 경우 최적의 성능과 효율적인 스토리지 관리를 보장하기 위해 정기적인 유지 관리를 수행하는 것이 중요합니다. 중요한 유지 관리 작업 중 하나는 데이터 대상을 진공 청소하는 것입니다. 이 프로세스는 델타 테이블 로그에서 더 이상 참조되지 않는 이전 파일을 제거하여 스토리지 비용을 최적화하고 데이터의 무결성을 유지하는 데 도움이 됩니다.
진공이 중요한 이유
- 스토리지 최적화: 시간이 지남에 따라 델타 테이블은 더 이상 필요하지 않은 오래된 파일을 누적합니다. 진공은 이러한 파일을 정리하여 스토리지 공간을 확보하고 비용을 절감하는 데 도움이 됩니다.
- 성능 향상: 불필요한 파일을 제거하면 읽기 작업 중에 검사해야 하는 파일 수를 줄여 쿼리 성능을 향상시킬 수 있습니다.
- 데이터 무결성: 관련 파일만 유지되도록 하면 데이터의 무결성을 유지하여 판독기 오류 또는 테이블 손상으로 이어질 수 있는 커밋되지 않은 파일의 잠재적인 문제를 방지할 수 있습니다.
데이터 대상을 진공 청소하는 방법
Lakehouse에서 델타 테이블을 진공 청소하려면 다음 단계를 수행합니다.
- Lakehouse로 이동합니다. Microsoft Fabric 계정에서 원하는 Lakehouse로 이동합니다.
- 액세스 테이블 유지 관리: Lakehouse 탐색기에서 유지 관리하려는 테이블을 마우스 오른쪽 단추로 클릭하거나 줄임표를 사용하여 상황에 맞는 메뉴에 액세스합니다.
- 유지 관리 옵션 선택: 유지 관리 메뉴 항목을 선택하고 진공 옵션을 선택합니다.
- 진공 명령을 실행합니다. 보존 임계값(기본값은 7일)을 설정하고 지금 실행을 선택하여 진공 명령을 실행합니다.
모범 사례
- 보존 기간: 이전 스냅샷 및 커밋되지 않은 파일이 조기에 제거되지 않도록 보존 간격을 최소 7일로 설정하면 동시 테이블 판독기 및 기록기가 중단될 수 있습니다.
- 정기 유지 관리: 데이터 유지 관리 루틴의 일부로 정기적인 진공 청소를 예약하여 델타 테이블을 최적화하고 분석할 준비를 유지합니다.
데이터 유지 관리 전략에 진공을 통합하면 Lakehouse 대상이 데이터 흐름 작업에 효율적이고 비용 효율적이며 안정적으로 유지되도록 할 수 있습니다.
Lakehouse의 테이블 유지 관리에 대한 자세한 내용은 델타 테이블 유지 관리 설명서를 참조 하세요.
Nullable
Null 허용 열이 있는 경우 파워 쿼리에서 null을 허용하지 않는 것으로 검색되고 데이터 대상에 쓸 때 열 형식이 null을 허용하지 않는 경우가 있습니다. 새로 고치는 동안 다음 오류가 발생합니다.
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
null 허용 열을 강제로 적용하려면 다음 단계를 시도해 볼 수 있습니다.
데이터 대상에서 테이블을 삭제합니다.
데이터 흐름에서 데이터 대상을 제거합니다.
데이터 흐름으로 이동하여 다음 파워 쿼리 코드를 사용하여 데이터 형식을 업데이트합니다.
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )데이터 대상 추가
데이터 형식 변환 및 업 스케일링
데이터 흐름 내의 데이터 형식이 아래 데이터 대상에서 지원되는 것과 다른 경우가 있습니다. 데이터 대상에서 데이터를 계속 가져올 수 있도록 하기 위해 적용한 몇 가지 기본 변환이 있습니다.
| 대상 | 데이터 흐름 데이터 형식 | 대상 데이터 형식 |
|---|---|---|
| Fabric 웨어하우스 | Int8.Type | Int16.Type |