데이터 개인 정보 보호 방화벽의 백그라운드
참고 항목
현재 Power Platform 데이터 흐름에서는 개인 정보 수준을 사용할 수 없지만 제품 팀은 이 기능을 사용하도록 설정하기 위해 노력하고 있습니다.
파워 쿼리를 오랜 시간 동안 사용한 적이 있다면 경험해 볼 수 있습니다. 거기, 멀리 쿼리, 갑자기 온라인 검색의 양을 얻을 때, 쿼리 조정, 또는 키보드 bashing 해결할 수 없습니다. 다음과 같은 오류:
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
아니면 다음을 수행할 수도 있습니다.
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
이러한 Formula.Firewall 오류는 파워 쿼리의 데이터 개인 정보 보호 방화벽(방화벽이라고도 함)의 결과이며, 때로는 전 세계 데이터 분석가를 좌절시키는 것만 있을 수 있습니다. 믿거나 말거나, 그러나, 방화벽은 중요한 목적을 제공합니다. 이 문서에서는 작동 방식을 더 잘 이해하기 위해 내부적으로 살펴보겠습니다. 더 잘 이해하면 나중에 방화벽 오류를 더 잘 진단하고 수정할 수 있기를 바랍니다.
이것은 무엇인가요?
데이터 개인 정보 방화벽의 목적은 간단합니다. 파워 쿼리가 의도치 않게 원본 간에 데이터가 누출되지 않도록 하기 위해 존재합니다.
왜 이것이 필요합니까? 즉, SQL 값을 OData 피드에 전달하는 일부 M을 확실히 작성할 수 있습니다. 그러나 이것은 의도적인 데이터 유출일 것입니다. 매시업 저자는 (또는 적어도) 그들이이 일을하고 있다는 것을 알 것입니다. 그렇다면 의도하지 않은 데이터 유출에 대한 보호가 필요한 이유는 무엇일까요?
대답? 접는.
접는?
폴딩은 M의 식(예: 필터, 이름 바꾸기, 조인 등)을 원시 데이터 원본(예: SQL, OData 등)에 대한 작업으로 변환하는 것을 참조하는 용어입니다. 파워 쿼리 기능의 큰 부분은 PQ가 사용자가 해당 언어를 알 필요 없이 사용자가 사용자 인터페이스를 통해 수행하는 작업을 복잡한 SQL 또는 다른 백 엔드 데이터 원본 언어로 변환할 수 있다는 사실에서 비롯됩니다. 사용자는 일반적인 명령 집합을 사용하여 모든 데이터 원본을 변환할 수 있는 UI를 쉽게 사용할 수 있는 네이티브 데이터 원본 작업의 성능 이점을 얻을 수 있습니다.
접기의 일부로 PQ에서 지정된 매시업을 실행하는 가장 효율적인 방법은 한 원본에서 데이터를 가져와서 다른 원본으로 전달하는 것이라고 판단할 수 있습니다. 예를 들어 작은 CSV 파일을 거대한 SQL 테이블에 조인하는 경우 PQ가 CSV 파일을 읽고 전체 SQL 테이블을 읽은 다음 로컬 컴퓨터에서 함께 조인하는 것을 원하지 않을 수 있습니다. PQ에서 CSV 데이터를 SQL 문으로 인라인하고 SQL 데이터베이스에 조인을 수행하도록 요청할 수 있습니다.
이것은 의도하지 않은 데이터 유출이 발생할 수 있는 방법입니다.
직원 사회 보장 번호가 포함된 SQL 데이터를 외부 OData 피드의 결과와 조인하고 갑자기 SQL의 주민등록번호가 OData 서비스로 전송되고 있음을 알게 된 경우를 가정해 보십시오. 나쁜 소식, 맞죠?
방화벽이 방지하려는 시나리오의 종류입니다.
작동 방식
방화벽은 한 원본의 데이터가 의도치 않게 다른 원본으로 전송되는 것을 방지하기 위해 존재합니다. 충분히 간단합니다.
