Microsoft Purview에서 검사 및 수집
이 문서에서는 Microsoft Purview의 검사 및 수집 기능에 대한 개요를 제공합니다. 이러한 기능은 Microsoft Purview 계정을 원본에 연결하여 데이터 맵을 채우고 microsoft Purview를 통해 데이터 탐색 및 관리를 시작할 수 있도록 통합 카탈로그.
- 검사는데이터 원본 에서 메타데이터를 캡처하여 Microsoft Purview로 가져옵니다.
-
수집은 메타데이터를 처리하고 다음 두 가지 모두에서 통합 카탈로그 저장합니다.
- 데이터 원본 검사 - 검사된 메타데이터가 Microsoft Purview 데이터 맵 추가됩니다.
- 계보 연결 - 변환 리소스는 원본, 출력 및 활동에 대한 메타데이터를 Microsoft Purview 데이터 맵 추가합니다.
검색
데이터 원본이 Microsoft Purview 계정에 등록되면 다음 단계는 데이터 원본을 검사하는 것입니다. 검사 프로세스는 데이터 원본에 대한 연결을 설정하고 이름, 파일 크기, 열 등과 같은 기술 메타데이터를 캡처합니다. 또한 구조화된 데이터 원본에 대한 스키마를 추출하고, 스키마에 분류를 적용하고, Microsoft Purview 데이터 맵 Microsoft Purview 규정 준수 포털 연결된 경우 민감도 레이블을 적용합니다. 검사 프로세스는 즉시 실행되도록 트리거되거나 Microsoft Purview 계정을 최신 상태로 유지하기 위해 주기적으로 실행되도록 예약할 수 있습니다.
각 검사에는 전체 원본이 아닌 필요한 정보만 검사하도록 적용할 수 있는 사용자 지정이 있습니다.
검사에 대한 인증 방법 선택
Microsoft Purview는 기본적으로 안전합니다. 암호나 비밀은 Microsoft Purview에 직접 저장되지 않으므로 원본에 대한 인증 방법을 선택해야 합니다. Microsoft Purview 계정을 인증하는 방법에는 여러 가지가 있지만 각 데이터 원본에 대해 모든 메서드가 지원되는 것은 아닙니다.
- 관리 ID
- 서비스 주체
- SQL 인증
- Windows 인증
- 역할 ARN
- 위임된 인증
- 소비자 키
- 계정 키 또는 기본 인증
가능하면 개별 데이터 원본에 대한 자격 증명을 저장하고 관리할 필요가 없으므로 관리 ID가 기본 인증 방법입니다. 이렇게 하면 사용자와 팀이 검사에 대한 인증 설정 및 문제 해결에 소요되는 시간을 크게 줄일 수 있습니다. Microsoft Purview 계정에 대해 관리 ID를 사용하도록 설정하면 id가 Microsoft Entra ID 만들어지고 계정의 수명 주기에 연결됩니다.
검사 범위 지정
원본을 검사할 때 전체 데이터 원본을 검사하거나 검사할 특정 엔터티(폴더/테이블)만 선택할 수 있습니다. 사용 가능한 옵션은 검사하는 원본에 따라 달라지며 일회성 검사와 예약된 검사 모두에 대해 정의할 수 있습니다.
예를 들어 Azure SQL 데이터베이스에 대한 검사를 만들고 실행할 때 검색할 테이블을 선택하거나 전체 데이터베이스를 선택할 수 있습니다.
각 엔터티(폴더/테이블)에 대해 완전히 선택되고, 부분적으로 선택되고, 선택되지 않은 세 가지 선택 상태가 있습니다. 아래 예제에서 폴더 계층 구조에서 "Department 1"을 선택하면 "Department 1"이 완전히 선택된 것으로 간주됩니다. "회사" 및 "예제"와 같은 "Department 1"의 부모 엔터티는 동일한 부모 아래에 다른 엔터티가 선택되지 않았기 때문에 부분적으로 선택된 것으로 간주됩니다(예: "Department 2"). 선택 상태가 다른 엔터티의 경우 UI에서 다른 아이콘이 사용됩니다.
