Azure Databricks와 OneLake 통합
이 시나리오에서는 Azure Databricks를 통해 OneLake에 연결하는 방법을 보여 줍니다. 이 자습서를 완료하면 Azure Databricks 작업 영역에서 Microsoft Fabric 레이크하우스를 읽고 쓸 수 있습니다.
필수 조건
연결하려면 다음 항목이 있어야 합니다.
- Fabric 작업 영역 및 레이크하우스
- 프리미엄 Azure Databricks 작업 영역 프리미엄 Azure Databricks 작업 영역만 이 시나리오에 필요한 Microsoft Entra 자격 증명 통과를 지원합니다.
Databricks 작업 영역 설정
Azure Databricks 작업 영역을 열고 만들기>클러스터를 선택합니다.
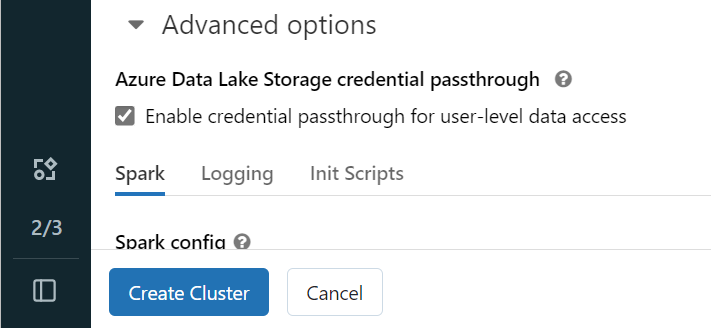
Microsoft Entra ID를 사용하여 OneLake에 인증하려면 고급 옵션의 클러스터에서 ADLS(Azure Data Lake Storage) 자격 증명 통과를 사용하도록 설정해야 합니다.
참고 항목
서비스 주체를 사용하여 Databricks를 OneLake에 연결할 수도 있습니다. 서비스 주체를 사용하여 Azure Databricks 인증에 대한 자세한 내용은 서비스 주체 관리를 참조하세요.
기본 설정 매개 변수를 사용하여 클러스터를 만듭니다. Databricks 클러스터 만들기에 대한 자세한 내용은 클러스터 구성 - Azure Databricks를 참조하세요.
Notebook을 열고 새로 만든 클러스터에 연결합니다.
Notebook 작성
Fabric 레이크하우스로 이동하여 ABFS(Azure Blob Filesystem) 경로를 레이크하우스에 복사합니다. 속성 창에서 찾을 수 있습니다.
참고 항목
Azure Databricks는 ADLS Gen2 및 OneLake에 읽고 쓸 때 ABFS(Azure Blob Filesystem) 드라이버만 지원합니다.
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/Databricks Notebook에 레이크하우스 경로를 저장합니다. 이 레이크하우스는 나중에 처리된 데이터를 작성하는 위치입니다.
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Databricks 공용 데이터 세트에서 데이터 프레임으로 데이터를 로드합니다. Fabric의 다른 위치에서 파일을 읽거나 이미 소유하고 있는 다른 ADLS Gen2 계정에서 파일을 선택할 수도 있습니다.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")데이터를 필터링, 변환 또는 준비합니다. 이 시나리오에서는 더 빠른 로드를 위해 데이터 세트를 트리밍하거나 다른 데이터 세트와 조인하거나 특정 결과로 필터링할 수 있습니다.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)OneLake 경로를 사용하여 필터링된 데이터 프레임을 Fabric 레이크하우스에 씁니다.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)새로 로드된 파일을 읽어 데이터가 성공적으로 작성되었는지 테스트합니다.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
축하합니다. 이제 Azure Databricks를 사용하여 Fabric에서 데이터를 읽고 쓸 수 있습니다.