series_fit_lowess_fl()
적용 대상: ✅Microsoft Fabric✅Azure Data Explorer
이 함수 series_fit_lowess_fl() 는 계열에 LOWESS 회귀를 적용하는 UDF(사용자 정의 함수)입니다. 이 함수는 여러 계열(동적 숫자 배열)이 있는 테이블을 사용하고 원래 계열의 부드러운 버전인 LOWESS 곡선을 생성합니다.
필수 조건
- 클러스터에서 Python 플러그 인을 사용하도록 설정해야 합니다. 이 작업은 함수에 사용되는 인라인 Python에 필요합니다.
- 데이터베이스에서 Python 플러그 인을 사용하도록 설정해야 합니다. 이 작업은 함수에 사용되는 인라인 Python에 필요합니다.
구문
T | invoke series_fit_lowess_fl(, y_series y_fit_series, [ fit_size ], [ x_series ], [ x_istime ])
구문 규칙에 대해 자세히 알아봅니다.
매개 변수
| 이름 | Type | 필수 | 설명 |
|---|---|---|---|
| y_series | string |
✔️ | 종속 변수를 포함하는 입력 테이블 열의 이름입니다. 이 열은 맞출 계열입니다. |
| y_fit_series | string |
✔️ | 맞춤 계열을 저장할 열의 이름입니다. |
| fit_size | int |
각 지점에 대해 로컬 회귀는 해당 fit_size 가장 가까운 지점에 적용됩니다. 기본값은 5입니다. | |
| x_series | string |
독립 변수, 즉 x 또는 시간 축을 포함하는 열의 이름입니다. 이 매개 변수는 선택 사항이며 간격이 고르지 않은 계열에만 필요합니다. x는 균등하게 간격이 있는 계열의 회귀에 중복되므로 기본값은 빈 문자열입니다. | |
| x_istime | bool |
이 부울 매개 변수는 x_series 지정되고 datetime의 벡터인 경우에만 필요합니다. 기본값은 false입니다. |
함수 정의
다음과 같이 해당 코드를 쿼리 정의 함수로 포함하거나 데이터베이스에 저장된 함수로 만들어 함수를 정의할 수 있습니다.
다음 let 문을 사용하여 함수를 정의합니다. 사용 권한이 필요 없습니다.
Important
let 문은 자체적으로 실행할 수 없습니다. 그 뒤에 테이블 형식 식 문이 있어야 합니다. 작업 예제 series_fit_lowess_fl()를 실행하려면 예제를 참조 하세요.
let series_fit_lowess_fl=(tbl:(*), y_series:string, y_fit_series:string, fit_size:int=5, x_series:string='', x_istime:bool=False)
{
let kwargs = bag_pack('y_series', y_series, 'y_fit_series', y_fit_series, 'fit_size', fit_size, 'x_series', x_series, 'x_istime', x_istime);
let code = ```if 1:
y_series = kargs["y_series"]
y_fit_series = kargs["y_fit_series"]
fit_size = kargs["fit_size"]
x_series = kargs["x_series"]
x_istime = kargs["x_istime"]
import statsmodels.api as sm
def lowess_fit(ts_row, x_col, y_col, fsize):
y = ts_row[y_col]
fraction = fsize/len(y)
if x_col == "": # If there is no x column creates sequential range [1, len(y)]
x = np.arange(len(y)) + 1
else: # if x column exists check whether its a time column. If so, normalize it to the [1, len(y)] range, else take it as is.
if x_istime:
x = pd.to_numeric(pd.to_datetime(ts_row[x_col]))
x = x - x.min()
x = x / x.max()
x = x * (len(x) - 1) + 1
else:
x = ts_row[x_col]
lowess = sm.nonparametric.lowess
z = lowess(y, x, return_sorted=False, frac=fraction)
return list(z)
result = df
result[y_fit_series] = df.apply(lowess_fit, axis=1, args=(x_series, y_series, fit_size))
```;
tbl
| evaluate python(typeof(*), code, kwargs)
};
// Write your query to use the function here.
예제
다음 예제에서는 호출 연산자를 사용하여 함수를 실행합니다.
정규 시계열의 LOWESS 회귀
쿼리 정의 함수를 사용하려면 포함된 함수 정의 후에 호출합니다.
let series_fit_lowess_fl=(tbl:(*), y_series:string, y_fit_series:string, fit_size:int=5, x_series:string='', x_istime:bool=False)
{
let kwargs = bag_pack('y_series', y_series, 'y_fit_series', y_fit_series, 'fit_size', fit_size, 'x_series', x_series, 'x_istime', x_istime);
let code = ```if 1:
y_series = kargs["y_series"]
y_fit_series = kargs["y_fit_series"]
fit_size = kargs["fit_size"]
x_series = kargs["x_series"]
x_istime = kargs["x_istime"]
import statsmodels.api as sm
def lowess_fit(ts_row, x_col, y_col, fsize):
y = ts_row[y_col]
fraction = fsize/len(y)
if x_col == "": # If there is no x column creates sequential range [1, len(y)]
x = np.arange(len(y)) + 1
else: # if x column exists check whether its a time column. If so, normalize it to the [1, len(y)] range, else take it as is.
