다변량 변칙 검색
실시간 인텔리전스에서 다변량 변칙 검색에 대한 일반적인 내용은 Microsoft Fabric의 다변량 변칙 검색 - 개요를 참조하세요. 이 자습서에서는 샘플 데이터를 사용하여 Python Notebook의 Spark 엔진을 사용하여 다변량 변칙 검색 모델을 학습합니다. 그런 다음 Eventhouse 엔진을 사용하여 학습된 모델을 새 데이터에 적용하여 변칙을 예측합니다. 처음 몇 단계에서는 환경을 설정하고, 다음 단계에서는 모델을 학습하고 변칙을 예측합니다.
필수 조건
- Microsoft Fabric 지원 용량 작업 영역
- 작업 영역에서 관리자, 기여자 또는 구성원 역할. 환경과 같은 항목을 만들려면 이 권한 수준이 필요합니다.
- 데이터베이스가 있는 작업 영역의 Eventhouse.
- GitHub 리포지토리에서 샘플 데이터를 다운로드합니다.
- GitHub 리포지토리에서 Notebook을 다운로드합니다.
1부 - OneLake 가용성 사용
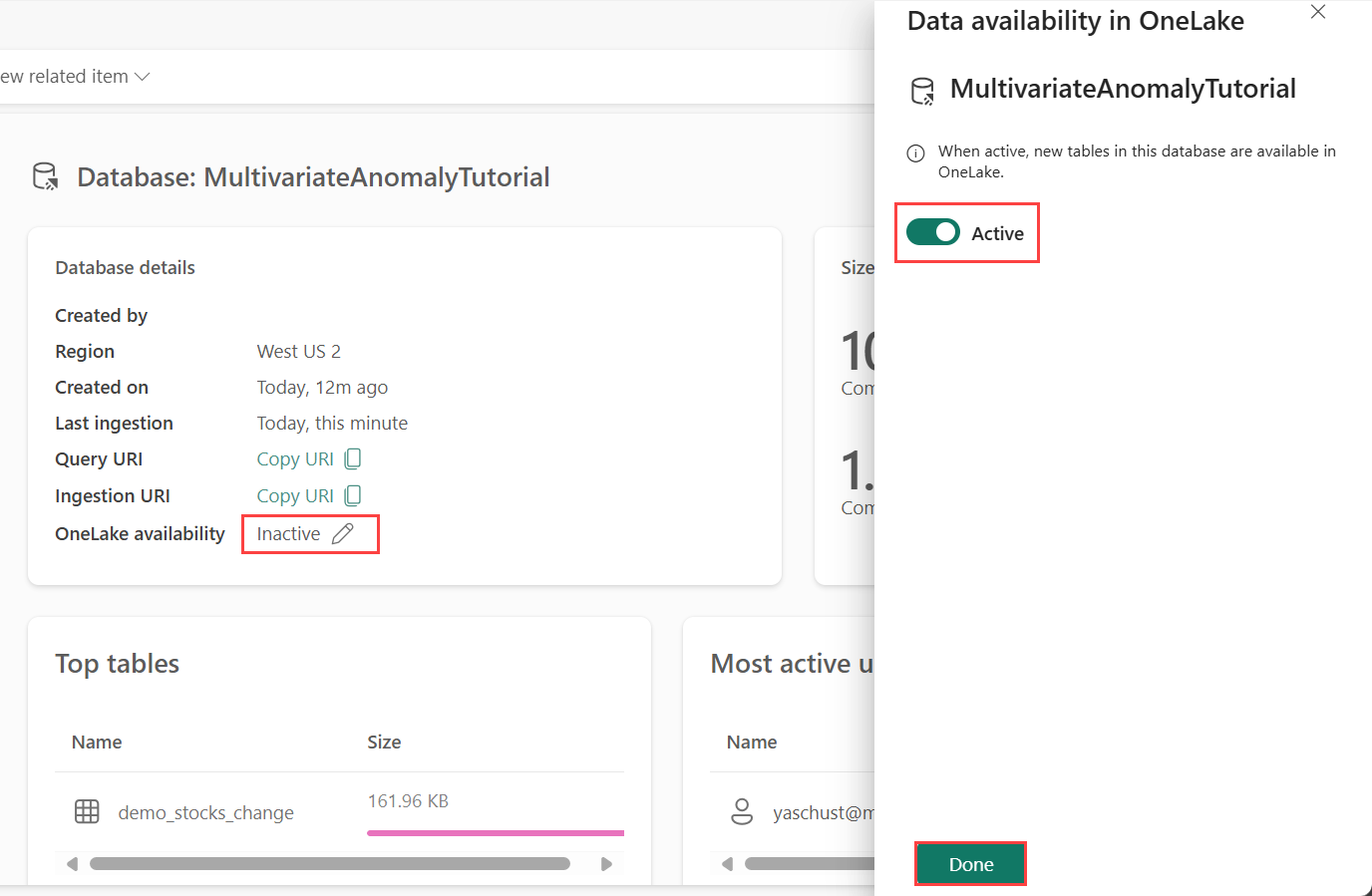
