성능 및 보안 살펴보기
Azure 에코시스템은 Azure 가상 머신의 SQL Server 인스턴스에 대한 몇 가지 성능 및 보안 옵션을 제공합니다. 각 옵션은 워크로드의 용량 및 성능 요구 사항을 충족하는 다양한 디스크 유형과 같은 여러 기능을 제공합니다.
스토리지 고려 사항
온-프레미스 인스턴스든, 아니면 Azure VM에 설치되어 있든 간에 SQL Server에서 강력한 애플리케이션 성능을 제공하려면 뛰어난 스토리지 성능이 필요합니다. Azure는 워크로드의 요구 사항을 충족하는 다양한 스토리지 솔루션을 제공합니다. Azure에서 다양한 유형의 스토리지(Blob, 파일, 큐, 테이블)를 제공하기는 하지만, 대부분의 경우 SQL Server 워크로드는 Azure 관리 디스크를 사용합니다. 단, 장애 조치(failover) 클러스터 인스턴스는 파일 스토리지에서 빌드될 수 있고 백업은 Blob 스토리지를 사용합니다. Azure 관리 디스크는 Azure VM에 제공되는 블록 수준 스토리지 디바이스 역할을 합니다. 관리 디스크는 99.999% 가용성, 스케일링 가능한 배포(지역별로 구독당 최대 50,000개의 VM 디스크 사용 가능), 가용성 집합 및 영역과 통합을 비롯한 다양한 혜택을 제공하여 장애 발생 시 더 높은 수준의 복원력을 제공합니다.
Azure 관리 디스크는 모두 두 가지 유형의 암호화를 제공합니다. Azure 서버 쪽 암호화는 스토리지 서비스에서 제공되며 스토리지 서비스에서 제공되는 미사용 암호화 역할을 합니다. Azure Disk Encryption은 Windows의 BitLocker 및 Linux의 DM-Crypt를 사용하여 VM 내에서 OS 및 데이터 디스크 암호화를 제공합니다. 두 기술 모두 Azure Key Vault와 통합되며 사용자 고유의 암호화 키를 가져올 수 있도록 허용합니다.
각 VM에는 최소한 두 개의 다음 디스크가 연결되어 있습니다.
운영 체제 디스크 – 각 가상 머신에는 부팅 볼륨을 포함하는 운영 체제 디스크가 필요합니다. 이 디스크는 Windows 플랫폼 가상 머신의 경우 C: 드라이브, Linux의 경우 /dev/sda1입니다. 운영 체제는 자동으로 운영 체제 디스크에 설치됩니다.
임시 디스크 – 각 가상 머신은 임시 스토리지에 사용되는 디스크 1개를 포함합니다. 이 스토리지는 페이지 파일 또는 스왑 파일과 같이 지속성이 필요하지 않은 데이터에 사용하기 위한 것입니다. 임시 디스크이기 때문에 유지 관리 또는 가상 머신 재부팅 중에 손실되므로 데이터베이스 또는 트랜잭션 로그 파일과 같은 중요한 정보를 저장하는 데 사용해서는 안 됩니다. 이 드라이브는 Windows의 경우 D:\, Linux의 경우 /dev/sdb1로 탑재됩니다.
SQL Server를 실행하는 Azure VM에 데이터 디스크를 더 추가할 수도 있고 추가해야 합니다.
- 데이터 디스크 – 데이터 디스크라는 용어는 Azure Portal에서 사용되지만 사실상 VM에 추가된 추가 관리 디스크일 뿐입니다. 이 디스크를 풀링하여 Windows의 스토리지 공간 또는 Linux의 논리적 볼륨 관리를 통해 사용 가능한 IOPs 및 스토리지 용량을 늘릴 수 있습니다.
