전체 텍스트 검색
적용 대상: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
SQL Server와 Azure SQL Database의 전체 텍스트 검색을 사용하면 사용자와 애플리케이션이 SQL Server 테이블의 문자 기반 데이터에 대해 전체 텍스트 쿼리를 실행할 수 있습니다.
기본 작업
이 문서에서는 전체 텍스트 검색의 개요를 제공하고 해당 구성 요소 및 해당 아키텍처에 대해 설명합니다. 바로 시작하려면 기본 작업은 다음과 같습니다.
전체 텍스트 검색은 SQL Server 데이터베이스 엔진의 선택적 구성 요소입니다. SQL Server를 설치할 때 전체 텍스트 검색을 선택하지 않은 경우 SQL Server 설치 프로그램을 다시 실행하여 추가합니다.
개요
전체 텍스트 인덱스에는 테이블에 하나 이상의 문자 기반 열이 포함됩니다. 이러한 열은 char, varchar,nchar, nvarchar, text, ntext, image, xml 또는 varbinary(max) 및 FILESTREAM과 같은 데이터 형식을 가질 수 있습니다. 각 전체 텍스트 인덱스는 테이블에서 하나 이상의 열을 인덱싱하고 각 열은 특정 언어를 사용할 수 있습니다.
전체 텍스트 쿼리는 영어와 일본어 같은 특정 언어의 규칙을 기준으로 단어와 구에 적용되어 전체 텍스트 인덱스의 텍스트 데이터에 대해 언어 검색을 수행합니다. 전체 텍스트 쿼리에는 간단한 단어와 구 또는 여러 형식의 단어 또는 구가 포함될 수 있습니다. 전체 텍스트 쿼리는 하나 이상의 일치(적중이라고도 함)가 포함된 모든 문서를 반환합니다. 대상 문서에 전체 텍스트 쿼리에서 지정된 모든 용어가 포함되어 있고 일치하는 용어 사이의 거리와 같은 다른 검색 조건을 충족할 때 일치가 발생합니다.
전체 텍스트 검색 쿼리
열이 전체 텍스트 인덱스에 추가된 후 사용자 및 애플리케이션은 열의 텍스트에서 전체 텍스트 쿼리를 실행할 수 있습니다. 이러한 쿼리는 다음 중 하나를 검색할 수 있습니다.
- 하나 이상의 특정 단어 또는 구(단순 용어)
- 특정 텍스트로 시작하는 단어 또는 구(접두사 용어)
- 특정 단어의 굴절형(생성 단어)
- 다른 단어 또는 다른 구와 근접한 단어 또는 구 검색(근접 용어)
- 특정 단어의 동의어 형태(동의어 사전)
- 가중치를 사용하는 단어나 구(가중치 단어)
전체 텍스트 쿼리는 대/소문자를 구분하지 않습니다. 예를 들어 Aluminum 또는 aluminum을 검색하면 동일한 결과가 반환됩니다.
전체 텍스트 쿼리는 Transact-SQL 조건자(CONTAINS 및 FREETEXT)와 함수(CONTAINSTABLE 및 FREETEXTTABLE)의 작은 집합을 사용합니다. 그러나 지정된 비즈니스 시나리오의 검색 목표는 전체 텍스트 쿼리의 구조에 영향을 줍니다. 예시:
전자 상거래 웹 사이트에서 제품 검색:
SELECT product_id FROM products WHERE CONTAINS (product_description, '"Snap Happy 100EZ" OR FORMSOF(THESAURUS,"Snap Happy") OR "100EZ"') AND product_cost < 200;SQL Server 작업 경험이 있는 구직자를 찾는 채용 시나리오:
SELECT candidate_name, SSN FROM candidates WHERE CONTAINS (candidate_resume, '"SQL Server"') AND candidate_division = 'DBA';
자세한 내용은 전체 텍스트 검색을 사용한 쿼리를 참조하세요.