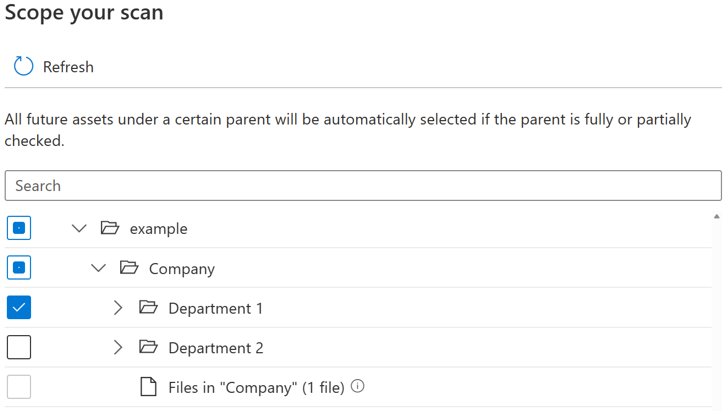
검사를 실행한 후에는 원본 시스템에 새 자산이 추가될 가능성이 높습니다. 검사를 다시 실행할 때 부모가 완전히 선택되거나 부분적으로 선택되면 기본적으로 특정 부모 아래의 미래 자산이 자동으로 선택됩니다. 위의 예제에서 "Department 1"을 선택하고 검사를 실행한 후 검색을 다시 실행할 때 "Department 1" 또는 "Company" 및 "example" 아래에 있는 모든 새 자산이 포함됩니다.
사용자가 부분적으로 선택된 부모 아래에서 새 자산에 대한 자동 포함을 제어할 수 있도록 토글 단추가 도입되었습니다. 기본적으로 토글은 꺼지고 부분적으로 선택된 부모에 대한 자동 포함 동작은 사용하지 않도록 설정됩니다. 토글이 꺼진 동일한 예제에서 "회사" 및 "예제"와 같이 부분적으로 선택된 부모 아래에 있는 새 자산은 검사를 다시 실행할 때 포함되지 않으며 "부서 1"의 새 자산만 향후 검사에 포함됩니다.
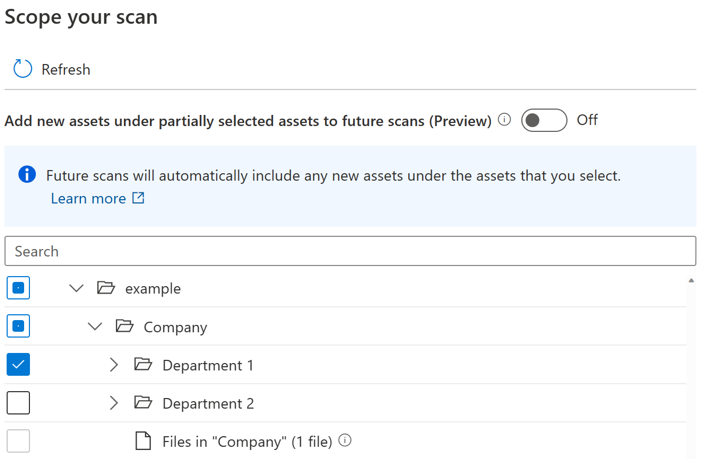
토글 단추가 켜져 있으면 검사를 다시 실행할 때 부모가 완전히 선택되거나 부분적으로 선택되면 특정 부모 아래의 새 자산이 자동으로 선택됩니다. 포함 동작은 토글 단추가 도입되기 전과 동일합니다.
