소개
개요
Microsoft 파워 쿼리는 많은 기능을 포함하는 강력한 "데이터 가져오기" 환경을 제공합니다. 파워 쿼리의 핵심 기능은 여러 다양한 지원 데이터 원본에서 데이터를 필터링하고 결합하여, 이른바 "매시업"하는 것입니다. 이러한 데이터 매시업은 파워 쿼리 수식 언어(비공식적으로 "M"라고 함)를 사용하여 표현됩니다. 파워 쿼리는 반복 가능한 데이터 매시업을 사용하도록 Excel, Power BI, Analysis Services 및 Dataverse를 비롯한 다양한 Microsoft 제품에 M 문서를 포함합니다.
이 문서에서는 M에 대한 사양을 제공합니다. 이 문서에서는 언어에 대한 첫 번째 직관과 친숙함을 구축하는 것을 목표로 하는 간략한 소개를 마친 후 다음과 같은 몇 가지 점진적 단계에서 정확하게 언어를 다룹니다.
어휘 구조 어휘적으로 유효한 텍스트 집합을 정의합니다.
값, 식, 환경 및 변수, 식별자 및 평가 모델은 언어의 기본 개념형성합니다.
기본 및 구조화된
값의 자세한 사양은 언어의 대상 도메인을 정의합니다. 값에는 기본 값의 종류를 설명하고 구조화된 값의 형태와 관련된 추가 메타데이터를 전달하는 특별한 종류의 형식이 있습니다.
M에서
연산자 집합은 어떤 종류의 식을 구성할 수 있는지 정의합니다. Functions은 다른 종류의 특수 값으로, M을 위한 풍부한 표준 라이브러리의 기초를 제공하며 새로운 추상화 추가를 가능하게 합니다.
오류 식 평가 중에 연산자 또는 함수를 적용할 때 발생할 수 있습니다. 오류는 값이 아니지만 오류를 값으로 다시 매핑하여 처리하는 방법이 있습니다.
식을 사용하면 더 작은 단계에서 복잡한 식을 빌드하는 데 사용되는 보조 정의를 도입할 수 있습니다.
If 식은 조건부 평가를 지원합니다.
단락은 간단한 모듈성 메커니즘을 제공합니다. (섹션은 파워 쿼리에서 아직 활용되지 않습니다.)
마지막으로, 종합 문법이 문서의 다른 모든 섹션에서 문법 조각을 수집하여 하나의 완전한 정의로 만듭니다.
컴퓨터 언어 이론가의 경우: 이 문서에 지정된 수식 언어는 대부분 순수하고, 순서가 높고, 동적으로 입력되고, 부분적으로 지연된 기능 언어입니다.
식 및 값
M의 중앙 구문은 표현식입니다. 식은 계산되어 단일 값을생성할 수 있습니다.
리터럴을 사용하여 많은 값을 식으로 직접 작성할 수 있지만, 값 자체는 식이 아닙니다. 예를 들어, 식 1는 값 1로 계산되며, 식 1+1는 값 2로 계산됩니다. 이러한 구분은 미묘하지만 중요합니다. 표현식은 평가를 위한 레시피입니다. 값은 평가 결과입니다.
다음 예제에서는 M에서 사용할 수 있는 다양한 종류의 값을 보여 줍니다. 규칙으로 값은 해당 값으로 계산되는 식에 표시되는 리터럴 형식을 사용하여 작성됩니다. (// 줄의 끝까지 계속되는 주석의 시작을 나타냅니다.
기본 값은 숫자, 논리, 텍스트, 또는 null과 같은 단일 요소 값입니다. null 값을 사용하여 데이터가 없음을 나타낼 수 있습니다.