또한 각 디스크는 다음과 같은 여러 유형 중 하나일 수 있습니다.
| 기능 | Ultra Disk | 프리미엄 SSD | 표준 SSD | 표준 HDD |
|---|---|---|---|---|
| 디스크 유형 | SSD | SSD | SSD | HDD |
| 적합한 대상 | IO 집약적 워크로드 | 성능에 중요한 워크로드 | 경량 워크로드 | 백업, 중요하지 않은 워크로드 |
| 최대 디스크 크기 | 65,536GiB | 32,767GiB | 32,767GiB | 32,767GiB |
| 최대 처리량 | 2,000MB/s | 900MB/s | 750MB/s | 500MB/s |
| 최대 IOPS | 160,000 | 20,000 | 6,000 | 2,000 |
Azure의 SQL Server에 대한 모범 사례로, IOPs 및 스토리지 용량을 늘리기 위해 풀링된 프리미엄 디스크를 사용하는 것이 좋습니다. 데이터 파일은 Azure 디스크에서 읽기 캐싱을 사용하는 고유한 풀에 저장해야 합니다.
트랜잭션 로그 파일은 캐싱을 활용하지 않으므로 캐싱을 사용하지 않는 고유한 풀로 이동해야 합니다. TempDB는 필요에 따라 고유한 풀로 이동하거나 VM 임시 디스크를 사용할 수 있습니다. VM 임시 디스크는 VM이 실행되는 물리적 서버에 물리적으로 연결되어 있으므로 대기 시간이 짧습니다. 올바르게 구성된 프리미엄 SSD의 대기 시간은 10밀리초 미만입니다. 더 낮은 대기 시간이 필요한 중요 업무용 워크로드의 경우 울트라 SSD를 고려해야 합니다.
보안 고려 사항
Azure가 준수하는 몇 가지 업계 규정 및 표준이 있으므로 가상 머신에서 실행되는 SQL Server 준수 솔루션을 빌드할 수 있습니다.
Microsoft Defender for SQL
SQL용 Microsoft Defender를 통해 취약성 평가 및 보안 경고와 같은 Azure Security Center 보안 기능을 사용할 수 있습니다.
SQL Azure Defender를 사용하여 SQL Server 인스턴스 및 데이터베이스의 잠재적 취약성을 식별하고 완화할 수 있습니다. 취약성 평가 기능은 SQL Server 환경에서 잠재적인 위험을 감지하고 이를 해결하는 데 도움이 될 수 있습니다. 또한 보안 상태에 대한 인사이트를 제공하고 보안 문제를 해결하기 위한 실행 가능한 단계를 제공합니다.
Azure Security Center
Azure Security Center는 데이터 환경의 여러 보안 측면을 개선할 수 있는 기회를 평가하고 제공하는 통합 보안 관리 시스템입니다. Azure Security Center는 모든 하이브리드 클라우드 자산의 보안 상태에 대한 포괄적인 보기를 제공합니다.
성능 고려 사항
대부분의 기존 온-프레미스 SQL Server 성능 기능은 Azure VM(가상 머신)에서도 사용할 수 있습니다. 제공되는 옵션 중에는 데이터베이스 크기를 줄이면서 I/O 집약적 워크로드의 성능을 향상시킬 수 있는 데이터 압축이 있습니다. 마찬가지로 테이블 및 인덱스 분할은 큰 테이블의 쿼리 성능을 향상시키는 동시에 성능과 확장성을 향상시킬 수 있습니다.
테이블 분할
테이블 분할은 많은 이점을 제공하지만 테이블이 충분히 커져서 쿼리 성능이 저하되기 시작하는 경우에만 이 전략을 고려하는 경우가 많습니다. 테이블 분할에 적합한 테이블을 식별하는 것은 중단 및 개입을 줄이는 좋은 방법입니다. 파티션 열을 사용하여 데이터를 필터링하는 경우 전체 테이블이 아닌 데이터의 하위 집합에만 액세스합니다. 마찬가지로 분할된 테이블에 대한 유지 관리 작업은 특정 파티션의 특정 데이터를 압축하거나 인덱스의 특정 파티션을 다시 빌드하여 유지 관리 기간을 줄입니다.
테이블 파티션을 정의할 때는 다음 네 가지 주요 단계가 필요합니다.
- 파티션을 만들 때 관련된 파일을 정의하는 파일 그룹 만들기입니다.
- 지정된 열을 기반으로 파티션 규칙을 정의하는 파티션 함수 만들기입니다.
- 각 파티션의 파일 그룹을 정의하는 파티션 구성표 만들기입니다.
- 분할할 테이블입니다.
