series_uv_anomalies_fl()
적용 대상: ✅Microsoft Fabric✅Azure Data Explorer
이 함수 series_uv_anomalies_fl() 는 Azure Cognitive Services의 일부인 일변량 변칙 검색 API를 호출하여 시계열에서 변칙을 검색하는 UDF(사용자 정의 함수)입니다. 이 함수는 숫자 동적 배열 및 필요한 변칙 검색 민감도 수준으로 제한된 시계열 집합을 허용합니다. 각 시계열은 필수 JSON 형식으로 변환되어 Anomaly Detector 서비스 엔드포인트에 게시됩니다. 서비스 응답에는 높음/낮음/모든 변칙의 동적 배열, 모델링된 기준 시계열, 표준 높음/낮은 경계(높음/낮은 경계 위 또는 아래 값이 변칙임) 및 검색된 계절성이 포함됩니다.
참고 항목
확장성이 높고 더 빠르게 실행되는 네이티브 함수 series_decompose_anomalies() 를 사용하는 것이 좋습니다.
필수 구성 요소
- Azure 구독 무료 Azure 계정을 만듭니다.
- 클러스터 및 데이터베이스 편집 권한 및 데이터를 사용하여 클러스터 및 데이터베이스 또는 KQL 데이터베이스를 만듭니다.
- 클러스터에서 Python 플러그 인을 사용하도록 설정해야 합니다. 이 작업은 함수에 사용되는 인라인 Python에 필요합니다.
- Anomaly Detector 리소스를 만들고 해당 키를 가져와서 서비스에 액세스합니다.
- 클러스터에서 http_request 플러그 인/http_request_post 플러그 인 을 사용하도록 설정하여 변칙 검색 서비스 엔드포인트에 액세스합니다.
- 변칙 검색 서비스 엔드포인트에 액세스하도록 형식
webapi에 대한 설명선 정책을 수정합니다.
다음 함수 예제에서는 URI 및 YOUR-KEY Ocp-Apim-Subscription-Key 헤더에서 Anomaly Detector 리소스 이름 및 키로 바꿉 YOUR-AD-RESOURCE-NAME 다.
구문
T | invoke series_uv_anomalies_fl( y_series [, 민감도 [, tsid]])
구문 규칙에 대해 자세히 알아봅니다.
매개 변수
| 이름 | Type | 필수 | 설명 |
|---|---|---|---|
| y_series | string |
✔️ | 변칙이 검색될 계열 값을 포함하는 입력 테이블 열의 이름입니다. |
| 민감 | 정수 | 변칙 검색 민감도를 지정하는 [0-100] 범위의 정수입니다. 0은 가장 중요한 검색이지만, 100은 예상 기준에서 작은 편차도 변칙으로 태그가 지정됨을 나타내는 가장 중요한 검색입니다. 기본값: 85 | |
| tsid | string |
시계열 ID를 포함하는 입력 테이블 열의 이름입니다. 단일 시계열을 분석할 때 생략할 수 있습니다. |
함수 정의
다음과 같이 해당 코드를 쿼리 정의 함수로 포함하거나 데이터베이스에 저장된 함수로 만들어 함수를 정의할 수 있습니다.
다음 let 문을 사용하여 함수를 정의합니다. 사용 권한이 필요 없습니다.
Important
let 문은 자체적으로 실행할 수 없습니다. 그 뒤에 테이블 형식 식 문이 있어야 합니다. 작업 예제 series_uv_anomalies_fl()를 실행하려면 예제를 참조 하세요.
