Azure Database for PostgreSQL에 벡터 저장
의미 체계 검색을 실행하려면 벡터 데이터베이스에 저장된 포함 벡터가 필요합니다. Azure Database for PostgreSQL 유연한 서버는 vector 확장을 통해 벡터 데이터베이스로 사용할 수 있습니다.
vector 소개
오픈 소스 vector 확장은 PostgreSQL에 대한 벡터 저장, 유사성 쿼리 및 기타 벡터 작업을 제공합니다. 사용하도록 설정되면 vector 열을 만들어 다른 열과 함께 포함(또는 다른 벡터)을 저장할 수 있습니다.
/* Enable the extension. */
CREATE EXTENSION vector;
/* Create a table containing a 3d vector. */
CREATE TABLE documents (id bigserial PRIMARY KEY, embedding vector(3));
/* Create some sample data. */
INSERT INTO documents (embedding) VALUES
('[1,2,3]'),
('[2,1,3]'),
('[4,5,6]');
기존 테이블에 벡터 열을 추가할 수 있습니다.
ALTER TABLE documents ADD COLUMN embedding vector(3);
벡터 데이터가 있으면 일반 테이블 데이터와 함께 볼 수 있습니다.
# SELECT * FROM documents;
id | embedding
----+-----------
1 | [1,2,3]
2 | [2,1,3]
3 | [4,5,6]
vector 확장은 .NET, Python, Java 등 여러 언어를 지원합니다. 자세한 내용은 GitHub 리포지토리를 참조하세요.
C#에서 Npgsql을 사용하여 벡터가 [1, 2, 3]인 문서를 삽입하려면 다음과 같은 코드를 실행합니다.
var sql = "INSERT INTO documents (embedding) VALUES ($1)";
await using (var cmd = new NpgsqlCommand(sql, conn))
{
var embedding = new Vector(new float[] { 1, 2, 3 });
cmd.Parameters.AddWithValue(embedding);
await cmd.ExecuteNonQueryAsync();
}
벡터 삽입 및 업데이트
테이블에 벡터 열이 있으면 앞에서 언급한 대로 벡터 값을 사용하여 행을 추가할 수 있습니다.
INSERT INTO documents (embedding) VALUES ('[1,2,3]');
COPY 문을 사용하여 벡터를 대량으로 로드할 수도 있습니다(Python의 전체 예 참조).
COPY documents (embedding) FROM STDIN WITH (FORMAT BINARY);
벡터 열은 표준 열처럼 업데이트될 수 있습니다.
UPDATE documents SET embedding = '[1,1,1]' where id = 1;
코사인 거리 검색 수행
vector 확장은 벡터 v1과 v2 사이의 코사인 거리를 계산하기 위한 v1 <=> v2 연산자를 제공합니다. 결과는 0과 2 사이의 숫자입니다. 여기서 0은 "의미 체계상 동일"(거리 없음)을 의미하고 2는 "의미 체계상 반대"(최대 거리)를 의미합니다.
코사인 거리와 유사성이라는 용어를 확인할 수 있습니다. 코사인 유사성은 -1과 1 사이입니다. 여기서 -1은 "의미 체계상 반대"를 의미하고 1은 "의미 체계상 동일"을 의미합니다. similarity = 1 - distance에 유의하세요.
결과적으로 거리 오름차순으로 정렬된 쿼리는 가장 먼(가장 유사한) 결과를 먼저 반환하는 반면, 유사성 내림차순으로 정렬된 쿼리는 가장 유사한(가장 덜 먼) 결과를 먼저 반환합니다.
다음은 개념을 설명하기 위한 일부 벡터와 해당 거리 및 유사점입니다. 다음과 같이 실행하여 이 컴퓨팅을 직접 계산할 수 있습니다.
SELECT '[1,1]' <=> '[-1,-1]';
다음 벡터를 고려합니다.
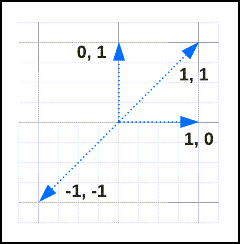
유사성과 거리는 다음과 같습니다.
| v1 | V2 | 거리 | 유사성 |
|---|---|---|---|
[1, 1] |
[1, 1] |
0 | 1 |
[1, 1] |
[-1, -1] |
2 | -1 |
[1, 0] |
[0, 1] |
1 | 0 |
벡터 [2, 3, 4]에 가까운 순서로 문서를 가져오려면 다음 쿼리를 실행합니다.
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance;
Results:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535
1 | [1,2,3] | 0.007416666029069763
2 | [2,1,3] | 0.05704583272761632
id=3이 포함된 문서가 쿼리와 가장 유사하며 그다음에는 id=1, 마지막에는 id=2가 옵니다.
가장 유사한 상위 N개 문서를 반환하려면 SELECT 쿼리에 LIMIT N 절을 추가합니다. 예를 들어, 가장 유사한 문서를 가져오려면:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance
LIMIT 1;
Results:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535