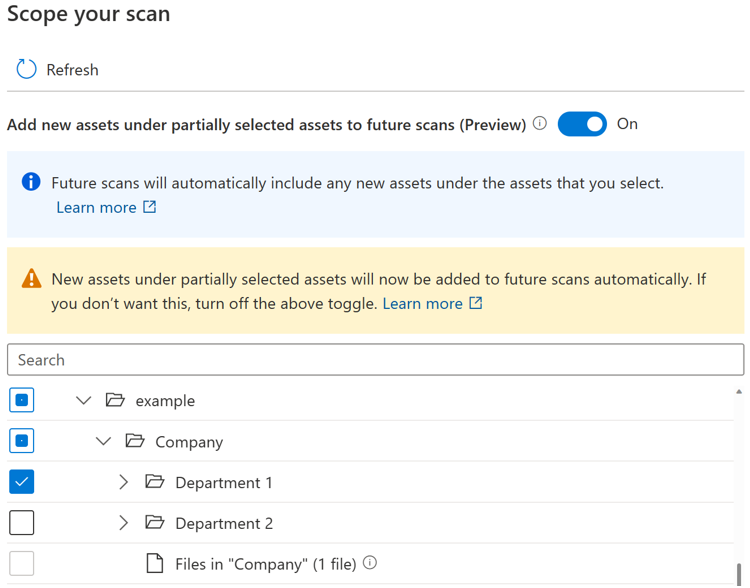
참고
- 토글 단추의 가용성은 데이터 원본 형식에 따라 달라집니다. 현재 Azure Blob Storage, Azure Data Lake Storage Gen 1, Azure Data Lake Storage Gen 2, Azure Files 및 Azure Dedicated SQL 풀(이전의 SQL DW)을 포함한 원본에 대한 공개 미리 보기에서 사용할 수 있습니다.
- 토글 단추가 도입되기 전에 생성되거나 예약된 검사의 경우 토글 상태가 켜짐으로 설정되며 변경할 수 없습니다. 토글 단추가 도입된 후 생성되거나 예약된 검사의 경우 검색을 저장한 후에는 토글 상태를 변경할 수 없습니다. 토글 상태를 변경하려면 새 검사를 만들어야 합니다.
- 토글 단추를 끄면 Azure Data Lake Storage Gen 2와 같은 스토리지 유형의 원본에 대해 검색 작업이 완료된 후 원본 유형별 찾아보기 환경을 완전히 사용할 수 있게 되기까지 최대 4시간이 걸릴 수 있습니다.
알려진 제한
토글 단추가 꺼져 있는 경우:
- 부분적으로 선택된 부모 아래의 파일 엔터티는 검사되지 않습니다.
- 부모 아래의 모든 기존 엔터티가 명시적으로 선택된 경우 부모는 완전히 선택된 것으로 간주되고 검사를 다시 실행할 때 부모 아래의 모든 새 자산이 포함됩니다.
검사 수준 사용자 지정
Microsoft Purview 데이터 맵 용어에는 메타데이터 scope 및 기능에 따라 세 가지 수준의 검사가 있습니다.
- L1 검사: 파일 이름, 크기 및 정규화된 이름과 같은 기본 정보 및 메타데이터를 추출합니다.
- L2 검사: 구조화된 파일 형식 및 데이터베이스 테이블에 대한 스키마 추출
- L3 검사: 해당하는 경우 스키마를 추출하고 샘플링된 파일을 시스템 및 사용자 지정 분류 규칙에 적용합니다.
새 검사를 설정하거나 기존 검사를 편집할 때 검사 수준 구성을 이미 지원한 데이터 원본을 검사하기 위한 검사 수준을 사용자 지정할 수 있습니다.
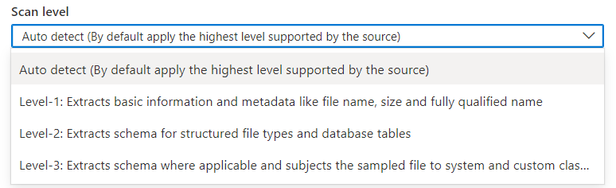
기본적으로 "자동 검색"이 선택됩니다. 즉, Microsoft Purview는 이 데이터 원본에 사용할 수 있는 가장 높은 검사 수준을 적용합니다. Azure SQL 데이터베이스를 예로 들어 데이터 원본이 이미 Microsoft Purview에서 분류를 지원하므로 검사가 실행될 때 "자동 검색"이 "수준 3"으로 확인됩니다. 검사 실행 세부 정보에서 검사 수준은 적용된 실제 수준을 표시합니다.
