dbscan_fl()
이 함수 dbscan_fl() 는 DBSCAN 알고리즘을 사용하여 데이터 세트를 클러스터화하는 UDF(사용자 정의 함수)입니다.
필수 조건
- 클러스터에서 Python 플러그 인을 사용하도록 설정해야 합니다. 이 작업은 함수에 사용되는 인라인 Python에 필요합니다.
- 데이터베이스에서 Python 플러그 인을 사용하도록 설정해야 합니다. 이 작업은 함수에 사용되는 인라인 Python에 필요합니다.
구문
T | invoke dbscan_fl(기능, cluster_col, epsilon, min_samples, 메트릭 metric_params, )
구문 규칙에 대해 자세히 알아봅니다.
매개 변수
| 이름 | Type | 필수 | 설명 |
|---|---|---|---|
| features | dynamic |
✔️ | 클러스터링에 사용할 기능 열의 이름을 포함하는 배열입니다. |
| cluster_col | string |
✔️ | 각 레코드에 대한 출력 클러스터 ID를 저장할 열의 이름입니다. |
| epsilon | real |
✔️ | 인접 항목으로 간주될 두 샘플 사이의 최대 거리입니다. |
| min_samples | int |
핵심 지점으로 간주될 지점에 대한 이웃의 샘플 수입니다. | |
| 메트릭 | string |
점 사이의 거리를 계산할 때 사용할 메트릭입니다. | |
| metric_params | dynamic |
메트릭 함수에 대한 추가 키워드 인수입니다. |
함수 정의
다음과 같이 해당 코드를 쿼리 정의 함수로 포함하거나 데이터베이스에 저장된 함수로 만들어 함수를 정의할 수 있습니다.
다음 let 문을 사용하여 함수를 정의합니다. 사용 권한이 필요 없습니다.
Important
let 문은 자체적으로 실행할 수 없습니다. 그 뒤에 테이블 형식 식 문이 있어야 합니다. 작업 예제를 실행하려면 예제kmeans_fl()를 참조하세요.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
예시
다음 예제에서는 호출 연산자를 사용하여 함수를 실행합니다.
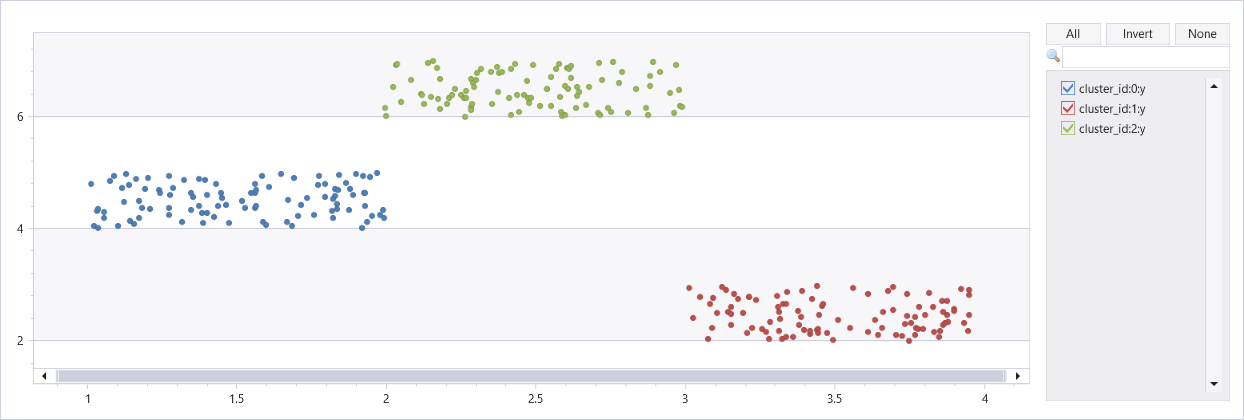
세 개의 클러스터를 사용하여 인공 데이터 세트 클러스터링
쿼리 정의 함수를 사용하려면 포함된 함수 정의 후에 호출합니다.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| extend cluster_id=int(null)
| invoke dbscan_fl(pack_array("x", "y"), "cluster_id", epsilon=0.6, min_samples=4, metric_params=dynamic({'p':2}))
| render scatterchart with(series=cluster_id)