Eventhouse에서 데이터를 가져오기 전에 OneLake 가용성을 사용해야 합니다. 이 단계 수집한 데이터를 OneLake에서 사용할 수 있도록 하기 때문에 중요합니다. 이후 단계에서는 Spark Notebook으로부터 이 동일한 데이터에 액세스하여 모델을 학습합니다.
실시간 인텔리전스에서 작업 영역 홈 페이지로 이동합니다.
이전 섹션에서 만든 Eventhouse를 선택합니다. 데이터를 저장할 데이터베이스를 선택합니다.
데이터베이스 세부 정보 타일에서 OneLake 가용성 옆에 있는 연필 아이콘을 선택합니다.
오른쪽 창에서 버튼을 활성으로 전환합니다.
완료를 선택합니다.
2부 - KQL Python 플러그 인 사용
이 단계에서는 Eventhouse에서 Python 플러그 인을 사용합니다. 이 단계는 KQL 쿼리 세트에서 예측 변칙 Python 코드를 실행하는 데 필요합니다. time-series-anomaly-detector 패키지를 포함하는 올바른 패키지를 선택하는 것이 중요합니다.
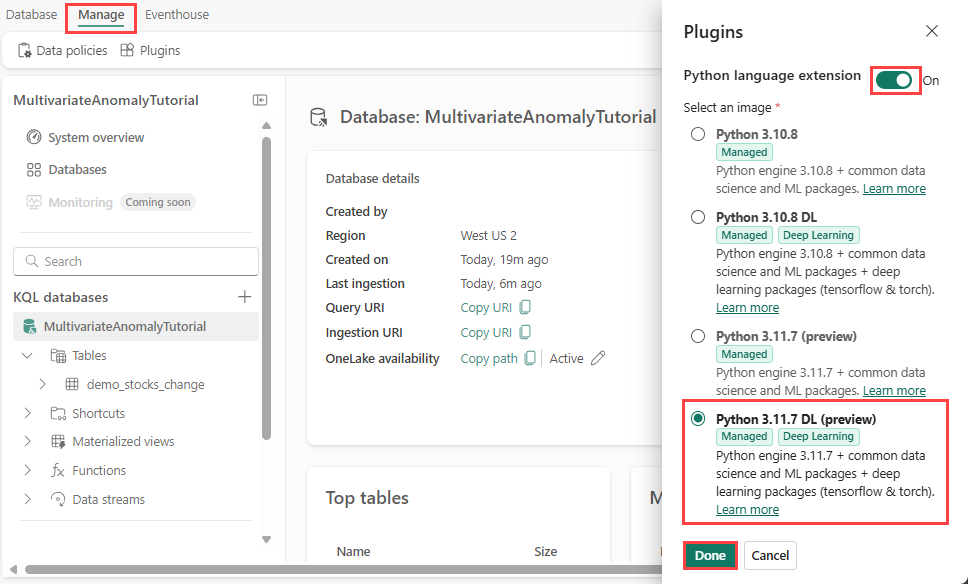
Eventhouse 화면에서 데이터베이스를 선택하고 리본에서 관리>플러그 인을 선택합니다.
