CREATE EXTERNAL TABLE(Transact-SQL)
외부 테이블을 만듭니다.
이 아티클에서는 원하는 SQL 제품에 대한 구문, 인수, 설명, 사용 권한 및 예제를 제공합니다.
구문 표기 규칙에 대한 자세한 내용은 Transact-SQL 구문 표기 규칙을 참조하세요.
제품 선택
다음 행에서 관심 있는 제품 이름을 선택하면 해당 제품의 정보만 표시됩니다.
* SQL Server *
개요: SQL Server
이 명령은 Hadoop 클러스터나 Azure Blob Storage에 저장된 데이터를 참조하는 Hadoop 클러스터나 Azure Blob Storage PolyBase 외부 테이블에 저장된 데이터에 액세스하는 PolyBase용 외부 테이블을 만듭니다.
적용 대상: SQL Server 2016 이상
PolyBase 쿼리에 대한 외부 데이터 원본이 있는 외부 테이블을 사용합니다. 외부 데이터 원본은 연결을 설정하고 다음과 같은 기본 사용 사례를 지원하는 데 사용됩니다.
- PolyBase를 사용하여 데이터 가상화 및 데이터 로드
-
BULK INSERT또는OPENROWSET를 통해 SQL Server 또는 SQL Database를 사용한 대량 로드 작업
CREATE EXTERNAL DATA SOURCE 및 DROP EXTERNAL TABLE도 참조하세요.
구문
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
인수
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
만들려는 테이블의 한 부분에서 세 부분으로 이루어진 이름입니다. 외부 테이블의 경우 SQL은 Hadoop 또는 Azure Blob Storage에서 참조되는 파일이나 폴더에 대한 기본 통계와 함께 메타데이터만 저장합니다. 실제 데이터가 이동되거나 SQL Server에 저장되지 않습니다.
중요
최상의 성능을 위해 외부 데이터 원본 드라이버가 세 부분으로 된 이름을 지원하는 경우 세 부분으로 된 이름을 제공하는 것이 좋습니다.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE은 열 이름, 데이터 형식, Null 허용 여부 및 데이터 정렬을 구성하는 기능을 지원합니다. 외부 테이블에 DEFAULT CONSTRAINT를 사용할 수 없습니다.
데이터 형식 및 열 수를 포함한 열 정의는 외부 파일의 데이터와 일치해야 합니다. 불일치가 있는 경우 실제 데이터를 쿼리할 때 파일 행이 거부됩니다.
LOCATION = 'folder_or_filepath'
Hadoop 또는 Azure Blob Storage의 실제 데이터에 대한 폴더 또는 파일 경로 및 파일 이름을 지정합니다. 또한 S3 호환 개체 스토리지는 SQL Server 2022(16.x)부터 지원됩니다. 위치는 루트 폴더에서 시작합니다. 루트 폴더는 외부 데이터 원본에 지정된 데이터 위치입니다.
SQL Server에서는 CREATE EXTERNAL TABLE 문이 경로 및 폴더가 없으면 만듭니다. 그런 다음, INSERT INTO를 사용하여 로컬 SQL Server 테이블에서 외부 데이터 원본으로 데이터를 내보냅니다. 자세한 내용은 PolyBase 쿼리를 참조하세요.
위치(LOCATION)를 폴더로 지정할 경우, 외부 테이블에서 선택하는 PolyBase 쿼리는 폴더 및 해당 폴더의 모든 하위 폴더에서 파일을 검색합니다. Hadoop과 마찬가지로 PolyBase도 숨겨진 폴더를 반환하지 않습니다. 또한 파일 이름이 밑줄(_) 또는 마침표(.)로 시작하는 파일을 반환하지 않습니다.
다음 이미지 예제에서는 LOCATION='/webdata/'이면 PolyBase 쿼리는 mydata.txt 및 mydata2.txt에서 행을 반환합니다.
mydata3.txt는 숨겨진 하위 폴더의 파일이므로 반환하지 않습니다. 그리고 _hidden.txt는 숨겨진 파일이므로 반환하지 않습니다.
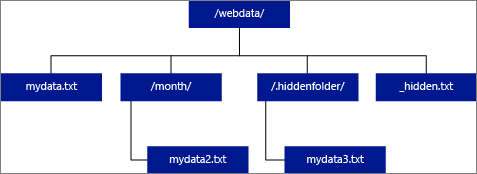
기본값을 변경하고 루트 폴더에서 읽기만 하려면 core-site.xml 구성 파일에서 <polybase.recursive.traversal> 특성을 'false'로 설정합니다. 이 파일은 SQL Server의 <SqlBinRoot>\PolyBase\Hadoop\Conf 루트 아래에 bin 있습니다. 예들 들어 C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn입니다.
DATA_SOURCE = external_data_source_name
외부 데이터 위치가 포함된 외부 데이터 원본의 이름을 지정합니다. 이 위치는 HDFS(Hadoop 파일 시스템), Azure Blob Storage 컨테이너 또는 Azure Data Lake Store입니다. 외부 데이터 원본을 만들려면 CREATE EXTERNAL DATA SOURCE를 사용합니다.
FILE_FORMAT = external_file_format_name
외부 데이터에 대한 파일 형식과 압축 방법을 저장하는 외부 파일 형식 개체의 이름을 지정합니다. 외부 파일 형식을 만들려면 CREATE EXTERNAL FILE FORMAT을 사용합니다.
여러 유사한 외부 파일에서 외부 파일 형식을 다시 사용할 수 있습니다.
거부 옵션
이 옵션은 TYPE = HADOOP인 외부 데이터 원본에서만 사용할 수 있습니다.
PolyBase가 외부 데이터 원본에서 검색하는 더티 레코드를 처리하는 방법을 결정하는 거부 매개 변수를 지정할 수 있습니다. 데이터 레코드는 실제 데이터 형식 또는 열 수가 외부 테이블의 열 정의와 일치하지 않으면 '더티'로 간주됩니다.
거부 값을 지정하거나 변경하지 않으면 PolyBase는 기본값을 사용합니다. 거부 매개 변수에 관한 이 정보는 CREATE EXTERNAL TABLE 문을 사용하여 외부 테이블을 만들 때 추가 메타데이터로 저장됩니다. 후속 SELECT 문 또는 SELECT INTO SELECT 문이 외부 데이터에서 데이터를 선택하는 경우, PolyBase는 거부 옵션을 사용하여 실제 쿼리가 실패할 때까지 거부될 수 있는 행의 개수 또는 비율을 결정합니다. 이 쿼리는 거부된 임계값이 초과될 때까지 (부분) 결과를 반환합니다. 그런 다음, 적절한 오류 메시지와 함께 실패합니다.
REJECT_TYPE = value | percentage
REJECT_VALUE 옵션이 리터럴 값으로 지정되는지 또는 백분율로 지정되는지 구체화합니다.
value
REJECT_VALUE는 백분율이 아닌 리터럴 값입니다. 쿼리는 거부된 행 수가 reject_value를 초과하면 실패합니다.
예를 들어 if REJECT_VALUE = 5 및 REJECT_TYPE = value, 5개의 행이 거부된 후 SELECT 쿼리가 실패합니다.
percentage
REJECT_VALUE는 리터럴 값이 아닌 백분율입니다. 실패한 행의 백분율이 reject_value 초과하면 쿼리가 실패합니다. 실패한 행의 백분율은 일정 간격으로 계산됩니다.
REJECT_VALUE = reject_value
쿼리가 실패할 때까지 거부될 수 있는 값 또는 행의 백분율을 지정합니다.
REJECT_TYPE = value인 경우, reject_value는 0에서 2,147,483,647 사이의 정수여야 합니다.
REJECT_TYPE = percentage인 경우, reject_value는 0에서 100 사이의 부동 소수점 수이어야 합니다.
REJECT_SAMPLE_VALUE = reject_sample_value
이 특성은 REJECT_TYPE = percentage를 지정한 경우에 필요하며 PolyBase가 거부된 행의 백분율을 다시 계산하기 전까지 검색을 시도하는 행 수를 결정합니다.
reject_sample_value 매개 변수는 0에서 2,147,483,647 사이의 정수여야 합니다.
예를 들어 REJECT_SAMPLE_VALUE = 1000인 경우, PolyBase는 외부 데이터 파일에서 행 1000개 가져오기를 시도한 후 실패한 행의 백분율을 계산합니다. 실패한 행의 백분율이 reject_value보다 작은 경우, PolyBase는 또 다른 행 1000개의 검색을 시도합니다. 계속해서 추가로 행 1000개의 가져오기를 시도한 후마다 실패한 행의 백분율을 다시 계산합니다.
참고
PolyBase는 실패한 행의 백분율을 일정 간격으로 계산하므로 실패한 행의 실제 백분율은 reject_value를 초과할 수 있습니다.
예제:
이 예제에서는 REJECT 옵션 세 개가 서로 상호 작용하는 방법을 보여 줍니다. 예를 들어 REJECT_TYPE = percentage, REJECT_VALUE = 30 및 REJECT_SAMPLE_VALUE = 100인 경우 다음과 같은 시나리오가 일어날 수 있습니다.
- PolyBase가 처음 100개 행의 검색을 시도하며, 25개가 실패하고 75개가 성공합니다.
- 실패한 행의 백분율은 25%로 계산되며, 이는 거부 값 30%보다 작습니다. 결과적으로 PolyBase는 외부 데이터 원본에서 데이터를 계속 검색합니다.
