파워 쿼리에서 유사 항목 일치가 작동하는 방식
유사 항목 병합, 클러스터 값 및 유사 항목 그룹화와 같은 파워 쿼리 기능은 유사 항목 일치로 작동하는 동일한 메커니즘을 사용합니다.
이 문서에서는 '유사 항목'을 명확하게 하기 위해 유사 항목 일치가 가진 옵션을 활용하는 방법을 보여 주는 많은 시나리오를 설명합니다.
유사성 임계값 조정
유사 항목 일치 알고리즘을 적용하는 가장 좋은 시나리오는 열의 모든 텍스트 문자열에 비교해야 하는 문자열만 포함하고 추가 구성 요소가 없는 경우입니다. 예를 들어 비교하면 Apples 4ppl3s 비교보다 높은 유사성 점수 Apples 가 My favorite fruit, by far, is Apples. I simply love them!생성됩니다.
두 번째 문자열의 단어 Apples 는 전체 텍스트 문자열의 작은 부분일 뿐이므로 비교하면 유사성 점수가 낮아집니다.
예를 들어 다음 데이터 세트는 질문 하나만 있는 설문 조사의 응답으로 구성됩니다. "가장 좋아하는 과일은 무엇인가요?"
| 과일 |
|---|
| 블루베리 |
| 블루 베리는 단순히 최고입니다 |
| 딸기 |
| 딸기 = <3 |
| Apples |
| 'sples |
| 4ppl3s |
| 바나나 |
| fav 과일은 바나나입니다 |
| 바나스 주 |
| 내가 가장 좋아하는 과일은 지금까지 사과입니다. 나는 단순히 그들을 사랑해요! |
설문 조사는 값을 입력할 단일 텍스트 상자를 하나 제공했으며 유효성 검사가 없었습니다.
이제 값을 클러스터링해야 합니다. 이 작업을 수행하려면 이전 과일 테이블을 파워 쿼리에 로드하고 열을 선택한 다음 리본 메뉴의 열 추가 탭에서 클러스터 값 옵션을 선택합니다.
![]()
새 열의 이름을 지정할 수 있는 클러스터 값 대화 상자가 나타납니다. 이 새 열 클러스터의 이름을 지정하고 확인을 선택합니다.
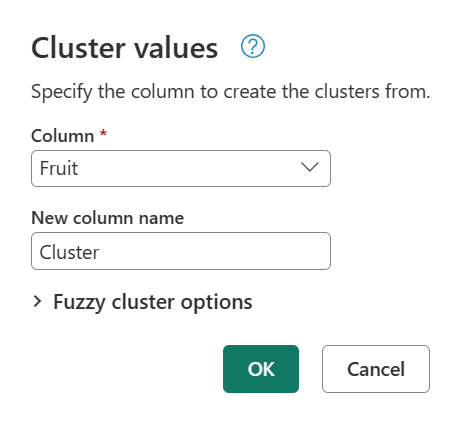
기본적으로 파워 쿼리는 0.8(또는 80%)의 유사성 임계값을 사용합니다. 최소값 0.00은 모든 수준의 유사성을 가진 모든 값이 서로 일치하도록 하고 최대값 1.00은 정확한 일치만 허용합니다. 유사하게 "정확한 일치"는 대/소문자, 단어 순서 및 문장 부호와 같은 차이를 무시할 수 있습니다. 이전 작업의 결과로 새 클러스터 열이 있는 다음 테이블이 생성됩니다.
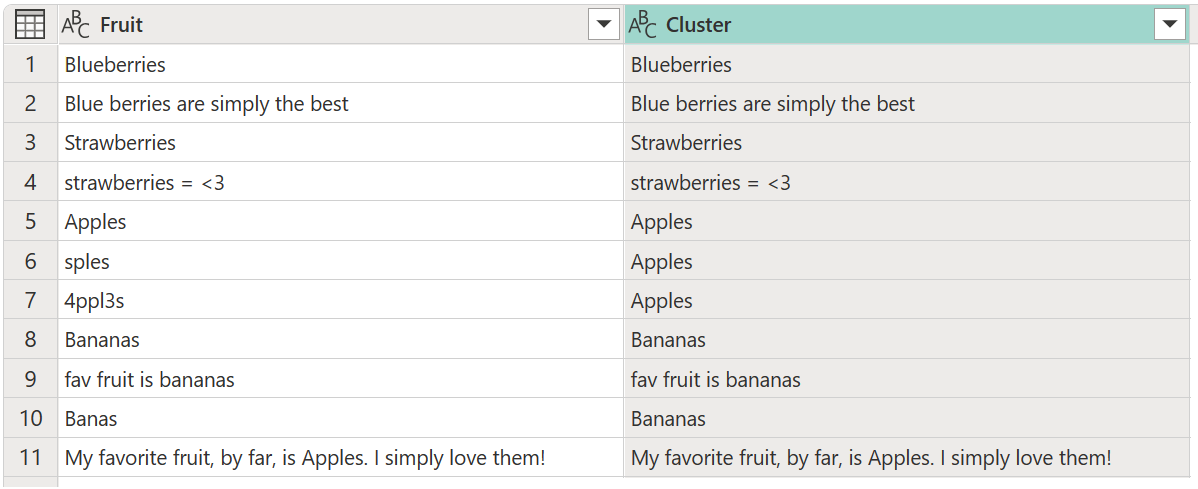
클러스터링이 완료되는 동안 모든 행에 대한 예상 결과를 제공하지는 않습니다. 행 번호 2(2)에는 여전히 값Blue berries are simply the best이 있지만 묶Blueberries어야 하며 텍스트 문자열과 My favorite fruit, by far, is Apples. I simply love them!비슷한 동작이 발생합니다Strawberries = <3fav fruit is bananas.
이 클러스터링의 원인을 확인하려면 적용된 단계 패널에서 클러스터형 값을 두 번 클릭하여 클러스터 값 대화 상자를 다시 가져옵니다. 이 대화 상자 내에서 유사 항목 클러스터 옵션을 확장 합니다. 유사성 점수 표시 옵션을 사용하도록 설정한 다음 확인을 선택합니다.
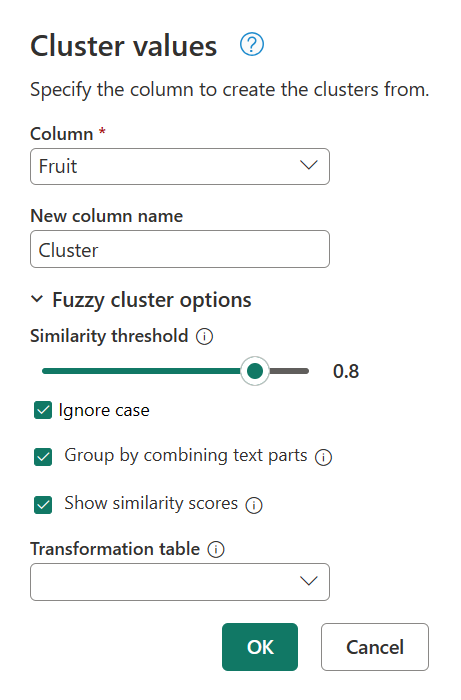
유사성 점수 표시 옵션을 사용하도록 설정하면 테이블에 새 열이 만들어집니다. 이 열은 정의된 클러스터와 원래 값 간의 정확한 유사성 점수를 보여줍니다.

