서비스 계층별 고가용성
Azure SQL의 가용성 옵션 및 기능을 이해하려면 서비스 계층을 이해해야 합니다. 선택하는 서비스 계층에 따라 배포하는 데이터베이스 또는 관리되는 인스턴스의 기본 아키텍처가 결정됩니다.
고려할 두 가지 구매 모델, 즉 DTU 및 vCore가 있습니다. 이 단원에서는 고가용성을 위해 vCore 서비스 계층 및 해당 아키텍처에 중점을 둡니다. DTU 모델의 기본 및 표준 계층은 범용에 해당하고 프리미엄 계층은 중요 비즈니스용에 해당한다고 볼 수 있습니다.
범용
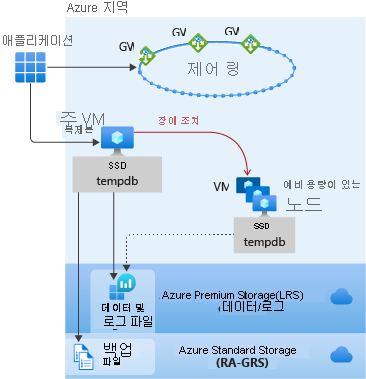
범용 서비스 계층의 데이터베이스 및 관리되는 인스턴스에는 동일한 가용성 아키텍처가 있습니다. 다음 그림을 가이드로 사용하여 먼저 ‘애플리케이션’ 및 ‘제어 링’을 고려합니다. 애플리케이션은 서버 이름에 연결되고, 이 서버는 VM에서 실행되는 올바른 서버에 대한 애플리케이션 연결을 가리키는 게이트웨이(GW)에 연결됩니다. 범용의 경우 주 복제본은 로컬로 연결된 SSD를 tempdb에 사용합니다. 데이터 및 로그 파일은 로컬 중복 스토리지(한 영역에 여러 사본이 위치함)인 Azure Premium Storage에 저장됩니다. 그런 다음 백업 파일은 Azure Standard Storage에 저장되며, 이 스토리지는 기본적으로 RA-GRS, 즉 RA-GRS는 여러 지역에 복사본이 있는 전역 중복 스토리지입니다.
학습 경로의 이전 모듈에서 설명한 대로 모든 Azure SQL은 Azure 백본 역할을 하는 Azure Service Fabric을 기반으로 빌드됩니다. Azure Service Fabric에서 장애 조치가 필요하다고 판단하는 경우 해당 장애 조치는 FCI(장애 조치 클러스터 인스턴스)의 장애 조치와 유사합니다. 서비스 패브릭은 예비 용량이 있는 노드를 검색하고 새 SQL Server 인스턴스를 실행합니다. 그런 다음, 데이터베이스 파일이 연결되고, 복구가 실행되며, 애플리케이션을 새 노드에 가리키도록 게이트웨이가 업데이트됩니다. 가상 네트워크 또는 수신기나 업데이트는 필요하지 않습니다. 이 기능은 기본 제공됩니다.
중요 비즈니스용
고려해야 할 다음 서비스 계층은 중요 비즈니스용으로, 모든 Azure SQL 서비스 계층(범용, 하이퍼스케일, 중요 비즈니스용) 중 최고의 성능과 가용성을 달성할 수 있습니다. 중요 비즈니스용은 짧은 대기 시간과 최소 가동 중지 시간이 필요한 중요 업무용 애플리케이션에 사용됩니다.
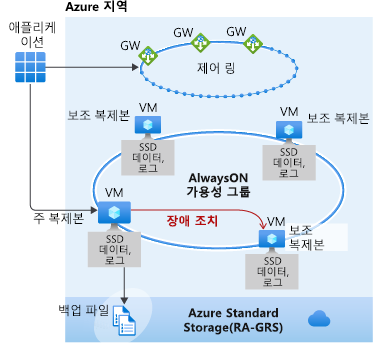
중요 비즈니스용 계층을 사용하는 것은 백그라운드에서 Always On AG(가용성 그룹)를 배포하는 것과 비슷합니다. 범용 계층과 달리 중요 비즈니스용의 데이터 및 로그 파일은 모두 직접 연결된 SSD에서 실행되므로 네트워크 대기 시간이 크게 줄어듭니다. (범용은 원격 스토리지를 사용합니다.) 이 AG에는 3개의 보조 복제본이 있습니다. 그중 하나를 읽기 전용 엔드포인트로 사용할 수 있습니다(추가 요금 없음). 보조 복제본 중 하나 이상이 트랜잭션 로그의 변경을 강화했을 때 트랜잭션이 커밋을 완료할 수 있습니다.