123 // A number true // A logical "abc" // A text null // null value목록 값은 정렬된 값 시퀀스입니다. M은 무한 목록을 지원하지만 리터럴로 작성된 경우 목록은 길이가 고정됩니다. 중괄호 문자
{와}은 목록의 시작과 끝을 나타냅니다.{123, true, "A"} // list containing a number, a logical, and // a text {1, 2, 3} // list of three numbers레코드
는 입니다. 필드는 이름/값 쌍으로, 이름은 필드 레코드 내에서 고유한 텍스트 값입니다. 레코드 값에 대한 리터럴 구문을 사용하면 이름을 따옴표 없이 쓸 수 있습니다. 이러한 형태는 식별자로도 알려져 있으며,이라고 합니다. 다음은 값이필드의 집합 1,2및3있는 "A" , "B" 및 "C"라는 세 개의 필드가 포함된 레코드를 보여줍니다.[ A = 1, B = 2, C = 3 ]테이블 열(이름으로 식별됨) 및 행으로 구성된 값 집합입니다. 테이블을 만들기 위한 리터럴 구문은 없지만 목록이나 레코드에서 테이블을 만드는 데 사용할 수 있는 몇 가지 표준 함수가 있습니다.
예를 들어:
#table( {"A", "B"}, { {1, 2}, {3, 4} } )그러면 다음 셰이프의 테이블이 만들어집니다.
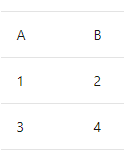
함수는 인수를 사용하여 호출할 때 새 값을 생성하는 값입니다. 함수는 괄호 안에 함수의 매개 변수를 나열하고, 이어서 기호 =>를 쓰고, 그 뒤에 함수를 정의하는 식을 작성하여 만듭니다. 해당 식은 일반적으로 매개 변수를 참조합니다(이름별).(x, y) => (x + y) / 2`
평가
M 언어의 평가 모델은 스프레드시트에서 일반적으로 발견되는 평가 모델을 기준으로 모델링됩니다. 여기서 계산 순서는 셀의 수식 간의 종속성에 따라 결정될 수 있습니다.
Excel과 같은 스프레드시트에서 수식을 작성한 경우 계산 시 왼쪽의 수식이 오른쪽 값으로 인식될 수 있습니다.

M에서 식의 일부는 이름으로 식의 다른 부분을 참조할 수 있으며, 평가 프로세스는 참조된 식이 계산되는 순서를 자동으로 결정합니다.
레코드를 사용하여 이전 스프레드시트 예제와 동일한 식을 생성할 수 있습니다. 필드 값을 초기화할 때 다음과 같이 필드 이름을 사용하여 레코드 내의 다른 필드를 참조할 수 있습니다.
[
A1 = A2 * 2,
A2 = A3 + 1,
A3 = 1
]
위의 식은 다음과 같습니다(두 식 모두 같은 값으로 평가됩니다).
[
A1 = 4,
A2 = 2,
A3 = 1
]
레코드는 다른 레코드 안에 포함되거나 다른 레코드 안에서 중첩될 수 있습니다.
조회 연산자([])를 사용하여 이름으로 레코드의 필드에 액세스할 수 있습니다. 예를 들어 다음 레코드에는 레코드가 포함된 Sales 필드와 Sales 레코드의 FirstHalf 및 SecondHalf 필드에 액세스하는 Total 필드가 있습니다.
[
Sales = [ FirstHalf = 1000, SecondHalf = 1100 ],
Total = Sales[FirstHalf] + Sales[SecondHalf]
]
위의 식은 계산될 때 다음과 같습니다.
[
Sales = [ FirstHalf = 1000, SecondHalf = 1100 ],
Total = 2100
]
레코드는 목록에 포함할 수도 있습니다.
위치 인덱스 연산자({})를 사용하여 숫자 인덱스로 목록의 항목에 액세스할 수 있습니다. 목록 내의 값은 목록의 시작 부분에서 0부터 시작하는 인덱스를 사용하여 참조됩니다. 예를 들어 0 및 1 인덱스는 아래 목록의 첫 번째 및 두 번째 항목을 참조하는 데 사용됩니다.
[
Sales =
{
[
Year = 2007,
FirstHalf = 1000,
SecondHalf = 1100,
Total = FirstHalf + SecondHalf // 2100
],
[
Year = 2008,
FirstHalf = 1200,
SecondHalf = 1300,
Total = FirstHalf + SecondHalf // 2500
]
},
TotalSales = Sales{0}[Total] + Sales{1}[Total] // 4600
]
목록 및 레코드 멤버 표현식(let 표현식포함)은 지연 평가방법을 사용하여 필요할 때만 평가됩니다. 다른 모든 식은 즉시 평가사용하여 평가됩니다. 즉, 평가 프로세스 중에 발견되면 즉시 평가됩니다. 이에 대해 생각해 보는 좋은 방법은 목록 또는 레코드 식을 평가하면 목록 항목 또는 레코드 필드가 요청될 때(조회 또는 인덱스 연산자를 통해) 계산되어야 하는 방법을 기억하는 목록 또는 레코드 값이 반환된다는 점을 기억하는 것입니다.
