Dataflows Gen2의 빠른 복사
이 문서에서는 Microsoft Fabric의 Data Factory용 Dataflows Gen2의 빠른 복사 기능을 설명합니다. 데이터 흐름은 데이터를 수집하고 변환하는 데 도움이 됩니다. SQL DW 컴퓨팅을 사용하여 데이터 흐름 스케일 아웃이 도입되면 데이터를 대규모로 변환할 수 있습니다. 그러나 데이터를 먼저 수집해야 합니다. 빠른 복사가 도입되면 쉽게 데이터 흐름을 경험할 수 있지만 파이프라인 복사 작업의 확장 가능한 백 엔드를 사용하여 테라바이트 단위의 데이터를 수집할 수 있습니다.
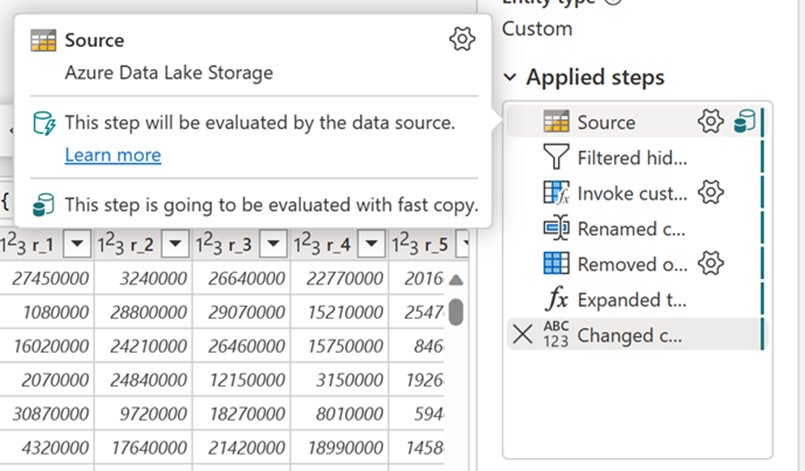
이 기능을 사용하도록 설정한 후 데이터 흐름은 데이터 흐름을 작성하는 동안 아무 것도 변경하지 않고도 데이터 크기가 특정 임계값을 초과하면 자동으로 백 엔드를 전환합니다. 데이터 흐름을 새로 고친 후 새로 고침 기록을 확인하여 실행 중에 표시되는 엔진 유형을 확인하여 빠른 복사본이 사용되었는지 확인할 수 있습니다.
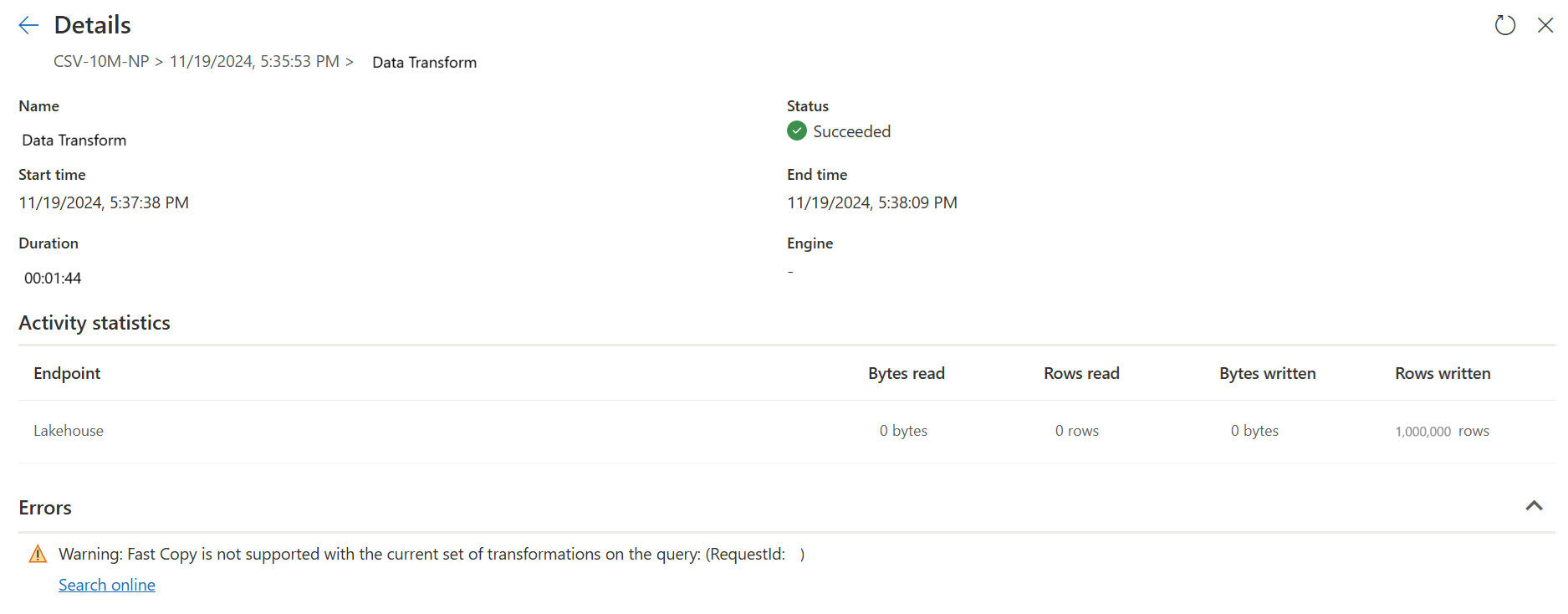
빠른 복사 옵션을 사용하도록 설정하면 빠른 복사를 사용하지 않으면 데이터 흐름 새로 고침이 취소됩니다. 이렇게 하면 새로 고침 시간 제한이 계속될 때까지 기다리지 않도록 방지할 수 있습니다. 이 동작은 디버깅 세션에서 대기 시간을 줄이면서 데이터 흐름 동작을 테스트하는 데 유용할 수도 있습니다. 쿼리 단계 창에서 빠른 복사 표시기를 사용하여 빠른 복사를 사용하여 쿼리를 실행할 수 있는지 쉽게 확인할 수 있습니다.