아래 예제에서는 2021년 1월 1일부터 2021년 12월 1일까지 파티션 함수를 만들고 파티션을 여러 파일 그룹에 분산하는 방법을 보여 줍니다.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
데이터 압축
SQL Server 데이터 압축을 위한 다양한 옵션을 제공합니다. SQL Server는 압축된 데이터를 8KB 페이지에 저장하지만 데이터가 압축되면 지정된 페이지에 더 많은 데이터 행을 저장할 수 있고, 이렇게 하면 쿼리 시 더 적은 페이지를 읽을 수 있습니다. 더 적은 페이지를 읽으면 두 가지 이점이 있습니다. 수행되는 물리적 IO의 양을 줄이고, 더 많은 행을 버퍼 풀에 저장할 수 있으므로 메모리를 보다 효율적으로 사용할 수 있습니다. 적절한 경우 데이터베이스 페이지 압축을 사용하도록 설정하는 것이 좋습니다.
압축에는 약간의 CPU 오버헤드가 필요하다는 단점이 있지만 대부분의 경우 스토리지 IO상의 이점이 추가 프로세서를 사용하는 것보다 훨씬 큽니다.
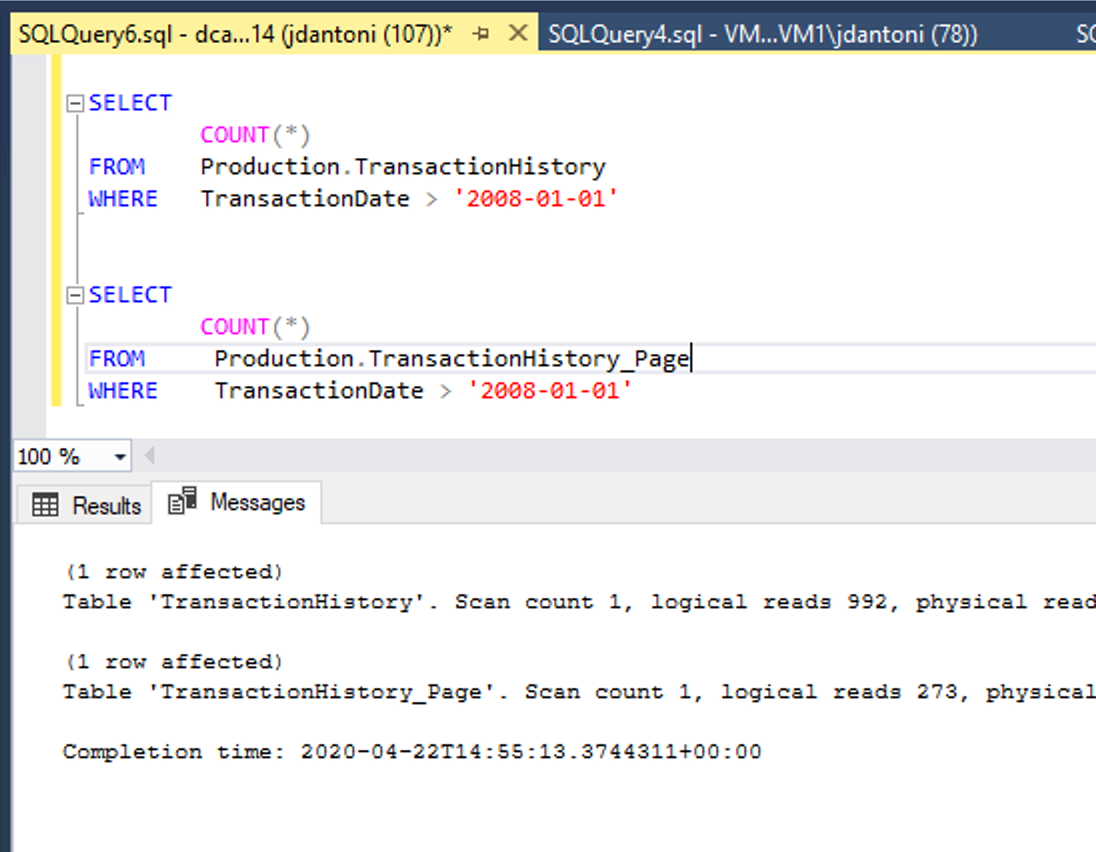
위의 이미지는 성능상의 이점을 보여줍니다. 해당 테이블에는 동일한 기본 인덱스가 있습니다. 유일한 차이점은 Production.TransactionHistory_Page 테이블의 클러스터형 인덱스와 비클러스터형 인덱스의 페이지가 압축된다는 것입니다. 페이지 압축 개체에 대한 쿼리는 압축되지 않은 개체를 사용하는 쿼리보다 72% 더 적은 논리적 읽기를 수행합니다.