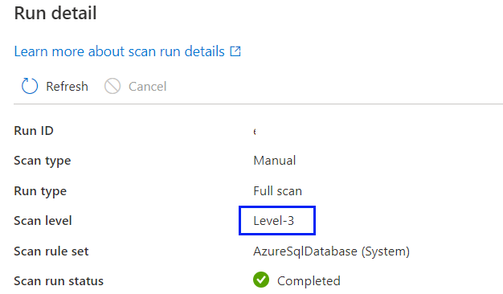
새 기능이 도입됨에 따라 검사 수준을 사용자 지정하기 전에 완료된 검사 기록에서 모든 검사 실행의 경우 기본적으로 검사 수준이 설정되고 "자동 검색"으로 표시됩니다.
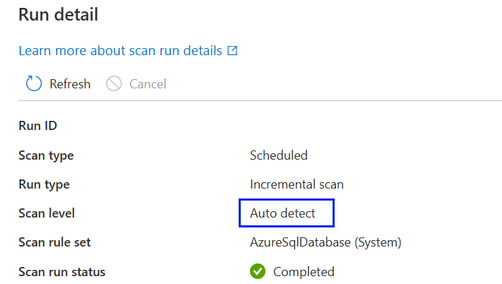
- 데이터 원본에 대해 더 높은 검사 수준을 사용할 수 있게 되면 검색 수준이 "자동 검색"으로 설정된 저장되거나 예약된 검색이 새 검사 수준을 자동으로 적용합니다. 예를 들어 지정된 데이터 원본에 대해 새 기능으로 분류를 사용하도록 설정하면 이 데이터 원본의 모든 기존 검사에서 분류가 자동으로 적용됩니다.
- 검사 수준 설정은 각 검사 실행에 대한 검사 모니터링 인터페이스에 표시됩니다.
- "수준 1"을 선택한 경우 검사는 특정 데이터 원본의 기존 메타데이터 가용성에 따라 자산 이름, 자산 크기, 수정된 타임스탬프 등과 같은 기본 기술 메타데이터만 반환합니다. Azure SQL Database의 경우 테이블과 같은 자산 엔터티는 테이블 스키마 추출 없이 Microsoft Purview 데이터 맵 만들어집니다. (참고: 사용자는 원본 시스템에 필요한 권한이 있는 경우 라이브 보기를 통해 테이블 스키마를 계속 볼 수 있습니다.)
- "수준 2"를 선택하면 검사에서 테이블 스키마와 기본 기술 메타데이터를 반환하지만 데이터 샘플링 및 분류는 수행되지 않습니다. Azure SQL 데이터베이스의 경우 테이블 자산 엔터티에는 분류 정보 없이 테이블 스키마가 캡처됩니다.)
- "수준 3"을 선택하면 검사에서 데이터 샘플링 및 분류를 수행합니다. 새 기능이 도입됨에 따라 검사 수준을 Azure SQL 데이터베이스 검사를 위한 표준 구성입니다.
- 예약된 검사가 더 낮은 검사 수준으로 설정되고 나중에 더 높은 검사 수준으로 수정되면 다음 검사 실행은 자동으로 전체 검사를 수행하고 데이터 원본의 모든 기존 데이터 자산은 더 높은 검사 수준 설정에 의해 도입된 메타데이터로 업데이트됩니다. 예를 들어 Azure SQL Database에서 "Level-2"로 설정된 예약된 검사 집합이 "Level-3"으로 변경되면 다음 검사 실행은 전체 검색이 되고 모든 기존 Azure SQL Database 테이블/뷰 자산이 분류 정보로 업데이트되고 그 이후의 모든 검사는 "Level-3"으로 설정된 증분 검사로 다시 시작됩니다.
- 예약된 검사가 더 높은 검사 수준으로 설정되고 나중에 더 낮은 검사 수준으로 수정되는 경우 다음 검사 실행은 증분 검사를 계속 수행하고 데이터 원본의 모든 새 데이터 자산에는 낮은 검사 수준 설정에서 도입된 메타데이터만 포함됩니다. 예를 들어 Azure SQL Database에서 "Level-3"이 있는 예약된 검사 집합이 "Level-2"로 변경되면 다음 검사 실행은 증분 검사이며 Microsoft Purview 데이터 맵 추가된 모든 새 Azure SQL Database 테이블/뷰 자산에는 분류 정보가 없습니다. 모든 기존 데이터 자산은 이전 검사 집합에서 생성된 분류 정보를 "Level-3"으로 유지합니다.
