kmeans_dynamic_fl()
이 함수 kmeans_dynamic_fl() 는 k-평균 알고리즘을 사용하여 데이터 세트를 클러스터화하는 UDF(사용자 정의 함수)입니다. 이 함수는 여러 스칼라 열이 아닌 단일 숫자 배열 열에서 제공하는 기능만 kmeans_fl()와 비슷합니다.
필수 조건
- 클러스터에서 Python 플러그 인을 사용하도록 설정해야 합니다. 이 작업은 함수에 사용되는 인라인 Python에 필요합니다.
- 데이터베이스에서 Python 플러그 인을 사용하도록 설정해야 합니다. 이 작업은 함수에 사용되는 인라인 Python에 필요합니다.
구문
T | invoke kmeans_dynamic_fl(k, features_col, cluster_col)
구문 규칙에 대해 자세히 알아봅니다.
매개 변수
| 이름 | Type | 필수 | 설명 |
|---|---|---|---|
| k | int |
✔️ | 클러스터 수입니다. |
| features_col | string |
✔️ | 클러스터링에 사용할 기능의 숫자 배열을 포함하는 열의 이름입니다. |
| cluster_col | string |
✔️ | 각 레코드에 대한 출력 클러스터 ID를 저장할 열의 이름입니다. |
함수 정의
다음과 같이 해당 코드를 쿼리 정의 함수로 포함하거나 데이터베이스에 저장된 함수로 만들어 함수를 정의할 수 있습니다.
다음 let 문을 사용하여 함수를 정의합니다. 사용 권한이 필요 없습니다.
Important
let 문은 자체적으로 실행할 수 없습니다. 그 뒤에 테이블 형식 식 문이 있어야 합니다. 작업 예제를 실행하려면 예제kmeans_fl()를 참조하세요.
let kmeans_dynamic_fl=(tbl:(*),k:int, features_col:string, cluster_col:string)
{
let kwargs = bag_pack('k', k, 'features_col', features_col, 'cluster_col', cluster_col);
let code = ```if 1:
from sklearn.cluster import KMeans
k = kargs["k"]
features_col = kargs["features_col"]
cluster_col = kargs["cluster_col"]
df1 = df[features_col].apply(np.array)
matrix = np.vstack(df1.values)
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(matrix)
result = df
result[cluster_col] = kmeans.labels_
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
예시
다음 예제에서는 호출 연산자를 사용하여 함수를 실행합니다.
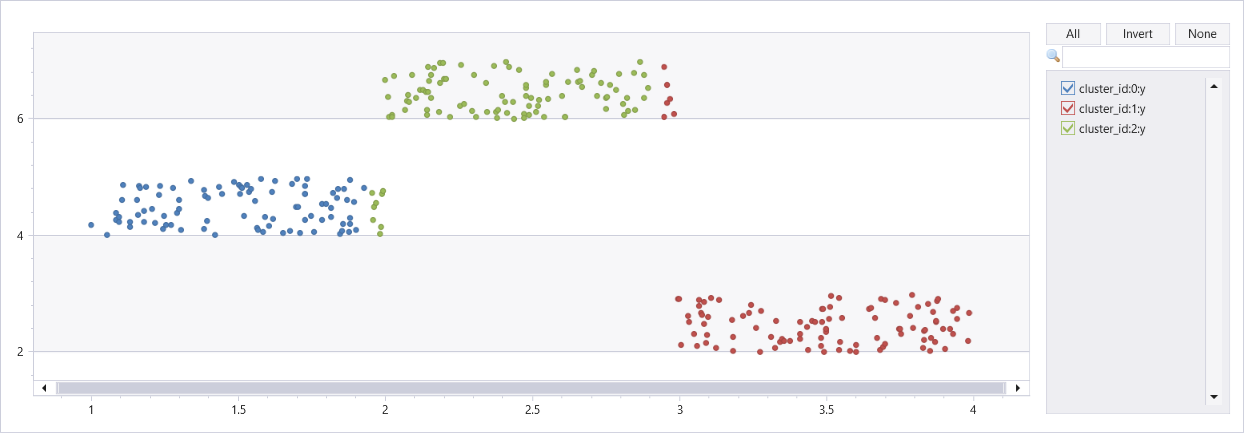
세 개의 클러스터를 사용하여 인공 데이터 세트 클러스터링
쿼리 정의 함수를 사용하려면 포함된 함수 정의 후에 호출합니다.
let kmeans_dynamic_fl=(tbl:(*),k:int, features_col:string, cluster_col:string)
{
let kwargs = bag_pack('k', k, 'features_col', features_col, 'cluster_col', cluster_col);
let code = ```if 1:
from sklearn.cluster import KMeans
k = kargs["k"]
features_col = kargs["features_col"]
cluster_col = kargs["cluster_col"]
df1 = df[features_col].apply(np.array)
matrix = np.vstack(df1.values)
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(matrix)
result = df
result[cluster_col] = kmeans.labels_
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| project Features=pack_array(x, y), cluster_id=int(null)
| invoke kmeans_dynamic_fl(3, "Features", "cluster_id")
| extend x=toreal(Features[0]), y=toreal(Features[1])
| render scatterchart with(series=cluster_id)