데이터 자산에 대한 데이터 프로파일링 구성 및 실행
데이터 프로파일링은 다양한 데이터 원본에서 사용할 수 있는 데이터를 검사하고 이 데이터에 대한 통계 및 정보를 수집하는 프로세스입니다. 데이터 프로파일링은 정의된 목표 집합에 따라 데이터의 품질 수준을 평가하는 데 도움이 됩니다. 데이터가 품질이 좋지 않거나 기업의 요구 사항을 충족하기 위해 통합할 수 없는 구조에서 관리되는 경우 비즈니스 프로세스 및 의사 결정이 어려움을 겪습니다. 데이터 프로파일링을 사용하면 데이터의 신뢰성과 품질을 이해할 수 있으며, 이는 수익을 높이고 성장을 촉진하는 데이터 기반 의사 결정을 내리기 위한 필수 구성 요소입니다.
필수 구성 요소
- 데이터 품질 평가 검사를 실행하고 예약하려면 사용자가 데이터 품질 관리자 역할에 있어야 합니다.
- 현재 Microsoft Purview 계정은 데이터 품질 검사를 실행할 수 있도록 공용 액세스 또는 관리형 vNet 액세스를 허용하도록 설정할 수 있습니다.
데이터 품질 수명 주기
데이터 프로파일링은 데이터 자산의 데이터 품질 수명 주기의 다섯 번째 단계입니다. 이전 단계는 다음과 같습니다.
- 통합 카탈로그 사용자 데이터 품질 관리자 권한을 할당하여 모든 데이터 품질 기능을 사용합니다.
- Microsoft Purview 데이터 맵 데이터 원본을 등록하고 검사합니다.
- 데이터 제품에 데이터 자산 추가
- 데이터 품질 평가를 위해 원본을 준비하도록 데이터 원본 연결을 설정합니다.
지원되는 다중 클라우드 데이터 원본
- Azure Data Lake Storage(ADLS Gen2)
- 파일 형식: Delta Parquet 및 Parquet
- Azure SQL 데이터베이스
- OneLake의 패브릭 데이터 자산에는 바로 가기 및 미러링 데이터 자산이 포함됩니다. 데이터 프로파일링은 Lakehouse 델타 테이블 및 parquet 파일에 대해서만 지원됩니다.
- 미러링 데이터 자산: Cosmos DB, Snowflake, Azure SQL
- 바로 가기 데이터 자산: AWS S3, GCS, AdlsG2 및 Dataverse
- 서버리스 및 데이터 웨어하우스 Azure Synapse
- Azure Databricks Unity 카탈로그
- Snowflake
- Google 빅 쿼리(프라이빗 미리 보기)
중요
Parquet 파일의 데이터 품질은 다음을 지원하도록 설계되었습니다.
- Parquet 파트 파일이 있는 디렉터리입니다. 예: ./Sales/{Parquet Part Files}. 정규화된 이름은 을 따라
https://(storage account).dfs.core.windows.net/(container)/path/path2/{SparkPartitions}야 합니다. 디렉터리/하위 디렉터리 구조에 {n} 패턴이 없는지 확인합니다. 대신 {SparkPartitions}로 이어지는 직접 FQN이어야 합니다. - 분할된 Parquet 파일이 있는 디렉터리로, 연도 및 월별로 분할된 판매 데이터와 같이 데이터 세트 내의 열로 분할됩니다. 예: ./Sales/{Year=2018}/{Month=Dec}/{Parquet Part Files}.
일관된 parquet 데이터 세트 스키마를 제공하는 이러한 필수 시나리오가 모두 지원됩니다.
제한: Parquet Files를 사용하여 디렉터리의 N 임의 계층 구조를 지원하거나 지원하지 않습니다.
(1) 또는 (2) 생성된 구조에 데이터를 제시하는 것이 좋습니다.