- PolyBase는 다음 100개 행의 로드를 시도합니다. 이번에는 25개 행이 성공하고 75개 행이 실패합니다.
- 실패한 행의 백분율은 50%로 다시 계산됩니다. 실패한 행의 이 백분율은 30% 거부 값을 초과했습니다.
- PolyBase 쿼리는 처음 200개 행의 반환을 시도한 후 거부된 행이 50%여서 실패합니다. PolyBase 쿼리가 거부 임계값이 초과되었음을 감지하기 전에 일치하는 행이 반환되었습니다.
REJECTED_ROW_LOCATION = 디렉터리 위치
적용 대상: SQL Server 2019 CU6 이상 버전, Azure Synapse Analytics.
거부된 행과 해당 오류 파일을 작성해야 하는 외부 데이터 원본 내 디렉터리를 지정합니다.
지정된 경로가 존재하지 않을 경우 PolyBase는 사용자를 대신하여 경로를 만듭니다. "_rejectedrows"라는 이름의 자식 디렉터리가 생성됩니다. "_" 문자는 위치 매개 변수에 명시적으로 명명되지 않는 한 다른 데이터 처리를 위해 디렉터리를 이스케이프합니다. 이 디렉터리 내에는 로드 제출 시간을 기준으로 형식(예YearMonthDay -HourMinuteSecond: )으로 만든 폴더가 20230330-173205 있습니다. 이 폴더에서 _reason 파일과 data 파일이라는 두 가지 파일에 데이터가 기록됩니다. 이 옵션은 TYPE = HADOOP인 외부 데이터 원본 및 DELIMITEDTEXT FORMAT_TYPE을 사용하는 외부 테이블에서만 사용할 수 있습니다. 자세한 내용은 CREATE EXTERNAL DATA SOURCE 및 CREATE EXTERNAL FILE FORMAT을 참조하세요.
reason 파일과 data 파일에는 모두 CTAS 문과 연결된 queryID가 있습니다. data와 reason은 별도의 파일에 있으므로 해당 파일의 접미사가 일치해야 합니다.
사용 권한
다음과 같은 권한이 필요합니다.
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT(Hadoop 및 Azure Storage 외부 데이터 원본에만 적용됨)
- CONTROL DATABASE(Hadoop 및 Azure Storage 외부 데이터 원본에만 적용됨)
CREATE EXTERNAL TABLE 명령에서 사용하는 DATABASE SCOPED CREDENTIAL에 지정된 원격 로그인에는 LOCATION 매개 변수에 지정된 외부 데이터 원본의 경로/테이블/컬렉션에 대한 읽기 원한이 있어야 합니다. 이 EXTERNAL TABLE을 사용하여 Hadoop 또는 Azure Storage 외부 데이터 원본으로 데이터를 내보내려는 경우에는, 지정된 로그인에 LOCATION에 지정된 경로에 대한 쓰기 권한이 있어야 합니다. Hadoop은 현재 SQL Server 2022(16.x)에서 지원되지 않습니다.
Azure Blob Storage 경우, Azure Portal, Azure Blob Storage 또는 ADLS Gen2 스토리지 계정에서 액세스 키 및 SAS(공유 액세스 서명)를 구성할 때는 최소한 읽기 및 쓰기 권한을 부여하도록 허용된 권한을 구성해야 합니다. 여러 폴더를 검색할 때는 목록 권한이 필요할 수도 있습니다. 또한 컨테이너와 개체 모두를 허용되는 리소스 유형으로 선택해야 합니다.
중요
ALTER ANY EXTERNAL DATA SOURCE 권한은 보안 주체에 대해 외부 데이터 원본 개체를 만들고 수정하는 권한을 부여하며, 따라서 데이터베이스의 모든 데이터베이스 범위 자격 증명에 액세스하는 권한도 부여합니다. 이 권한은 높은 수준의 권한으로 간주되어야 하므로, 시스템의 신뢰할 수 있는 보안 주체에만 부여되어야 합니다.
오류 처리
CREATE EXTERNAL TABLE 문을 실행하는 동안 PolyBase는 외부 데이터 원본에 연결을 시도합니다. 연결 시도가 실패하면 이 명령문이 실패하고 외부 테이블이 만들어지지 않습니다. PolyBase는 쿼리가 결국 실패할 때까지 연결을 다시 시도하므로 이 명령이 실패하려면 1분 이상 걸릴 수 있습니다.
설명
SELECT FROM EXTERNAL TABLE과 같은 임시 쿼리 시나리오에서 PolyBase는 외부 데이터 원본에서 검색된 행을 임시 테이블에 저장합니다. 쿼리가 완료된 후 PolyBase는 임시 테이블을 제거하고 삭제합니다. 영구적 데이터가 SQL 테이블에 저장되지 않습니다.
이와는 대조적으로 SELECT INTO FROM EXTERNAL TABLE과 같은 가져오기 시나리오에서 PolyBase는 외부 데이터 원본에서 검색된 행을 영구 데이터로 SQL 테이블에 저장합니다. 새 테이블은 PolyBase에서 외부 데이터를 검색할 때 쿼리 실행 중에 만들어집니다.
PolyBase는 쿼리 성능을 향상시키기 위해 쿼리 계산 중 일부를 Hadoop에 푸시할 수 있습니다. 이 작업을 조건자 푸시 다운이라 합니다. 이를 활성화하려면 CREATE EXTERNAL DATA SOURCE에 Hadoop 리소스 관리자 위치 옵션을 지정합니다.
동일하거나 서로 다른 외부 데이터 원본을 참조하는 많은 외부 테이블을 만들 수 있습니다.
제한 사항
외부 테이블의 데이터가 SQL Server의 직접 관리 제어를 받고 있지 않으므로 언제든지 외부 프로세스에 의해 변경 또는 제거될 수 있습니다. 따라서 외부 테이블에 대한 쿼리 결과는 결정적인 것으로 보증되지 않습니다. 즉, 외부 테이블에 대해 실행할 때마다 같은 쿼리가 서로 다른 결과를 반환할 수 있습니다. 마찬가지로 외부 데이터를 이동하거나 제거하면 쿼리가 실패할 수 있습니다.
각각 서로 다른 외부 데이터 원본을 참조하는 여러 개의 외부 테이블을 만들 수 있습니다. 서로 다른 Hadoop 데이터 원본에 대해 동시에 쿼리를 실행하는 경우 각 Hadoop 원본은 동일한 'hadoop 연결' 서버 구성 설정을 사용해야 합니다. 예를 들어 Cloudera Hadoop 클러스터 및 Hortonworks Hadoop 클러스터는 서로 다른 구성 설정을 사용하므로 이들에 대해 하나의 쿼리를 동시에 실행할 수 없습니다. 구성 설정 및 지원되는 결합에 대해서는 PolyBase 연결 구성을 참조하세요.
외부 테이블이 데이터 형식으로 사용하거나 DELIMITEDTEXT 데이터 형식으로 사용하는 CSVPARQUETDELTA경우 외부 테이블은 명령당 CREATE STATISTICS 하나의 열에 대한 통계만 지원합니다.
다음 DDL(Data Definition Language) 문은 외부 테이블에 대해 허용됩니다.
- CREATE TABLE 및 DROP TABLE
- CREATE STATISTICS 및 DROP STATISTICS
- CREATE VIEW 및 DROP VIEW
지원되지 않는 구문 및 작업:
- 외부 테이블 열에 대한 DEFAULT 제약 조건
- 삭제, 삽입 및 업데이트의 DML(데이터 조작 언어) 작업
쿼리 제한 사항
PolyBase는 32개의 동시 PolyBase 쿼리를 실행할 때 폴더당 최대 3만 3천 개의 파일을 사용할 수 있습니다. 이 최대 개수는 각 HDFS 폴더의 파일과 하위 폴더를 모두 포함합니다. 동시성 수준이 32보다 작은 경우 사용자는 33k보다 많은 파일을 포함하는 HDFS의 폴더에 대해 PolyBase 쿼리를 실행할 수 있습니다. 외부 파일 경로를 짧게 유지하고 HDFS 폴더당 30k 이하의 파일을 사용하는 것이 좋습니다. 너무 많은 파일이 참조되면 JVM(Java Virtual Machine) 메모리 부족 예외가 발생할 수 있습니다.
테이블 너비 제한 사항
SQL Server 2016의 PolyBase에는 테이블 정의에 의해 유효한 단일 행의 최대 크기를 기반으로 32KB의 행 너비 한도가 적용됩니다. 열 스키마의 합계가 32KB보다 큰 경우 PolyBase는 데이터를 쿼리할 수 없습니다.
데이터 형식 제한 사항
다음 데이터 형식은 PolyBase 외부 테이블에 사용할 수 없습니다.
geographygeometryhierarchyidimagetextnTextxml- 모든 사용자 정의 형식
데이터 원본 관련 제한 사항
Oracle
Oracle 동의어의 경우 PolyBase 사용이 지원되지 않습니다.