그렇다면 어떻게 이 임무를 완수할 수 있을까요?
M 쿼리를 파티션이라고 하는 것으로 나눈 다음 다음 규칙을 적용하여 이 작업을 수행합니다.
- 파티션은 호환되는 데이터 원본에 액세스하거나 다른 파티션을 참조할 수 있지만 둘 다 참조할 수는 없습니다.
간단한... 그러나 혼란스럽습니다. 파티션이란? 두 데이터 원본이 "호환"되는 이유는 무엇인가요? 파티션이 데이터 원본에 액세스하고 파티션을 참조하려는 경우 방화벽이 관리해야 하는 이유는 무엇인가요?
이를 세분화하고 위의 규칙을 한 번에 한 조각씩 살펴보겠습니다.
파티션이란?
가장 기본적인 수준에서 파티션은 하나 이상의 쿼리 단계의 컬렉션일 뿐입니다. 가능한 가장 세분화된 파티션(적어도 현재 구현에서)은 단일 단계입니다. 가장 큰 파티션은 경우에 따라 여러 쿼리를 포함할 수 있습니다. (자세한 내용은 나중에 참조하세요.)
단계에 익숙하지 않은 경우 적용된 단계 창에서 쿼리를 선택한 후 Power Query 편집기 창 오른쪽에서 볼 수 있습니다. 단계는 데이터를 최종 셰이프로 변환하기 위해 수행한 모든 작업을 추적합니다.
다른 파티션을 참조하는 파티션
방화벽을 사용하여 쿼리를 평가할 때 방화벽은 쿼리와 모든 종속성을 파티션(즉, 단계 그룹)으로 나눕니다. 한 파티션이 다른 파티션에서 무언가를 참조할 때마다 방화벽은 참조를 호출 Value.Firewall로 대체합니다. 즉, 방화벽은 파티션이 서로 직접 액세스하는 것을 허용하지 않습니다. 모든 참조는 방화벽을 통과하도록 수정됩니다. 방화벽을 게이트키퍼로 생각하세요. 다른 파티션을 참조하는 파티션은 방화벽의 사용 권한을 가져와야 하며 방화벽은 참조된 데이터를 파티션에 허용할지 여부를 제어합니다.
이 모든 것이 매우 추상적인 것처럼 보일 수 있으므로 예제를 살펴보겠습니다.
SQL 데이터베이스에서 일부 데이터를 가져오는 Employees라는 쿼리가 있다고 가정합니다. 단순히 직원을 참조하는 다른 쿼리(EmployeesReference)도 있다고 가정합니다.
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
이러한 쿼리는 Employees 쿼리용과 EmployeesReference 쿼리(Employees 파티션을 참조하는)에 대한 파티션의 두 파티션으로 나뉩니다. 방화벽을 사용하여 평가하면 다음과 같이 이러한 쿼리가 다시 작성됩니다.
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
Employees 쿼리에 대한 간단한 참조가 Employees 쿼리의 전체 이름을 제공하는 호출 Value.Firewall로 대체되었습니다.
EmployeesReference를 평가하면 Value.Firewall("Section1/Employees") 호출이 방화벽에 의해 가로채지며, 이제 요청된 데이터가 EmployeesReference 파티션으로 흐르는지(그리고 어떻게) 제어할 수 있습니다. 요청 거부, 요청된 데이터 버퍼링(원래 데이터 원본에 대한 추가 접기 방지) 등 다양한 작업을 수행할 수 있습니다.
이것이 방화벽이 파티션 간에 흐르는 데이터를 제어할 기본 있는 방법입니다.