필수 조건
- Fabric 용량이 있어야 합니다.
- 파일 데이터의 경우 파일은 100MB 이상의 .csv 또는 parquet 형식이며 ADLS(Azure Data Lake Storage) Gen2 또는 Blob Storage 계정에 저장됩니다.
- Azure SQL DB 및 PostgreSQL을 포함한 데이터베이스의 경우 데이터 원본에 5백만 개 이상의 데이터 행이 있습니다.
참고 항목
"빠른 복사 필요" 설정을 선택하여 임계값을 우회하여 빠른 복사를 강제 적용할 수 있습니다.
커넥터 지원
빠른 복사는 현재 다음 Dataflow Gen2 커넥터에서 지원됩니다.
- ADLS Gen2
- Blob Storage
- Azure SQL DB
- Lakehouse
- PostgreSQL
- 온-프레미스 SQL Server
- 웨어하우스
- Oracle
- Snowflake
복사 작업은 파일 원본에 연결할 때 몇 가지 변환만 지원합니다.
- 파일 병합
- 열 선택
- 데이터 형식 변경
- 열 이름 바꾸기
- 열 제거
수집 및 변환 단계를 별도의 쿼리로 분할하여 다른 변환을 적용할 수 있습니다. 첫 번째 쿼리는 실제로 데이터를 검색하고 두 번째 쿼리는 DW 컴퓨팅을 사용할 수 있도록 결과를 참조합니다. SQL 원본의 경우 네이티브 쿼리의 일부인 모든 변환이 지원됩니다.
쿼리를 출력 대상으로 직접 로드하는 경우 현재 Lakehouse 대상만 지원됩니다. 다른 출력 대상을 사용하려면 먼저 쿼리를 스테이징하고 나중에 참조할 수 있습니다.
빠른 복사를 사용하는 방법
적절한 Fabric 엔드포인트로 이동합니다.
프리미엄 작업 영역으로 이동하여 Dataflow Gen2를 만듭니다.
새 데이터 흐름의 홈 탭에서 옵션을 선택합니다.
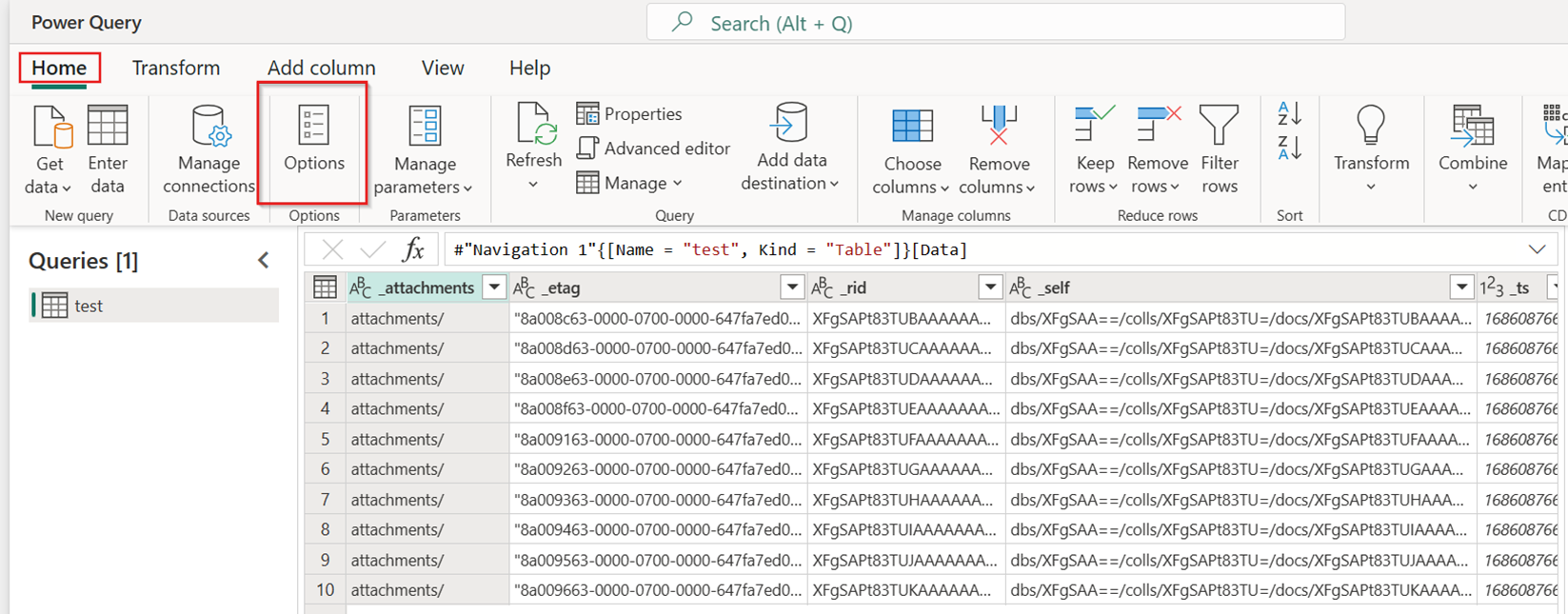
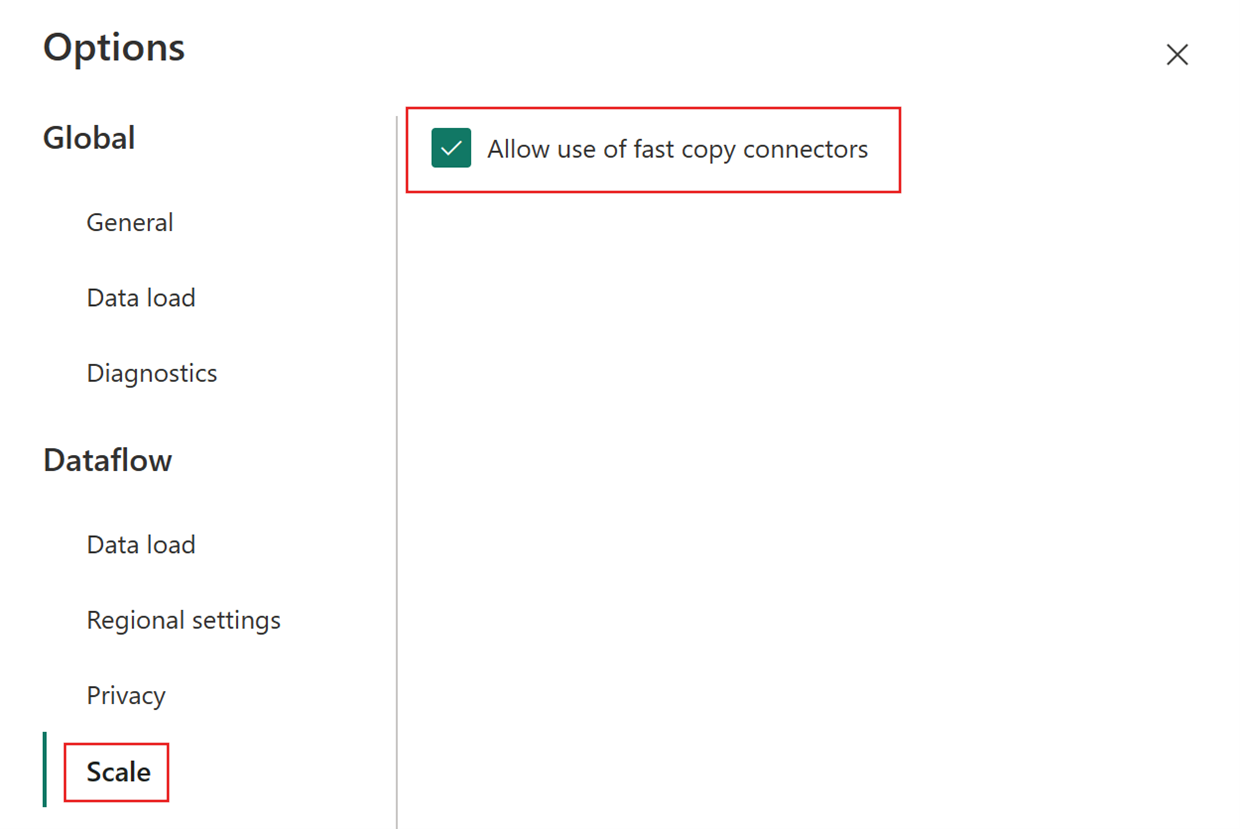
그런 다음 옵션 대화 상자에서 크기 조정 탭을 선택하고 빠른 복사 커넥터 사용 허용 확인란을 선택하여 빠른 복사를 켭니다. 그런 다음 옵션 대화 상자를 닫습니다.
데이터 가져오기를 선택한 다음 ADLS Gen2 원본을 선택하고 컨테이너에 대한 세부 정보를 입력합니다.
파일 결합 기능을 사용합니다.