배열을 포함하는 MongoDB 컬렉션 외부 테이블
배열을 포함하는 MongoDB 컬렉션 외부 테이블을 만들려면 Azure Data Studio용 데이터 가상화 확장을 사용하여 MongoDB용 PolyBase ODBC 드라이버에 의해 감지된 스키마를 기준으로 CREATE EXTERNAL TABLE 문을 생성해야 합니다. 평면화 작업은 드라이버에 의해 자동으로 수행됩니다. 또는 sp_data_source_objects(Transact-SQL)를 사용하여 컬렉션 스키마(열)를 감지하고 외부 테이블을 수동으로 만들 수도 있습니다.
sp_data_source_table_columns 저장 프로시저도 MongoDB 드라이버용 PolyBase ODBC 드라이버를 통해 자동으로 평면화를 수행합니다. Azure Data Studio용 데이터 가상화 확장 및 sp_data_source_table_columns는 동일한 내부 저장 프로시저를 사용하여 외부 스키마를 쿼리합니다.
잠금
SCHEMARESOLUTION 개체에 대한 공유 잠금입니다.
보안
외부 테이블에 대한 데이터 파일은 Hadoop 또는 Azure Blob Storage에 저장됩니다. 이러한 데이터 파일은 사용자 고유의 프로세스에 의해 만들어지고 관리됩니다. 외부 데이터의 보안을 관리하는 것은 사용자의 책임입니다.
예제
A. 텍스트로 구분된 형식의 데이터를 사용하여 외부 테이블 만들기
이 예제에서는 텍스트로 구분된 파일 형식의 데이터를 가진 외부 테이블을 만드는 데 필요한 모든 단계를 보여 줍니다. 즉, 외부 데이터 원본 mydatasource 및 외부 파일 형식 myfileformat을 만듭니다. 이러한 데이터베이스 수준 개체는 나중에 CREATE EXTERNAL TABLE 문에 참조됩니다. 자세한 내용은 CREATE EXTERNAL DATA SOURCE 및 CREATE EXTERNAL FILE FORMAT을 참조하세요.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. RCFile 형식의 데이터를 사용하여 외부 테이블 만들기
이 예제에서는 RCFile 형식의 데이터를 가진 외부 테이블을 만드는 데 필요한 모든 단계를 보여 줍니다. 즉, 외부 데이터 원본 mydatasource_rc 및 외부 파일 형식 myfileformat_rc를 만듭니다. 이러한 데이터베이스 수준 개체는 나중에 CREATE EXTERNAL TABLE 문에 참조됩니다. 자세한 내용은 CREATE EXTERNAL DATA SOURCE 및 CREATE EXTERNAL FILE FORMAT을 참조하세요.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. ORC 형식의 데이터를 사용하여 외부 테이블 만들기
이 예제에서는 ORC 형식의 데이터를 가진 외부 테이블을 만드는 데 필요한 모든 단계를 보여 줍니다. 즉, 외부 데이터 원본 mydatasource_orc와 외부 파일 형식 myfileformat_orc를 정의합니다. 이러한 데이터베이스 수준 개체는 나중에 CREATE EXTERNAL TABLE 문에 참조됩니다. 자세한 내용은 CREATE EXTERNAL DATA SOURCE 및 CREATE EXTERNAL FILE FORMAT을 참조하세요.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Hadoop 데이터 쿼리
ClickStream은 Hadoop 클러스터의 구분된 텍스트 파일 employee.tbl에 연결하는 외부 테이블입니다. 다음 쿼리는 표준 테이블에 대한 쿼리와 유사해 보입니다. 그러나 이 쿼리는 Hadoop에서 데이터를 검색한 다음, 결과를 계산합니다.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Hadoop 데이터를 SQL 데이터와 조인
이 쿼리는 SQL 테이블 두 개에 대한 표준 JOIN과 유사해 보입니다. 차이점은 PolyBase가 Hadoop에서 clickstream 데이터를 검색한 다음, UrlDescription 테이블에 조인한다는 것입니다. 한 테이블은 외부 테이블이며 다른 테이블은 표준 SQL 테이블입니다.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. SQL 테이블로 Hadoop의 데이터 가져오기
이 예제에서는 표준 SQL 테이블 ms_user와 외부 테이블 user 간 조인의 결과를 영구적으로 저장하는 새 SQL 테이블 ClickStream를 만듭니다.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. SQL Server용 외부 테이블 만들기
데이터베이스 범위 자격 증명을 만들기 전에 자격 증명을 보호하려면 사용자 데이터베이스에 마스터 키가 있어야 합니다. 자세한 내용은 CREATE MASTER KEY 및 CREATE DATABASE SCOPED CREDENTIAL을 참조하세요.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
다음과 같은 SQLServerInstance 새 외부 데이터 원본 및 sqlserver.customer 외부 테이블을 만듭니다.
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
9\. Oracle용 외부 테이블 만들기
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Teradata용 외부 테이블 만들기
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
11. MongoDB용 외부 테이블 만들기
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
12. 외부 테이블을 통해 S3 호환 개체 스토리지 쿼리
적용 대상: SQL Server 2022(16.x) 이상
다음 예제에서는 T-SQL을 사용하여 외부 테이블 쿼리를 통해 S3 호환 개체 스토리지에 저장된 parquet 파일을 쿼리하는 방법을 보여 줍니다. 이 샘플에서는 외부 데이터 원본 내의 상대 경로를 사용합니다.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
다음 단계
다음 문서에서 관련 개념에 대해 자세히 알아보세요.
* Azure SQL Database *
개요: Azure SQL Database
Azure SQL Database에서 탄력적 쿼리(미리 보기 상태)에 대한 외부 테이블을 만듭니다.
CREATE EXTERNAL DATA SOURCE도 참조하세요.
구문
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
인수
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
만들려는 테이블의 한 부분에서 세 부분으로 이루어진 이름입니다. 외부 테이블의 경우 SQL은 Azure SQL Database에서 참조되는 파일이나 폴더에 대한 기본 통계와 함께 메타데이터만 저장합니다. 실제 데이터가 이동되거나 Azure SQL Database에 저장되지 않습니다.
중요
최상의 성능을 위해 외부 데이터 원본 드라이버가 세 부분으로 된 이름을 지원하는 경우 세 부분으로 된 이름을 제공하는 것이 좋습니다.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE은 열 이름, 데이터 형식, Null 허용 여부 및 데이터 정렬을 구성하는 기능을 지원합니다. 외부 테이블에 DEFAULT CONSTRAINT를 사용할 수 없습니다.
참고
Text, nText 및 XML은(는) Azure SQL Database의 외부 테이블에 있는 열에서 지원되지 않는 데이터 형식입니다.
데이터 형식 및 열 수를 포함한 열 정의는 외부 파일의 데이터와 일치해야 합니다. 불일치가 있는 경우 실제 데이터를 쿼리할 때 파일 행이 거부됩니다.
분할된 데이터베이스 외부 테이블 옵션
탄력적 쿼리의 외부 데이터 원본(비 SQL Server 데이터 원본) 및 배포 방법을 지정합니다.
DATA_SOURCE
DATA_SOURCE 절은 외부 테이블에 사용하는 외부 데이터 원본(분할 맵)을 정의합니다. 예제는 외부 테이블 만들기를 참조하세요.
중요
Azure SQL Database는 EXTERNAL DATA SOURCE 형식 RDMS와 SHARD_MAP_MANAGER에 대한 외부 테이블 만들기를 지원합니다. Azure SQL Database는 Azure Blob Storage에 대한 외부 테이블 만들기를 지원하지 않습니다.
SCHEMA_NAME과 OBJECT_NAME
SCHEMA_NAME과 OBJECT_NAME 절은 외부 테이블 정의를 다른 스키마의 테이블에 매핑합니다. 생략할 경우 원격 개체의 스키마를 “dbo”라 가정하고 그 이름이 정의하는 외부 테이블 이름과 동일하다고 간주합니다. 외부 테이블을 만들려는 데이터베이스에서 이미 원격 테이블의 이름을 가져온 경우에 유용합니다. 수평 확장된 데이터 계층에서 DMV의 카탈로그 뷰 집계를 가져오기 위해 외부 테이블을 정의하는 경우를 예로 들 수 있습니다. 카탈로그 뷰와 DMV는 이미 로컬로 존재하므로 외부 테이블 정의에 그 이름을 사용할 수 없습니다. 대신, 다른 이름을 사용하고 SCHEMA_NAME 및/또는 OBJECT_NAME 절에 카탈로그 뷰 또는 DMV의 이름을 사용합니다. 예제는 외부 테이블 만들기를 참조하세요.
DISTRIBUTION
선택 사항입니다. 이 인수는 SHARD_MAP_MANAGER 형식의 데이터베이스에 대해서만 필요합니다. 이 인수는 테이블이 분할된 테이블로 처리되는지 아니면 복제된 테이블로 처리되는지를 제어합니다. SHARDED(열 이름) 테이블을 사용하면 서로 다른 테이블의 데이터가 겹치지 않습니다. REPLICATED는 테이블이 모든 분할된 데이터베이스에서 같은 데이터를 갖도록 지정합니다. ROUND_ROBIN은 애플리케이션 관련 방법을 사용하여 데이터를 배포하도록 지정합니다.
DISTRIBUTION 절은 이 테이블에 사용되는 데이터 배포를 지정합니다. 쿼리 프로세서는 가장 효율적인 쿼리 계획을 구성하기 위해 DISTRIBUTION에서 제공하는 정보를 활용합니다.
- SHARDED는 데이터가 데이터베이스에 수평 분할되었음을 의미합니다. 데이터 배포의 분할 키는
sharding_column_name매개 변수입니다. - REPLICATED는 테이블의 동일한 복사본이 각 데이터베이스에 있음을 의미합니다. 사용자가 데이터베이스 전체에서 복제본이 동일한지 확인해야 합니다.