함수
M에서 함수은 입력 값 집합을 단일 출력 값에 매핑하는 것입니다. 함수는 먼저 필수 입력 값 집합(함수에 대한 매개 변수)의 이름을 지정한 다음, 해당 입력 값(함수 본문)을 사용하여 함수의 결과를 계산하는 식을 제공하여=>기호 다음에 작성됩니다. 예를 들어:
(x) => x + 1 // function that adds one to a value
(x, y) => x + y // function that adds two values
함수는 숫자나 텍스트 값과 같은 값입니다. 다음 예제에서는 추가 필드의 값인 함수를 보여주며, 이 함수는 다른 여러 필드로부터호출되거나 실행됩니다
[
Add = (x, y) => x + y,
OnePlusOne = Add(1, 1), // 2
OnePlusTwo = Add(1, 2) // 3
]
도서관
M에는 표준 라이브러리으로 불리는 식에서 사용할 수 있는 일반적인 정의 집합이 포함되어 있으며, 간단히 라이브러리 로도 불립니다. 이러한 정의는 명명된 값 집합으로 구성됩니다. 라이브러리에서 제공하는 값의 이름은 식에서 명시적으로 정의하지 않고도 식 내에서 사용할 수 있습니다. 예를 들어:
Number.E // Euler's number e (2.7182...)
Text.PositionOf("Hello", "ll") // 2
운영자
M에는 식에 사용할 수 있는 연산자 집합이 포함되어 있습니다.
연산자피연산자 적용되어 기호식을 형성합니다. 예를 들어, 식 1 + 2에서 숫자 1과 2는 피연산자이고, 연산자는 더하기 연산자(+)입니다.
연산자의 의미는 피연산자의 값 종류에 따라 달라질 수 있습니다. 예를 들어 더하기 연산자는 숫자 외에 다른 종류의 값과 함께 사용할 수 있습니다.
1 + 2 // numeric addition: 3
#time(12,23,0) + #duration(0,0,2,0)
// time arithmetic: #time(12,25,0)
피연산자에 따라 의미가 있는 연산자의 또 다른 예는 조합 연산자(&)입니다.
"A" & "BC" // text concatenation: "ABC"
{1} & {2, 3} // list concatenation: {1, 2, 3}
[ a = 1 ] & [ b = 2 ] // record merge: [ a = 1, b = 2 ]
일부 연산자는 값의 모든 조합을 지원하지 않습니다. 예를 들어:
1 + "2" // error: adding number and text isn't supported
계산 시 정의되지 않은 연산자 조건이오류를
메타데이터
메타데이터는 값에 관련된 정보입니다. 메타데이터는 메타데이터 레코드레코드 값으로 표시됩니다. 메타데이터 레코드의 필드를 사용하여 값에 대한 메타데이터를 저장할 수 있습니다.
모든 값에는 메타데이터 레코드가 있습니다. 메타데이터 레코드의 값을 지정하지 않은 경우 메타데이터 레코드는 비어 있습니다(필드 없음).
메타데이터 레코드는 추가 정보를 눈에 거슬리지 않는 방식으로 모든 종류의 값과 연결하는 방법을 제공합니다. 메타데이터 레코드를 값과 연결해도 값이나 동작은 변경되지 않습니다.
y 메타데이터 레코드 값은 x meta y구문을 사용하여 x 기존의 값과 연결됩니다. 예를 들어 다음 코드는 메타데이터 레코드를 Rating 및 Tags 필드와 텍스트 값 "Mozart"연결합니다.
"Mozart" meta [ Rating = 5, Tags = {"Classical"} ]
비어 있지 않은 메타데이터 레코드가 이미 있는 값의 경우 메타를 적용한 결과는 기존 및 새 메타데이터 레코드의 레코드 병합을 계산하는 것입니다. 예를 들어 다음 두 식은 서로 동일하며 이전 식과 동일합니다.