let series_uv_anomalies_fl=(tbl:(*), y_series:string, sensitivity:int=85, tsid:string='_tsid')
{
let uri = 'https://YOUR-AD-RESOURCE-NAME.cognitiveservices.azure.com/anomalydetector/v1.0/timeseries/entire/detect';
let headers=dynamic({'Ocp-Apim-Subscription-Key': h'YOUR-KEY'});
let kwargs = bag_pack('y_series', y_series, 'sensitivity', sensitivity);
let code = ```if 1:
import json
y_series = kargs["y_series"]
sensitivity = kargs["sensitivity"]
json_str = []
for i in range(len(df)):
row = df.iloc[i, :]
ts = [{'value':row[y_series][j]} for j in range(len(row[y_series]))]
json_data = {'series': ts, "sensitivity":sensitivity} # auto-detect period, or we can force 'period': 84. We can also add 'maxAnomalyRatio':0.25 for maximum 25% anomalies
json_str = json_str + [json.dumps(json_data)]
result = df
result['json_str'] = json_str
```;
tbl
| evaluate python(typeof(*, json_str:string), code, kwargs)
| extend _tsid = column_ifexists(tsid, 1)
| partition by _tsid (
project json_str
| evaluate http_request_post(uri, headers, dynamic(null))
| project period=ResponseBody.period, baseline_ama=ResponseBody.expectedValues, ad_ama=series_add(0, ResponseBody.isAnomaly), pos_ad_ama=series_add(0, ResponseBody.isPositiveAnomaly)
, neg_ad_ama=series_add(0, ResponseBody.isNegativeAnomaly), upper_ama=series_add(ResponseBody.expectedValues, ResponseBody.upperMargins), lower_ama=series_subtract(ResponseBody.expectedValues, ResponseBody.lowerMargins)
| extend _tsid=toscalar(_tsid)
)
};
// Write your query to use the function here.
예제
다음 예제에서는 호출 연산자를 사용하여 함수를 실행합니다.
변칙 검색에 사용 series_uv_anomalies_fl()
쿼리 정의 함수를 사용하려면 포함된 함수 정의 후에 호출합니다.
let series_uv_anomalies_fl=(tbl:(*), y_series:string, sensitivity:int=85, tsid:string='_tsid')
{
let uri = 'https://YOUR-AD-RESOURCE-NAME.cognitiveservices.azure.com/anomalydetector/v1.0/timeseries/entire/detect';
let headers=dynamic({'Ocp-Apim-Subscription-Key': h'YOUR-KEY'});
let kwargs = bag_pack('y_series', y_series, 'sensitivity', sensitivity);