플러그 인 창에서 Python 언어 확장을 켜기로 전환합니다.
Python 3.11.7 DL(미리 보기)을 선택합니다.
완료를 선택합니다.
3부 - Spark 환경 만들기
이 단계에서는 Spark 엔진을 사용하여 다변량 변칙 검색 모델을 학습하는 Python Notebook을 실행하도록 Spark 환경을 만듭니다. 환경을 만드는 방법에 대한 자세한 내용은 환경 만들기 및 관리를 참조하세요.
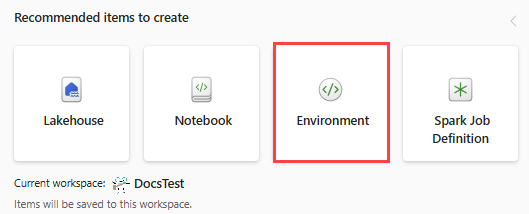
환경 전환기에서 데이터 엔지니어링을 선택합니다. 이미 데이터 엔지니어링 환경에 있는 경우 홈으로 이동합니다.
만들 권장 항목에서 환경을 선택하고 환경의 이름 MVAD_ENV 입력합니다.
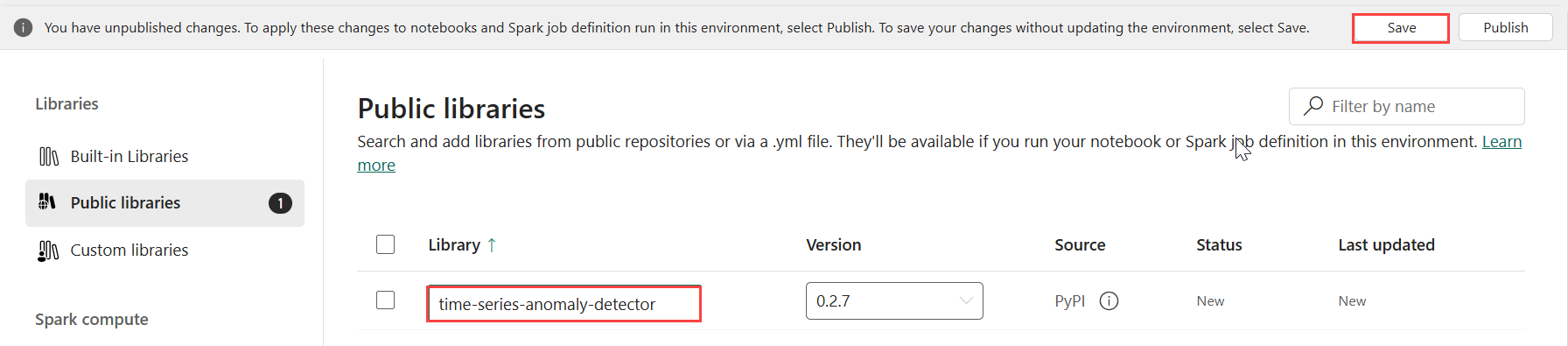
라이브러리에서 공용 라이브러리를 선택합니다.
PyPI에서 추가를 선택합니다.
검색 상자에 time-series-anomaly-detector를 입력합니다. 버전은 자동으로 최신 버전으로 채워집니다. 이 자습서는 Kusto Python 3.11.7 DL에 포함된 버전인 버전 0.2.7을 사용하여 만들어졌습니다.
저장을 선택합니다.
환경에서 홈 탭을 선택합니다.