압축은 SQL Server의 개체 수준에서 구현됩니다. 각 인덱스나 테이블은 개별적으로 압축될 수 있으며, 분할된 테이블 또는 인덱스 내에서 파티션을 압축할 수 있습니다. sp_estimate_data_compression_savings 시스템 저장 프로시저를 사용하여 저장할 공간의 크기를 평가할 수 있습니다. SQL Server 2019 이전에는 이 프로시저에서 columnstore 인덱스 또는 columnstore 보관 압축을 지원하지 않았습니다.
행 압축 - 매우 기본적인 것이며 많은 오버헤드가 발생하지 않습니다. 그러나 페이지 압축이 제공할 수 있는 것과 동일한 압축 크기(필요한 스토리지 공간의 비율 감소로 측정)는 제공하지 않습니다. 행 압축은 기본적으로 각 열의 개별 값을 해당 값을 저장하는 데 필요한 최소 공간 크기로 행에 저장합니다. 이는 integer, float 및 decimal과 같은 숫자 데이터 형식에 가변 길이 스토리지 형식을 사용하고, 가변 길이 형식을 사용하여 고정 길이 문자열을 저장합니다.
페이지 압축 - 모든 페이지가 페이지 압축을 적용하기 전에 행 압축되기 때문에 행 압축의 상위 집합입니다. 그런 다음 접두사 및 사전 압축이라는 기법을 조합하여 데이터에 적용합니다. 접두사 압축은 단일 열의 중복 데이터를 제거하고, 다시 페이지 헤더에 포인터를 저장합니다. 이 단계를 수행한 후에 사전 압축을 통해 페이지에서 반복된 값을 검색하고 이를 포인터로 대체하여 스토리지를 더 절약합니다. 데이터의 중복성이 클수록 데이터를 압축할 때 공간 절약 효과가 커집니다.
Columnstore 보관 압축 - Columnstore 개체는 항상 압축되지만 데이터에 Microsoft XPRESS 압축 알고리즘을 사용하는 보관 압축을 사용하여 추가로 압축할 수 있습니다. 해당 압축 유형은 자주 읽지는 않지만 규정 또는 비즈니스상의 이유로 보존되어야 하는 데이터에 사용하는 것이 가장 좋습니다. 이 데이터는 추가 압축되는 반면, 압축 풀기 시 CPU 비용이 IO 감소로 인한 성능 향상 효과보다 더 클 수 있습니다.
추가 옵션
다음은 프로덕션 워크로드에 대해 고려할 추가 SQL Server 기능 및 작업 목록입니다.
- 백업 압축 사용
- 데이터 파일에 인스턴트 파일 초기화를 사용하도록 설정합니다.
- 데이터베이스의 자동 확장을 제한합니다.
- 데이터베이스에 대해 자동 축소/자동 축소 사용 안 함
- 시스템 데이터베이스를 포함하여 모든 데이터베이스를 데이터 디스크로 이동
- SQL Server 오류 로그 및 추적 파일 디렉터리를 데이터 디스크로 이동
- 최대 SQL Server 메모리 제한 설정
- 메모리의 페이지 잠금 사용
- OLTP를 많이 사용하는 환경에서 임시 작업을 위해 최적화를 사용하도록 설정
- 쿼리 저장소를 사용하도록 설정합니다.
- SQL Server 에이전트 작업을 예약하여 DBCC CHECKDB, 인덱스 재구성, 인덱스 다시 빌드 및 통계 업데이트 작업 실행
- 트랜잭션 로그 파일의 상태 및 크기 모니터링 및 관리
성능 모범 사례에 대한 자세한 내용은 Azure VM의 SQL Server 모범 사례를 참조하세요.