지원되는 인증 방법
현재 Microsoft Purview는 관리 ID 를 인증 옵션으로 사용하여 데이터 품질 검사만 실행할 수 있습니다. 데이터 품질 서비스는 Apache Spark 3.4 및 Delta Lake 2.4에서 실행됩니다. 지원되는 지역에 대한 자세한 내용은 데이터 품질 개요를 참조하세요.
중요
스키마가 데이터 원본에서 업데이트되는 경우 데이터 프로파일링을 실행하기 전에 데이터 맵 검사를 다시 실행해야 합니다.
데이터 프로파일링 작업을 구성하는 단계
Microsoft Purview 통합 카탈로그 상태 관리 메뉴 및 데이터 품질 하위 메뉴를 선택합니다.
데이터 품질 하위 메뉴에서 데이터 프로파일링에 대한 거버넌스 도메인 을 선택합니다.
데이터 제품을 선택하여 해당 제품에 연결된 데이터 자산을 프로파일합니다.
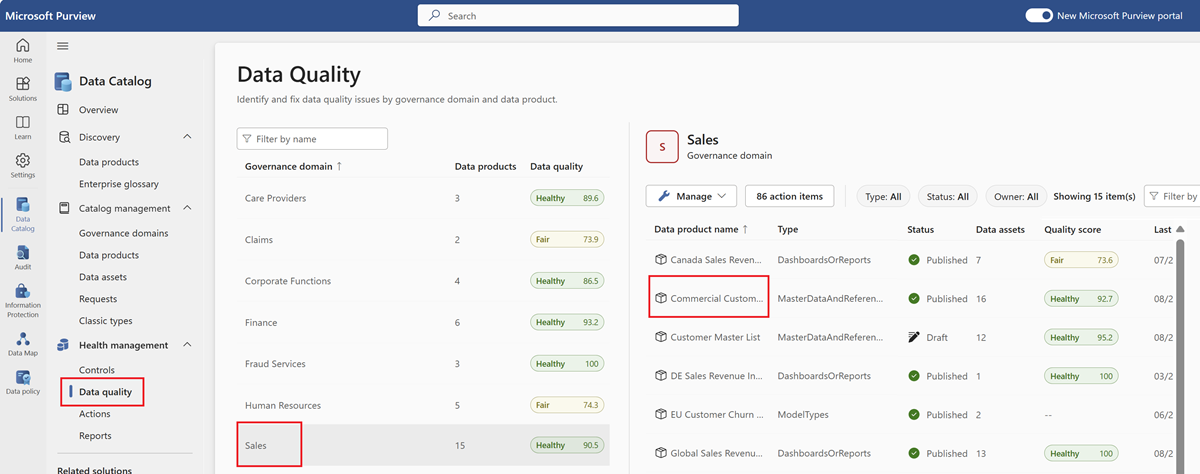
데이터 자산을 선택하여 프로파일링을 위해 데이터 품질 개요 페이지로 이동합니다.
프로필 단추를 선택하여 선택한 데이터 자산에 대한 프로파일링 작업을 실행합니다.

AI 권장 사항 엔진은 데이터 프로파일링을 실행하는 데 잠재적으로 중요한 열을 제안합니다. 권장 열의 선택을 취소하거나 프로파일될 더 많은 열을 선택할 수 있습니다.
