Microsoft Syntex 모델 형식 개요
적용 대상: ✓ 모든 사용자 지정 모델 | ✓ 미리 빌드된 모든 모델
Microsoft Syntex 콘텐츠 이해는 문서 처리 모델에서 시작됩니다. 문서 처리 모델을 사용하면 SharePoint 문서 라이브러리에 업로드된 문서를 식별하고 분류한 다음 각 파일에서 필요한 정보를 추출할 수 있습니다.
SharePoint 문서 라이브러리에 적용하면 모델이 콘텐츠 형식과 연결되고 추출되는 정보를 저장할 열이 있습니다. 사용자가 만든 콘텐츠 형식은 SharePoint 콘텐츠 형식 갤러리에 저장됩니다. 기존 콘텐츠 유형을 사용하여 해당 스키마를 사용하도록 선택할 수도 있습니다.
Syntex는 사용자 지정 모델 및 미리 빌드된 모델을 사용합니다.
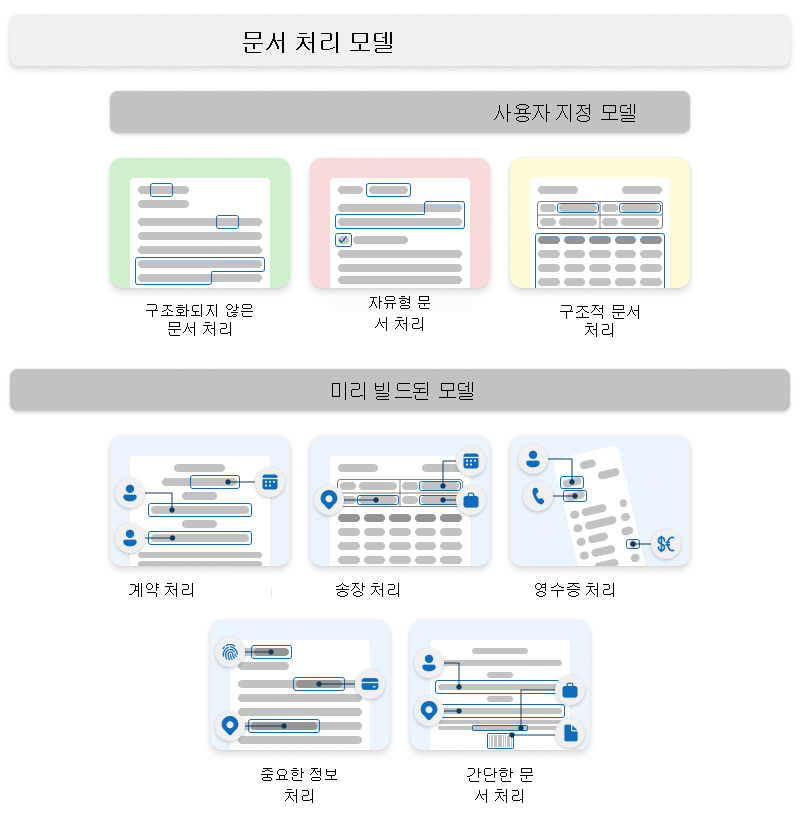
모델은 콘텐츠 센터에서 만든 엔터프라이즈 모델 또는 로컬 SharePoint 사이트에서 만든 로컬 모델일 수 있습니다.
사용자 지정 모델
선택하는 사용자 지정 모델의 형식은 사용하는 파일 형식, 파일의 형식 및 구조, 모델을 적용할 위치에 따라 달라집니다.
사용자 지정 모델은 다음과 같습니다.
사용자 지정 모델의 나란히 차이점을 보려면 사용자 지정 모델 비교를 참조하세요.
구조화되지 않은 문서 처리
구조화되지 않은 문서 처리 모델을 사용하여 문서를 자동으로 분류하고 해당 문서에서 정보를 추출합니다. 편지나 계약서와 같이 구조화 되지 않은 문서에 가장 적합합니다. 이러한 문서에는 구문 또는 패턴을 기반으로 식별할 수 있는 텍스트가 있어야 합니다. 식별 된 텍스트는 파일 형식(분류자)과 추출 하려는 대상(추출자)을 지정합니다.
예를 들어, 비정형 문서는 다양한 방법으로 작성할 수 있는 계약 갱신 서한이 될 수 있습니다. 그러나 "서비스 시작 날짜"라는 텍스트 문자열과 실제 날짜와 같은 정보가 각 계약 갱신 문서의 본문에 일관되게 존재합니다.
이 모델 형식은 가장 광범위한 파일 형식을 지원하고 40개 이상의 언어를 지원합니다.
구조화되지 않은 문서 처리 모델을 만들 때 는 단일 클래스 모델 옵션을 사용합니다.
자세한 내용은 비정형 문서 처리 개요를 참조하세요.
자유형 문서 처리
자유 형식 문서 처리 모델을 사용하여 문서의 아무 곳에나 정보가 표시될 수 있는 편지 및 계약과 같은 구조화되지 않은 자유형 문서에서 정보를 자동으로 추출합니다.
자유형 문서 처리 모델은 Microsoft Power Apps AI Builder 를 사용하여 Syntex 내에서 모델을 만들고 학습시킵니다.
