원본 시스템 최적화 - 고급
이러한 고급 지침은 VLDB 시스템의 원본 내보내기에 도움이 될 수 있습니다.
Oracle 행 ID 테이블 분할
SAP에서는 WHR 파일의 WHERE 절을 ROW ID 값으로 변환하는 스크립트가 포함된 SAP Note #1043380을 릴리스했습니다. 또는 Oracle에서 Oracle R3load로 마이그레이션하도록 SWPM이 구성된 경우 최신 버전의 SAPInst는 ROW ID 분할 WHR 파일을 자동으로 생성합니다. SWPM에서 생성한 STR 및 WHR 파일은 OS/DB 마이그레이션 프로세스의 모든 측면과 마찬가지로 운영 체제 및 데이터베이스와 독립적입니다.
OSS 노트에는 "대상 데이터베이스가 Oracle이 아닌 다른 데이터베이스인 경우 ROWID 테이블 분할을 사용할 수 없습니다"라는 문장이 포함되어 있습니다. 엄밀히 말해서, R3load 덤프 파일은 데이터베이스 및 운영 체제에 대해 독립적입니다. 하지만 SQL Server에서는 가져오기가 진행되는 동안 패키지를 다시 시작할 수 없다는 제한이 있습니다. 이 시나리오에서는 전체 테이블을 삭제하고 테이블에 대한 모든 패키지를 다시 시작해야 합니다. 항상 특정 분할 테이블에 대한 R3load 작업을 중지하고, 테이블을 TRUNCATE하고, 분할 R3load가 중단되는 경우 전체 가져오기 프로세스를 다시 시작하는 것이 좋습니다. 이렇게 하는 이유는 R3load에 기본 제공되는 복구 프로세스에서 단일 행 단위 DELETE 문을 수행하여 중단되는 R3load 프로세스에서 로드한 레코드를 제거하기 때문입니다. 이 작업은 느리며 데이터베이스에서 차단/잠금 상황이 발생하는 경우가 많습니다. 경험상 이 특정 테이블의 가져오기를 처음부터 시작하는 것이 더 빠르기 때문에 SAP Note #1043380에 언급된 제한은 제한이 아닙니다.
ROW ID는 가동 중지 시간 동안 분할을 계산해야 한다는 단점이 있습니다. 자세한 내용은 SAP Note #1043380을 참조하세요.
원본 데이터베이스의 여러 "클론"을 만들고 병렬로 내보내기
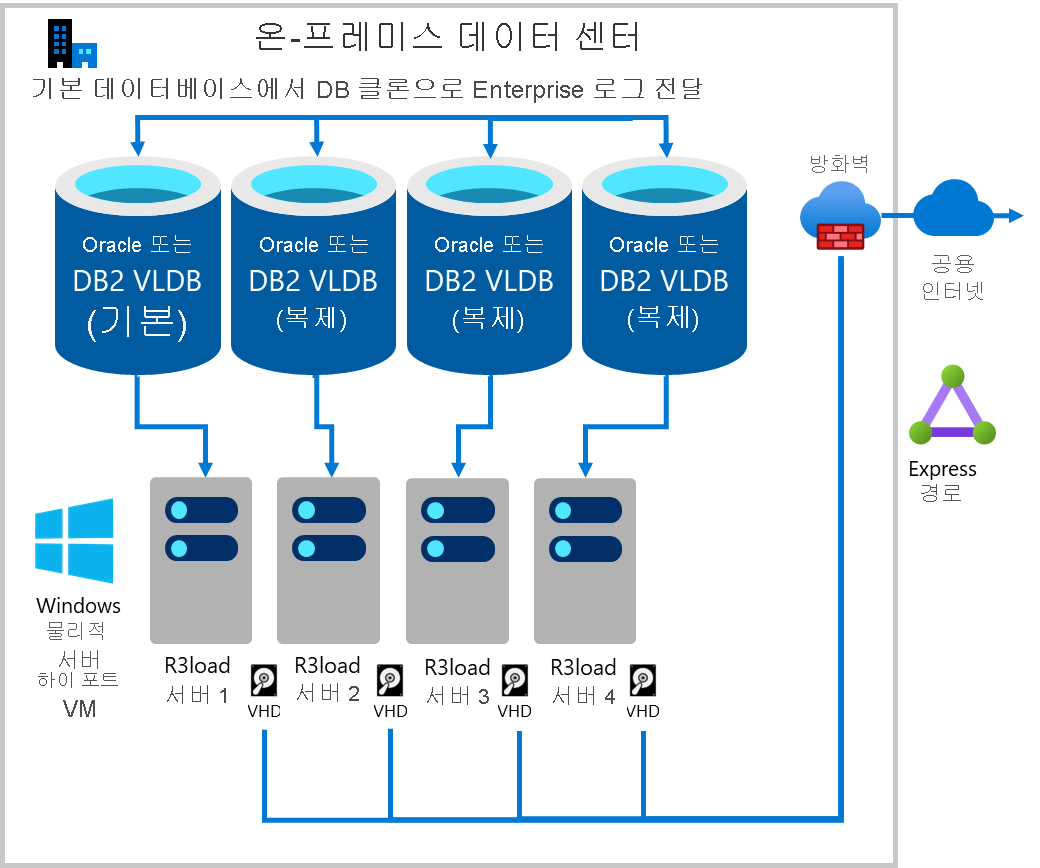
내보내기 성능을 높이는 한 가지 방법은 동일한 데이터베이스의 여러 복사본에서 내보내는 것입니다. 서버, 네트워크 및 스토리지를 포함하고 있는 기본 인프라를 확장할 수 있는 경우 이 방법은 선형적으로 스케일링 가능한 경향이 있습니다. 동일한 데이터베이스의 복사본 2개에서 내보내면 2배, 복사본 4개에서 보내면 4배 빠릅니다. 마이그레이션 모니터는 각 데이터베이스 "클론"에서 선택한 수의 테이블을 내보내도록 구성됩니다. 다음 예제에서 내보내기 워크로드는 4개의 데이터베이스 서버 각각에 약 25%씩 분산됩니다.