데이터 원본에 직접 액세스하는 파티션
한 단계로 쿼리 Query1을 정의하고(이 단일 단계 쿼리는 하나의 방화벽 파티션에 해당) 이 단일 단계에서 SQL 데이터베이스 테이블과 CSV 파일의 두 데이터 원본에 액세스한다고 가정해 보겠습니다. 파티션 참조가 없으므로 방화벽이 이를 가로채도록 Value.Firewall 호출하지 않으므로 방화벽에서 이 문제를 어떻게 처리하나요? 앞에서 설명한 규칙을 검토해 보겠습니다.
- 파티션은 호환되는 데이터 원본에 액세스하거나 다른 파티션을 참조할 수 있지만 둘 다 참조할 수는 없습니다.
단일 파티션이 아닌 두 개의 데이터 원본 쿼리를 실행하도록 허용하려면 두 데이터 원본이 "호환"되어야 합니다. 즉, 데이터를 양방향으로 공유해도 됩니다. 즉, 두 원본의 개인 정보 수준은 양방향으로 공유를 허용하는 유일한 두 가지 조합이므로 공용이거나 둘 다 조직이어야 합니다. 두 원본이 모두 비공개로 표시되거나 한 원본이 공용으로 표시되고 하나는 조직으로 표시되거나 다른 개인 정보 수준 조합을 사용하여 표시된 경우 양방향 공유가 허용되지 않으므로 둘 다 동일한 파티션에서 평가되는 것이 안전하지 않습니다. 이렇게 하면 안전하지 않은 데이터 누출이 발생할 수 있으며(접기로 인해) 방화벽이 이를 방지할 방법이 없습니다.
동일한 파티션에서 호환되지 않는 데이터 원본에 액세스하려고 하면 어떻게 되나요?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
이제 이 문서의 시작 부분에 나열된 오류 메시지 중 하나를 더 잘 이해할 수 있기를 바랍니다.
이 호환성 요구 사항은 지정된 파티션 내에서만 적용됩니다. 파티션이 다른 파티션을 참조하는 경우 참조된 파티션의 데이터 원본은 서로 호환될 필요가 없습니다. 방화벽이 데이터를 버퍼링할 수 있기 때문에 원래 데이터 원본에 대한 추가 접기를 방지할 수 있기 때문입니다. 데이터는 메모리에 로드되고 아무 데도 없는 것처럼 처리됩니다.
왜 둘 다하지?
두 개의 다른 쿼리(즉, 다른 두 파티션)에 액세스하는 한 단계(한 파티션에 다시 해당)로 쿼리를 정의한다고 가정해 보겠습니다. 동일한 단계에서 SQL 데이터베이스에 직접 액세스하려면 어떻게 해야 할까요? 파티션이 다른 파티션을 참조하고 호환되는 데이터 원본에 직접 액세스할 수 없는 이유는 무엇인가요?
앞에서 보았듯이 한 파티션이 다른 파티션을 참조할 때 방화벽은 파티션으로 흐르는 모든 데이터에 대한 게이트키퍼 역할을 합니다. 이렇게 하려면 허용되는 데이터를 제어할 수 있어야 합니다. 파티션 내에서 액세스되는 데이터 원본이 있고 다른 파티션에서 들어오는 데이터가 있는 경우 내부적으로 액세스하는 데이터 원본 중 하나에 데이터가 유출될 수 있으므로 게이트키퍼가 될 수 없습니다. 따라서 방화벽은 다른 파티션에 액세스하는 파티션이 데이터 원본에 직접 액세스할 수 없도록 합니다.
따라서 파티션이 다른 파티션을 참조하고 데이터 원본에 직접 액세스하려고 하면 어떻게 될까요?
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
이제 이 문서의 시작 부분에 나열된 다른 오류 메시지를 더 잘 이해할 수 있기를 바랍니다.
파티션 심층 분석
위의 정보에서 추측할 수 있듯이 쿼리가 분할되는 방식은 매우 중요합니다. 다른 쿼리를 참조하는 몇 가지 단계와 데이터 원본에 액세스하는 다른 단계가 있는 경우 이제 특정 위치에서 파티션 경계를 그리면 방화벽 오류가 발생하는 것을 인식하고 다른 위치에 그리면 쿼리가 제대로 실행될 수 있습니다.