전체 텍스트 검색 쿼리와 LIKE 조건자 비교
전체 텍스트 검색과 달리 LIKE Transact-SQL 조건자는 문자 패턴에 대해서만 적용됩니다. 또한 LIKE 조건자는 서식 있는 LIKE이진 데이터를 쿼리하는 데 사용할 수도 없습니다. 특히 구조화되지 않은 많은 텍스트 데이터에 대한 LIKE 쿼리는 동일한 데이터에 대한 전체 텍스트 쿼리보다 훨씬 느립니다. 수백만 개의 텍스트 데이터 행에 대해 LIKE 쿼리를 실행하면 결과가 반환되기까지 몇 분이 걸릴 수 있지만 같은 데이터에 대해 전체 텍스트 쿼리를 실행하면 반환되는 행 수에 따라 몇 초 내에 완료됩니다.
전체 텍스트 검색 아키텍처
전체 텍스트 검색 아키텍처는 다음과 같은 프로세스로 구성됩니다.
SQL Server 프로세스 (
sqlservr.exe)필터 디먼 호스트 프로세스 (
fdhost.exe).보안상의 이유로 별도의 프로세스에서 로드된 필터는 필터 디먼 호스트를 호출합니다. FDHOST 시작 관리자 서비스(
MSSQLFDLauncher)가fdhost.exe프로세스를 만들고 FDHOST 시작 관리자 서비스 계정의 보안 자격 증명으로 실행합니다. 따라서 FDHOST 시작 관리자 서비스는 전체 텍스트 인덱싱 및 전체 텍스트 쿼리 작동을 위해 실행 중이어야 합니다. 이 서비스의 서비스 계정을 설정하는 방법에 대한 자세한 내용은 전체 텍스트 필터 디몬 시작 관리자의 서비스 계정 설정을 참조하세요.
이 두 프로세스에는 전체 텍스트 검색 아키텍처의 구성 요소가 포함됩니다. 이러한 구성 요소와 해당 관계는 다음 그림에 요약되어 있습니다. 구성 요소는 그림 다음에 설명되어 있습니다.
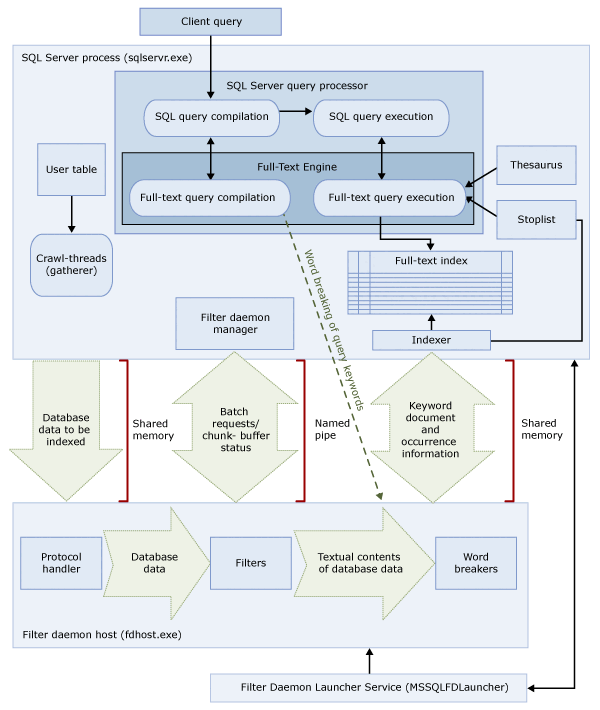
SQL Server 프로세스
SQL Server 프로세스는 전체 텍스트 검색에 다음 구성 요소를 사용합니다.