- ROUND_ROBIN은 테이블이 애플리케이션 종속 배포 방법을 사용하여 수평 분할되었음을 의미합니다.
사용 권한
외부 테이블에 대한 액세스 권한이 있는 사용자는 외부 데이터 원본 정의에서 제공한 자격 증명에 따라 자동으로 기본 원격 테이블에 액세스할 수 있습니다. 외부 데이터 원본의 자격 증명을 통해 원치 않는 권한 상승을 방지합니다. 일반 테이블인 것처럼 외부 테이블에 GRANT 또는 REVOKE를 사용합니다. 외부 데이터 원본 및 외부 테이블을 정의한 후 외부 테이블을 통해 전체 T-SQL을 사용할 수 있습니다.
오류 처리
CREATE EXTERNAL TABLE 문을 실행하는 동안 연결 시도가 실패하면 이 명령문이 실패하고 외부 테이블이 만들어지지 않습니다. SQL Database는 쿼리가 결국 실패할 때까지 연결을 다시 시도하므로 이 명령이 실패하려면 1분 이상 걸릴 수 있습니다.
설명
SELECT FROM EXTERNAL TABLE과 같은 임시 쿼리 시나리오에서 SQL Database는 외부 데이터 원본에서 검색된 행을 임시 테이블에 저장합니다. 쿼리가 완료된 후 SQL Database는 임시 테이블을 제거하고 삭제합니다. 영구적 데이터가 SQL 테이블에 저장되지 않습니다.
이와는 대조적으로 SELECT INTO FROM EXTERNAL TABLE과 같은 가져오기 시나리오에서 SQL Database는 외부 데이터 원본에서 검색된 행을 영구 데이터로 SQL 테이블에 저장합니다. 새 테이블은 SQL Database에서 외부 데이터를 검색할 때 쿼리 실행 중에 만들어집니다.
동일하거나 서로 다른 외부 데이터 원본을 참조하는 많은 외부 테이블을 만들 수 있습니다.
각각 서로 다른 외부 데이터 원본을 참조하는 여러 개의 외부 테이블을 만들 수 있습니다.
제한
격리 의미 체계: 외부 테이블을 통한 데이터에 대한 액세스는 SQL Server 내의 격리 의미 체계를 준수하지 않습니다. 즉, 외부 테이블을 쿼리해도 잠금 또는 스냅샷 격리가 적용되지 않습니다. 따라서 외부 데이터 원본의 데이터가 변경되면 데이터 반환이 변경됩니다. 즉, 외부 테이블에 대해 실행할 때마다 같은 쿼리가 서로 다른 결과를 반환할 수 있습니다. 마찬가지로 외부 데이터를 이동하거나 제거하면 쿼리가 실패할 수 있습니다.
구문 및 작업은지원되지 않습니다.
- 외부 테이블 열에 대한 DEFAULT 제약 조건
- 삭제, 삽입, 업데이트의 DML(데이터 조작 언어) 작업
- 외부 테이블 열에 대한 동적 데이터 마스킹
- Azure SQL Database 외부 테이블에는 커서가 지원되지 않습니다.
리터럴 조건자만: 쿼리에 정의된 리터럴 조건자만 외부 데이터 원본으로 푸시다운할 수 있습니다. 연결된 서버와 달리, 쿼리 실행 중에 즉 쿼리 계획에서 중첩된 루프와 함께 사용할 때 조건자를 통해 결정된 위치에 액세스할 수 있습니다. 이로 인해 전체 외부 테이블이 로컬로 복사된 다음 조인되는 경우가 많습니다.
다음 예제에서
External.Orders외부 테이블이고Customer로컬 테이블인 경우 필요한 조건자를 컴파일 시간에 알 수 없으므로 쿼리는 전체 외부 테이블을 로컬로 복사합니다.SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );병렬 처리없음: 외부 테이블을 사용하면 쿼리 계획에서 병렬 처리를 사용할 수 없습니다.
원격 쿼리실행됨: 외부 테이블은 원격 쿼리로 구현되므로 반환되는 예상 행 수는 일반적으로 1000개입니다. 외부 테이블을 필터링하는 데 사용되는 조건자의 형식에 따라 다른 규칙이 있습니다. 외부 테이블의 실제 데이터를 기반으로 하는 추정치가 아니라 규칙 기반 추정치입니다. 최적화 프로그램은 더 정확한 추정치를 얻기 위해 원격 데이터 원본에 액세스하지 않습니다.
프라이빗 엔드포인트지원되지 않음: 원격 테이블에 대한 연결이 프라이빗 엔드포인트인 경우 외부 테이블 쿼리가 지원되지 않습니다.
데이터 형식 제한 사항
다음 데이터 형식은 PolyBase 외부 테이블에 사용할 수 없습니다.
geographygeometryhierarchyidimagetextnTextxml- 모든 사용자 정의 형식
잠금
SCHEMARESOLUTION 개체에 대한 공유 잠금입니다.
예제
A. Azure SQL Database용 외부 테이블 만들기
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. 분할된 데이터베이스 데이터 원본에 대한 외부 테이블 만들기
이 예제에서는 SCHEMA_NAME 및 OBJECT_NAME 절을 사용하여 원격 DMV를 외부 테이블에 다시 매핑합니다.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
다음 단계
다음 문서에서 Azure SQL Database 외부 테이블에 대해 자세히 알아보세요.
* Azure Synapse
Analytics *
개요: Azure Synapse Analytics
외부 테이블을 사용하여 다음을 수행합니다.
- 전용 SQL 풀은 Hadoop, Azure Blob Storage 및 Azure Data Lake Storage Gen1 및 Gen2에서 데이터를 쿼리, 가져오기 및 저장할 수 있습니다.
- 서버리스 SQL 풀은 Azure Blob Storage, Azure Data Lake Storage Gen1 및 Gen2에서 데이터를 쿼리, 가져오기 및 저장할 수 있습니다. 서버리스에서 지원하지
TYPE=Hadoop않습니다.
CREATE EXTERNAL DATA SOURCE 및 DROP EXTERNAL TABLE도 참조하세요.
Azure Synapse에서 외부 테이블 사용에 대한 자세한 지침 및 예제는 Synapse SQL에서 외부 테이블 사용을 참조하세요.
구문
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
인수
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
만들려는 테이블의 한 부분에서 세 부분으로 이루어진 이름입니다. 외부 테이블의 경우, Azure Data Lake, Hadoop 또는 Azure Blob Storage에서 참조되는 파일이나 폴더에 대한 기본 통계와 함께 메타데이터만 해당합니다. 외부 테이블을 만들 때 실제 데이터가 이동하거나 저장되지 않습니다.
중요
최상의 성능을 위해 외부 데이터 원본 드라이버가 세 부분으로 된 이름을 지원하는 경우 세 부분으로 된 이름을 제공하는 것이 좋습니다.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE은 열 이름, 데이터 형식, Null 허용 여부 및 데이터 정렬을 구성하는 기능을 지원합니다. 외부 테이블에 DEFAULT CONSTRAINT를 사용할 수 없습니다.
참고
사용되지 않는 데이터 형식 textntext 이며 XML Synapse Analytics에 대한 외부 테이블의 열에 대해 지원되지 않는 데이터 형식입니다.
- 구분된 파일을 읽을 때 데이터 형식 및 열 수를 포함한 열 정의는 외부 파일의 데이터와 일치해야 합니다. 불일치가 있는 경우 실제 데이터를 쿼리할 때 파일 행이 거부됩니다.
- Parquet 파일에서 읽을 때 나머지를 읽고 건너뛰려는 열만 지정할 수 있습니다.
LOCATION = 'folder_or_filepath'
Azure Data Lake, Hadoop 또는 Azure Blob Storage의 실제 데이터에 대한 폴더 또는 파일 경로 및 파일 이름을 지정합니다. 위치는 루트 폴더에서 시작합니다. 루트 폴더는 외부 데이터 원본에 지정된 데이터 위치입니다.
CREATE EXTERNAL TABLE AS SELECT 문이 경로 및 폴더가 없으면 만듭니다.
CREATE EXTERNAL TABLE은 경로 및 폴더를 만들지 않습니다.
위치(LOCATION)를 폴더로 지정할 경우, 외부 테이블에서 선택하는 PolyBase 쿼리는 폴더 및 해당 폴더의 모든 하위 폴더에서 파일을 검색합니다. Hadoop과 마찬가지로 PolyBase도 숨겨진 폴더를 반환하지 않습니다. 또한 파일 이름이 밑줄(_) 또는 마침표(.)로 시작하는 파일을 반환하지 않습니다.
다음 이미지 예제에서는 LOCATION='/webdata/'이면 PolyBase 쿼리는 mydata.txt 및 mydata2.txt에서 행을 반환합니다.
mydata3.txt는 숨겨진 폴더의 하위 폴더이므로 반환하지 않습니다. 그리고 _hidden.txt는 숨겨진 파일이므로 반환하지 않습니다.
Hadoop 외부 테이블과 달리 네이티브 외부 테이블은 경로 끝에 지정 /** 하지 않는 한 하위 폴더를 반환하지 않습니다. 이 예제에서 서버리스 SQL 풀 쿼리인 경우 LOCATION='/webdata/'mydata.txt 행을 반환합니다. mydata2.txt 및 mydata3.txt는 하위 폴더에 있으므로 반환되지 않습니다. Hadoop 테이블은 모든 하위 폴더에 있는 모든 파일을 반환합니다.