if x_istime:
x = pd.to_numeric(pd.to_datetime(ts_row[x_col]))
x = x - x.min()
x = x / x.max()
x = x * (len(x) - 1) + 1
else:
x = ts_row[x_col]
lowess = sm.nonparametric.lowess
z = lowess(y, x, return_sorted=False, frac=fraction)
return list(z)
result = df
result[y_fit_series] = df.apply(lowess_fit, axis=1, args=(x_series, y_series, fit_size))
```;
tbl
| evaluate python(typeof(*), code, kwargs)
};
//
// Apply 9 points LOWESS regression on regular time series
//
let max_t = datetime(2016-09-03);
demo_make_series1
| make-series num=count() on TimeStamp from max_t-1d to max_t step 5m by OsVer
| extend fnum = dynamic(null)
| invoke series_fit_lowess_fl('num', 'fnum', 9)
| render timechart
출력
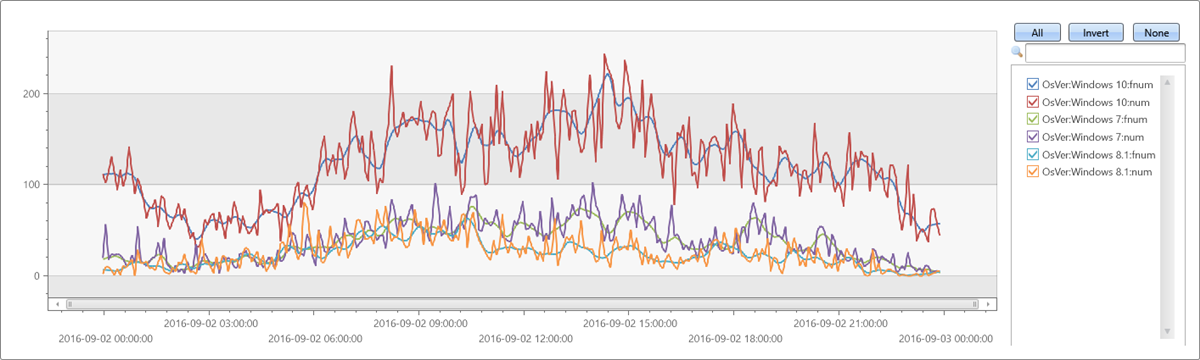
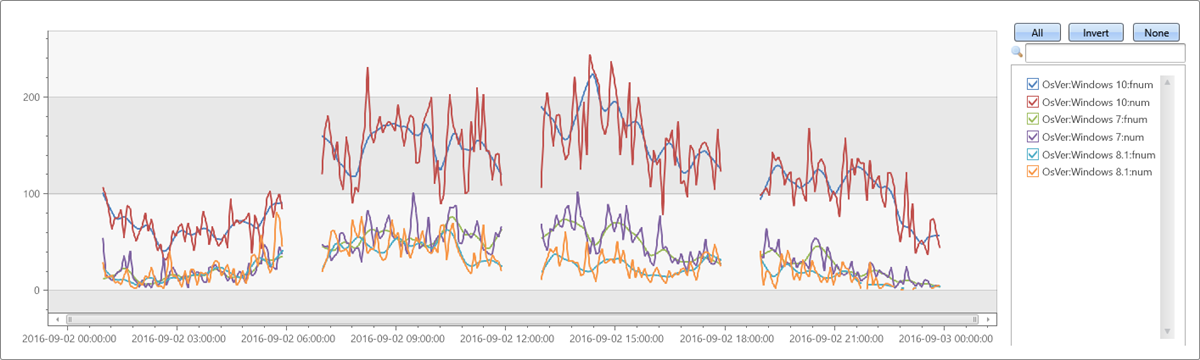
불규칙한 시계열 테스트
쿼리 정의 함수를 사용하려면 포함된 함수 정의 후에 호출합니다.
let series_fit_lowess_fl=(tbl:(*), y_series:string, y_fit_series:string, fit_size:int=5, x_series:string='', x_istime:bool=False)
{
let kwargs = bag_pack('y_series', y_series, 'y_fit_series', y_fit_series, 'fit_size', fit_size, 'x_series', x_series, 'x_istime', x_istime);
let code = ```if 1:
y_series = kargs["y_series"]
y_fit_series = kargs["y_fit_series"]
fit_size = kargs["fit_size"]
x_series = kargs["x_series"]
x_istime = kargs["x_istime"]
import statsmodels.api as sm
def lowess_fit(ts_row, x_col, y_col, fsize):
y = ts_row[y_col]
fraction = fsize/len(y)
if x_col == "": # If there is no x column creates sequential range [1, len(y)]
x = np.arange(len(y)) + 1
else: # if x column exists check whether its a time column. If so, normalize it to the [1, len(y)] range, else take it as is.
