SQL Server Always On 환경에서 자동 장애 조치(failover) 문제 해결
이 문서는 Microsoft SQL Server에서 자동 장애 조치(failover) 중에 발생하는 문제를 해결하는 데 도움이 됩니다.
원래 제품 버전: SQL Server
원래 KB 번호: 2833707
요약
자동 장애 조치(failover)를 위해 SQL Server Always On 가용성 그룹을 구성할 수 있습니다. 주 복제본을 호스팅하는 SQL Server 인스턴스에서 상태 문제가 감지되면 주 역할을 자동 장애 조치 파트너(보조 복제본)로 전환할 수 있습니다. 그러나 보조 복제본을 항상 주 역할로 전환할 수는 없습니다. 경우에 따라 역할로만 RESOLVING 전환할 수 있습니다. 이 경우 주 복제본이 정상 상태로 반환되지 않는 한 복제본에는 주 역할이 없습니다. 또한 가용성 데이터베이스에 액세스할 수 없습니다.
이 문서에서는 자동 장애 조치(failover)에 실패한 몇 가지 일반적인 원인을 나열하고 이러한 오류의 원인을 진단하기 위해 수행할 수 있는 단계를 설명합니다.
자동 장애 조치(failover)가 성공적으로 트리거되는 경우의 증상
주 복제본을 호스팅하는 SQL Server 인스턴스에서 자동 장애 조치(failover)가 트리거되면 보조 복제본은 역할로 전환한 다음 주 역할로 전환됩니다 RESOLVING . 프로세스가 성공했지만 오류 항목은 다음 텍스트와 유사한 SQL Server 로그 보고서에 기록됩니다.
The state of the local availability replica in availability group '\<Group name>' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'
The state of the local availability replica in availability group '\<Group name>' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'

참고 항목
보조 복제본이 상태에서 상태로 PRIMARY_NORMAL 성공적으로 RESOLVING_NORMAL 전환됩니다.
자동 장애 조치(failover)가 실패한 경우의 증상
자동 장애 조치(failover) 이벤트가 성공하지 못하면 보조 복제본이 주 역할로 성공적으로 전환되지 않습니다. 따라서 가용성 복제본은 이 복제본 RESOLVING 이 상태에 있다고 보고합니다. 또한 가용성 데이터베이스는 상태에 있다고 NOT SYNCHRONIZING 보고하며 애플리케이션은 이러한 데이터베이스에 액세스할 수 없습니다.
예를 들어 다음 이미지에서 SQL Server Management Studio는 자동 장애 조치 프로세스에서 RESOLVING 보조 복제본을 주 역할로 전환할 수 없기 때문에 보조 복제본이 상태에 있다고 보고합니다.
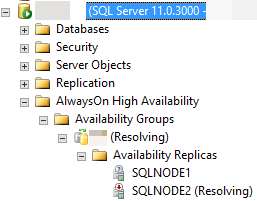
다음 섹션에서는 자동 장애 조치(failover)가 실패할 수 있는 몇 가지 가능한 이유와 각 원인을 진단하는 방법에 대해 설명합니다.
사례 1: "지정된 기간의 최대 오류" 값이 소진됨
가용성 그룹에는 지정된 기간 속성의 최대 실패와 같은 Windows 클러스터 리소스 속성이 있습니다. 이 속성은 여러 노드 오류가 발생할 때 클러스터된 리소스의 무기한 이동을 방지하는 데 사용됩니다.
장애 조치(failover) 실패의 원인인지 조사하고 진단하려면 Windows 클러스터 로그(Cluster.log)를 검토한 다음 속성을 확인합니다.
1단계: Windows 클러스터 로그의 데이터 검토(Cluster.log)
Windows PowerShell을 사용하여 주 복제본을 호스팅하는 클러스터 노드에서 Windows 클러스터 로그를 생성합니다. 이렇게 하려면 주 복제본을 호스팅하는 SQL Server 인스턴스의 관리자 권한 PowerShell 창에서 다음 cmdlet을 실행합니다.
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15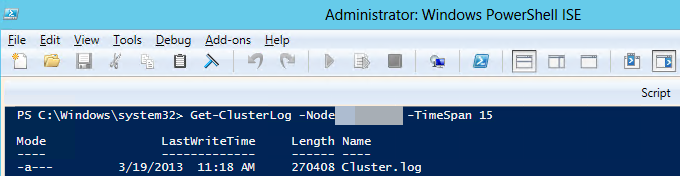
[! 참고 사항]
- 이 단계의 매개 변수는
-TimeSpan 15진단 중인 문제가 이전 15분 동안 발생했다고 가정합니다. - 기본적으로 로그 파일은 %WINDIR%\cluster\reports에 만들어집니다.
