실시간 운영 분석을 위한 columnstore 인덱스 시작
적용 대상:![]() Microsoft Fabric의 SQL Server
Microsoft Fabric의 SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() SQL 데이터베이스
SQL 데이터베이스
SQL Server 2016(13.x)에는 분석 워크로드와 OLTP 워크로드 모두를 같은 데이터베이스 테이블에서 동시에 실행하는 기능인 실시간 운영 분석이 도입되었습니다. 실시간으로 분석을 실행하는 것 외에도 ETL 및 Data Warehouse의 필요성을 제거할 수 있습니다.
실시간 운영 분석 설명
기존에는 운영 워크로드(즉, OLTP)와 분석 워크로드에 사용되는 별도의 시스템이 있었습니다. 이러한 시스템의 경우 ETL(추출, 변환, 로드) 작업은 정기적으로 운영 저장소에서 분석 저장소로 데이터를 이동합니다. 분석 데이터는 일반적으로 데이터 웨어하우스나 분석 쿼리 실행 전용 데이터 마트에 저장됩니다. 이 솔루션은 표준이지만 다음과 같은 세 가지 주요 과제가 있습니다.
복잡성. ETL을 구현하려면 특히 수정된 행만 로드하는 데 상당한 코딩이 필요할 수 있습니다. 수정된 행을 식별하는 것은 복잡할 수 있습니다.
비용 ETL을 구현하려면 추가 하드웨어 및 소프트웨어 라이선스를 구매하는 비용이 필요합니다.
데이터 대기 시간. ETL을 구현하면 분석 실행에 대한 시간 지연이 추가됩니다. 예를 들어 ETL 작업이 각 업무일 종료 시간에 실행되는 경우 분석 쿼리는 최소한 하루 이전의 데이터에서 실행됩니다. 대부분의 기업에서는 비즈니스가 실시간으로 데이터를 분석하는 데 의존하기 때문에 이 지연은 허용되지 않습니다. 예를 들어 사기 감지에는 운영 데이터에 대한 실시간 분석이 필요합니다.
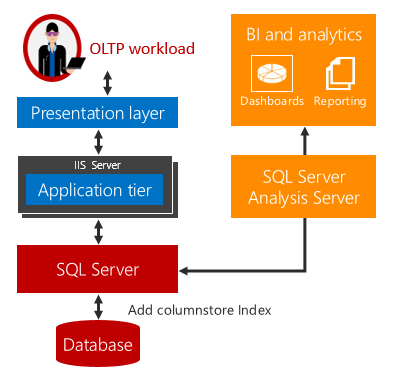
실시간 운영 분석은 이러한 문제에 대한 솔루션을 제공합니다.
분석 및 OLTP 워크로드가 동일한 기본 테이블에서 실행되는 경우 시간이 지연되지 않습니다. 실시간 분석을 사용할 수 있는 시나리오의 경우 ETL의 필요성과 별도의 Data Warehouse를 구입하고 유지 관리할 필요가 없으므로 비용과 복잡성이 크게 줄어듭니다.
참고 항목
실시간 운영 분석은 운영 및 분석 워크로드를 모두 실행할 수 있는 ERP(엔터프라이즈 리소스 계획) 애플리케이션과 같은 단일 데이터 원본의 시나리오를 대상으로 합니다. 이는 분석 워크로드를 실행하기 전에 여러 원본의 데이터를 통합해야 하거나 큐브와 같은 사전 집계된 데이터의 사용으로 극단적인 분석 성능이 필요한 경우에는 별도 데이터 웨어하우스에 대한 필요성을 대체하지 못합니다.
실시간 분석에서는 rowstore 테이블에서 업데이트 가능한 columnstore 인덱스를 사용합니다. columnstore 인덱스는 데이터의 복사본을 유지 관리하므로 OLTP 및 분석 워크로드는 별도의 데이터 복사본에 대해 실행됩니다. 이렇게 하면 두 워크로드의 동시 실행이 성능에 미치는 영향이 최소화됩니다. SQL Server는 인덱스 변경 내용을 자동으로 유지하므로 OLTP 변경 내용은 항상 분석을 위해 최신 상태로 유지됩니다. 이 디자인에서는 최신 데이터에서 실시간으로 분석을 실행하는 것이 가능하고 유용합니다. 디스크 기반 테이블과 메모리 최적화 테이블 모두에서 작동합니다.
