Anomaly diagnosis for root cause analysis
Applies to: ✅ Microsoft Fabric ✅ Azure Data Explorer ✅ Azure Monitor ✅ Microsoft Sentinel
Kusto Query Language (KQL) has built-in anomaly detection and forecasting functions to check for anomalous behavior. Once such a pattern is detected, a Root Cause Analysis (RCA) can be run to mitigate or resolve the anomaly.
The diagnosis process is complex and lengthy, and done by domain experts. The process includes:
- Fetching and joining more data from different sources for the same time frame
- Looking for changes in the distribution of values on multiple dimensions
- Charting more variables
- Other techniques based on domain knowledge and intuition
Since these diagnosis scenarios are common, machine learning plugins are available to make the diagnosis phase easier, and shorten the duration of the RCA.
All three of the following Machine Learning plugins implement clustering algorithms: autocluster, basket, and diffpatterns. The autocluster and basket plugins cluster a single record set, and the diffpatterns plugin clusters the differences between two record sets.
Clustering a single record set
A common scenario includes a dataset selected by a specific criteria such as:
- Time window that shows anomalous behavior
- High temperature device readings
- Long duration commands
- Top spending users
You want a fast and easy way to find common patterns (segments) in the data. Patterns are a subset of the dataset whose records share the same values over multiple dimensions (categorical columns).
The following query builds and shows a time series of service exceptions over the period of a week, in ten-minute bins:
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")
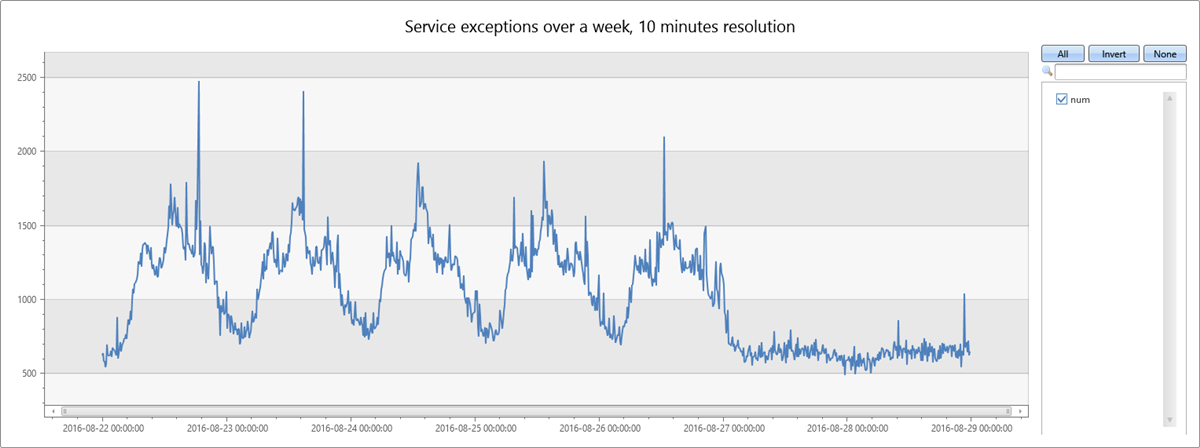
The service exception count correlates with the overall service traffic. You can clearly see the daily pattern for business days, Monday to Friday. There's a rise in service exception counts at mid-day, and drops in counts during the night. Flat low counts are visible over the weekend. Exception spikes can be detected using time series anomaly detection.
The second spike in the data occurs on Tuesday afternoon. The following query is used to further diagnose and verify whether it's a sharp spike. The query redraws the chart around the spike in a higher resolution of eight hours in one-minute bins. You can then study its borders.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")
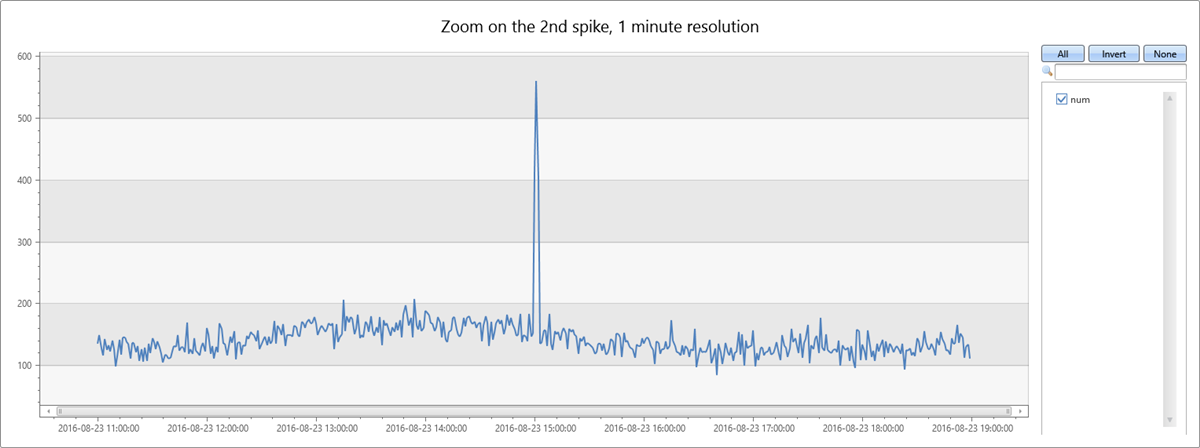
You see a narrow two-minute spike from 15:00 to 15:02. In the following query, count the exceptions in this two-minute window:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Count |
|---|
| 972 |
In the following query, sample 20 exceptions out of 972:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | Region | ScaleUnit | DeploymentId | Tracepoint | ServiceHost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Use autocluster() for single record set clustering
Even though there are less than a thousand exceptions, it's still hard to find common segments, since there are multiple values in each column. You can use the autocluster() plugin to instantly extract a short list of common segments and find the interesting clusters within the spike's two minutes, as seen in the following query:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| SegmentId | Count | Percent | Region | ScaleUnit | DeploymentId | ServiceHost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
You can see from the results above that the most dominant segment contains 65.74% of the total exception records and shares four dimensions. The next segment is much less common. It contains only 9.67% of the records, and shares three dimensions. The other segments are even less common.