참고
- 검사 수준 사용자 지정은 현재 다음과 같은 데이터 원본에 사용할 수 있습니다. Azure SQL Database, Azure SQL Managed Instance, NoSQL용 Azure Cosmos DB, Azure Database for PostgreSQL, Azure Database for MySQL Azure Data Lake Storage Gen2, Azure Blob Storage, Azure Files, Azure Synapse Analytics, Azure Dedicated SQL 풀(이전의 SQL DW), Azure Data Explorer, Dataverse, Azure 다중(Azure 구독), Azure 다중(Azure 리소스 그룹), Snowflake, Azure Databricks Unity Catalog
- 현재 이 기능은 Azure IR 및 관리형 VNet IR v2에서만 사용할 수 있습니다.
검사 규칙 집합
검사 규칙 집합은 원본 중 하나에 대해 검색이 실행될 때 검색할 정보의 종류를 결정합니다. 사용 가능한 규칙은 검사하는 원본의 종류에 따라 달라지지만 검사해야 하는 파일 형식 및 필요한 분류 종류와 같은 항목 이 포함됩니다 .
많은 데이터 원본 형식에 대해 이미 사용할 수 있는 시스템 검사 규칙 집합이 있지만 사용자 고유의 검사 규칙 집합을 만들어 검사를 organization 맞게 조정할 수도 있습니다.
검사 예약
Microsoft Purview는 선택한 특정 시간에 매일, 매주 또는 매월 스캔을 선택할 수 있습니다. 지원되는 일정 옵션에 대해 자세히 알아봅니다. 매일 또는 매주 검색은 적극적으로 개발 중이거나 자주 변경되는 구조의 데이터 원본에 적합할 수 있습니다. 월별 검사는 자주 변경되지 않는 데이터 원본에 더 적합합니다. 가장 좋은 방법은 검사하려는 원본의 관리자와 협력하여 원본에 대한 컴퓨팅 요구가 낮은 시간을 식별하는 것입니다.
검사에서 삭제된 자산을 검색하는 방법
Microsoft Purview 카탈로그는 검사를 실행할 때만 데이터 저장소의 상태를 인식합니다. 카탈로그에서 파일, 테이블 또는 컨테이너가 삭제되었는지 확인하려면 마지막 검사 출력과 현재 검사 출력을 비교합니다. 예를 들어 Azure Data Lake Storage Gen2 계정을 마지막으로 검사했을 때 folder1이라는 폴더가 포함되어 있다고 가정합니다. 동일한 계정을 다시 검사하면 folder1 이 누락됩니다. 따라서 카탈로그는 폴더가 삭제되었다고 가정합니다.
팁
삭제된 파일이 검색되는 방식 때문에 삭제된 자산을 검색하고 resolve 위해 여러 횟수의 성공적인 검사가 필요할 수 있습니다. 통합 카탈로그 범위가 지정된 검사에 대한 삭제를 등록하지 않는 경우 여러 전체 검사를 시도하여 문제를 resolve.
삭제된 파일 검색
누락된 파일을 검색하는 논리는 동일한 사용자와 다른 사용자가 여러 클릭하여 검색하는 데 작동합니다. 예를 들어 사용자가 폴더 A, B 및 C의 Data Lake Storage Gen2 데이터 저장소에서 일회성 검사를 실행한다고 가정합니다. 나중에 동일한 계정의 다른 사용자가 동일한 데이터 저장소의 C, D 및 E 폴더에서 다른 일회성 검사를 실행합니다. C 폴더가 두 번 검사되었으므로 카탈로그는 삭제 가능한지 확인합니다. 그러나 A, B, D 및 E 폴더는 한 번만 검사되었으며 카탈로그는 삭제된 자산에 대해 검사 않습니다.