("Mozart" meta [ Rating = 5 ]) meta [ Tags = {"Classical"} ]
"Mozart" meta ([ Rating = 5 ] & [ Tags = {"Classical"} ])
Value.Metadata 함수를 사용하여 지정된 값에 대한 메타데이터 레코드에 액세스할 수 있습니다. 다음 예제에서 ComposerRating 필드의 식은 Composer 필드에 있는 값의 메타데이터 레코드에 액세스한 다음 메타데이터 레코드의 Rating 필드에 액세스합니다.
[
Composer = "Mozart" meta [ Rating = 5, Tags = {"Classical"} ],
ComposerRating = Value.Metadata(Composer)[Rating] // 5
]
Let 식
지금까지 보여 준 많은 예제에는 식의 결과에 식의 모든 리터럴 값이 포함되어 있습니다.
let 식을 사용하면 값 집합을 계산하고 이름을 할당한 다음 in뒤에 있는 후속 식에서 사용할 수 있습니다. 예를 들어 판매 데이터 예제에서는 다음을 수행할 수 있습니다.
let
Sales2007 =
[
Year = 2007,
FirstHalf = 1000,
SecondHalf = 1100,
Total = FirstHalf + SecondHalf // 2100
],
Sales2008 =
[
Year = 2008,
FirstHalf = 1200,
SecondHalf = 1300,
Total = FirstHalf + SecondHalf // 2500
]
in Sales2007[Total] + Sales2008[Total] // 4600
위의 식의 결과는 이름 Sales2007 및 Sales2008바인딩된 값에서 계산되는 숫자 값(4600)입니다.
If 조건문
if 식은 논리 조건에 따라 두 식 중에서 선택합니다. 예를 들어:
if 2 > 1 then
2 + 2
else
1 + 1
논리 식(2 > 1)이 true이면 첫 번째 식(2 + 2)이 선택되고 두 번째 식(1 + 1)이 false이면 선택됩니다. 선택한 식(이 경우 2 + 2)이 계산되고 if 식(4)의 결과가 됩니다.
오류
오류 식 평가 프로세스에서 값을 생성할 수 없음을 나타냅니다.
오류는 오류 조건이 발생하거나 오류 식을 사용하여 연산자와 함수에 의해 발생합니다. 오류는 try 식을 사용하여 처리됩니다. 오류가 발생하면 오류가 발생한 이유를 나타내는 데 사용할 수 있는 값이 지정됩니다.
let Sales =
[
Revenue = 2000,
Units = 1000,
UnitPrice = if Units = 0 then error "No Units"
else Revenue / Units
],
UnitPrice = try Number.ToText(Sales[UnitPrice])
in "Unit Price: " &
(if UnitPrice[HasError] then UnitPrice[Error][Message]
else UnitPrice[Value])
위의 예제에서는 Sales[UnitPrice] 필드에 액세스하고 결과를 생성하는 값의 형식을 지정합니다.
"Unit Price: 2"
Units 필드가 0이었다면, UnitPrice 필드가 오류를 발생시켰을 것이고, 이는 try에 의해 처리되었을 것입니다. 그러면 결과 값은 다음과 같습니다.
"No Units"
try 식은 적절한 값과 오류를 레코드 값으로 변환하여, try 식이 오류를 처리했는지 여부와 오류를 처리할 때 추출한 적절한 값 또는 오류 레코드를 나타냅니다. 예를 들어 오류를 발생시킨 다음 바로 처리하는 다음 식을 고려해 보세요.
try error "negative unit count"
이 표현식은 이전 단가 예제에서 [HasError], [Error], 및 [Message] 필드 조회를 설명하는 다음과 같은 중첩된 레코드 값으로 평가됩니다.
[
HasError = true,
Error =
[
Reason = "Expression.Error",
Message = "negative unit count",
Detail = null
]
]
일반적인 경우는 오류를 기본값으로 바꾸는 것입니다.
try 식은 선택적 otherwise 절과 함께 사용하여 간결한 형식으로 구현할 수 있습니다.
try error "negative unit count" otherwise 42
// 42