| 구성 요소 | 설명 |
|---|---|
| 사용자 테이블 | 이러한 테이블에는 전체 텍스트 인덱싱할 데이터가 포함됩니다. |
| 전체 텍스트 gatherer | 전체 텍스트 수집기는 전체 텍스트 크롤링 스레드에서 작동합니다. 이 구성 요소는 전체 텍스트 카탈로그를 모니터링하고 전체 텍스트 인덱스 채우기를 예약 및 수행합니다. |
| 동의어 사전 파일 | 이 파일은 검색어의 동의어를 포함합니다. 자세한 내용은 전체 텍스트 검색을 위한 동의어 사전 파일 구성 및 관리를 참조하세요. |
| 중지 목록 개체 | 중지 목록 개체에는 검색에 유용하지 않은 일반적인 단어 목록이 포함되어 있습니다. 자세한 내용은 전체 텍스트 검색에 사용할 중지 단어와 중지 목록 구성 및 관리를 참조하세요. |
| SQL Server 쿼리 프로세서 | 쿼리 프로세서는 SQL 쿼리를 컴파일하고 실행합니다. SQL 쿼리에 전체 텍스트 검색 쿼리가 포함된 경우 해당 쿼리는 컴파일 및 실행 중에 전체 텍스트 엔진으로 전송됩니다. 쿼리 결과는 전체 텍스트 인덱스와 일치합니다. |
| 전체 텍스트 엔진 | SQL Server의 전체 텍스트 엔진은 쿼리 프로세서와 완전히 통합됩니다. 전체 텍스트 엔진은 전체 텍스트 쿼리를 컴파일하고 실행합니다. 쿼리 실행의 일부인 전체 텍스트 엔진은 동의어 사전과 중지 목록에서 입력을 수신할 수 있습니다. |
| 인덱스 기록기(인덱서) | 인덱스 작성기는 인덱싱된 토큰을 저장하는 데 사용되는 구조를 빌드합니다. |
| 필터 디먼 관리자 | 필터 데몬 관리자는 전체 텍스트 엔진 필터 데몬 호스트의 상태를 모니터링합니다. |
필터 디먼 호스트 프로세스
필터 데몬 호스트는 전체 텍스트 엔진에 의해 시작되는 프로세스로, 테이블 데이터의 액세스, 필터링 및 단어 분리, 그리고 쿼리 입력의 단어 분리 및 형태소 분석을 담당하는 다음과 같은 전체 텍스트 검색 구성 요소를 실행합니다.
필터 디먼 호스트의 구성 요소는 다음과 같습니다.
| 구성 요소 | 설명 |
|---|---|
| 프로토콜 처리기 | 이 구성 요소는 추가 처리를 위해 메모리에서 데이터를 가져오고 지정된 데이터베이스의 사용자 테이블에서 데이터에 액세스합니다. 프로토콜 처리기가 수행해야 하는 기능 중 하나는 전체 텍스트 인덱싱되는 열에서 데이터를 수집하고 필요에 따라 필터링과 단어 분리기를 적용하는 필터 데몬 호스트에 이 데이터를 전달하는 것입니다. |
| 필터 | 일부 데이터 형식은 varbinary, varbinary(max), image, 또는 xml 열의 데이터를 포함하여 문서의 데이터를 전체 텍스트 인덱싱하기 전에 필터링해야 합니다. 지정된 문서에 사용되는 필터는 해당 문서 유형에 따라 달라집니다. 예를 들어 Microsoft Word (.doc) 문서, Microsoft Excel (.xls) 문서 및 XML (.xml) 문서에 다양한 필터가 사용됩니다. 그런 다음 필터는 문서에서 텍스트 청크를 추출하여 포함된 서식을 제거하고 텍스트 및 잠재적인 텍스트 위치에 대한 정보를 유지합니다. 결과는 텍스트 정보의 스트림입니다. 자세한 내용은 고급 분석 확장 구성 및 관리를 참조하세요. |
| 단어 분리기 및 형태소 분석기 | 단어 분리기는 지정된 언어의 어휘 규칙을 기준으로 단어 경계(단어 분리)를 찾는 언어별 구성 요소입니다. 각 단어 분리기는 동사를 결합하고 형태 변화 확장을 수행하는 언어별 형태소 분석기 구성 요소와 연결됩니다. 인덱싱할 때 필터 데몬 호스트는 단어 분리기와 형태소 분석기를 사용하여 지정된 테이블 열의 텍스트 데이터에 대해 언어 분석을 수행합니다. 전체 텍스트 인덱스의 테이블 열과 연결된 언어에 따라 열을 인덱싱하는 데 사용되는 단어 분리기와 형태소 분석기가 결정됩니다. 자세한 내용은 검색을 위해 단어 분리기와 형태소 분석기 구성 및 관리(SQL Sever)를 참조하세요. |
SQL Server 2012(11.x)는 미국 영어(LCID 1033) 및 영국 영어(LCID 2057)에 대해 새로운 버전의 단어 분리기 및 형태소 분석기를 설치합니다. 그러나 이전 동작을 유지하려는 경우 이러한 구성 요소의 이전 버전으로 전환할 수 있습니다. 자세한 내용은 미국 영어 및 영국 영어에 사용되는 단어 분리기 변경을 참조하세요.