let code = ```if 1:
import json
y_series = kargs["y_series"]
sensitivity = kargs["sensitivity"]
json_str = []
for i in range(len(df)):
row = df.iloc[i, :]
ts = [{'value':row[y_series][j]} for j in range(len(row[y_series]))]
json_data = {'series': ts, "sensitivity":sensitivity} # auto-detect period, or we can force 'period': 84. We can also add 'maxAnomalyRatio':0.25 for maximum 25% anomalies
json_str = json_str + [json.dumps(json_data)]
result = df
result['json_str'] = json_str
```;
tbl
| evaluate python(typeof(*, json_str:string), code, kwargs)
| extend _tsid = column_ifexists(tsid, 1)
| partition by _tsid (
project json_str
| evaluate http_request_post(uri, headers, dynamic(null))
| project period=ResponseBody.period, baseline_ama=ResponseBody.expectedValues, ad_ama=series_add(0, ResponseBody.isAnomaly), pos_ad_ama=series_add(0, ResponseBody.isPositiveAnomaly)
, neg_ad_ama=series_add(0, ResponseBody.isNegativeAnomaly), upper_ama=series_add(ResponseBody.expectedValues, ResponseBody.upperMargins), lower_ama=series_subtract(ResponseBody.expectedValues, ResponseBody.lowerMargins)
| extend _tsid=toscalar(_tsid)
)
};
let etime=datetime(2017-03-02);
let stime=datetime(2017-01-01);
let dt=1h;
let ts = requests
| make-series value=avg(value) on timestamp from stime to etime step dt
| extend _tsid='TS1';
ts
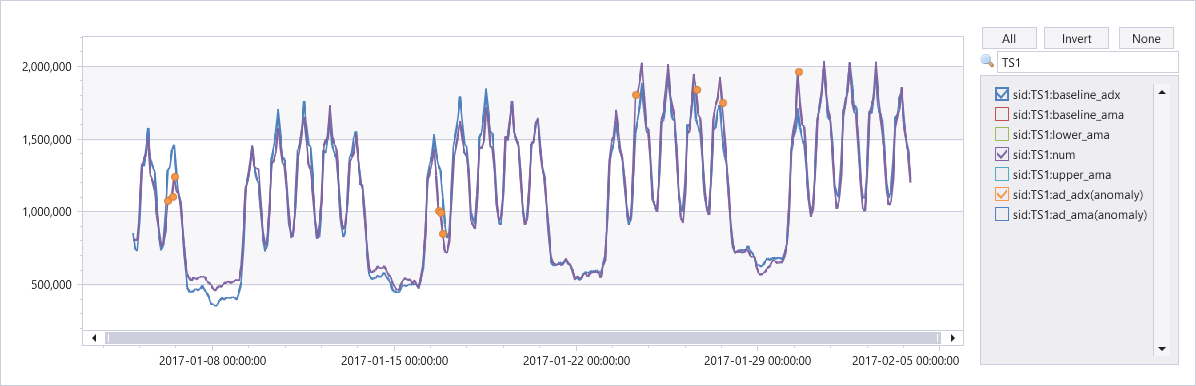
| invoke series_uv_anomalies_fl('value')
| lookup ts on _tsid
| render anomalychart with(xcolumn=timestamp, ycolumns=value, anomalycolumns=ad_ama)
출력
비교 series_uv_anomalies_fl() 및 네이티브 series_decompose_anomalies()
다음 예제에서는 단변량 변칙 검색 API를 네이티브 series_decompose_anomalies() 함수와 세 개의 시계열을 비교하고 해당 함수가 데이터베이스에 이미 정의되어 있다고 가정합니다 series_uv_anomalies_fl() .
쿼리 정의 함수를 사용하려면 포함된 함수 정의 후에 호출합니다.
let series_uv_anomalies_fl=(tbl:(*), y_series:string, sensitivity:int=85, tsid:string='_tsid')
{
let uri = 'https://YOUR-AD-RESOURCE-NAME.cognitiveservices.azure.com/anomalydetector/v1.0/timeseries/entire/detect';