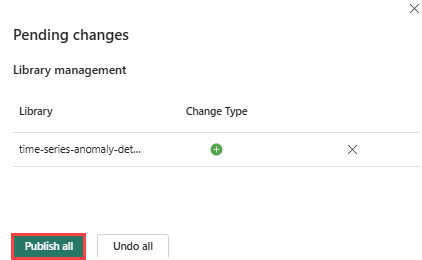
리본에서 게시 아이콘을 선택합니다.

모두 게시를 선택합니다. 이 단계를 완료하는 데 몇 분 정도 걸릴 수 있습니다.
4부 - Eventhouse로 데이터 가져오기
데이터를 저장하려는 KQL 데이터베이스에 커서를 댑니다. 추가 메뉴 [...]>데이터 가져오기>로컬 파일을 선택합니다.
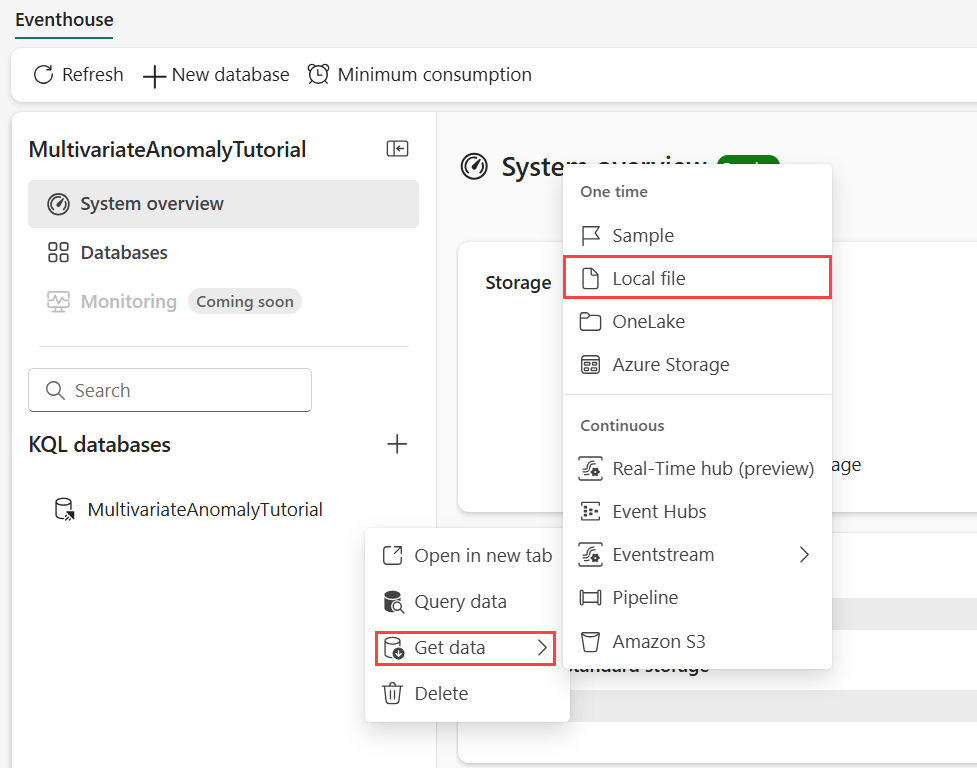
+ 새 테이블을 선택하고 테이블 이름을 demo_stocks_change로 입력합니다.
데이터 업로드 대화 상자에서 파일 찾아보기를 선택하고 전제 조건에서 다운로드한 샘플 데이터 파일을 업로드합니다.
다음을 선택합니다.
데이터 검사 섹션에서 첫 번째 행은 열 머리글을 켜기로 전환합니다.
마침을 선택합니다.
데이터가 업로드되면 닫기를 선택합니다.