그렇다면 쿼리는 정확히 어떻게 분할될까요?
이 섹션은 방화벽 오류가 표시되는 이유를 이해하고 해결 방법(가능한 경우)을 이해하는 데 가장 중요합니다.
다음은 분할 논리에 대한 대략적인 요약입니다.
- 초기 분할
- 각 쿼리의 각 단계에 대한 파티션을 만듭니다.
- 정적 단계
- 이 단계는 평가 결과에 의존하지 않습니다. 대신 쿼리를 구성하는 방법에 의존합니다.
- 매개 변수 트리밍
- 매개 변수-에스크 파티션, 즉 다음 중 하나를 트리밍합니다.
- 다른 파티션을 참조하지 않음
- 함수 호출을 포함하지 않습니다.
- 순환되지 않음(즉, 자체 참조하지 않음)
- 파티션을 "제거"하면 파티션을 참조하는 다른 파티션에 효과적으로 포함됩니다.
- 매개 변수 파티션을 트리밍하면 "파티션은 데이터 원본 및 기타 단계를 참조할 수 없습니다." 오류를 throw하는 대신 데이터 원본 함수 호출(예
Web.Contents(myUrl): )에 사용되는 매개 변수 참조가 작동할 수 있습니다.
- 매개 변수-에스크 파티션, 즉 다음 중 하나를 트리밍합니다.
- 그룹화(정적)
- 파티션은 상향식 종속성 순서로 병합됩니다. 결과 병합된 파티션에서는 다음과 같이 구분됩니다.
- 다른 쿼리의 파티션
- 다른 파티션을 참조하지 않고 데이터 원본에 액세스할 수 있는 파티션
- 다른 파티션을 참조하는 파티션(따라서 데이터 원본에 액세스하는 것이 금지됨)
- 파티션은 상향식 종속성 순서로 병합됩니다. 결과 병합된 파티션에서는 다음과 같이 구분됩니다.
- 매개 변수 트리밍
- 이 단계는 평가 결과에 의존하지 않습니다. 대신 쿼리를 구성하는 방법에 의존합니다.
- 동적 단계
- 이 단계는 다양한 파티션에서 액세스하는 데이터 원본에 대한 정보를 포함하여 평가 결과에 따라 달라집니다.
- 트리밍
- 다음 요구 사항을 모두 충족하는 파티션을 트리밍합니다.
- 데이터 원본에 액세스하지 않음
- 데이터 원본에 액세스하는 파티션을 참조하지 않습니다.
- 순환되지 않음
- 다음 요구 사항을 모두 충족하는 파티션을 트리밍합니다.
- 그룹화(동적)
- 불필요한 파티션이 잘리게 되었으므로 가능한 한 큰 원본 파티션을 만들려고 합니다. 이 작업은 위의 정적 그룹화 단계에서 설명한 것과 동일한 규칙을 사용하여 파티션을 병합하여 수행됩니다.
이 모든 것이 무엇을 의미합니까?
위에 배치된 복잡한 논리가 어떻게 작동하는지 보여 주는 예제를 살펴보겠습니다.
다음은 샘플 시나리오입니다. SQL Server가 매개 변수(DbServer)인 SQL 데이터베이스(Employees)와 텍스트 파일(연락처)을 매우 간단하게 병합하는 것입니다.