let headers=dynamic({'Ocp-Apim-Subscription-Key': h'YOUR-KEY'});
let kwargs = bag_pack('y_series', y_series, 'sensitivity', sensitivity);
let code = ```if 1:
import json
y_series = kargs["y_series"]
sensitivity = kargs["sensitivity"]
json_str = []
for i in range(len(df)):
row = df.iloc[i, :]
ts = [{'value':row[y_series][j]} for j in range(len(row[y_series]))]
json_data = {'series': ts, "sensitivity":sensitivity} # auto-detect period, or we can force 'period': 84. We can also add 'maxAnomalyRatio':0.25 for maximum 25% anomalies
json_str = json_str + [json.dumps(json_data)]
result = df
result['json_str'] = json_str
```;
tbl
| evaluate python(typeof(*, json_str:string), code, kwargs)
| extend _tsid = column_ifexists(tsid, 1)
| partition by _tsid (
project json_str
| evaluate http_request_post(uri, headers, dynamic(null))
| project period=ResponseBody.period, baseline_ama=ResponseBody.expectedValues, ad_ama=series_add(0, ResponseBody.isAnomaly), pos_ad_ama=series_add(0, ResponseBody.isPositiveAnomaly)
, neg_ad_ama=series_add(0, ResponseBody.isNegativeAnomaly), upper_ama=series_add(ResponseBody.expectedValues, ResponseBody.upperMargins), lower_ama=series_subtract(ResponseBody.expectedValues, ResponseBody.lowerMargins)
| extend _tsid=toscalar(_tsid)
)
};
let ts = demo_make_series2
| summarize TimeStamp=make_list(TimeStamp), num=make_list(num) by sid;
ts
| invoke series_uv_anomalies_fl('num', 'sid', 90)
| join ts on $left._tsid == $right.sid
| project-away _tsid
| extend (ad_adx, score_adx, baseline_adx)=series_decompose_anomalies(num, 1.5, -1, 'linefit')
| project-reorder num, *
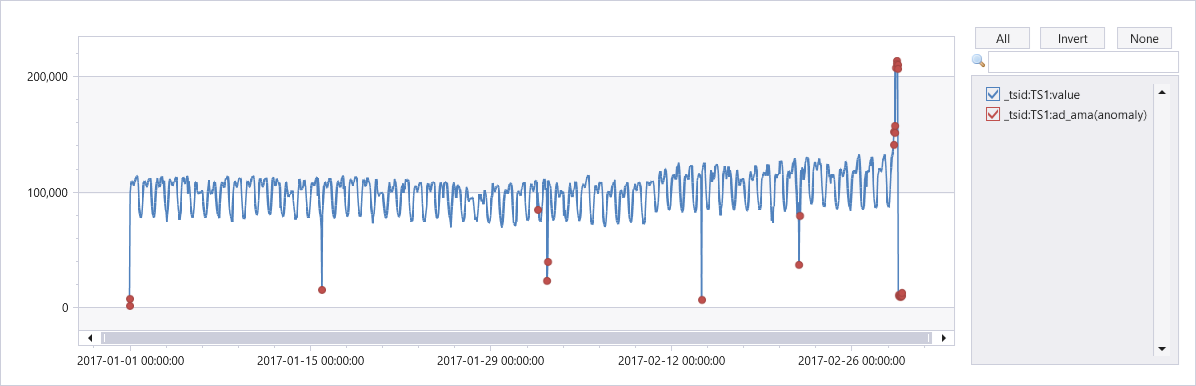
| render anomalychart with(series=sid, xcolumn=TimeStamp, ycolumns=num, baseline_adx, baseline_ama, lower_ama, upper_ama, anomalycolumns=ad_adx, ad_ama)
출력
다음 그래프는 TS1의 단변량 변칙 검색 API에서 검색된 변칙을 보여 줍니다. 차트 필터 상자에서 TS2 또는 TS3을 선택할 수도 있습니다.
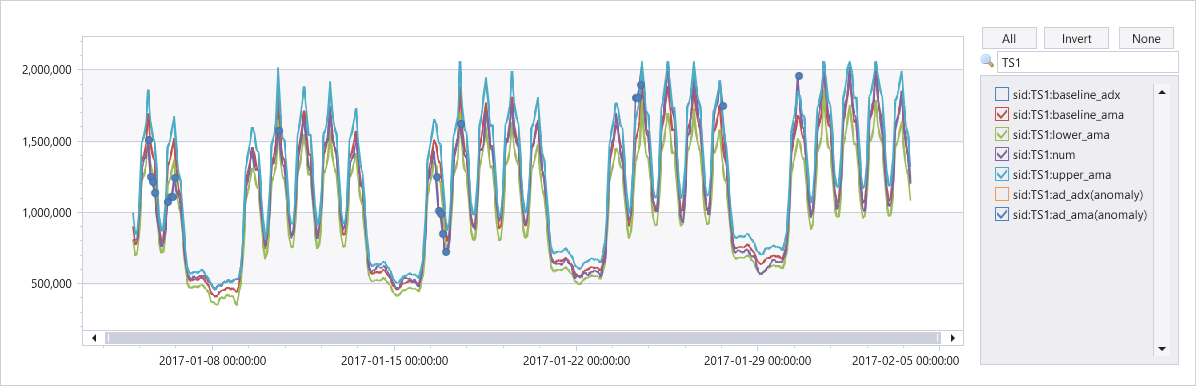
다음 그래프는 TS1의 네이티브 함수에서 검색된 변칙을 보여 줍니다.