빠른 복사를 보장하려면 이 문서의 커넥터 지원 섹션에 나열된 변환만 적용합니다. 더 많은 변환을 적용해야 하는 경우 먼저 데이터를 스테이징하고 나중에 쿼리를 참조합니다. 참조된 쿼리에서 다른 변환을 만듭니다.
(선택 사항) 쿼리를 마우스 오른쪽 단추로 클릭하여 해당 옵션을 선택하고 사용하도록 설정하여 쿼리에 대한 빠른 복사 필요 옵션을 설정할 수 있습니다.
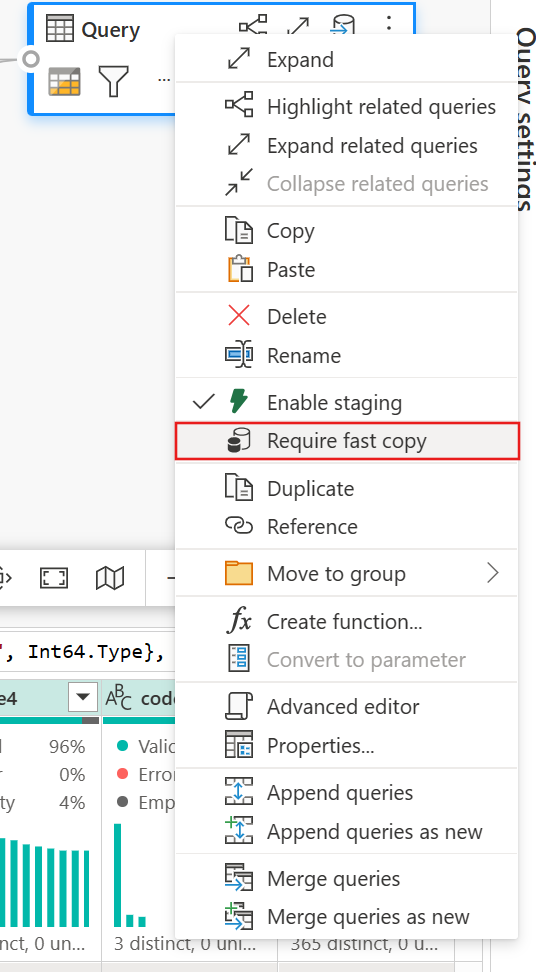
(선택 사항) 현재는 Lakehouse를 출력 대상으로만 구성할 수 있습니다. 다른 대상의 경우 쿼리를 스테이징하고 나중에 다른 쿼리에서 참조하여 원본에 출력할 수 있습니다.
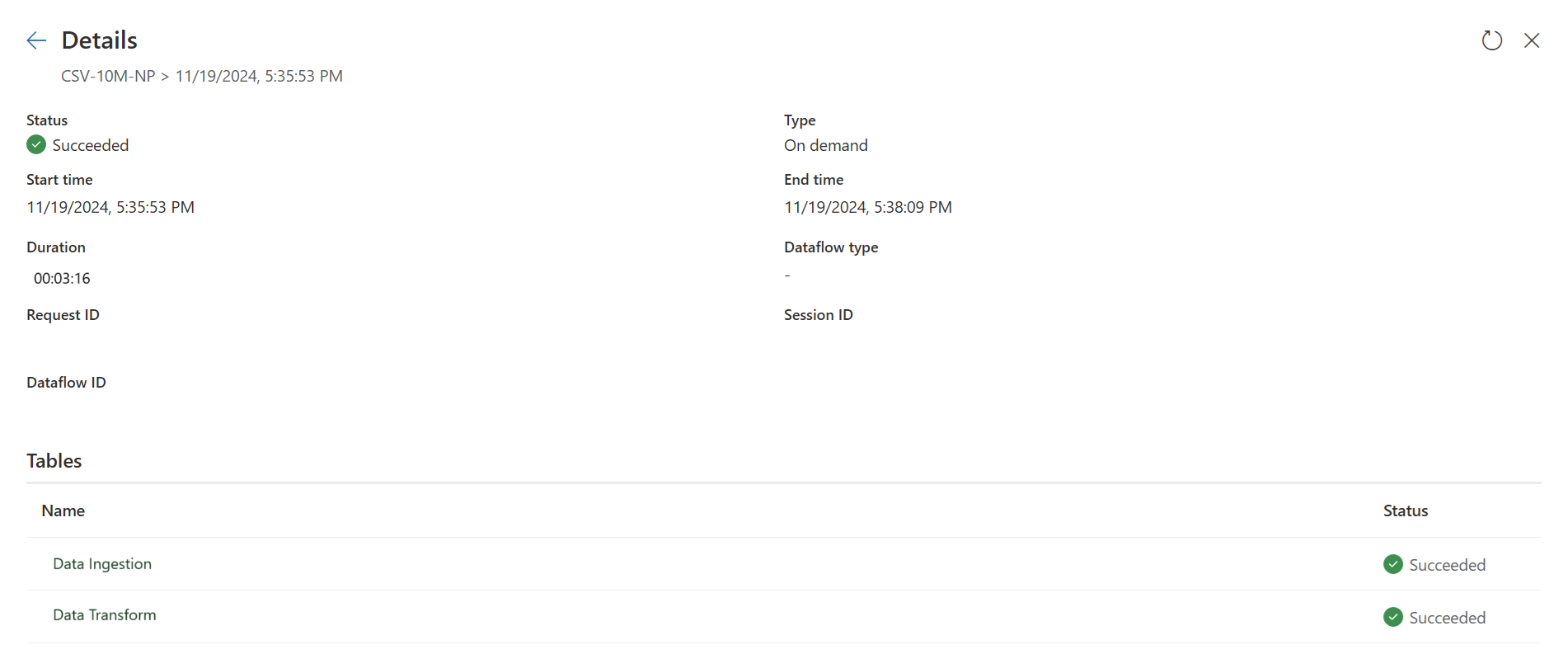
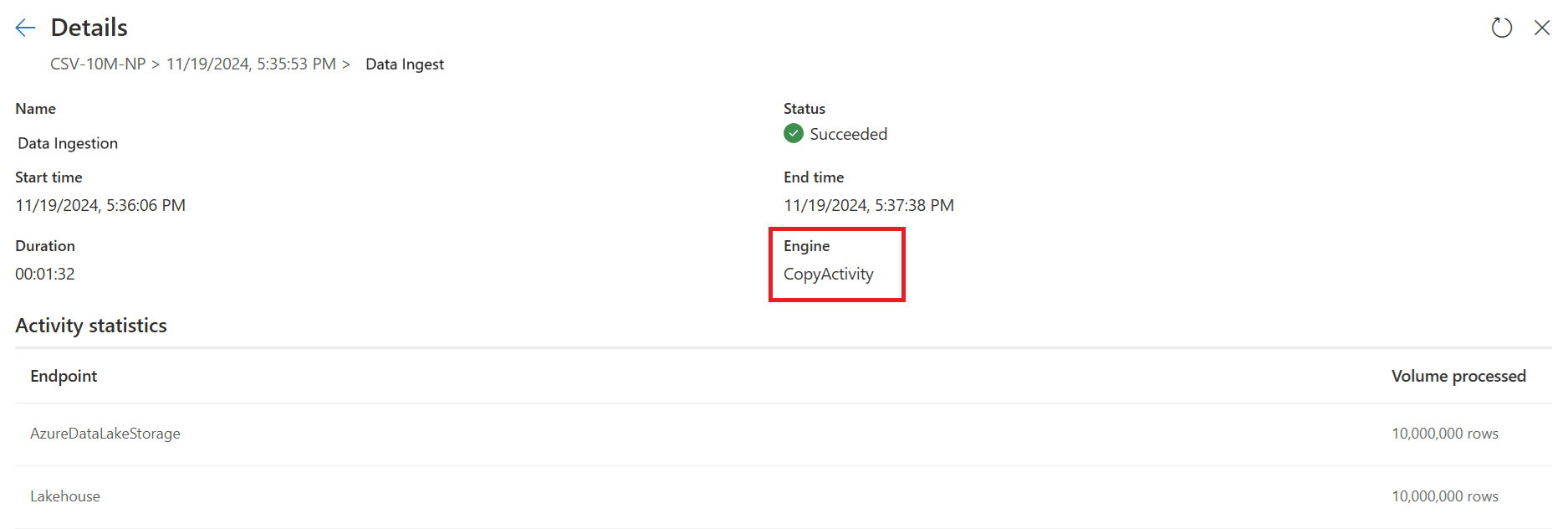
빠른 복사 표시기를 확인하여 빠른 복사를 사용하여 쿼리를 실행할 수 있는지 확인합니다. 이 경우 엔진 유형에 CopyActivity가 표시됩니다.

데이터 흐름을 게시합니다.
새로 고침이 완료된 후 빠른 복사본이 사용되었는지 확인합니다.

빠른 복사를 활용하기 위해 쿼리를 분할하는 방법
Dataflow Gen2를 사용하여 대량의 데이터를 처리할 때 최적의 성능을 위해 빠른 복사 기능을 사용하여 먼저 스테이징으로 데이터를 수집한 다음 SQL DW 컴퓨팅을 사용하여 대규모로 변환합니다. 이 방법은 엔드 투 엔드 성능을 크게 향상시킵니다.
이를 구현하기 위해 빠른 복사 표시기를 통해 쿼리를 스테이징에 대한 데이터 수집과 SQL DW 컴퓨팅을 사용한 대규모 변환의 두 부분으로 분할할 수 있습니다. 데이터를 수집하는 데 사용할 수 있는 빠른 복사에 쿼리 평가의 많은 부분을 푸시하는 것이 좋습니다. 빠른 복사 표시기에서 나머지 단계를 빠른 복사로 실행할 수 없다고 알려주면, 스테이징이 활성화된 상태에서 나머지 쿼리를 분할할 수 있습니다.