세 가지 쿼리
다음은 이 예제에 사용된 세 개의 쿼리에 대한 M 코드입니다.
shared DbServer = "MySqlServer" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents("C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(#"Promoted Headers",{{"ContactID", Int64.Type}, {"NameStyle", type logical}, {"Title", type text}, {"FirstName", type text}, {"MiddleName", type text}, {"LastName", type text}, {"Suffix", type text}, {"EmailAddress", type text}, {"EmailPromotion", Int64.Type}, {"Phone", type text}, {"PasswordHash", type text}, {"PasswordSalt", type text}, {"AdditionalContactInfo", type text}, {"rowguid", type text}, {"ModifiedDate", type datetime}})
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(HumanResources_Employee,{"HumanResources.Employee(EmployeeID)", "HumanResources.Employee(ManagerID)", "HumanResources.EmployeeAddress", "HumanResources.EmployeeDepartmentHistory", "HumanResources.EmployeePayHistory", "HumanResources.JobCandidate", "Person.Contact", "Purchasing.PurchaseOrderHeader", "Sales.SalesPerson"}),
#"Merged Queries" = Table.NestedJoin(#"Removed Columns",{"ContactID"},Contacts,{"ContactID"},"Contacts",JoinKind.LeftOuter),
#"Expanded Contacts" = Table.ExpandTableColumn(#"Merged Queries", "Contacts", {"EmailAddress"}, {"EmailAddress"})
in
#"Expanded Contacts";
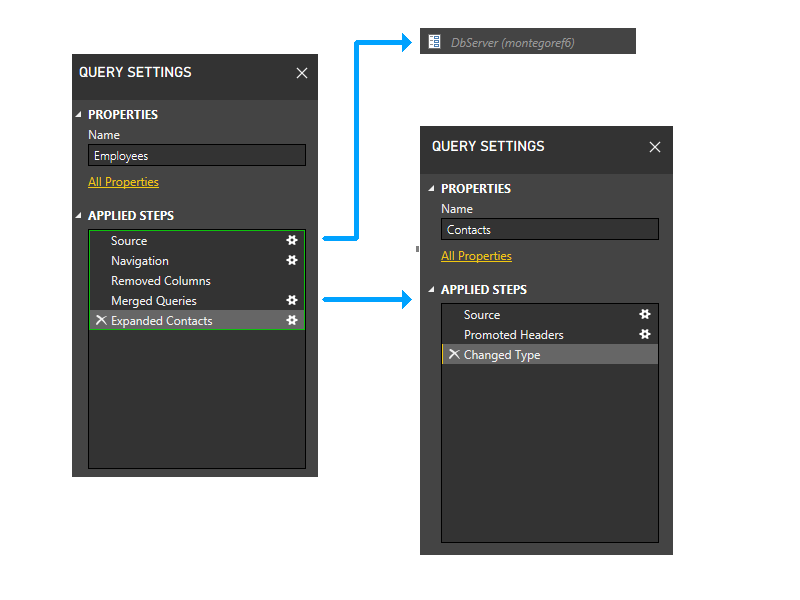
다음은 종속성을 보여 주는 상위 수준 보기입니다.
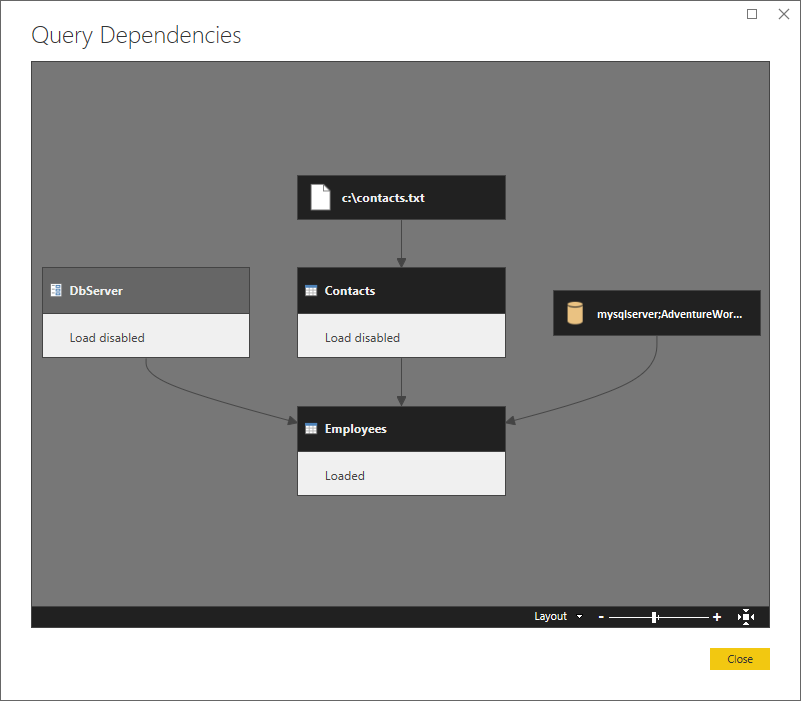
파티션을 살펴보겠습니다.