전체 텍스트 검색 처리
전체 텍스트 검색은 전체 텍스트 엔진에 의해 제공됩니다. 전체 텍스트 엔진은 인덱싱 지원과 쿼리 지원의 두 가지 역할을 수행합니다.
전체 텍스트 인덱싱 프로세스
전체 텍스트 채우기(크롤링이라고도 함)가 시작되면 전체 텍스트 엔진은 대규모 데이터 일괄 처리를 메모리에 푸시하고 필터 디먼 호스트에 알립니다. 호스트는 데이터를 필터링하고 데이터의 단어를 분리한 후 변환된 데이터를 반전된 단어 목록으로 변환합니다. 그런 다음 전체 텍스트 검색은 단어 목록에서 변환된 데이터를 끌어오고, 데이터를 처리하여 중지 단어를 제거하며, 일괄 처리에 대한 단어 목록을 하나 이상의 반전된 인덱스로 유지합니다.
varbinary(max) 또는 이미지 열에 저장된 데이터를 인덱싱할 때 인터페이스를 구현하는 필터는 해당 데이터에 지정된 파일 형식 (IFilter)에 따라 텍스트를 추출합니다. 경우에 따라 필터 구성 요소는 메모리로 푸시되는 대신 varbinary(max) 또는 이미지 데이터를 filterdata 폴더에 기록해야 합니다.
수집된 텍스트 데이터는 처리 중에 단어 분리기를 통과하여 텍스트가 개별 토큰 또는 키워드로 분리됩니다. 토큰화에 사용되는 언어는 열 수준에서 지정되거나 필터 구성 요소로 varbinary(max), image 또는 xml 데이터 내에서 식별할 수 있습니다.
추가 처리를 수행하여 중지 단어를 제거하고 전체 텍스트 인덱스 또는 인덱스 조각에 저장되기 전에 토큰을 정규화할 수 있습니다.
채우기가 완료되면 인덱스 조각을 하나의 마스터 전체 텍스트 인덱스로 병합하는 최종 병합 프로세스가 트리거됩니다. 이렇게 하면 많은 인덱스 조각이 아닌 마스터 인덱스만 쿼리하면 되기 때문에 쿼리 성능이 향상되고 관련성 순위에 더 나은 채점 통계가 사용될 수 있습니다.
전체 텍스트 쿼리 프로세스
쿼리 프로세서는 쿼리의 전체 텍스트 부분을 처리하기 위해 전체 텍스트 엔진에 전달합니다. 전체 텍스트 엔진은 단어 분리를 수행하고, 필요에 따라 동의어 사전 확장, 형태소 분석 및 중지 단어(의미 없는 단어) 처리를 수행합니다. 그런 다음 쿼리의 전체 텍스트 부분은 주로 SQL 연산자의 형태인 STVF(스트리밍 테이블 반환 함수)로 표시됩니다. 쿼리를 실행하는 동안 이러한 STVF는 반전된 인덱스에 액세스하여 올바른 결과를 검색합니다. 결과는 이 시점에서 클라이언트에 반환되거나 클라이언트로 반환되기 전에 추가로 처리됩니다.
전체 텍스트 인덱스 아키텍처
전체 텍스트 인덱스의 정보는 전체 텍스트 엔진에서 특정 단어 또는 단어 조합을 신속하게 검색할 수 있는 전체 텍스트 쿼리를 컴파일하는 데 사용됩니다. 전체 텍스트 인덱스는 데이터베이스 테이블의 하나 이상의 열 내에 중요한 단어 및 해당 위치의 정보를 저장합니다. 전체 텍스트 인덱스는 SQL Server용 전체 텍스트 검색 엔진에서 작성 및 유지 관리하는 특수한 유형의 토큰 기반 인덱스입니다. 전체 텍스트 인덱스를 빌드하는 프로세스는 다른 유형의 인덱스를 빌드하는 것과 다릅니다. 전체 텍스트 엔진은 특정 행에 저장된 값을 기반으로 B-트리 구조를 생성하는 대신 인덱싱되는 텍스트의 개별 토큰을 기반으로 반전된 누적 압축 인덱스 구조를 빌드합니다. 전체 텍스트 인덱스의 크기는 SQL Server 인스턴스가 실행 중인 컴퓨터의 사용 가능한 메모리 리소스에 의해서만 제한됩니다.