Hadoop 및 네이티브 외부 테이블은 모두 밑줄(_) 또는 마침표(.)로 시작하는 이름의 파일을 건너뜁니다.
DATA_SOURCE = external_data_source_name
외부 데이터 위치가 포함된 외부 데이터 원본의 이름을 지정합니다. 이 위치는 Azure Data Lake에 있습니다. 외부 데이터 원본을 만들려면 CREATE EXTERNAL DATA SOURCE를 사용합니다.
FILE_FORMAT = external_file_format_name
외부 데이터에 대한 파일 형식과 압축 방법을 저장하는 외부 파일 형식 개체의 이름을 지정합니다. 외부 파일 형식을 만들려면 CREATE EXTERNAL FILE FORMAT을 사용합니다.
TABLE_OPTIONS
기본 파일을 읽는 방법을 설명하는 옵션 세트를 지정합니다. 현재 사용할 수 있는 유일한 옵션은 일부 일치하지 않는 읽기 작업이 발생할 수 있는 경우에도 외부 테이블에 기본 파일에 대한 업데이트를 무시하도록 지시하는 {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}입니다. 자주 추가되는 파일이 있는 특수한 경우에만 이 옵션을 사용합니다. 이 옵션은 서버리스 SQL 풀에서 CSV 형식으로 사용할 수 있습니다.
REJECT 옵션
거부 옵션은 Azure Synapse Analytics의 서버리스 SQL 풀에 대해 미리 보기로 제공됩니다.
이 옵션은 TYPE = HADOOP인 외부 데이터 원본에서만 사용할 수 있습니다.
PolyBase가 외부 데이터 원본에서 검색하는 더티 레코드를 처리하는 방법을 결정하는 거부 매개 변수를 지정할 수 있습니다. 데이터 레코드는 실제 데이터 형식 또는 열 수가 외부 테이블의 열 정의와 일치하지 않으면 '더티'로 간주됩니다.
거부 값을 지정하거나 변경하지 않으면 PolyBase는 기본값을 사용합니다. 거부 매개 변수에 관한 이 정보는 CREATE EXTERNAL TABLE 문을 사용하여 외부 테이블을 만들 때 추가 메타데이터로 저장됩니다. 후속 SELECT 문 또는 SELECT INTO SELECT 문이 외부 데이터에서 데이터를 선택하는 경우, PolyBase는 거부 옵션을 사용하여 실제 쿼리가 실패할 때까지 거부될 수 있는 행의 개수 또는 비율을 결정합니다. 이 쿼리는 거부된 임계값이 초과될 때까지 (부분) 결과를 반환합니다. 그런 다음, 적절한 오류 메시지와 함께 실패합니다.
PARSER_VERSION 형식 옵션은 서버리스 SQL 풀에서만 지원됩니다.
REJECT_TYPE = value | percentage
REJECT_VALUE 옵션이 리터럴 값으로 지정되는지 또는 백분율로 지정되는지 구체화합니다.
value
REJECT_VALUE는 백분율이 아닌 리터럴 값입니다. PolyBase 쿼리는 거부된 행 수가 reject_value를 초과하면 실패합니다.
예를 들어 REJECT_VALUE = 5이고 REJECT_TYPE = value인 경우, PolyBase SELECT 쿼리는 5개 행이 거부된 후 실패합니다.
percentage
REJECT_VALUE는 리터럴 값이 아닌 백분율입니다. PolyBase 쿼리는 실패한 행의 백분율(percentage)이 reject_value를 초과하면 실패합니다. 실패한 행의 백분율은 일정 간격으로 계산됩니다.
REJECT_VALUE = reject_value
쿼리가 실패할 때까지 거부될 수 있는 값 또는 행의 백분율을 지정합니다.
- REJECT_TYPE = value인 경우, reject_value는 0에서 2,147,483,647 사이의 정수여야 합니다.
- REJECT_TYPE = percentage인 경우, reject_value는 0에서 100 사이의 부동 소수점 수이어야 합니다. 백분율은 전용 SQL 풀에만 유효합니다.
TYPE=HADOOP
쿼리는 거부된 행 수가 reject_value를 초과하면 실패합니다. 예를 들어 REJECT_VALUE = 5이고 REJECT_TYPE = value인 경우, SELECT 쿼리는 5개 행이 거부된 후 실패합니다.
REJECT_SAMPLE_VALUE = reject_sample_value
이 특성은 REJECT_TYPE = percentage를 지정한 경우에 필요하며 PolyBase가 거부된 행의 백분율을 다시 계산하기 전까지 검색을 시도하는 행 수를 결정합니다.
reject_sample_value 매개 변수는 0에서 2,147,483,647 사이의 정수여야 합니다.
예를 들어 REJECT_SAMPLE_VALUE = 1000인 경우, PolyBase는 외부 데이터 파일에서 행 1000개 가져오기를 시도한 후 실패한 행의 백분율을 계산합니다. 실패한 행의 백분율이 reject_value보다 작은 경우, PolyBase는 또 다른 행 1000개의 검색을 시도합니다. 계속해서 추가로 행 1000개의 가져오기를 시도한 후마다 실패한 행의 백분율을 다시 계산합니다.
참고
PolyBase는 실패한 행의 백분율을 일정 간격으로 계산하므로 실패한 행의 실제 백분율은 reject_value를 초과할 수 있습니다.
예제:
이 예제에서는 REJECT 옵션 세 개가 서로 상호 작용하는 방법을 보여 줍니다. 예를 들어 REJECT_TYPE = percentage, REJECT_VALUE = 30 및 REJECT_SAMPLE_VALUE = 100인 경우 다음과 같은 시나리오가 일어날 수 있습니다.
- PolyBase가 처음 100개 행의 검색을 시도하며, 25개가 실패하고 75개가 성공합니다.
- 실패한 행의 백분율은 25%로 계산되며, 이는 거부 값 30%보다 작습니다. 결과적으로 PolyBase는 외부 데이터 원본에서 데이터를 계속 검색합니다.
- PolyBase는 다음 100개 행의 로드를 시도합니다. 이번에는 25개 행이 성공하고 75개 행이 실패합니다.
- 실패한 행의 백분율은 50%로 다시 계산됩니다. 실패한 행의 이 백분율은 30% 거부 값을 초과했습니다.
- PolyBase 쿼리는 처음 200개 행의 반환을 시도한 후 거부된 행이 50%여서 실패합니다. PolyBase 쿼리가 거부 임계값이 초과되었음을 감지하기 전에 일치하는 행이 반환되었습니다.
REJECTED_ROW_LOCATION = 디렉터리 위치
거부된 행과 해당 오류 파일을 작성해야 하는 외부 데이터 원본 내 디렉터리를 지정합니다.
지정된 경로가 없으면 해당 경로가 만들어집니다. 자식 디렉터리가 이름으로 _rejectedrows만들어집니다. 이 문자는 _ 위치 매개 변수에 명시적으로 이름을 지정하지 않는 한 다른 데이터 처리를 위해 디렉터리가 이스케이프되도록 합니다.
- 서버리스 SQL 풀에서 경로는 .입니다
YearMonthDay_HourMinuteSecond_StatementID. 명령문 ID를 사용하여 폴더를 생성한 쿼리와 폴더를 연관시킬 수 있습니다. - 전용 SQL 풀에서 만든 경로는 예를 들어
YearMonthDay -HourMinuteSecond형식20180330-173205으로 로드 제출 시간을 기반으로 합니다.
이 폴더에는 파일과 데이터 파일의 두 가지 형식이 _reason 기록됩니다.
자세한 내용은 CREATE EXTERNAL DATA SOURCE를 참조하세요.
reason 파일과 data 파일에는 모두 CTAS 문과 연결된 queryID가 있습니다. data와 reason은 별도의 파일에 있으므로 해당 파일의 접미사가 일치해야 합니다.
서버리스 SQL 풀 error.json 에서 파일은 거부된 행과 관련된 오류가 발생한 JSON 배열을 포함합니다. 오류를 나타내는 각 요소에는 다음 특성이 포함됩니다.
| attribute | 설명 |
|---|---|
| 오류 | 행이 거부된 이유입니다. |
| Row | 파일에서 행 서수를 거부했습니다. |
| Column | 거부된 열 서수. |
| 값 | 거부된 열 값입니다. 값이 100자보다 크면 처음 100자만 표시됩니다. |
| 파일 | 해당 행이 속한 파일의 경로입니다. |
사용 권한
다음과 같은 권한이 필요합니다.
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
참고
CONTROL DATABASE 권한은 마스터 키, 데이터베이스 범위 자격 증명 및 외부 데이터 원본을 만드는 경우에만 필요합니다.
참고로 외부 데이터 원본을 만드는 로그인은 Hadoop 또는 Azure Blob Storage에 있는 외부 데이터 원본에 대한 읽기 및 쓰기 권한을 가져야 합니다.
중요
ALTER ANY EXTERNAL DATA SOURCE 권한은 보안 주체에 대해 외부 데이터 원본 개체를 만들고 수정하는 권한을 부여하며, 따라서 데이터베이스의 모든 데이터베이스 범위 자격 증명에 액세스하는 권한도 부여합니다. 이 권한은 높은 수준의 권한으로 간주되어야 하므로, 시스템의 신뢰할 수 있는 보안 주체에만 부여되어야 합니다.