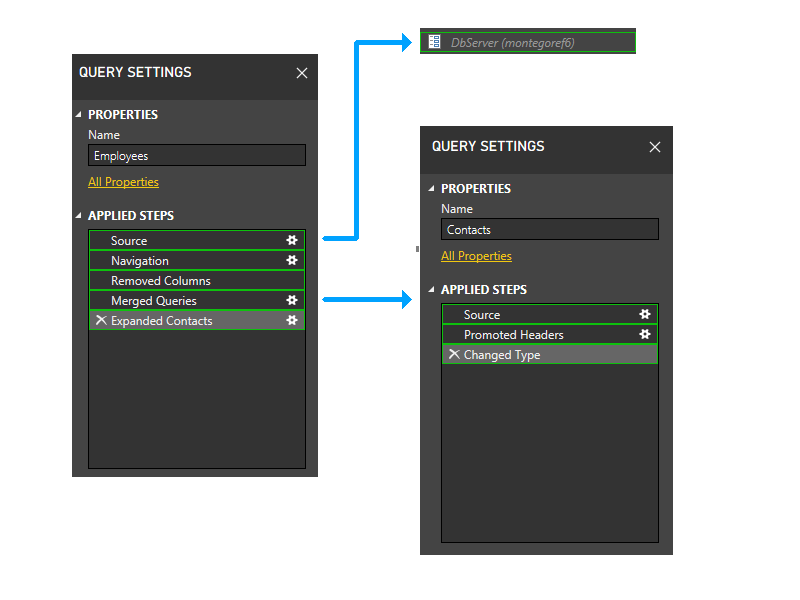
조금씩 확대하고 그림에 단계를 포함하고 분할 논리를 탐색해 보겠습니다. 다음은 초기 방화벽 파티션을 녹색으로 보여 주는 세 가지 쿼리의 다이어그램입니다. 각 단계는 자체 파티션에서 시작됩니다.
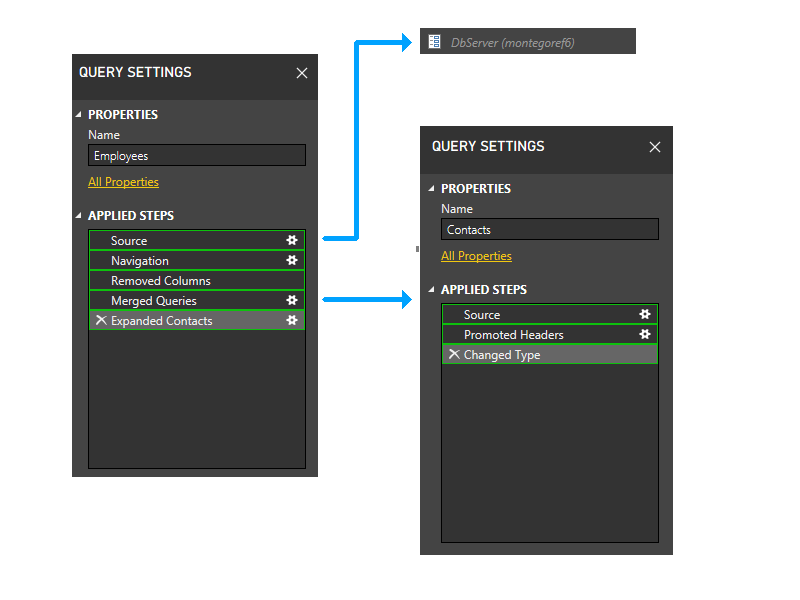
다음으로 매개 변수 파티션을 트리밍합니다. 따라서 DbServer는 소스 파티션에 암시적으로 포함됩니다.