- DB 서버 1 및 내보내기 서버 1 - 가장 큰 1~4 테이블 전용(원본 데이터베이스에서 데이터 배포의 기울기에 따라 다름)
- DB 서버 2 및 내보내기 서버 2 - 테이블 분할을 사용하는 테이블 전용
- DB 서버 3 및 내보내기 서버 3 - 테이블 분할을 사용하는 테이블 전용
- DB 서버 4 및 내보내기 서버 4 – 나머지 테이블
데이터베이스가 정확하게 동기화되도록 주의를 기울여야 합니다. 그렇지 않으면 데이터가 손실되거나 데이터 불일치가 발생할 수 있습니다. 제공된 단계를 정확하게 따르면 데이터 무결성이 유지됩니다.
이 방법은 표준 상용 Intel 하드웨어를 사용하므로 간단하고 저렴하지만 독점 UNIX 하드웨어를 실행하는 고객도 사용할 수 있습니다. 샌드박스, 개발, QAS, 교육 및 DR 시스템이 이미 Azure로 이동된 경우에는 OS/DB 마이그레이션 프로젝트의 중간에 상당히 많은 하드웨어 리소스를 사용할 수 있습니다. "클론" 서버의 하드웨어 리소스가 동일해야 한다는 엄격한 요구 사항은 없습니다. 적절한 CPU, RAM, 디스크 및 네트워크 성능을 갖추면 클론을 추가할 때마다 성능이 향상됩니다.
추가적인 내보내기 성능이 여전히 필요한 경우 BC-DB-MSS에서 SAP 인시던트를 열어 내보내기 성능을 높이기 위한 추가 단계를 진행합니다(고급 컨설턴트에 한함).
여러 병렬 내보내기를 구현하는 단계는 다음과 같습니다.
- 주 데이터베이스를 백업하고 "n"개의 서버에 복원합니다(여기서 n은 클론의 수). 이 예제에서는 n = 3개의 서버를 가정하여 총 4개의 DB 서버를 만듭니다.
- 3개의 서버에 백업을 복원합니다.
- 주 원본 DB 서버에서 3개의 대상 "클론" 서버로 로그 전달을 설정합니다.
- 며칠 동안 로그 전달을 모니터링하면서 로그 전달이 안정적으로 작동하는지 확인합니다.
- 가동 중지 시간이 시작되면 PAS를 제외한 모든 SAP 애플리케이션을 종료합니다. 모든 일괄 처리가 중지되고 모든 RFC 트래픽이 중지되었는지 확인합니다.
- 트랜잭션 SM02에서 "Checkpoint PAS Running" 텍스트를 입력합니다. 그러면 TEMSG 테이블이 업데이트됩니다.
- 주 애플리케이션 서버를 중지합니다. 이제 SAP가 종료되었습니다. 원본 DB에서 더 이상 쓰기 작업을 수행할 수 없습니다. 원본 DB에 연결된 비-SAP 애플리케이션이 없어야 합니다(그럴 리는 없지만 DB 수준에 SAP가 아닌 세션이 있는지 확인하세요).
- 주 DB 서버에서
SELECT EMTEXT FROM [schema].TEMSG;쿼리를 실행합니다. - 네이티브 DBMS 수준 문
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”를 실행합니다(정확한 구문은 원본 DBMS에 따라 다를 수 있음. INSERT into EMTEXT) - 자동 트랜잭션 로그 백업을 중지합니다. 주 DB 서버에서 마지막 트랜잭션 로그 백업을 수동으로 실행합니다. 로그 백업이 복제 서버에 복사되었는지 확인합니다.
- 3개 노드 전부에서 최종 트랜잭션 로그 백업을 복원합니다.
- 3개의 "클론" 노드에서 데이터베이스를 복구합니다.
- 4개 노드 전부에서 다음 SELECT 문을 실행합니다.
SELECT EMTEXT FROM [schema].TEMSG; - 4개 DB 서버(주 서버 1개, 클론 서버 3개) 각각의 SELECT 문 실행 결과 화면을 캡처합니다. 각 호스트 이름을 신중하게 포함시켜야 합니다. 호스트 이름은 클론 DB와 주 DB가 동일하고 같은 시점의 같은 데이터를 포함하고 있다는 것을 증명하는 데 사용됩니다.
- 각 Intel R3load 내보내기 서버에서 export_monitor.bat를 시작합니다.
- 덤프 파일을 Azure 프로세스로 복사하기 시작합니다(AzCopy 또는 Robocopy).
- R3load Azure Virtual Machines에서 import_monitor.bat를 시작합니다.
다음 다이어그램은 기존 프로덕션 DB 서버 로그를 "클론" 데이터베이스로 전달하는 것을 보여줍니다. 각 DB 서버에는 하나 이상의 Intel R3load 서버가 있습니다.