자세히 살펴보면 파워 쿼리에서 텍스트 문자열Blue berries are simply the bestStrawberries = <3fav fruit is bananas, 및 My favorite fruit, by far, is Apples. I simply love them!에 대한 유사성 임계값에서 다른 값을 찾을 수 없습니다.
적용된 단계 패널에서 클러스터형 값을 두 번 클릭하여 클러스터 값 대화 상자로 한 번 더 돌아갑니다. 유사성 임계값을 0.8에서 0.6으로 변경한 다음 확인을 선택합니다.
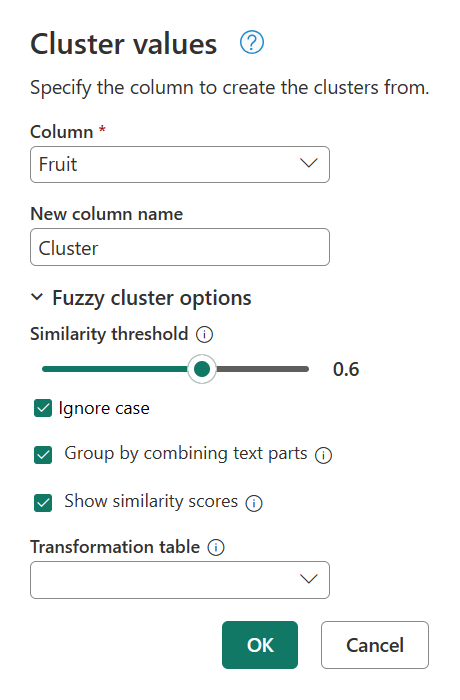
이렇게 변경하면 텍스트 문자열 My favorite fruit, by far, is Apples. I simply love them!을 제외하고 찾고 있는 결과에 더 가까워집니다. 유사성 임계값을 0.8에서 0.6으로 변경한 경우 파워 쿼리는 이제 0.6에서 1까지 시작하는 유사성 점수가 있는 값을 사용할 수 있었습니다.

참고 항목
파워 쿼리는 항상 임계값에 가장 가까운 값을 사용하여 클러스터를 정의합니다. 임계값은 클러스터에 값을 할당할 수 있는 유사성 점수의 하한을 정의합니다.
원하는 결과를 얻을 때까지 유사성 점수를 0.6에서 더 낮은 숫자로 변경하여 다시 시도할 수 있습니다. 이 경우 유사성 점수를 0.5로 변경합니다. 이 변경으로 인해 이제 클러스터Apples에 할당된 텍스트 문자열 My favorite fruit, by far, is Apples. I simply love them! 로 예상하는 정확한 결과가 생성됩니다.

참고 항목
현재 파워 쿼리 온라인의 클러스터 값 기능만 유사성 점수가 있는 새 열을 제공합니다.
변환 테이블에 대한 특별 고려 사항
변환 테이블을 사용하면 유사 항목 일치 알고리즘을 수행하기 전에 열의 값을 새 값으로 매핑할 수 있습니다.
변환 테이블을 사용하는 방법에 대한 몇 가지 예는 다음과 같습니다.
Important
변환 테이블을 사용하는 경우 변환 테이블의 값에 대한 최대 유사성 점수는 0.95입니다. 이러한 열의 원래 값이 변환이 발생한 이후와 비교된 값과 같지 않음을 구분하기 위해 0.05의 의도적인 페널티가 적용됩니다.
먼저 값을 매핑한 다음 0.05 페널티 없이 유사 항목 일치를 수행하려는 시나리오의 경우 열의 값을 바꾼 다음 유사 항목 일치를 수행하는 것이 좋습니다.