전체 텍스트 인덱스는 이전 버전의 SQL Server에서 파일 시스템에 있었던 것과는 달리 SQL Server 2008(10.0.x)부터는 데이터베이스 엔진과 통합됩니다. 새 데이터베이스의 경우 전체 텍스트 카탈로그는 이제 어떤 파일 그룹에도 속하지 않는 가상 개체이며, 전체 텍스트 인덱스 그룹을 참조하는 논리적 개념일 뿐입니다. 그러나 SQL Server 2005(9.x) 데이터베이스를 업그레이드하는 동안 데이터 파일이 포함된 모든 전체 텍스트 카탈로그에 대해 새 파일 그룹이 만들어집니다. 이에 대한 자세한 내용은 전체 텍스트 검색 업그레이드를 참조하세요.
테이블당 한 개의 전체 텍스트 인덱스만 허용합니다. 테이블에 전체 텍스트 인덱스를 만드는 경우 테이블에는 하나의 고유한 non-null 열이 있어야 합니다. char, varchar, nchar, nvarchar, text, ntext, image, xml, varbinary 및 varbinary(max) 유형의 열에 전체 텍스트 인덱스를 빌드할 수 있습니다. 데이터 형식이 varbinary, varbinary(max), image또는 xml 인 열에 대한 전체 텍스트 인덱스를 만들려면 유형 열을 지정해야 합니다. 형식 열은 각 행에 문서의 파일 확장명(.doc, .pdf, .xls 등)을 저장하는 테이블 열입니다.
전체 텍스트 인덱스 구조
전체 텍스트 인덱스의 구조를 잘 알게 되면 전체 텍스트 엔진의 작동 원리를 이해하는 데 도움이 됩니다. 이 항목에서 예제 테이블로 사용하는 Document 테이블은 AdventureWorks2022에서 발췌한 것입니다. 이 발췌문에서는 DocumentID 열과 Title 열 두 개와 표의 행 세 개만 보여줍니다.
이 예에서는 Title 열에 대해 전체 텍스트 인덱스를 만들었다고 가정합니다.
| DocumentID | 타이틀 |
|---|---|
1 |
Crank Arm and Tire Maintenance |
2 |
Front Reflector Bracket and Reflector Assembly 3 |
3 |
Front Reflector Bracket Installation |
예를 들어 조각 1을 보여주는 다음 표에서는 Document 테이블의 Title 열에서 만든 전체 텍스트 인덱스의 내용을 보여줍니다. 전체 텍스트 인덱스에는 이 표에 표시되어 있는 것보다 많은 정보가 포함되어 있습니다. 이 표는 전체 텍스트 인덱스를 논리적으로 표현한 것이며 설명 목적으로만 제공됩니다. 행은 디스크 사용량을 최적화하기 위해 압축된 형식으로 저장됩니다.
데이터가 원본 문서에서 반전되었습니다. 왜냐하면 키워드가 문서 ID로 매핑되기 때문입니다. 이러한 이유로 전체 텍스트 인덱스는 종종 반전된 인덱스라고 합니다.
또한 and 키워드가 전체 텍스트 인덱스에서 제거되었습니다. and 는 중지 단어이며 전체 텍스트 인덱스에서 중지 단어를 제거하면 디스크 공간이 크게 절약되어 쿼리 성능이 향상될 수 있기 때문에 이 작업이 수행됩니다. 중지 단어에 대한 자세한 내용은 전체 텍스트 검색에 사용할 중지 단어와 중지 목록 구성 및 관리를 참조하세요.