참고
일부 지역에서는 자유 형식 문서 처리 모델을 아직 사용할 수 없습니다. 자세한 내용은 지역별 기능 가용성을 참조하세요.
organization 메일, 팩스 및 전자 메일과 같은 다양한 원본에서 대량으로 편지와 문서를 받기 때문에 이러한 문서를 처리하고 데이터베이스에 수동으로 입력하는 데 상당한 시간이 걸릴 수 있습니다. 이 모델은 AI를 사용하여 이러한 문서에서 텍스트 및 기타 정보를 추출하여 이 프로세스를 자동화합니다.
이 모델 유형은 문서 형식의 자동 분류가 필요하지 않고 40개 이상의 언어를 지원하는 경우 PDF 또는 이미지 파일의 문서에 가장 적합한 옵션입니다.
자유 형식 문서 처리 모델을 만들 때 자유형 추출 모델 옵션을 사용합니다.
자세한 내용은 구조화 및 자유형 문서 처리 개요를 참조하세요.
구조적 문서 처리
구조화된 문서 처리 모델을 사용하여 필드 및 테이블 값을 자동으로 식별합니다. 양식 및 청구서와 같은 구조화되거나 반구조화된 문서에 가장 적합합니다.
구조적 문서 처리 모델은 Microsoft Power Apps AI Builder 문서 처리(이전의 양식 처리)를 사용하여 Syntex 내에서 모델을 만들고 학습시킵니다.
이 모델 형식은 가장 광범위한 언어를 지원하며 예제 문서에서 양식의 레이아웃을 이해하도록 학습된 다음 유사한 위치에서 추출해야 하는 데이터를 찾는 방법을 알아봅니다. Forms 일반적으로 엔터티가 동일한 위치에 있는 보다 구조화된 레이아웃이 있습니다(예: 세금 양식의 사회 보장 번호).
구조적 문서 처리 모델을 만들 때 구조적 추출 모델 옵션을 사용합니다.
자세한 내용은 구조화 및 자유형 문서 처리 개요를 참조하세요.
사전 구축 모델
사용자 지정 모델을 빌드할 필요가 없는 경우 특정 구조화된 문서에 대해 이미 학습된 미리 빌드된 문서 처리 모델을 사용할 수 있습니다.
미리 빌드된 모델에는 다음이 포함됩니다.
미리 빌드된 모델은 문서의 문서 및 구조화된 정보를 인식하도록 미리 학습됩니다. 새 사용자 지정 모델을 처음부터 만드는 대신 기존 미리 학습된 모델을 반복하여 organization 요구에 맞는 특정 필드를 추가할 수 있습니다.
계약 처리
미리 빌드된 계약 처리 모델은 계약 문서에서 주요 정보를 분석하고 추출합니다. API는 다양한 형식으로 계약을 분석하고 클라이언트 또는 당사자 이름, 청구 주소, 관할권 및 만료 날짜와 같은 주요 계약 정보를 추출합니다.
계약 처리 모델에 대한 자세한 내용은 미리 빌드된 모델을 사용하여 계약에서 정보 추출을 참조하세요.
송장 처리
미리 빌드된 청구서 처리 모델은 판매 청구서에서 주요 정보를 분석하고 추출합니다. API는 다양한 형식으로 청구서를 분석하고 고객 이름, 청구 주소, 기한 및 기한과 같은 주요 청구서 정보를 추출합니다.
청구서 처리 모델에 대한 자세한 내용은 미리 빌드된 모델을 사용하여 청구서에서 정보 추출을 참조하세요.
영수증 처리
미리 빌드된 영수증 처리 모델은 판매 영수증에서 주요 정보를 분석하고 추출합니다. API는 인쇄 및 필기 영수증을 분석하고 가맹점 이름, 가맹점 전화 번호, 거래 날짜, 세금 및 거래 총계와 같은 주요 영수증 정보를 추출합니다.
영수증 처리 모델에 대한 자세한 내용은 미리 빌드된 모델을 사용하여 영수증에서 정보 추출을 참조하세요.
중요한 정보 처리
미리 빌드된 중요한 정보 처리 모델은 문서에서 주요 정보를 분석, 검색 및 추출합니다. API는 다양한 형식으로 계약을 분석하고 사회 보장 번호, 재무 계정 번호, 운전 면허증 식별 번호 및 기타 개인 정보와 같은 주요 중요한 정보를 추출합니다.
중요한 정보 처리 모델에 대한 자세한 내용은 미리 빌드된 모델을 사용하여 문서에서 중요한 정보 검색을 참조하세요.
간단한 문서 처리
미리 빌드된 간단한 문서 처리 모델은 기본 구조화된 문서에서 키-값 쌍, 선택 표시 및 명명된 엔터티를 추출하기 위한 유연하고 미리 학습된 솔루션을 제공합니다. 고정 스키마가 있는 미리 빌드된 다른 모델과 달리 이 모델은 다른 사용자가 놓칠 수 있는 키를 식별하여 사용자 지정 모델 레이블 지정 및 학습에 대한 유용한 대안을 제공할 수 있습니다. 이 모델은 바코드 및 언어 검색도 지원합니다.
간단한 문서 처리 모델에 대한 자세한 내용은 미리 빌드된 모델을 사용하여 문서에서 중요한 정보 검색을 참조하세요.