Azure AI 확장을 사용하여 포함 만들기
의미 체계 검색을 실행하려면 쿼리 포함을 쿼리된 항목의 포함과 비교해야 합니다. Azure Database for PostgreSQL - 유연한 서버용 azure_ai 확장은 Azure OpenAI와 통합되어 포함 벡터를 생성합니다.
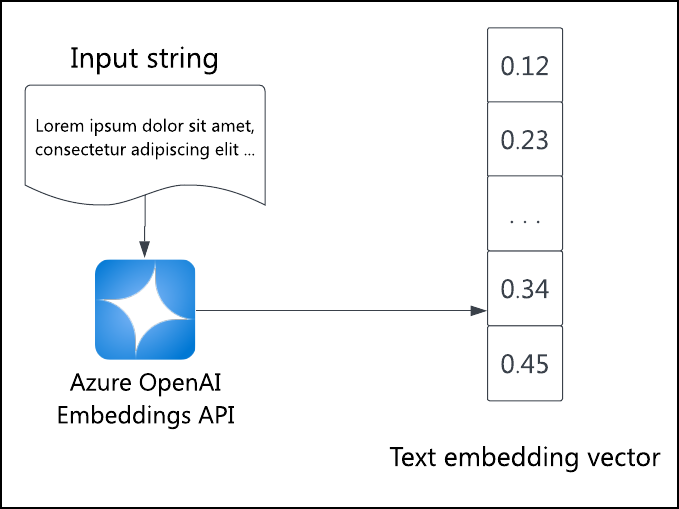
azure_ai 및 Azure OpenAI 소개
Azure AI용 Azure Database for PostgreSQL 유연한 확장은 Azure OpenAI 및 Azure Cognitive Services를 포함한 Azure AI 서비스와 통합하기 위한 사용자 정의 함수를 제공합니다.
Azure OpenAI 포함 API는 입력 텍스트의 포함 벡터를 생성합니다. 이 API를 사용하여 검색 중인 모든 항목에 대한 포함을 설정합니다. azure_ai 확장의 azure_openai 스키마를 사용하면 항목 포함을 초기화하거나 즉시 쿼리 포함을 만들지 여부에 관계없이 SQL에서 API를 쉽게 호출하여 포함을 만들 수 있습니다. 그런 다음 이러한 포함을 사용하여 벡터 유사성 검색, 즉 의미 체계 검색을 수행할 수 있습니다.
Azure OpenAI에서 azure_ai 확장 사용
PostgreSQL에서 Azure OpenAI 포함 API를 호출하려면 azure_ai 확장을 사용하도록 설정 및 구성하고, Azure OpenAI에 대한 액세스 권한을 부여하고, Azure OpenAI 모델을 배포해야 합니다. 자세한 내용은 Azure Database for PostgreSQL 유연한 서버의 Azure OpenAI 설명서를 참조하세요.
환경이 준비되고 확장이 허용 목록에 추가되면 다음 SQL을 실행합니다.
/* Enable the extension. */
CREATE EXTENSION azure_ai;
또한 OpenAI 서비스 리소스 엔드포인트 및 액세스 키를 구성해야 합니다.
SELECT azure_ai.set_setting('azure_openai.endpoint', '{your-endpoint-url}');
SELECT azure_ai.set_setting('azure_openai.subscription_key', '{your-api-key}}');
azure_ai 및 Azure OpenAI가 구성되면 포함을 가져오고 저장하는 것은 SQL 쿼리에서 함수를 호출하기만 하면 됩니다. description 열과 listing_vector 열이 있는 테이블 listings를 가정하면 다음 쿼리를 사용하여 모든 목록에 대한 포함을 생성하고 저장할 수 있습니다. {your-deployment-name}을 만든 모델에 대한 Azure OpenAI Studio의 배포 이름으로 바꿉니다.
UPDATE listings
SET listing_vector = azure_openai.create_embeddings('{your-deployment-name}', description, max_attempts => 5, retry_delay_ms => 500)
WHERE listing_vector IS NULL;
listing_vector 벡터 열은 언어 모델이 생성하는 차원 수와 동일해야 합니다.
문서 포함을 보려면 다음 쿼리를 실행합니다.
SELECT listing_vector FROM listings LIMIT 1;
결과는 부동 소수점 숫자의 벡터입니다. 출력을 더 쉽게 읽을 수 있도록 먼저 \x를 실행할 수 있습니다.
동적으로 쿼리 포함 생성
쿼리하려는 문서에 대한 포함이 있으면 의미 체계 검색 쿼리를 실행할 수 있습니다. 이렇게 하려면 쿼리 텍스트에 대한 포함도 생성해야 합니다.
azure_ai 확장의 azure_openai 스키마를 사용하면 SQL 내에서 포함을 생성할 수 있습니다. 예를 들어, 텍스트가 "걸을 수 있는 동네에서 장소를 찾아주세요"라는 쿼리와 의미 체계상 가장 유사한 상위 3개 목록을 찾으려면 다음 SQL을 실행합니다.
SELECT id, description FROM listings
ORDER BY listing_vector <=> azure_openai.create_embeddings('{your-deployment-name}', 'Find me places in a walkable neighborhood.')::vector
LIMIT 3;
<=> 연산자는 의미 체계 유사성 메트릭인 두 벡터 사이의 코사인 거리를 계산합니다. 벡터가 가까울수록 의미 체계상 더 유사합니다. 벡터가 멀수록 의미 체계상 더 다릅니다.
::vector 연산자는 생성된 포함을 PostgreSQL 벡터 배열로 변환합니다.
쿼리는 상위 3개 목록 ID 및 설명을 반환하며 순위는 낮은 것부터 더 다른 것 순으로(유사한 것 순으로) 순위가 매겨집니다.