조각 1
| 키워드 | ColId | DocId | 발생 |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 6 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Front |
1 | 3 | 1 |
Reflector |
6 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Bracket |
1 | 3 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Installation |
1 | 3 | 4 |
Keyword 열에는 인덱싱할 때 추출한 단일 토큰이 표시됩니다. 단어 분리기는 무엇이 토큰을 구성하는지 결정합니다.
ColId 열에는 전체 텍스트 인덱싱된 특정 열에 해당하는 값이 포함됩니다.
DocId 열에는 전체 텍스트 인덱싱된 테이블의 특정 전체 텍스트 키 값에 매핑되는 8 바이트 정수 값이 포함됩니다. 이 매핑은 전체 텍스트 키가 정수 데이터 형식이 아닌 경우에만 필요합니다. 이러한 경우 전체 텍스트 키 값과 DocId 값 간의 매핑은 DocId Mapping 매핑 테이블이라는 별도의 테이블에서 유지관리됩니다. 이러한 매핑을 쿼리하려면 sp_fulltext_keymappings 시스템 저장 프로시저를 사용합니다. 검색 조건을 충족하려면 위 테이블의 DocId 값을 DocId 매핑 테이블과 조인하여 쿼리 중인 기본 테이블에서 행을 검색해야 합니다. 기본 테이블의 전체 텍스트 키 값이 정수 형식인 경우 이 값은 DocId로 직접 사용되며 매핑이 필요하지 않습니다. 따라서 정수 전체 텍스트 키 값을 사용하면 전체 텍스트 쿼리 최적화에 도움이 될 수 있습니다.
Occurrence 열에는 정수 값이 포함됩니다. 각 DocId 값의 경우 해당 DocId 내에서 특정 키워드의 상대 단어 오프셋에 해당하는 발생 값 목록이 있습니다. 발생 값은 구 또는 근접 일치를 결정하는 데 유용하며, 예를 들어 구에는 수적으로 인접한 발생 값이 있습니다. 또한 이는 관련성 점수를 계산하는 데 유용하며, 예를 들어 DocId의 키워드 발생 횟수를 채점에 사용할 수 있습니다.
전체 텍스트 인덱스 조각
논리적 전체 텍스트 인덱스는 일반적으로 여러 개의 내부 테이블로 분할됩니다. 이러한 각 내부 테이블을 전체 텍스트 인덱스 조각이라고 부릅니다. 이러한 조각 중 일부는 비교적 최신의 데이터를 포함할 수도 있습니다. 예를 들어 사용자가 DocId가 3이고 테이블이 자동 변경 추적되는 다음 행을 업데이트하면 새 조각이 만들어집니다.
| DocumentID | 타이틀 |
|---|---|
3 |
Rear Reflector |
다음 예제에서는 조각 2를 보여 줍니다. 조각은 조각 1에 비해 DocId 3에 대한 최신 데이터를 포함합니다. 따라서 사용자가 Rear Reflector 를 쿼리할 때 조각 2의 데이터가 DocId 3에 사용됩니다. 각 조각은 sys.fulltext_index_fragments 카탈로그 뷰를 사용하여 쿼리할 수 있는 생성 타임스탬프로 표시됩니다.
조각 2
| 키워드 | ColId | DocId | Occ |
|---|---|---|---|
Rear |
1 | 3 | 1 |
Reflector |
1 | 3 | 2 |
조각 2에서 볼 수 있듯이 전체 텍스트 쿼리에서는 각 조각을 내부적으로 쿼리하고 이전 항목을 무시해야 합니다. 따라서 전체 텍스트 인덱스에 전체 텍스트 인덱스 조각이 너무 많을 경우 쿼리 성능이 크게 저하됩니다. 조각 수를 줄이려면 ALTER FULLTEXT CATALOG Transact-SQL 문의 REORGANIZE 옵션을 사용하여 전체 텍스트 카탈로그를 다시 구성합니다. 이 문은 조각을 더 큰 단일 조각으로 병합하고 전체 텍스트 인덱스에서 사용되지 않는 항목을 모두 제거하는 마스터 병합을 수행합니다.