if x_istime:
x = pd.to_numeric(pd.to_datetime(ts_row[x_col]))
x = x - x.min()
x = x / x.max()
x = x * (len(x) - 1) + 1
else:
x = ts_row[x_col]
lowess = sm.nonparametric.lowess
z = lowess(y, x, return_sorted=False, frac=fraction)
return list(z)
result = df
result[y_fit_series] = df.apply(lowess_fit, axis=1, args=(x_series, y_series, fit_size))
```;
tbl
| evaluate python(typeof(*), code, kwargs)
};
let max_t = datetime(2016-09-03);
demo_make_series1
| where TimeStamp between ((max_t-1d)..max_t)
| summarize num=count() by bin(TimeStamp, 5m), OsVer
| order by TimeStamp asc
| where hourofday(TimeStamp) % 6 != 0 // delete every 6th hour to create irregular time series
| summarize TimeStamp=make_list(TimeStamp), num=make_list(num) by OsVer
| extend fnum = dynamic(null)
| invoke series_fit_lowess_fl('num', 'fnum', 9, 'TimeStamp', True)
| render timechart
출력
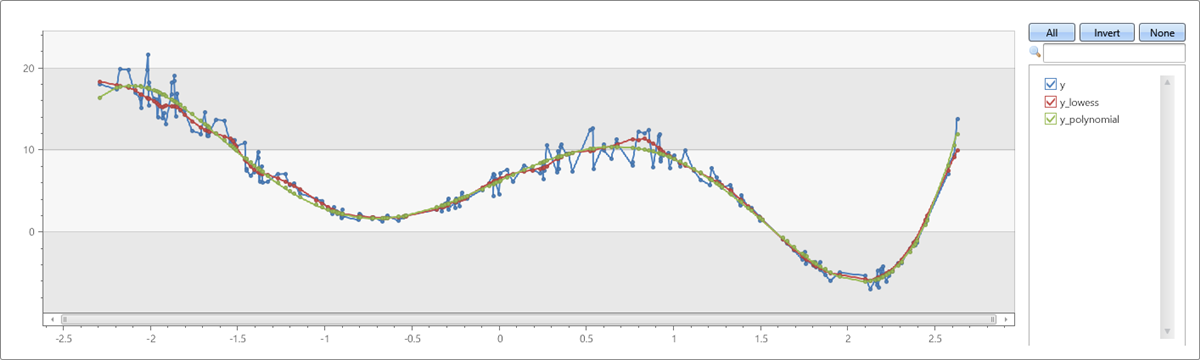
LOWESS와 다항식 맞춤 비교
쿼리 정의 함수를 사용하려면 포함된 함수 정의 후에 호출합니다.
let series_fit_lowess_fl=(tbl:(*), y_series:string, y_fit_series:string, fit_size:int=5, x_series:string='', x_istime:bool=False)
{
let kwargs = bag_pack('y_series', y_series, 'y_fit_series', y_fit_series, 'fit_size', fit_size, 'x_series', x_series, 'x_istime', x_istime);
let code = ```if 1:
y_series = kargs["y_series"]
y_fit_series = kargs["y_fit_series"]
fit_size = kargs["fit_size"]
x_series = kargs["x_series"]
x_istime = kargs["x_istime"]
import statsmodels.api as sm
def lowess_fit(ts_row, x_col, y_col, fsize):
y = ts_row[y_col]
fraction = fsize/len(y)
if x_col == "": # If there is no x column creates sequential range [1, len(y)]
x = np.arange(len(y)) + 1
else: # if x column exists check whether its a time column. If so, normalize it to the [1, len(y)] range, else take it as is.
if x_istime:
x = pd.to_numeric(pd.to_datetime(ts_row[x_col]))
x = x - x.min()
x = x / x.max()
x = x * (len(x) - 1) + 1
else:
x = ts_row[x_col]
lowess = sm.nonparametric.lowess
z = lowess(y, x, return_sorted=False, frac=fraction)
return list(z)
result = df
result[y_fit_series] = df.apply(lowess_fit, axis=1, args=(x_series, y_series, fit_size))
```;
tbl
| evaluate python(typeof(*), code, kwargs)
};
range x from 1 to 200 step 1
| project x = rand()*5 - 2.3
| extend y = pow(x, 5)-8*pow(x, 3)+10*x+6
| extend y = y + (rand() - 0.5)*0.5*y
| summarize x=make_list(x), y=make_list(y)
| extend y_lowess = dynamic(null)
| invoke series_fit_lowess_fl('y', 'y_lowess', 15, 'x')
| extend series_fit_poly(y, x, 5)
| project x, y, y_lowess, y_polynomial=series_fit_poly_y_poly_fit
| render linechart
출력