오류 처리
CREATE EXTERNAL TABLE 문을 실행하는 동안 PolyBase는 외부 데이터 원본에 연결을 시도합니다. 연결 시도가 실패하면 이 명령문이 실패하고 외부 테이블이 만들어지지 않습니다. PolyBase는 쿼리가 결국 실패할 때까지 연결을 다시 시도하므로 이 명령이 실패하려면 1분 이상 걸릴 수 있습니다.
설명
SELECT FROM EXTERNAL TABLE과 같은 임시 쿼리 시나리오에서 PolyBase는 외부 데이터 원본에서 검색된 행을 임시 테이블에 저장합니다. 쿼리가 완료된 후 PolyBase는 임시 테이블을 제거하고 삭제합니다. 영구적 데이터가 SQL 테이블에 저장되지 않습니다.
이와는 대조적으로 SELECT INTO FROM EXTERNAL TABLE과 같은 가져오기 시나리오에서 PolyBase는 외부 데이터 원본에서 검색된 행을 영구 데이터로 SQL 테이블에 저장합니다. 새 테이블은 PolyBase에서 외부 데이터를 검색할 때 쿼리 실행 중에 만들어집니다.
PolyBase는 쿼리 성능을 향상시키기 위해 쿼리 계산 중 일부를 Hadoop에 푸시할 수 있습니다. 이 작업을 조건자 푸시 다운이라 합니다. 이를 활성화하려면 CREATE EXTERNAL DATA SOURCE에 Hadoop 리소스 관리자 위치 옵션을 지정합니다.
동일하거나 서로 다른 외부 데이터 원본을 참조하는 많은 외부 테이블을 만들 수 있습니다.
UTF-8 데이터 정렬을 사용하여 원본 데이터에 주의하세요. UTF-8 데이터 정렬을 사용하는 원본 데이터의 경우 CREATE EXTERNAL TABLE 문의 각 UTF-8 열마다 UTF-8이 아닌 데이터 정렬을 수동으로 제공해야 합니다. UTF-8 지원이 외부 테이블로 확장되지 않기 때문입니다. UTF-8 데이터 정렬을 사용하여 외부 테이블을 만들려고 하면 오류 메시지가 표시됩니다 Unsupported collation . 외부 테이블의 데이터베이스 데이터 정렬이 UTF-8 데이터 정렬인 경우 명시적 비 UTF-8 열 데이터 정렬 [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,을 제공하지 않으면 외부 테이블 만들기가 실패합니다.
Azure Synapse Analytics의 서버리스 및 전용 SQL 풀은 데이터 가상화에 서로 다른 코드 베이스를 사용합니다. 서버리스 SQL 풀은 네이티브 데이터 가상화 기술을 지원합니다. 전용 SQL 풀은 네이티브 및 PolyBase 데이터 가상화를 모두 지원합니다. PolyBase 데이터 가상화는 EXTERNAL DATA SOURCE를 사용하여 TYPE=HADOOP만들 때 사용됩니다.
제한 사항
외부 테이블의 데이터가 Azure Synapse의 직접 관리 제어에 없으므로, 언제든지 외부 프로세스에 의해 변경 또는 제거될 수 있습니다. 따라서 외부 테이블에 대한 쿼리 결과는 결정적인 것으로 보증되지 않습니다. 즉, 외부 테이블에 대해 실행할 때마다 같은 쿼리가 서로 다른 결과를 반환할 수 있습니다. 마찬가지로 외부 데이터를 이동하거나 제거하면 쿼리가 실패할 수 있습니다.
각각 서로 다른 외부 데이터 원본을 참조하는 여러 개의 외부 테이블을 만들 수 있습니다.
다음 DDL(Data Definition Language) 문은 외부 테이블에 대해 허용됩니다.
- CREATE TABLE 및 DROP TABLE
- CREATE STATISTICS 및 DROP STATISTICS
- CREATE VIEW 및 DROP VIEW
지원되지 않는 구문 및 작업:
- 외부 테이블 열에 대한 DEFAULT 제약 조건
- 삭제, 삽입 및 업데이트의 DML(데이터 조작 언어) 작업
- 외부 테이블 열에 대한 동적 데이터 마스킹
쿼리 제한 사항
폴더당 파일 크기가 30k를 초과하지 않는 것이 좋습니다. 너무 많은 파일이 참조되면 JVM(Java Virtual Machine) 메모리 부족 예외가 발생하거나 성능이 저하될 수 있습니다.
테이블 너비 제한 사항
Data Warehouse의 PolyBase에는 테이블 정의에 의해 유효한 단일 행의 최대 크기를 기반으로 1MB의 행 너비 한도가 적용됩니다. 열 스키마의 합계가 1MB보다 큰 경우 PolyBase는 데이터를 쿼리할 수 없습니다.
데이터 형식 제한 사항
다음 데이터 형식은 PolyBase 외부 테이블에 사용할 수 없습니다.
geographygeometryhierarchyidimagetextnTextxml- 모든 사용자 정의 형식
잠금
SCHEMARESOLUTION 개체에 대한 공유 잠금입니다.
예제
A. ADLS Gen 2에서 Azure Synapse Analytics로 데이터 가져오기
ADLS Gen 1에 대한 예는 외부 데이터 원본 만들기를 참조하세요.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Parquet에서 Azure Synapse Analytics로 데이터 가져오기
다음 예제에서는 외부 테이블을 만듭니다. 그런 다음 첫 번째 행을 반환합니다.
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
다음 단계
다음 문서에서 외부 테이블 및 관련 개념에 대해 자세히 알아보세요.
* Analytics
플랫폼 시스템(PDW) *
개요: 분석 플랫폼 시스템
외부 테이블을 사용하여 다음을 수행합니다.
- Transact-SQL 문을 통해 Hadoop 또는 Azure Blob Storage 데이터를 쿼리합니다.
- Hadoop 또는 Azure Blob Storage의 데이터를 가져와서 Analytics Platform System에 저장합니다.
CREATE EXTERNAL DATA SOURCE 및 DROP EXTERNAL TABLE도 참조하세요.
구문
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
인수
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
만들려는 테이블의 한 부분에서 세 부분으로 이루어진 이름입니다. 외부 테이블의 경우 Analytics Platform System은 Hadoop 또는 Azure Blob Storage에서 참조되는 파일이나 폴더에 대한 기본 통계와 함께 메타데이터만 저장합니다. 실제 데이터가 이동되거나 Analytics Platform System에 저장되지 않습니다.
중요
최상의 성능을 위해 외부 데이터 원본 드라이버가 세 부분으로 된 이름을 지원하는 경우 세 부분으로 된 이름을 제공하는 것이 좋습니다.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE은 열 이름, 데이터 형식, Null 허용 여부 및 데이터 정렬을 구성하는 기능을 지원합니다. 외부 테이블에 DEFAULT CONSTRAINT를 사용할 수 없습니다.
데이터 형식 및 열 수를 포함한 열 정의는 외부 파일의 데이터와 일치해야 합니다. 불일치가 있는 경우 실제 데이터를 쿼리할 때 파일 행이 거부됩니다.
LOCATION = 'folder_or_filepath'
Hadoop 또는 Azure Blob Storage의 실제 데이터에 대한 폴더 또는 파일 경로 및 파일 이름을 지정합니다. 위치는 루트 폴더에서 시작합니다. 루트 폴더는 외부 데이터 원본에 지정된 데이터 위치입니다.
Analytics Platform System에서는 CREATE EXTERNAL TABLE AS SELECT 문이 존재하지 않는 경로 및 폴더를 만듭니다.
CREATE EXTERNAL TABLE은 경로 및 폴더를 만들지 않습니다.
위치(LOCATION)를 폴더로 지정할 경우, 외부 테이블에서 선택하는 PolyBase 쿼리는 폴더 및 해당 폴더의 모든 하위 폴더에서 파일을 검색합니다. Hadoop과 마찬가지로 PolyBase도 숨겨진 폴더를 반환하지 않습니다. 또한 파일 이름이 밑줄(_) 또는 마침표(.)로 시작하는 파일을 반환하지 않습니다.
다음 이미지 예제에서는 LOCATION='/webdata/'이면 PolyBase 쿼리는 mydata.txt 및 mydata2.txt에서 행을 반환합니다.
mydata3.txt는 숨겨진 폴더의 하위 폴더이므로 반환하지 않습니다. 그리고 _hidden.txt는 숨겨진 파일이므로 반환하지 않습니다.
기본값을 변경하고 루트 폴더에서 읽기만 하려면 <polybase.recursive.traversal> 구성 파일에서 core-site.xml 특성을 'false'로 설정합니다. 이 파일은 SQL Server의 <SqlBinRoot>\PolyBase\Hadoop\Conf\ 루트 아래에 bin 있습니다. 예들 들어 C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\입니다.
DATA_SOURCE = external_data_source_name
외부 데이터 위치가 포함된 외부 데이터 원본의 이름을 지정합니다. 이 위치는 Hadoop 또는 Azure Blob Storage입니다. 외부 데이터 원본을 만들려면 CREATE EXTERNAL DATA SOURCE를 사용합니다.
FILE_FORMAT = external_file_format_name
외부 데이터에 대한 파일 형식과 압축 방법을 저장하는 외부 파일 형식 개체의 이름을 지정합니다. 외부 파일 형식을 만들려면 CREATE EXTERNAL FILE FORMAT을 사용합니다.
거부 옵션
이 옵션은 TYPE = HADOOP인 외부 데이터 원본에서만 사용할 수 있습니다.