예제 시작하기
실시간 분석으로 시작하는 방법은 다음과 같습니다.
분석에 필요한 데이터가 포함된 운영 스키마의 테이블을 식별합니다.
각 테이블에 대해 OLTP 워크로드에서 주로 기존 분석 속도를 높이기 위해 설계된 모든 B-트리 인덱스를 삭제합니다. 이를 단일 columnstore 인덱스로 대체합니다. 유지 관리할 인덱스가 적기 때문에 OLTP 워크로드의 전반적인 성능을 향상시킬 수 있습니다.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;메모리 내 테이블의 columnstore 인덱스를 사용하면 메모리 내 OLTP 및 메모리 내 columnstore 기술을 통합하고 운영 분석을 통해 OLTP 및 분석 워크로드 모두에 고성능을 제공할 수 있습니다. 메모리 내 테이블의 columnstore 인덱스에는 모든 열이 포함되어야 합니다.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON ); GO
이제 애플리케이션을 변경하지 않고도 실시간 운영 분석을 실행할 준비가 완료되었습니다. 분석 쿼리는 columnstore 인덱스에 대해 실행되고 OLTP 작업은 OLTP B-트리 인덱스에 대해 계속 실행됩니다. OLTP 워크로드는 계속 수행되지만 columnstore 인덱스를 유지하기 위해 약간의 추가 오버헤드가 발생합니다. 다음 섹션에서 성능 최적화를 참조하세요.
참고 항목
설명서는 인덱스를 지칭할 때 B-트리라는 용어를 사용합니다. rowstore 인덱스에서 데이터베이스 엔진은 B+ 트리를 구현합니다. 이는 columnstore 인덱스나 메모리 최적화 테이블 인덱스에는 적용되지 않습니다. 자세한 내용은 SQL Server 및 Azure SQL 인덱스 아키텍처 및 디자인 가이드를 참조하세요.
블로그 게시물
실시간 운영 분석에 대해 자세히 알아보려면 다음 블로그 게시물을 읽어 보세요. 블로그 게시물을 먼저 살펴보면 성능 팁 섹션을 이해하는 것이 더 쉬울 수 있습니다.
비디오
데이터 노출 비디오 시리즈에서는 일부 기능 및 고려 사항에 대해 자세히 설명합니다.
- 1부: Azure SQL에서 HTAP(실시간 운영 분석)를 사용하도록 설정하는 방법
- 2부: 운영 분석을 사용하여 기존 데이터베이스 및 애플리케이션 최적화
- 3부: Window Functions를 사용하여 운영 분석을 만드는 방법
성능 팁 #1: 필터링된 인덱스를 사용하여 쿼리 성능 향상
실시간 운영 분석을 실행하면 OLTP 워크로드의 성능에 영향을 미칠 수 있습니다. 이 영향은 최소화되어야 합니다. 예제 A 는 필터링된 인덱스를 사용하여 트랜잭션 워크로드에 대한 비클러스터형 columnstore 인덱스의 영향을 최소화하는 동시에 실시간으로 분석을 제공하는 방법을 보여 줍니다.
운영 워크로드에서 비클러스터형 columnstore 인덱스 유지 관리 오버헤드를 최소화하려면 필터링된 조건을 사용하여 웜 또는 느린 변경 데이터에 대해서만 비클러스터형 columnstore 인덱스를 만들 수 있습니다. 예를 들어 주문 관리 애플리케이션에서 이미 배송된 주문에 대해 비클러스터형 columnstore 인덱스를 만들 수 있습니다. 주문이 배송되면 거의 변경되지 않으므로 웜 데이터로 간주할 수 있습니다. 필터링된 인덱스를 사용하면 비클러스터형 columnstore 인덱스의 데이터에는 더 적은 업데이트가 필요하므로 트랜잭션 워크로드에 미치는 영향이 줄어듭니다.