단계 진단 지표
| 지표 | 아이콘 | 묘사 |
|---|---|---|
| 이 단계는 빠른 복사를 사용하여 평가될 것입니다. | 
|
빠른 복사 표시기를 사용하면 이 단계까지의 쿼리가 빠른 복사를 지원한다는 것을 알 수 있습니다. |
| 이 단계는 빠른 복사에 의해 지원되지 않습니다. | 
|
빠른 복사 표시기는 이 단계가 빠른 복사를 지원하지 않음을 보여 줍니다. |
| 빠른 쿼리에서 지원되지 않는 단계가 하나 이상 쿼리에 포함되어 있습니다. | 
|
빠른 복사 표시기는 이 쿼리의 일부 단계가 빠른 복사를 지원하는 반면 다른 단계는 지원하지 않음을 보여 줍니다. 최적화하려면 노란색 단계(빠른 복사에서 잠재적으로 지원됨) 및 빨간색 단계(지원되지 않음)와 같은 쿼리를 분할합니다. |
단계별 지침
Dataflow Gen2에서 데이터 변환 논리를 완료한 후 빠른 복사 표시기가 각 단계를 평가하여 더 나은 성능을 위해 빠른 복사를 활용할 수 있는 단계 수를 결정합니다.
아래 예제에서 마지막 단계는 Group By 단계가 빠른 복사에서 지원되지 않음을 나타내는 빨간색으로 표시됩니다. 그러나 노란색을 표시하는 이전의 모든 단계는 빠른 복사에서 지원될 수 있습니다.
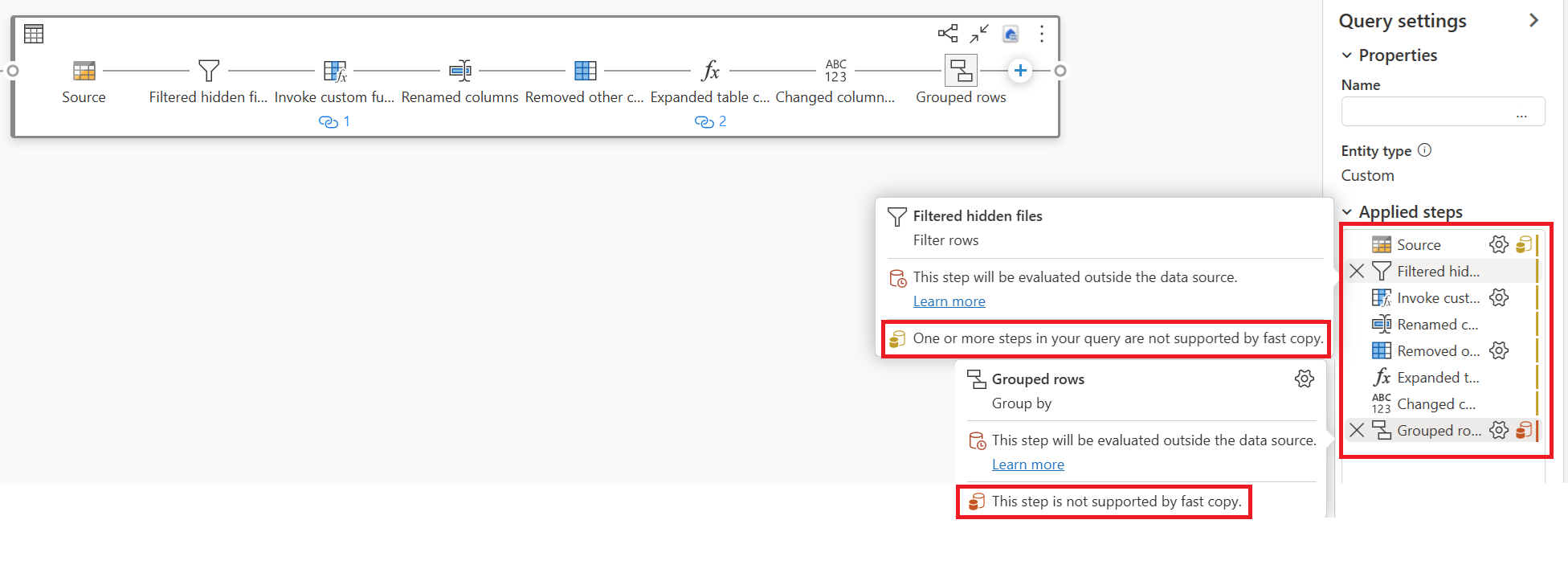
현재 Dataflow Gen2를 직접 게시하고 실행할 경우, 아래 그림처럼 데이터를 로드할 때 빠른 복사 엔진을 사용하지 않습니다.