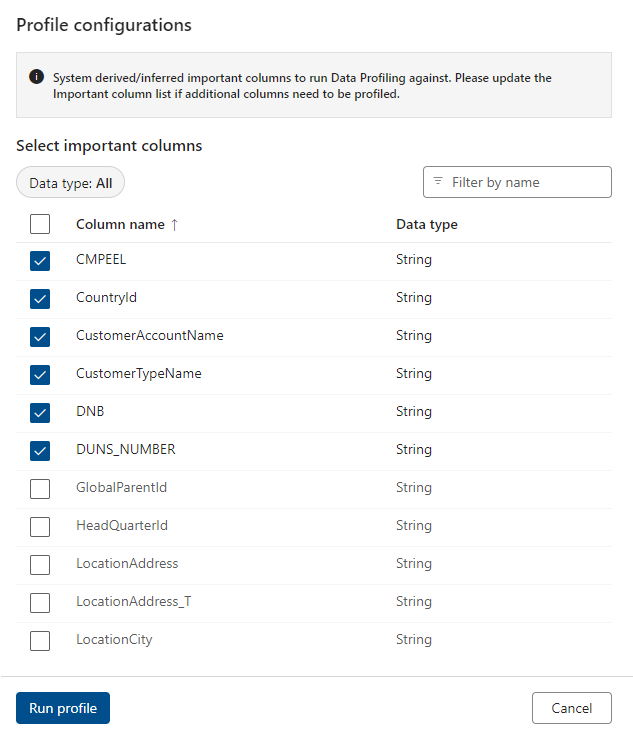
관련 열을 선택한 후 프로필 실행을 선택합니다.
작업이 실행되는 동안 거버넌스 도메인의 데이터 품질 모니터링 페이지에서 진행률을 추적할 수 있습니다.
작업이 완료되면 자산의 데이터 품질 페이지의 왼쪽 메뉴에서 프로필 탭을 선택하여 프로파일링 결과 및 통계 스냅샷 찾아봅니다. 데이터 자산의 열 수에 따라 여러 프로필 결과 페이지가 있을 수 있습니다.
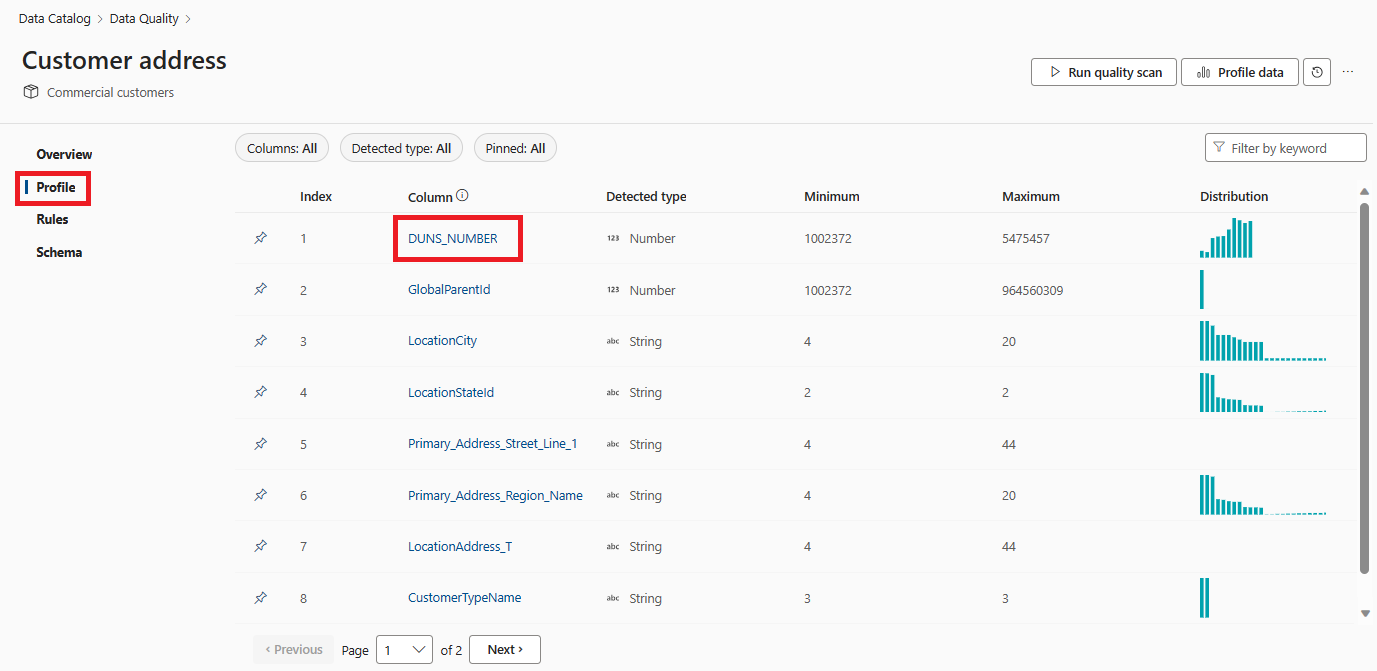
각 열에 대한 프로파일링 결과 및 통계 측정값을 찾아봅니다.