분석 쿼리는 실시간 분석을 제공하기 위해 필요에 따라 웜 데이터와 핫 데이터 모두에 투명하게 액세스합니다. 운영 워크로드의 상당 부분이 '핫' 데이터를 터치하는 경우 해당 작업에 columnstore 인덱스의 추가 유지 관리가 필요하지 않습니다. 모범 사례는 필터링된 인덱스 정의에 사용되는 열에 rowstore 클러스터형 인덱스가 있는 것입니다. SQL Server는 클러스터형 인덱스를 사용하여 필터링된 조건을 충족하지 않는 행을 빠르게 검색합니다. 이 클러스터형 인덱스가 없으면 분석 쿼리의 성능을 크게 저하시킬 수 있는 이러한 행을 찾기 위해 rowstore 테이블의 전체 검색을 수행해야 합니다. 클러스터형 인덱스가 없는 경우 이러한 행을 식별하기 위해 보완 필터링된 비클러스터형 B-트리 인덱스를 만들 수 있지만 비클러스터형 B-트리 인덱스를 통해 많은 행에 액세스하는 데 비용이 많이 들기 때문에 권장되지 않습니다.
참고 항목
필터링된 비클러스터형 columnstore 인덱스는 디스크 기반 테이블에서만 지원됩니다. 메모리 최적화 테이블에서 지원되지 않습니다.
예제 A: B-트리 인덱스에서 핫 데이터 액세스, columnstore 인덱스에서 웜 데이터
이 예제에서는 필터링된 조건(accountkey > 0)을 사용하여 columnstore 인덱스에 있을 행을 설정합니다. 자주 변경되는 “핫” 데이터는 B+ 트리 인덱스에서 액세스하고 보다 안정적인 “웜” 데이터는 columnstore 인덱스에서 액세스하도록 필터링된 조건 및 후속 쿼리를 디자인하는 것이 목적입니다.

참고 항목
쿼리 최적화 프로그램에서는 경우에 따라 쿼리 계획에 대해 columnstore 인덱스를 선택할 수 있습니다. 쿼리 최적화 프로그램에서 필터링된 columnstore 인덱스를 선택하면 columnstore 인덱스의 행과 필터링된 조건을 충족하지 않는 행을 투명하게 결합하여 실시간 분석을 허용합니다. 이는 인덱스에 있는 행으로 자신을 제한하는 쿼리에서만 사용할 수 있는 일반 비클러스터형 필터링 인덱스와 다릅니다.
--Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
Customername nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50));
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fulfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
where orderstatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT top 5 customername, sum (PurchasePrice)
FROM orders
WHERE purchaseprice > 100.0
Group By customername;
분석 쿼리는 다음 쿼리 계획을 사용하여 실행됩니다. 필터링된 조건을 충족하지 않는 행은 클러스터형 B-트리 인덱스를 통해 액세스되는 것을 볼 수 있습니다.

자세한 내용은 블로그: 필터링된 비클러스터형 columnstore 인덱스입니다.
성능 팁 2: 분석을 Always On 읽기 가능한 보조로 오프로드
필터링된 columnstore 인덱스를 사용하여 columnstore 인덱스 유지 관리를 최소화할 수 있지만 분석 쿼리에는 여전히 운영 워크로드 성능에 영향을 주는 많은 컴퓨팅 리소스(CPU, I/O, 메모리)가 필요할 수 있습니다. 업무에 중요한 워크로드에는 대부분 Always ON 구성을 사용하는 것이 좋습니다. 이 구성에서는 읽기 가능한 보조 복제본으로 오프로드하여 분석 실행의 영향을 제거할 수 있습니다.