5부 - 테이블에 OneLake 경로 복사
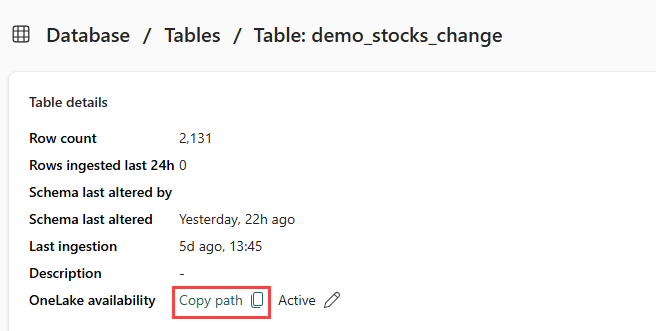
demo_stocks_change 테이블을 선택해야 합니다. 테이블 세부 정보 타일에서 경로 복사를 선택하여 OneLake 경로를 클립보드에 복사합니다. 이 복사한 텍스트를 이후 단계에서 사용할 텍스트 편집기 어딘가에 저장합니다.
6부 - Notebook 준비
환경 전환기에서 개발 및 작업 영역을 선택합니다.
가져오기, 전자 필기장, 이 컴퓨터에서 선택합니다.
업로드를 선택하고 필수 조건에서 다운로드한 Notebook을 선택합니다.
전자 필기장이 업로드되면 작업 영역에서 전자 필기장을 찾아서 열 수 있습니다.
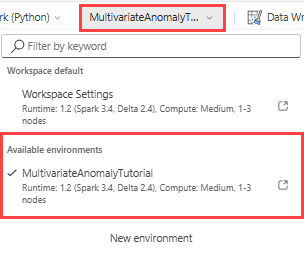
상단 리본에서 작업 영역 기본값 드롭다운을 선택하고 이전 단계에서 만든 환경을 선택합니다.
7부 - Notebook 실행
표준 패키지를 가져옵니다.
import numpy as np import pandas as pdSpark는 OneLake 스토리지에 안전하게 연결하기 위해 ABFSS URI가 필요하므로, 다음 단계에서는 OneLake URI를 ABFSS URI로 변환하도록 이 함수를 정의합니다.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uri5부 - 테이블에 OneLake URI 복사에서 복사한 OneLake URI를 입력하여 demo_stocks_change 테이블을 pandas 데이터 프레임으로 로드합니다.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]다음 셀을 실행하여 학습 및 예측 데이터 프레임을 준비합니다.
참고 항목
실제 예측은 9부 - Predict-anomalies-in-the-kql-queryset에서 Eventhouse에 의해 데이터에서 실행됩니다. 프로덕션 시나리오에서 데이터를 Eventhouse로 스트리밍하는 경우 새 스트리밍 데이터에 대한 예측이 수행됩니다. 자습서의 목적에 따라 데이터 세트는 학습 및 예측을 위해 날짜별로 두 섹션으로 분할됩니다. 기록 데이터 및 새 스트리밍 데이터를 시뮬레이션하기 위해서입니다.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')셀을 실행하여 모델을 학습하고 Fabric MLflow 모델 레지스트리에 저장합니다.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )# Extract the registered model path to be used for prediction using Kusto Python sandbox mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)마지막 셀 출력에서 모델 URI를 복사합니다. 나중에 이후 단계에서 사용합니다.
8부 - KQL 쿼리 세트 설정
일반적인 정보는 KQL 쿼리 세트 만들기를 참조하세요.
- 환경 전환기에서 실시간 인텔리전스를 선택합니다.
- 작업 영역을 선택합니다.
- +새 항목>KQL 쿼리 세트를 선택합니다. 이름름, MultivariateAnomalyDetectionTutorial을 입력합니다.
- 만들기를 실행합니다.
- OneLake 데이터 허브 창에서 데이터를 저장한 KQL 데이터베이스를 선택합니다.
- 연결을 선택합니다.
9부 - KQL 쿼리 세트에서 변칙 예측
다음 '.create-or-alter 함수' 쿼리를 복사하여 붙여넣고 실행하여
predict_fabric_mvad_fl()저장된 함수를 정의합니다..create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }다음 예측 쿼리를 복사하여 붙여넣습니다.