PolyBase가 외부 데이터 원본에서 검색하는 더티 레코드를 처리하는 방법을 결정하는 거부 매개 변수를 지정할 수 있습니다. 데이터 레코드는 실제 데이터 형식 또는 열 수가 외부 테이블의 열 정의와 일치하지 않으면 '더티'로 간주됩니다.
거부 값을 지정하거나 변경하지 않으면 PolyBase는 기본값을 사용합니다. 거부 매개 변수에 관한 이 정보는 CREATE EXTERNAL TABLE 문을 사용하여 외부 테이블을 만들 때 추가 메타데이터로 저장됩니다. 후속 SELECT 문 또는 SELECT INTO SELECT 문이 외부 데이터에서 데이터를 선택하는 경우, PolyBase는 거부 옵션을 사용하여 실제 쿼리가 실패할 때까지 거부될 수 있는 행의 개수 또는 비율을 결정합니다. 이 쿼리는 거부된 임계값이 초과될 때까지 (부분) 결과를 반환합니다. 그런 다음, 적절한 오류 메시지와 함께 실패합니다.
REJECT_TYPE = value | percentage
REJECT_VALUE 옵션이 리터럴 값으로 지정되는지 또는 백분율로 지정되는지 구체화합니다.
value
REJECT_VALUE는 백분율이 아닌 리터럴 값입니다. PolyBase 쿼리는 거부된 행 수가 reject_value를 초과하면 실패합니다.
예를 들어 REJECT_VALUE = 5이고 REJECT_TYPE = value인 경우, PolyBase SELECT 쿼리는 5개 행이 거부된 후 실패합니다.
percentage
REJECT_VALUE는 리터럴 값이 아닌 백분율입니다. PolyBase 쿼리는 실패한 행의 백분율(percentage)이 reject_value를 초과하면 실패합니다. 실패한 행의 백분율은 일정 간격으로 계산됩니다.
REJECT_VALUE = reject_value
쿼리가 실패할 때까지 거부될 수 있는 값 또는 행의 백분율을 지정합니다.
REJECT_TYPE = value인 경우, reject_value는 0에서 2,147,483,647 사이의 정수여야 합니다.
REJECT_TYPE = percentage인 경우, reject_value는 0에서 100 사이의 부동 소수점 수이어야 합니다.
REJECT_SAMPLE_VALUE = reject_sample_value
이 특성은 REJECT_TYPE = percentage를 지정한 경우에 필요하며 PolyBase가 거부된 행의 백분율을 다시 계산하기 전까지 검색을 시도하는 행 수를 결정합니다.
reject_sample_value 매개 변수는 0에서 2,147,483,647 사이의 정수여야 합니다.
예를 들어 REJECT_SAMPLE_VALUE = 1000인 경우, PolyBase는 외부 데이터 파일에서 행 1000개 가져오기를 시도한 후 실패한 행의 백분율을 계산합니다. 실패한 행의 백분율이 reject_value보다 작은 경우, PolyBase는 또 다른 행 1000개의 검색을 시도합니다. 계속해서 추가로 행 1000개의 가져오기를 시도한 후마다 실패한 행의 백분율을 다시 계산합니다.
참고
PolyBase는 실패한 행의 백분율을 일정 간격으로 계산하므로 실패한 행의 실제 백분율은 reject_value를 초과할 수 있습니다.
예제:
이 예제에서는 REJECT 옵션 세 개가 서로 상호 작용하는 방법을 보여 줍니다. 예를 들어 REJECT_TYPE = percentage, REJECT_VALUE = 30 및 REJECT_SAMPLE_VALUE = 100인 경우 다음과 같은 시나리오가 일어날 수 있습니다.
- PolyBase가 처음 100개 행의 검색을 시도하며, 25개가 실패하고 75개가 성공합니다.
- 실패한 행의 백분율은 25%로 계산되며, 이는 거부 값 30%보다 작습니다. 결과적으로 PolyBase는 외부 데이터 원본에서 데이터를 계속 검색합니다.
- PolyBase는 다음 100개 행의 로드를 시도합니다. 이번에는 25개 행이 성공하고 75개 행이 실패합니다.
- 실패한 행의 백분율은 50%로 다시 계산됩니다. 실패한 행의 이 백분율은 30% 거부 값을 초과했습니다.
- PolyBase 쿼리는 처음 200개 행의 반환을 시도한 후 거부된 행이 50%여서 실패합니다. PolyBase 쿼리가 거부 임계값이 초과되었음을 감지하기 전에 일치하는 행이 반환되었습니다.
사용 권한
다음과 같은 권한이 필요합니다.
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
- CONTROL DATABASE
참고로 외부 데이터 원본을 만드는 로그인은 Hadoop 또는 Azure Blob Storage에 있는 외부 데이터 원본에 대한 읽기 및 쓰기 권한을 가져야 합니다.
중요
ALTER ANY EXTERNAL DATA SOURCE 권한은 보안 주체에 대해 외부 데이터 원본 개체를 만들고 수정하는 권한을 부여하며, 따라서 데이터베이스의 모든 데이터베이스 범위 자격 증명에 액세스하는 권한도 부여합니다. 이 권한은 높은 수준의 권한으로 간주되어야 하므로, 시스템의 신뢰할 수 있는 보안 주체에만 부여되어야 합니다.
오류 처리
CREATE EXTERNAL TABLE 문을 실행하는 동안 PolyBase는 외부 데이터 원본에 연결을 시도합니다. 연결 시도가 실패하면 이 명령문이 실패하고 외부 테이블이 만들어지지 않습니다. PolyBase는 쿼리가 결국 실패할 때까지 연결을 다시 시도하므로 이 명령이 실패하려면 1분 이상 걸릴 수 있습니다.
설명
SELECT FROM EXTERNAL TABLE과 같은 임시 쿼리 시나리오에서 PolyBase는 외부 데이터 원본에서 검색된 행을 임시 테이블에 저장합니다. 쿼리가 완료된 후 PolyBase는 임시 테이블을 제거하고 삭제합니다. 영구적 데이터가 SQL 테이블에 저장되지 않습니다.
이와는 대조적으로 SELECT INTO FROM EXTERNAL TABLE과 같은 가져오기 시나리오에서 PolyBase는 외부 데이터 원본에서 검색된 행을 영구 데이터로 SQL 테이블에 저장합니다. 새 테이블은 PolyBase에서 외부 데이터를 검색할 때 쿼리 실행 중에 만들어집니다.
PolyBase는 쿼리 성능을 향상시키기 위해 쿼리 계산 중 일부를 Hadoop에 푸시할 수 있습니다. 이 작업을 조건자 푸시 다운이라 합니다. 이를 활성화하려면 CREATE EXTERNAL DATA SOURCE에 Hadoop 리소스 관리자 위치 옵션을 지정합니다.
동일하거나 서로 다른 외부 데이터 원본을 참조하는 많은 외부 테이블을 만들 수 있습니다.
제한 사항
외부 테이블의 데이터가 해당 기기의 직접 관리 제어에 없으므로, 언제든지 외부 프로세스에 의해 변경 또는 제거될 수 있습니다. 따라서 외부 테이블에 대한 쿼리 결과는 결정적인 것으로 보증되지 않습니다. 즉, 외부 테이블에 대해 실행할 때마다 같은 쿼리가 서로 다른 결과를 반환할 수 있습니다. 마찬가지로 외부 데이터를 이동하거나 제거하면 쿼리가 실패할 수 있습니다.
각각 서로 다른 외부 데이터 원본을 참조하는 여러 개의 외부 테이블을 만들 수 있습니다. 서로 다른 Hadoop 데이터 원본에 대해 동시에 쿼리를 실행하는 경우 각 Hadoop 원본은 동일한 'hadoop 연결' 서버 구성 설정을 사용해야 합니다. 예를 들어 Cloudera Hadoop 클러스터 및 Hortonworks Hadoop 클러스터는 서로 다른 구성 설정을 사용하므로 이들에 대해 하나의 쿼리를 동시에 실행할 수 없습니다. 구성 설정 및 지원되는 결합에 대해서는 PolyBase 연결 구성을 참조하세요.
다음 DDL(Data Definition Language) 문은 외부 테이블에 대해 허용됩니다.
- CREATE TABLE 및 DROP TABLE
- CREATE STATISTICS 및 DROP STATISTICS
- CREATE VIEW 및 DROP VIEW
지원되지 않는 구문 및 작업:
- 외부 테이블 열에 대한 DEFAULT 제약 조건
- 삭제, 삽입 및 업데이트의 DML(데이터 조작 언어) 작업
- 외부 테이블 열에 대한 동적 데이터 마스킹
쿼리 제한 사항
PolyBase는 32개의 동시 PolyBase 쿼리를 실행할 때 폴더당 최대 3만 3천 개의 파일을 사용할 수 있습니다. 이 최대 개수는 각 HDFS 폴더의 파일과 하위 폴더를 모두 포함합니다. 동시성 수준이 32보다 작은 경우 사용자는 33k보다 많은 파일을 포함하는 HDFS의 폴더에 대해 PolyBase 쿼리를 실행할 수 있습니다. 외부 파일 경로를 짧게 유지하고 HDFS 폴더당 30k 이하의 파일을 사용하는 것이 좋습니다. 너무 많은 파일이 참조되면 JVM(Java Virtual Machine) 메모리 부족 예외가 발생할 수 있습니다.