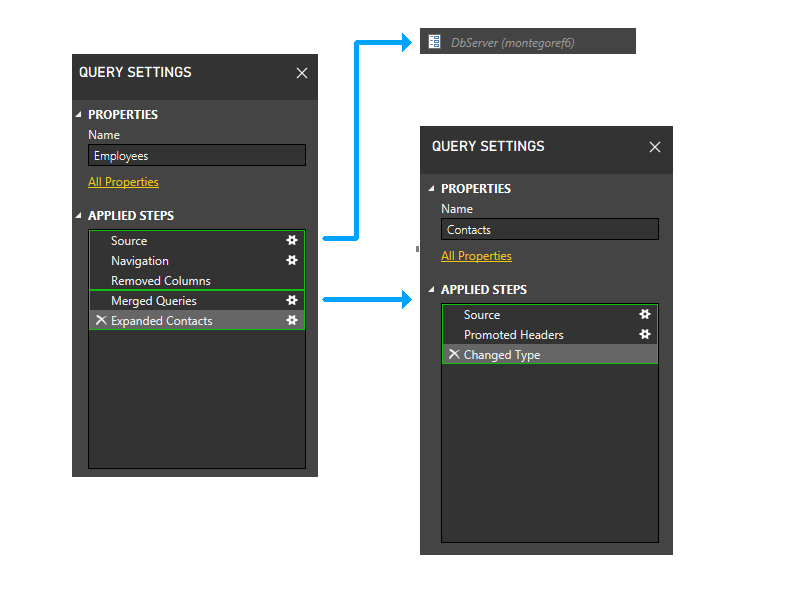
이제 정적 그룹화 작업을 수행합니다. 이 기본 별도의 쿼리에서 파티션(예를 들어 직원의 마지막 두 단계가 연락처의 단계로 그룹화되지 않음) 및 다른 파티션(예: 직원의 마지막 두 단계)을 참조하는 파티션과 그렇지 않은 파티션 간(예: 직원의 처음 세 단계)을 구분합니다.
이제 동적 단계로 들어갑니다. 이 단계에서는 위의 정적 파티션이 평가됩니다. 데이터 원본에 액세스하지 않는 파티션은 잘립니다. 그런 다음 파티션을 그룹화하여 가능한 한 큰 원본 파티션을 만듭니다. 그러나 이 샘플 시나리오에서는 모든 다시 기본 파티션이 데이터 원본에 액세스하며 더 이상 그룹화할 수 없습니다. 따라서 샘플의 파티션은 이 단계에서 변경되지 않습니다.
척해 봅시다.
하지만 설명을 위해 텍스트 파일에서 오는 대신 연락처 쿼리가 M에서 하드 코딩된 경우(아마도 데이터 입력 대화 상자를 통해) 어떻게 되는지 살펴보겠습니다.
이 경우 연락처 쿼리는 데이터 원본에 액세스하지 않습니다. 따라서 동적 단계의 첫 번째 부분에서 잘립니다.