카탈로그에서 삭제된 파일을 유지하려면 정기적인 검사를 실행하는 것이 중요합니다. 카탈로그는 다른 검사가 실행될 때까지 삭제된 자산을 검색할 수 없으므로 검사 간격이 중요합니다. 따라서 특정 저장소에서 한 달에 한 번 검사를 실행하는 경우 카탈로그는 한 달 후에 다음 검사를 실행할 때까지 해당 저장소에서 삭제된 데이터 자산을 검색할 수 없습니다.
Data Lake Storage Gen2 같은 큰 데이터 저장소를 열거하는 경우 정보를 누락하는 여러 가지 방법(열거형 오류 및 삭제된 이벤트 포함)이 있습니다. 특정 검사에서 파일이 만들어지거나 삭제된 것을 놓칠 수 있습니다. 따라서 카탈로그가 특정 파일이 삭제되지 않는 한 카탈로그에서 삭제되지 않습니다. 이 전략은 스캔한 데이터 저장소에 없는 파일이 카탈로그에 여전히 존재하는 경우 오류가 발생할 수 있음을 의미합니다. 경우에 따라 삭제된 특정 자산을 catch하기 전에 데이터 저장소를 두세 번 스캔해야 할 수 있습니다.
참고
- 삭제로 표시된 자산은 성공적으로 검사한 후 삭제됩니다. 삭제된 자산은 처리 및 제거되기 전에 일정 시간 동안 카탈로그에 계속 표시될 수 있습니다.
- 현재 원본 삭제 검색은 다음 원본에 대해 지원되지 않습니다. Azure Databricks, Amazon Redshift, Cassandra, Dataverse, Db2, Erwin, Google BigQuery, Hive Metastore, Looker, MongoDB, MySQL, Oracle, PostgreSQL, Power BI, Qlik Sense, Salesforce, SAP BW, SAP ECC, SAP HANA, SAP S/4HANA, Snowflake, Tableau 및 Teradata. 데이터 원본에서 개체를 삭제하면 후속 검사에서 Microsoft Purview에서 해당 자산을 자동으로 제거하지 않습니다.
음식물 섭취
수집은 다양한 프로세스를 통해 수집된 메타데이터로 데이터 맵을 채우는 프로세스입니다.
검사에서 수집
그런 다음, 검사 프로세스로 식별된 기술 메타데이터 또는 분류가 수집으로 전송됩니다. 수집은 검사에서 입력을 분석하고, 리소스 집합 패턴을 적용하고, 사용 가능한 계보 정보를 채웁니다. 그런 다음 데이터 맵을 자동으로 로드합니다. 자산/스키마는 수집이 완료된 후에만 검색하거나 큐레이팅할 수 있습니다. 따라서 검사가 완료되었지만 데이터 맵 또는 카탈로그에서 자산을 못한 경우 수집 프로세스가 완료되기를 기다려야 합니다.
계보 연결에서 수집
Azure Data Factory 및 Azure Synapse 같은 리소스를 Microsoft Purview에 연결하여 데이터 원본 및 계보 정보를 Microsoft Purview 데이터 맵 가져올 수 있습니다. 예를 들어 Microsoft Purview에 연결된 Azure Data Factory 복사 파이프라인이 실행되면 입력 원본, 활동 및 출력 원본에 대한 메타데이터가 Microsoft Purview에서 수집되고 정보가 데이터 맵에 추가됩니다.
검사를 통해 데이터 원본이 데이터 맵에 이미 추가된 경우 활동에 대한 계보 정보가 기존 원본에 추가됩니다. 데이터 원본이 데이터 맵에 아직 추가되지 않은 경우 계보 수집 프로세스는 계보 정보를 사용하여 루트 컬렉션에 추가합니다.
사용 가능한 계보 연결에 대한 자세한 내용은 계보 사용자 가이드를 참조하세요.
다음 단계
자세한 내용이나 원본 검사에 대한 특정 지침은 아래 링크를 따르세요.
- 리소스 집합을 이해하려면 리소스 집합 문서를 참조하세요.
- Azure SQL 데이터베이스를 관리하는 방법
- Microsoft Purview의 계보