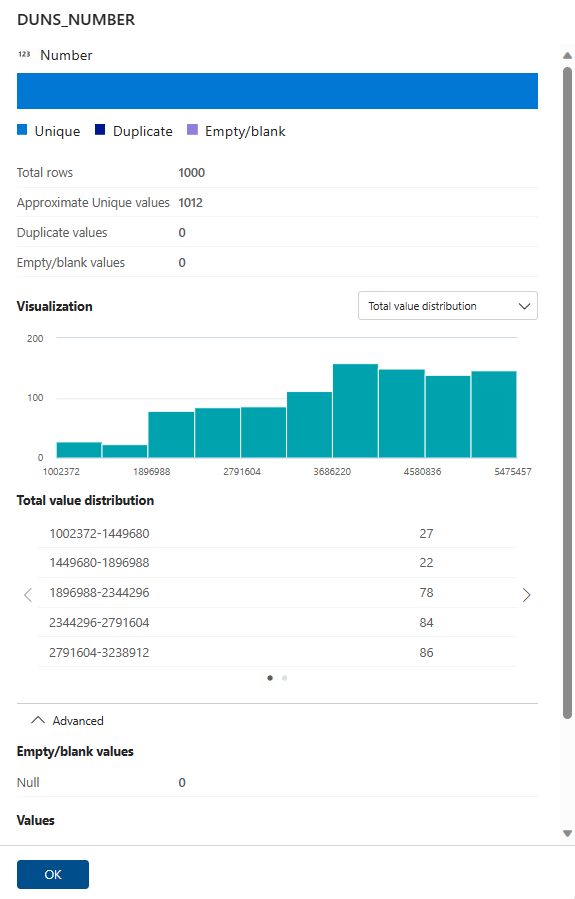



중요
원본 시스템에서 형식이 표준이고 올바른 경우 델타 형식은 대부분 자동으로 검색됩니다. Parquet 또는 iceberg 파일 형식을 프로파일하려면 데이터 자산 형식을 Parquet 또는 iceberg로 변경해야 합니다. 아래 스크린샷에 표시된 것처럼 데이터 자산 파일 형식이 델타가 아닌 경우 기본 데이터 자산 형식 Parquet 또는 기타 지원되는 형식을 변경합니다. 이 변경은 프로파일링 작업을 구성하기 전에 수행해야 합니다.

관련 콘텐츠
- 패브릭 데이터 자산에 대한 데이터 품질
- 패브릭 미러된 데이터 원본에 대한 데이터 품질
- 패브릭의 데이터 품질 바로 가기 데이터 원본
- Azure Synapse 서버리스 및 데이터 웨어하우스에 대한 데이터 품질
- Azure Databricks Unity 카탈로그에 대한 데이터 품질
- Snowflake 데이터 원본에 대한 데이터 품질
- Google 빅 쿼리에 대한 데이터 품질
다음 단계
- 프로파일링 결과에 따라 데이터 품질 규칙을 설정하고 데이터 자산에 적용합니다.
- 데이터 제품에서 데이터 품질 검사를 구성하고 실행 하여 데이터 제품의 지원되는 모든 자산의 품질을 평가합니다.
- 검사 결과를 검토 하여 데이터 제품의 현재 데이터 품질을 평가합니다.