빠른 복사를 사용하지 않은 상태의 결과를 보여주는 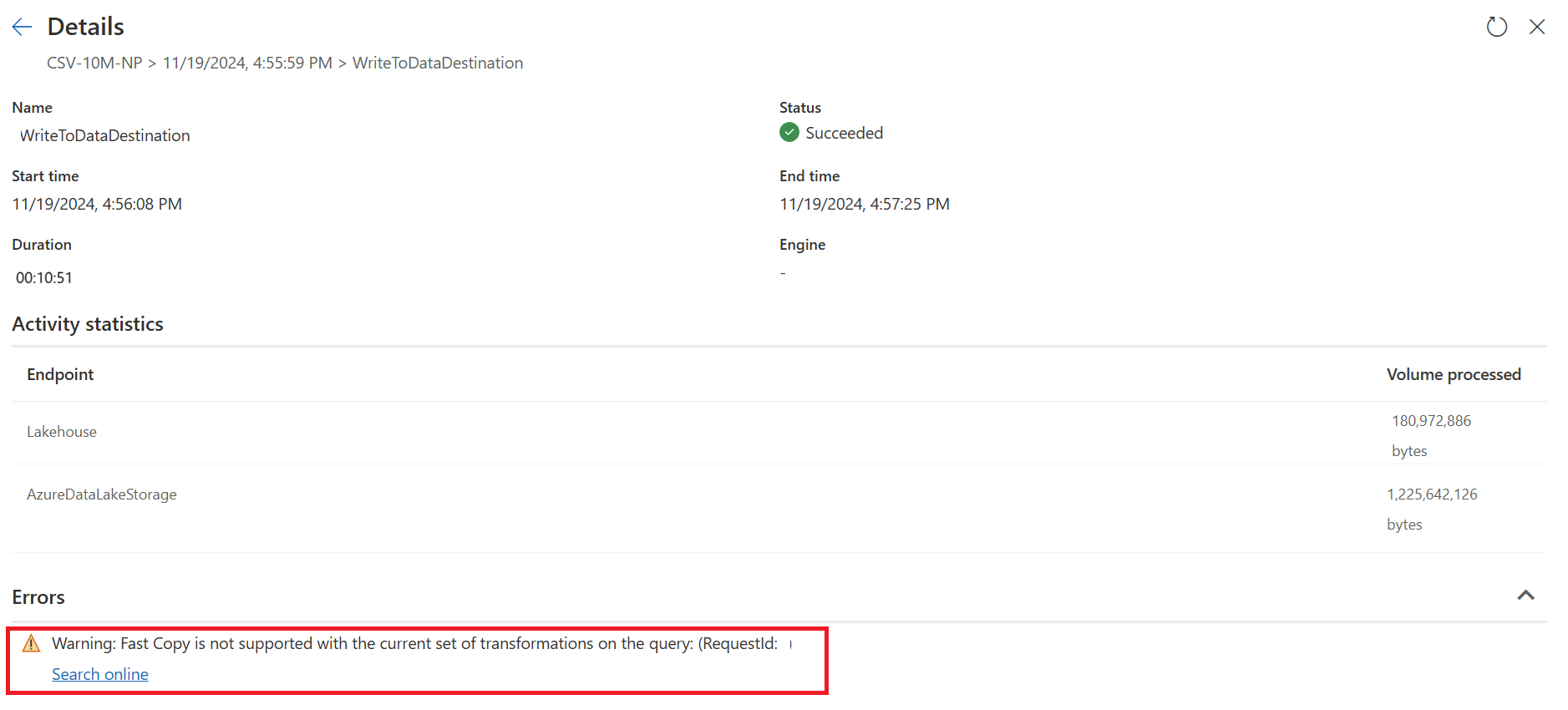
빠른 복사 엔진을 사용하고 Dataflow Gen2의 성능을 향상시키려면 다음과 같이 쿼리를 스테이징에 대한 데이터 수집 및 SQL DW 컴퓨팅을 사용한 대규모 변환의 두 부분으로 분할할 수 있습니다.
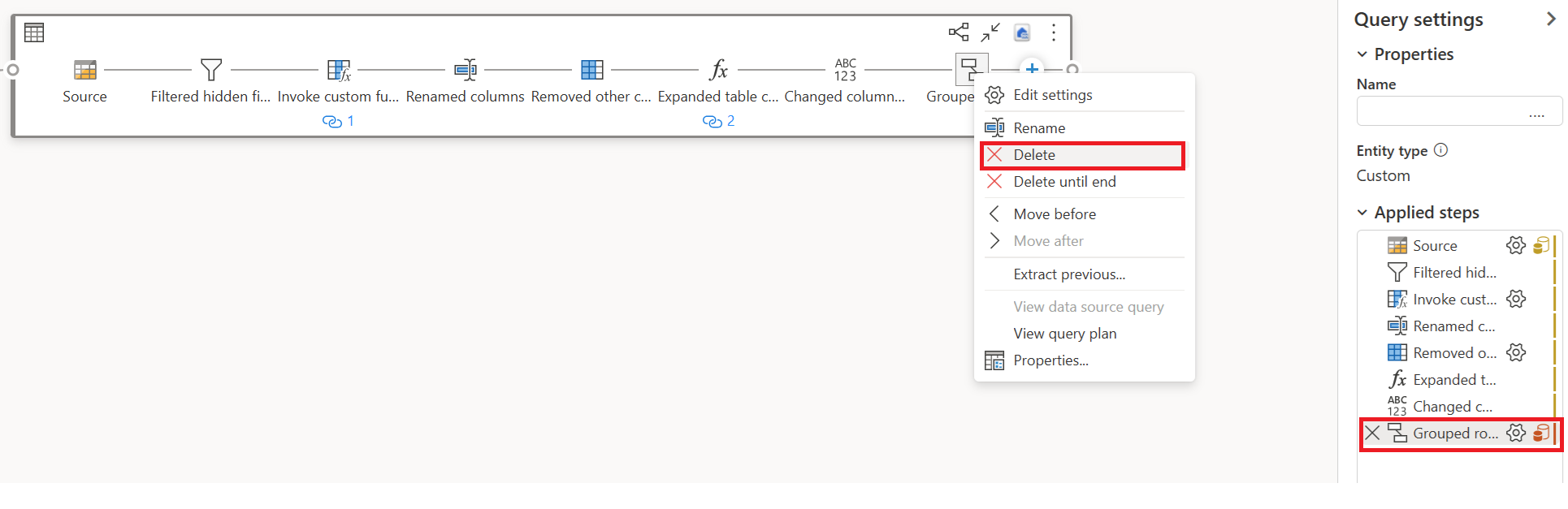
대상(정의된 경우)과 함께 빠른 복사에서 지원되지 않는 변환(빨간색 표시)을 제거합니다.