테이블 너비 제한 사항
SQL Server 2016의 PolyBase에는 테이블 정의에 의해 유효한 단일 행의 최대 크기를 기반으로 32KB의 행 너비 한도가 적용됩니다. 열 스키마의 합계가 32KB보다 큰 경우 PolyBase는 데이터를 쿼리할 수 없습니다.
Azure Synapse Analytics에서는 이 제한이 1MB로 증가했습니다.
데이터 형식 제한 사항
다음 데이터 형식은 PolyBase 외부 테이블에 사용할 수 없습니다.
geographygeometryhierarchyidimagetextnTextxml- 모든 사용자 정의 형식
잠금
SCHEMARESOLUTION 개체에 대한 공유 잠금입니다.
보안
외부 테이블에 대한 데이터 파일은 Hadoop 또는 Azure Blob Storage에 저장됩니다. 이러한 데이터 파일은 사용자 고유의 프로세스에 의해 만들어지고 관리됩니다. 외부 데이터의 보안을 관리하는 것은 사용자의 책임입니다.
예제
A. Analytics Platform System 데이터로 HDFS 데이터 조인
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. HDFS에서 분산된 Analytics Platform System 테이블로 행 데이터 가져오기
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. HDFS에서 복제된 Analytics Platform System 테이블로 행 데이터 가져오기
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
다음 단계
다음 문서에서 Analytics Platform System의 외부 테이블에 대해 자세히 알아보세요.
* Azure SQL Managed Instance *
개요: Azure SQL Managed Instance
Azure SQL Managed Instance에서 외부 데이터 테이블을 만듭니다. 자세한 내용은 Azure SQL Managed Instance를 사용한 데이터 가상화를 참조하세요.
Azure SQL Managed Instance 데이터 가상화는 Azure Data Lake Storage Gen2 또는 Azure Blob Storage 다양한 파일 형식의 외부 데이터에 대한 액세스를 제공하고, T-SQL 문으로 쿼리하고, 조인을 사용하여 로컬로 저장된 관계형 데이터와 데이터를 결합할 수도 있습니다.
CREATE EXTERNAL DATA SOURCE 및 DROP EXTERNAL TABLE도 참조하세요.
구문
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
인수
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
만들려는 테이블의 한 부분에서 세 부분으로 이루어진 이름입니다. 외부 테이블의 경우, Azure Data Lake 또는 Azure Blob Storage에서 참조되는 파일이나 폴더에 대한 기본 통계와 함께 메타데이터만 해당합니다. 외부 테이블을 만들 때 실제 데이터가 이동하거나 저장되지 않습니다.
중요
최상의 성능을 위해 외부 데이터 원본 드라이버가 세 부분으로 된 이름을 지원하는 경우 세 부분으로 된 이름을 제공하는 것이 좋습니다.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE은 열 이름, 데이터 형식, Null 허용 여부 및 데이터 정렬을 구성하는 기능을 지원합니다. 외부 테이블에 DEFAULT CONSTRAINT를 사용할 수 없습니다.
데이터 형식 및 열 수를 포함한 열 정의는 외부 파일의 데이터와 일치해야 합니다. 불일치가 있는 경우 실제 데이터를 쿼리할 때 파일 행이 거부됩니다.
LOCATION = 'folder_or_filepath'
Azure Data Lake 또는 Azure Blob Storage의 실제 데이터에 대한 폴더 또는 파일 경로 및 파일 이름을 지정합니다. 위치는 루트 폴더에서 시작합니다. 루트 폴더는 외부 데이터 원본에 지정된 데이터 위치입니다.
CREATE EXTERNAL TABLE은 경로 및 폴더를 만들지 않습니다.
LOCATION을 폴더로 지정할 경우, 외부 테이블에서 선택하는 Azure SQL Managed Instance의 쿼리는 폴더에서 파일을 검색하지만 해당 폴더의 하위 폴더는 검색 대상이 아닙니다.
Azure SQL Managed Instance 하위 폴더 또는 숨겨진 폴더에서 파일을 찾을 수 없습니다. 또한 파일 이름이 밑줄(_) 또는 마침표(.)로 시작하는 파일을 반환하지 않습니다.
다음 이미지 예제에서는 LOCATION='/webdata/'이면 쿼리는 mydata.txt에서 행을 반환합니다. 하위 폴더에 있으므로 mydata2.txt을 반환하지 않으며 숨겨진 폴더에 있으므로 mydata3.txt을 반환되지 않고 숨겨진 파일이므로 _hidden.txt을 반환하지 않습니다.
DATA_SOURCE = external_data_source_name
외부 데이터 위치가 포함된 외부 데이터 원본의 이름을 지정합니다. 이 위치는 Azure Data Lake에 있습니다. 외부 데이터 원본을 만들려면 CREATE EXTERNAL DATA SOURCE를 사용합니다.
FILE_FORMAT = external_file_format_name
외부 데이터에 대한 파일 형식과 압축 방법을 저장하는 외부 파일 형식 개체의 이름을 지정합니다. 외부 파일 형식을 만들려면 CREATE EXTERNAL FILE FORMAT을 사용합니다.
사용 권한
다음과 같은 권한이 필요합니다.
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
참고
CONTROL DATABASE 권한은 마스터 키, 데이터베이스 범위 자격 증명 및 외부 데이터 원본을 만드는 경우에만 필요합니다.
참고로 외부 데이터 원본을 만드는 로그인은 Hadoop 또는 Azure Blob Storage에 있는 외부 데이터 원본에 대한 읽기 및 쓰기 권한을 가져야 합니다.
중요
ALTER ANY EXTERNAL DATA SOURCE 권한은 보안 주체에 대해 외부 데이터 원본 개체를 만들고 수정하는 권한을 부여하며, 따라서 데이터베이스의 모든 데이터베이스 범위 자격 증명에 액세스하는 권한도 부여합니다. 이 권한은 높은 수준의 권한으로 간주되어야 하므로, 시스템의 신뢰할 수 있는 보안 주체에만 부여되어야 합니다.
설명
SELECT FROM EXTERNAL TABLE과 같은 임시 쿼리 시나리오에서는 외부 데이터 원본에서 검색되는 행이 임시 테이블에 저장됩니다. 쿼리가 완료되면 행이 제거되고 임시 테이블이 삭제됩니다. 영구적 데이터가 SQL 테이블에 저장되지 않습니다.
이와는 대조적으로 SELECT INTO FROM EXTERNAL TABLE과 같은 가져오기 시나리오에서는 외부 데이터 원본에서 검색된 행을 영구 데이터로 SQL 테이블에 저장합니다. 새 테이블은 외부 데이터를 검색할 때 쿼리 실행 중에 만들어집니다.
현재, Azure SQL Managed Instance를 사용한 데이터 가상화는 읽기 전용입니다.
동일하거나 서로 다른 외부 데이터 원본을 참조하는 많은 외부 테이블을 만들 수 있습니다.
제한 사항
외부 테이블의 데이터가 Azure SQL Managed Instance의 직접 관리 제어에 없으므로, 언제든지 외부 프로세스에 의해 변경 또는 제거될 수 있습니다. 따라서 외부 테이블에 대한 쿼리 결과는 결정적인 것으로 보증되지 않습니다. 즉, 외부 테이블에 대해 실행할 때마다 같은 쿼리가 서로 다른 결과를 반환할 수 있습니다. 마찬가지로 외부 데이터를 이동하거나 제거하면 쿼리가 실패할 수 있습니다.
각각 서로 다른 외부 데이터 원본을 참조하는 여러 개의 외부 테이블을 만들 수 있습니다.
다음 DDL(Data Definition Language) 문은 외부 테이블에 대해 허용됩니다.
- CREATE TABLE 및 DROP TABLE
- CREATE STATISTICS 및 DROP STATISTICS
- CREATE VIEW 및 DROP VIEW
지원되지 않는 구문 및 작업:
- 외부 테이블 열에 대한 DEFAULT 제약 조건
- 삭제, 삽입 및 업데이트의 DML(데이터 조작 언어) 작업
테이블 너비 제한 사항
테이블 정의에 의해 유효한 단일 행의 최대 크기를 기반으로 1MB의 행 너비 한도가 적용됩니다. 열 스키마의 합계가 1MB보다 크면 데이터 가상화 쿼리가 실패합니다.
데이터 형식 제한 사항
다음 데이터 형식은 Azure SQL Managed Instance 외부 테이블에서 사용할 수 없습니다.
geographygeometryhierarchyidimagetextnTextxml- 모든 사용자 정의 형식
잠금
SCHEMARESOLUTION 개체에 대한 공유 잠금입니다.
예제
A. 외부 테이블을 사용하여 Azure SQL Managed Instance 외부 데이터 쿼리
자세한 예제는 외부 데이터 원본 만들기를 참조하거나 Azure SQL Managed Instance 사용하여 데이터 가상화를 참조하세요.
데이터베이스 마스터 키가 없는 경우 만듭니다.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOSAS 토큰을 사용하여 데이터베이스 범위 자격 증명을 만듭니다. 관리 ID도 사용할 수 있습니다.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GO자격 증명을 사용하여 외부 데이터 원본을 만듭니다.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOEXTERNAL FILE FORMAT 및 EXTERNAL TABLE을 만들어 마치 로컬 테이블인 것처럼 데이터를 쿼리합니다.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
다음 단계
다음 문서에서 외부 테이블 및 관련 개념에 대해 자세히 알아보세요.