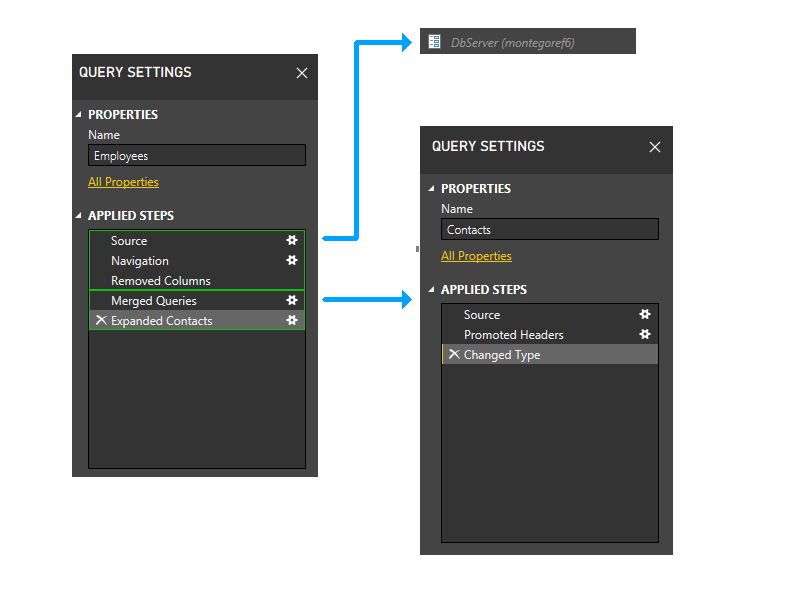
연락처 파티션이 제거되면 직원의 마지막 두 단계는 직원의 처음 세 단계를 포함하는 파티션을 제외하고 더 이상 파티션을 참조하지 않습니다. 따라서 두 파티션이 그룹화됩니다.
결과 파티션은 다음과 같습니다.
예: 한 데이터 원본에서 다른 데이터 원본으로 데이터 전달
좋아, 충분한 추상적 인 설명. 방화벽 오류가 발생할 가능성이 있는 일반적인 시나리오와 이를 해결하는 단계를 살펴보겠습니다.
Northwind OData 서비스에서 회사 이름을 조회한 다음 회사 이름을 사용하여 Bing 검색을 수행하려는 경우를 상상해 보세요.
먼저 회사 이름을 검색하는 회사 쿼리를 만듭니다.
let
Source = OData.Feed("https://services.odata.org/V4/Northwind/Northwind.svc/", null, [Implementation="2.0"]),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
다음으로, 회사를 참조하고 Bing에 전달하는 검색 쿼리를 만듭니다.
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
이 시점에서 당신은 문제가 발생합니다. 검색을 평가하면 방화벽 오류가 발생합니다.
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
검색의 원본 단계에서 데이터 원본(bing.com)을 참조하고 다른 쿼리/파티션(회사)도 참조하기 때문입니다. 위에서 멘션 규칙을 위반합니다("파티션은 호환되는 데이터 원본에 액세스하거나 다른 파티션을 참조할 수 있지만 둘 다 참조할 수는 없습니다.").
그렇다면 어떻게 해야 할까요? 한 가지 옵션은 방화벽을 완전히 사용하지 않도록 설정하는 것입니다(개인 정보 수준 무시 및 잠재적으로 성능 향상이라는 레이블이 지정된 개인 정보 옵션 사용). 하지만 방화벽을 사용하도록 설정하려면 어떻게 해야 할까요?
방화벽을 사용하지 않도록 설정하지 않고 오류를 해결하려면 다음과 같이 Company와 Search를 단일 쿼리로 결합할 수 있습니다.
let
Source = OData.Feed("https://services.odata.org/V4/Northwind/Northwind.svc/", null, [Implementation="2.0"]),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
이제 모든 것이 단일 파티션 내에서 발생합니다. 두 데이터 원본의 개인 정보 수준이 호환되는 경우 방화벽은 이제 만족해야 하며 더 이상 오류가 발생하지 않습니다.
즉, 랩입니다
이 주제에 대해 할 수 있는 것이 훨씬 더 많지만, 이 소개 문서는 이미 충분히 길다. 방화벽에 대한 이해를 높이고 나중에 방화벽 오류가 발생할 때 방화벽 오류를 이해하고 수정하는 데 도움이 되기를 바랍니다.