이제 빠른 복사 표시기가 나머지 단계에 대해 녹색으로 표시됩니다. 즉, 첫 번째 쿼리가 빠른 복사를 활용하여 성능을 높일 수 있습니다.
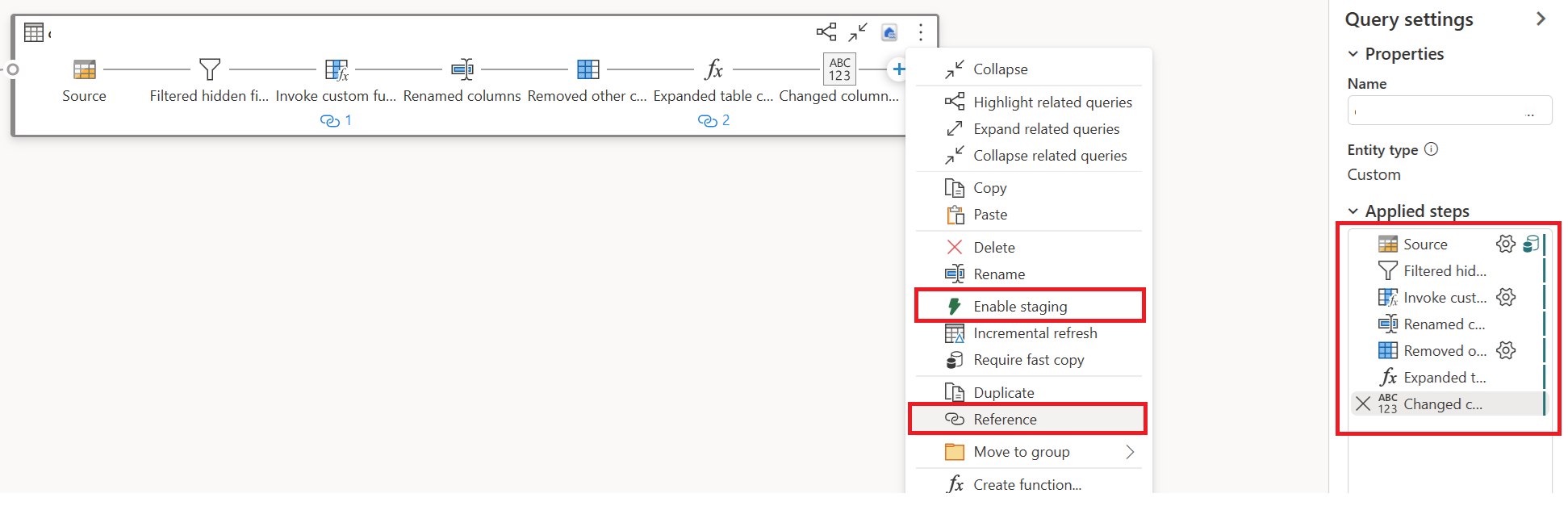
첫 번째 쿼리에 대한 작업을 선택한 다음, 스테이징 및 참조 사용을 활성화(Enable Staging and Reference)합니다.
참조된 새 쿼리에서 "Group By" 변환 및 대상(해당하는 경우)을 읽었습니다.
데이터 흐름 Gen2를 배포하고 업데이트합니다. 이제 Dataflow Gen2에 두 개의 쿼리가 표시되고 전체 기간이 크게 줄어듭니다.
첫 번째 쿼리는 Fast Copy를 사용하여 데이터를 스테이징에 적재합니다.
두 번째 쿼리는 SQL DW 컴퓨팅을 사용하여 대규모 변환을 수행합니다.
첫 번째 쿼리:
두 번째 쿼리는 다음과 같습니다.
알려진 제한 사항
- 빠른 복사를 지원하려면 온-프레미스 데이터 게이트웨이 버전 3000.214.2 이상이 필요합니다.
- VNet 게이트웨이는 지원되지 않습니다.
- Lakehouse의 기존 테이블에 데이터를 쓰는 것은 지원되지 않습니다.
- 고정 스키마는 지원되지 않습니다.