Autocluster uses a proprietary algorithm for mining multiple dimensions and extracting interesting segments. "Interesting" means that each segment has significant coverage of both the records set and the features set. The segments are also diverged, meaning that each one is different from the others. One or more of these segments might be relevant for the RCA process. To minimize segment review and assessment, autocluster extracts only a small segment list.
Use basket() for single record set clustering
You can also use the basket() plugin as seen in the following query:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| SegmentId | Count | Percent | Region | ScaleUnit | DeploymentId | Tracepoint | ServiceHost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scus | ||||
| 9 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9.25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Basket implements the "Apriori" algorithm for item set mining. It extracts all segments whose coverage of the record set is above a threshold (default 5%). You can see that more segments were extracted with similar ones, such as segments 0, 1 or 2, 3.
Both plugins are powerful and easy to use. Their limitation is that they cluster a single record set in an unsupervised manner with no labels. It's unclear whether the extracted patterns characterize the selected record set, anomalous records, or the global record set.
Clustering the difference between two records sets
The diffpatterns() plugin overcomes the limitation of autocluster and basket. Diffpatterns takes two record sets and extracts the main segments that are different. One set usually contains the anomalous record set being investigated. One is analyzed by autocluster and basket. The other set contains the reference record set, the baseline.
In the following query, diffpatterns finds interesting clusters within the spike's two minutes, which are different from the clusters within the baseline. The baseline window is defined as the eight minutes before 15:00, when the spike started. You extend by a binary column (AB), and specify whether a specific record belongs to the baseline or to the anomalous set. Diffpatterns implements a supervised learning algorithm, where the two class labels were generated by the anomalous versus the baseline flag (AB).
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| SegmentId | CountA | CountB | PercentA | PercentB | PercentDiffAB | Region | ScaleUnit | DeploymentId | Tracepoint |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 | 65.74 | 1.7 | 64.04 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | scus | |||
| 2 | 92 | 356 | 9.47 | 28.9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25.81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
The most dominant segment is the same segment that was extracted by autocluster. Its coverage on the two-minute anomalous window is also 65.74%. However, its coverage on the eight-minute baseline window is only 1.7%. The difference is 64.04%. This difference seems to be related to the anomalous spike. To verify this assumption, the following query splits the original chart into the records that belong to this problematic segment, and records from the other segments.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
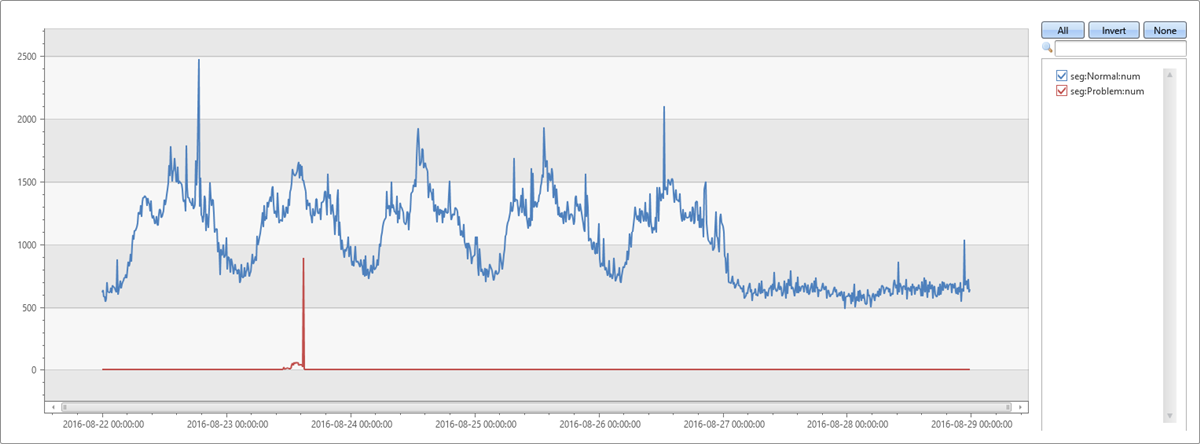
This chart allows us to see that the spike on Tuesday afternoon was because of exceptions from this specific segment, discovered by using the diffpatterns plugin.
Summary
The Machine Learning plugins are helpful for many scenarios. The autocluster and basket implement an unsupervised learning algorithm and are easy to use. Diffpatterns implements a supervised learning algorithm and, although more complex, it's more powerful for extracting differentiation segments for RCA.
These plugins are used interactively in ad-hoc scenarios and in automatic near real-time monitoring services. Time series anomaly detection is followed by a diagnosis process. The process is highly optimized to meet necessary performance standards.