- 7단계 끝에서 복사한 출력 모델 URI를 바꿉니다.
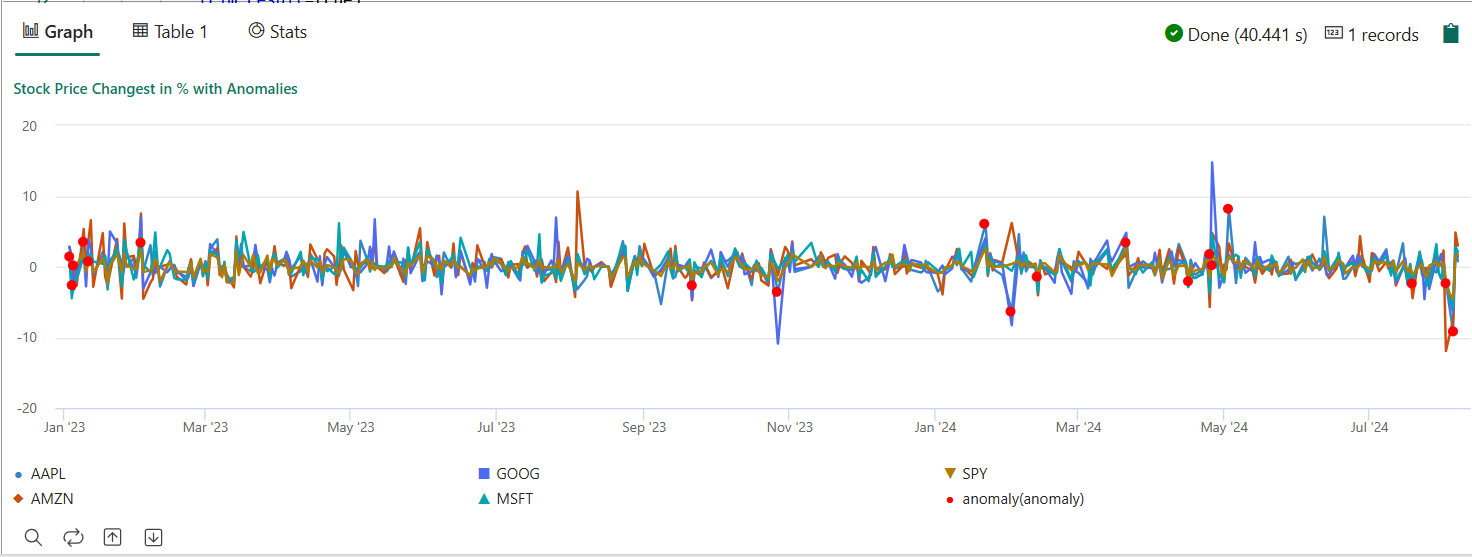
- 쿼리를 실행합니다. 학습된 모델을 기반으로 5개 주식에 대한 다변량 변칙을 검색하고 결과를 다음과 같이
anomalychart렌더링합니다. 변칙 지점은 다변량 변칙을 나타내도(즉, 특정 날짜에 5개 주식의 공동 변경에 대한 변칙) 첫 번째 주식(AAPL)에 렌더링됩니다.
let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
결과 변칙 차트는 다음 이미지와 비슷합니다.
리소스 정리
자습서를 마치면 다른 비용이 발생하지 않도록 만든 리소스를 삭제할 수 있습니다. 리소스를 삭제하려면 다음 단계를 수행합니다.
- 작업 영역 홈 페이지로 이동합니다.
- 이 자습서에서 만든 환경을 삭제합니다.
- 이 자습서에서 만든 Notebook을 삭제합니다.
- 이 자습서에 사용된 Eventhouse 또는 데이터베이스를 삭제합니다.
- 이 자습서에서 만든 KQL 쿼리 세트를 삭제합니다.