보조 복제본 중 하나를 사용한 읽기 스케일 아웃은 세션 수준 일관성을 지원하므로 복제본을 사용할 수 없어 연결 오류가 발생한 후 읽기 전용 세션이 다시 연결되면 읽기-쓰기 복제본을 사용하여 100% 최신 상태가 아닌 복제본으로 리디렉션될 수 있습니다. 마찬가지로 애플리케이션이 읽기-쓰기 세션을 사용하여 데이터를 쓰고 읽기 전용 세션을 사용하여 즉시 읽는 경우 최신 업데이트가 복제본에 즉시 표시되지 않을 수도 있습니다. 대기 시간은 비동기 트랜잭션 로그 다시 실행 작업으로 인해 발생합니다.
어떤 유형의 오류가 발생하고 서비스 패브릭이 장애 조치가 필요하다고 결정하는 경우 이미 복제본이 있고 데이터가 연결되어 있으므로 보조 복제본에 대한 장애 조치는 빠르게 수행됩니다. 장애 조치(failover)에서는 수신기가 필요하지 않습니다. 게이트웨이는 장애 조치(failover) 후에도 연결을 기본으로 리디렉션합니다. 이 전환은 빠르게 발생하며, Service Fabric은 또 다른 보조 복제본 실행을 처리합니다.
하이퍼스케일
하이퍼스케일 서비스 계층은 Azure SQL Database에서만 사용할 수 있습니다. 이 서비스 계층에는 고유한 아키텍처가 있는데, 계층화된 캐시 계층과 페이지 서버를 사용하여 데이터 파일에 직접 액세스하지 않고도 빠르게 데이터베이스 페이지에 액세스하는 기능을 확장하기 때문입니다.
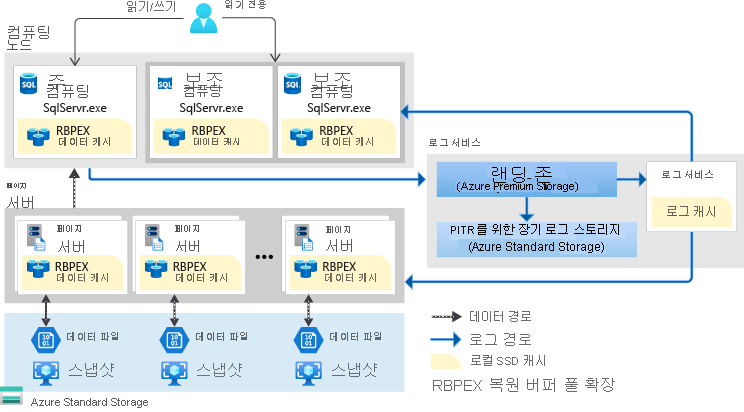
이 아키텍처에는 쌍을 이루는 페이지 서버가 사용되기 때문에 모든 데이터를 캐싱 계층에 넣도록 수평적으로 스케일링할 수 있습니다. 이 새로운 아키텍처를 사용하면 하이퍼스케일이 최대 100TB 크기의 데이터베이스를 지원할 수도 있습니다. 아키텍처에 스냅샷이 사용되므로, 크기에 관계없이 거의 즉각적인 데이터베이스 백업이 발생할 수 있습니다. 데이터베이스 복원에 몇 시간이나 며칠이 아닌 몇 분이 소요됩니다. 워크로드에 맞게 일정 시간에 스케일 업 또는 스케일 다운할 수도 있습니다.
이 아키텍처에서 로그 서비스를 끌어온 방법이 흥미롭습니다. 로그 서비스는 복제본 및 페이지 서버를 공급하는 데 사용됩니다. 로그 서비스가 랜딩 존으로 강화되면 트랜잭션이 커밋될 수 있으므로 커밋에 보조 컴퓨팅 복제본의 변경 내용을 사용할 필요가 없습니다. 다른 서비스 계층과 달리 보조 복제본을 사용할지 여부를 결정할 수 있습니다. 0~4개의 보조 복제본을 구성할 수 있으며 모두 읽기 스케일링에 사용할 수 있습니다.
다른 서비스 계층과 마찬가지로 Service Fabric이 필요하다고 결정하면 자동 장애 조치(failover)가 수행되지만 복구 시간은 보조 복제본의 존재 여부에 따라 달라집니다. 예를 들어 복제본이 없고 장애 조치가 발생하는 경우 시나리오는 범용 서비스 계층과 비슷합니다. 다시 말해서, 먼저 서비스 패브릭이 예비 용량을 찾아야 합니다. 하나 이상의 복제본이 있는 경우 복구는 더 빠르며 중요 비즈니스용 서비스 계층에 더 가깝게 맞춰집니다.
중요 비즈니스용은 짧은 대기 시간이 필요한 작은 로그 쓰기로 워크로드에 대해 최고의 성능과 가용성을 유지하지만 하이퍼스케일 서비스 계층을 사용하면 MB/초 측면에서 더 높은 로그 처리량을 얻을 수 있고, 가장 큰 데이터베이스 크기를 제공하며, 더 높은 수준의 읽기 스케일링을 위해 최대 4개의 보조 복제본을 제공합니다. 따라서 둘 중 하나를 선택할 때는 워크로드를 고려해야 합니다.