성능 팁 3: 델타 행 그룹에서 핫 데이터를 유지하여 인덱스 조각화 줄이기
columnstore 인덱스가 있는 테이블은 워크로드가 압축된 행을 업데이트/삭제하는 경우 크게 조각화될 수 있습니다(즉, 삭제된 행). 조각화된 columnstore 인덱스로 인해 메모리/스토리지의 비효율적인 사용이 발생합니다. 리소스를 비효율적으로 사용하는 것 외에도 추가 I/O 및 결과 집합에서 삭제된 행을 필터링해야 하므로 분석 쿼리 성능에 부정적인 영향을 줍니다.
삭제된 행은 REORGANIZE 명령을 사용하여 인덱스 조각 모음을 실행하거나 전체 테이블 또는 영향을 받는 파티션에서 columnstore 인덱스를 다시 작성할 때까지 물리적으로 제거되지 않습니다. 인덱스 REORGANIZE 및 REBUILD 둘 다 워크로드에 사용될 수 있는 리소스를 차지하는 부담이 큰 작업입니다. 또한 행이 너무 일찍 압축된 경우 업데이트로 인해 압축 오버헤드가 낭비되므로 여러 번 압축해야 할 수 있습니다.
COMPRESSION_DELAY 옵션을 사용하여 인덱스 조각화를 최소화할 수 있습니다.
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY. The columnstore index will keep the rows in closed delta rowgroup for 100 minutes
-- after it has been marked closed
CREATE NONCLUSTERED COLUMNSTORE index t_colstor_cci on t_colstor (accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION= COLUMNSTORE, COMPRESSION_DELAY = 100);
자세한 내용은 블로그: 압축 지연을 참조하세요.
권장 모범 사례는 다음과 같습니다.
삽입/쿼리 워크로드: 워크로드가 주로 데이터를 삽입하고 쿼리하는 경우 기본 COMPRESSION_DELAY(0)가 권장되는 옵션입니다. 새로 삽입된 행은 단일 델타 행 그룹에 100만 개의 행이 삽입되면 압축됩니다.
이러한 워크로드의 몇 가지 예는 웹 애플리케이션에서 선택 패턴을 분석해야 하는 경우 (a) 기존의 DW 워크로드(b) 선택 스트림 분석입니다.OLTP 워크로드: 워크로드가 DML이 많은 경우(즉, 업데이트, 삭제 및 삽입이 많이 혼합된 경우) DMV
sys. dm_db_column_store_row_group_physical_stats를 검사하여 columnstore 인덱스 조각화를 볼 수 있습니다. 최근 압축된 행 그룹에서 > 10% 행이 삭제된 것으로 표시되는 경우 COMPRESSION_DELAY 옵션을 사용하여 행이 압축될 때 시간 지연을 추가할 수 있습니다. 예를 들어 워크로드의 경우 새로 삽입된 항목이 60분 동안 '핫'(즉, 여러 번 업데이트됨)으로 유지되는 경우 COMPRESSION_DELAY를 60으로 선택해야 합니다.
대부분의 고객은 아무 것도 할 필요가 없습니다. 옵션의 COMPRESSION_DELAY 기본값이 해당 옵션에 대해 작동해야 합니다.
사전 사용자의 경우 다음 쿼리를 실행하고 지난 7일 동안 삭제된 행의 %를 수집하는 것이 좋습니다.
SELECT row_group_id,cast(deleted_rows as float)/cast(total_rows as float)*100 as [% fragmented], created_time
FROM sys. dm_db_column_store_row_group_physical_stats
WHERE object_id = object_id('FactOnlineSales2')
AND state_desc='COMPRESSED'
AND deleted_rows>0
AND created_time > GETDATE() - 7
ORDER BY created_time DESC;
압축된 행 그룹의 삭제된 행 수가 20%이면 이전 행 그룹에서 > 5% 변형(콜드 행 그룹 < 이라고 함) 집합 COMPRESSION_DELAY = (youngest_rowgroup_created_time - current_time)로 고원화됩니다. 이 방법은 안정적이고 상대적으로 동질적인 워크로드에서 가장 잘 작동합니다.