다시 구성한 후 예제 인덱스에는 다음 행이 포함됩니다.
| 키워드 | ColId | DocId | Occ |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 6 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Rear |
1 | 3 | 1 |
Reflector |
6 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
전체 텍스트 인덱스와 일반 SQL Server 인덱스의 차이점:
| 전체 텍스트 인덱스 | 일반 SQL Server 인덱스 |
|---|---|
| 테이블당 한 개의 전체 텍스트 인덱스만 허용합니다. | 테이블당 여러 개의 일반 인덱스를 허용합니다. |
| 전체 텍스트 인덱스에 데이터를 추가하는 채우기는 일정 예약 또는 특정 요청을 통해 수행할 수 있으며 새 데이터를 추가하면 자동으로 수행됩니다. | 기반 데이터가 삽입, 업데이트 또는 삭제될 때 자동으로 업데이트됩니다. |
| 동일한 데이터베이스 내에서 하나 이상의 전체 텍스트 카탈로그로 그룹화됩니다. | 그룹 아님. |
전체 텍스트 검색의 언어 구성 요소 및 언어 지원
전체 텍스트 검색에서 영어, 스페인어, 중국어, 일본어, 아랍어, 벵골어 및 힌디어를 포함하여 거의 50개의 언어를 지원합니다. 지원되는 전체 텍스트 언어의 전체 목록은 sys.fulltext_languages를 참조하세요. 전체 텍스트 인덱스에 있는 각 열은 전체 텍스트 검색에서 지원하는 언어에 해당하는 Windows LCID(로캘 ID)와 연결됩니다. 예를 들어 LCID 1033은 미국 영어와 동일하고 LCID 2057은 영국 영어와 동일합니다. 지원되는 각 전체 텍스트 언어의 경우 SQL Server는 해당 언어에 저장된 전체 텍스트 데이터의 인덱싱 및 쿼리를 지원하는 언어 구성 요소를 제공합니다.
언어별 구성 요소에는 다음이 포함됩니다.
| 구성 요소 | 설명 |
|---|---|
| 단어 분리기 및 형태소 분석기 | 단어 분리기는 지정된 언어의 어휘 규칙을 기준으로 단어 경계(단어 분리)를 찾습니다. 각 단어 분리기는 동일한 언어의 동사를 결합하는 형태소 분석기와 연결됩니다. 자세한 내용은 검색을 위해 단어 분리기와 형태소 분석기 구성 및 관리(SQL Sever)를 참조하세요. |
| 중지 목록. | 기본 중지 단어 집합(의미 없는 단어라고도 함)이 포함된 시스템 중지 목록이 제공됩니다. 중지 단어 는 검색에 도움이 되지 않고 전체 텍스트 쿼리에서 무시되는 단어입니다. 예를 들어 영어 로컬 단어의 경우 a, and, is 및 the 와 같은 단어는 중지 단어로 간주됩니다. 일반적으로 동의어 사전 파일 및 중지 목록을 하나 이상 구성해야 합니다. 자세한 내용은 전체 텍스트 검색에 사용할 중지 단어와 중지 목록 구성 및 관리를 참조하세요. |
| 동의어 사전 파일 | 또한 SQL Server는 각 전체 텍스트 언어에 대한 동의어 사전 파일과 전역 동의어 사전 파일을 설치합니다. 설치된 동의어 사전 파일은 기본적으로 비어 있지만 편집하여 특정 언어 또는 비즈니스 시나리오의 동의어를 정의할 수 있습니다. 전체 텍스트 데이터에 맞게 조정된 동의어 사전을 개발하면 해당 데이터에 대한 전체 텍스트 쿼리의 범위를 효과적으로 넓힐 수 있습니다. 자세한 내용은 전체 텍스트 검색을 위한 동의어 사전 파일 구성 및 관리를 참조하세요. |
| 필터(iFilters) | varbinary(max), image 또는 xml 데이터 형식 열의 문서를 인덱싱하려면 추가 처리를 수행하는 필터가 필요합니다. 필터를 문서 종류 (.doc, .pdf, .xls, .xml 등)에 지정해야 합니다. 자세한 내용은 고급 분석 확장 구성 및 관리를 참조하세요. |
단어 분리기(및 형태소 분석기)와 필터는 필터 디먼 호스트 프로세스(fdhost.exe)에서 실행됩니다.