- 이 단계의 매개 변수는
메모장에서 Cluster.log 파일을 열어 Windows 클러스터 로그를 검토합니다.
메모장에서 찾기 편집>을 선택한 다음 파일 끝에 있는 "failoverCount" 문자열을 검색합니다. 결과에서 다음 메시지와 유사한 메시지를 찾아야 합니다.
그룹 <리소스 이름>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2를 장애 조치하지 않음

2단계: 지정된 기간 속성의 최대 오류 확인
장애 조치(failover) 클러스터 관리자를 시작합니다.
탐색 창에서 역할을 선택합니다.
역할 창에서 클러스터된 리소스를 마우스 오른쪽 단추로 클릭한 다음 속성을 선택합니다.
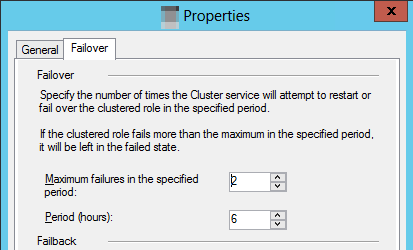
장애 조치 (failover ) 탭을 선택하고 지정된 기간 값에서 최대 실패를 선택합니다.
참고 항목
기본 동작은 클러스터된 리소스가 6시간 이내에 세 번 실패하는 경우 실패한 상태로 유지되도록 지정합니다. 가용성 그룹의 경우 복제본이 상태에 남아
RESOLVING있음을 의미합니다.
결론
로그를 분석한 후 failoverCount 값 3이 computedFailoverThreshold 값 2보다 큰 것을 확인할 수 있습니다. 따라서 Windows 클러스터는 가용성 그룹 리소스의 장애 조치(failover) 작업을 장애 조치(failover) 파트너에게 완료할 수 없습니다.
해결 방법
이 문제를 해결하려면 지정된 기간 값에서 최대 오류를 늘입니다.
참고 항목
이 값을 늘리면 문제가 해결되지 않을 수 있습니다. 짧은 기간 내에 가용성 그룹이 여러 번 실패하는 더 중요한 문제가 있을 수 있습니다. 기본적으로 이 기간은 15분입니다. 이 값을 늘리면 가용성 그룹이 더 많은 시간 동안 실패하고 실패한 상태로 남을 수 있습니다. 자동 장애 조치(failover)가 계속 발생하는 이유를 확인하려면 적극적인 문제 해결을 사용하는 것이 좋습니다.
사례 2: NT 기관\SYSTEM 계정 권한 부족
SQL Server 데이터베이스 엔진 리소스 DLL은 ODBC를 사용하여 상태를 모니터링하여 주 복제본을 호스팅하는 SQL Server 인스턴스에 연결합니다. 이 연결에 사용되는 로그온 자격 증명은 로컬 SQL Server NT AUTHORITY\SYSTEM 로그인 계정입니다. 기본적으로 이 로컬 로그인 계정에는 다음 권한이 부여됩니다.
- 가용성 그룹 변경
- SQL 연결
- 서버 상태 보기
NT AUTHORITY\SYSTEM 로그인 계정에 자동 장애 조치(failover) 파트너(보조 복제본)에 대한 이러한 권한이 없는 경우 자동 장애 조치(failover)가 발생할 때 SQL Server에서 상태 검색을 시작할 수 없습니다. 따라서 보조 복제본은 주 역할로 전환할 수 없습니다. 원인인지 조사하고 진단하려면 Windows 클러스터 로그를 검토합니다. 이렇게 하려면 다음 단계를 수행하세요.
Windows PowerShell을 사용하여 클러스터 노드에서 Windows 클러스터 로그를 생성합니다. 이렇게 하려면 주 역할로 전환되지 않은 보조 복제본을 호스팅하는 SQL Server 인스턴스의 관리자 권한 PowerShell 창에서 다음 cmdlet을 실행합니다.
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
메모장에서 Cluster.log 파일을 열어 Windows 클러스터 로그를 검토합니다.
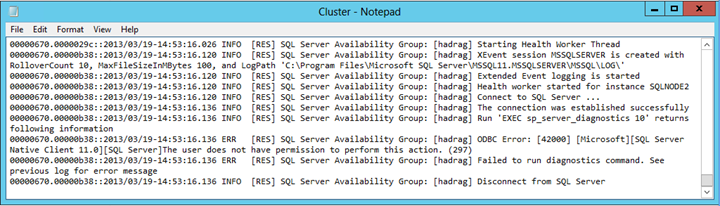
다음 텍스트와 유사한 오류 항목을 찾습니다.
진단 명령을 실행하지 못했습니다. 사용자에게 이 동작을 수행할 권한이 없습니다.
결론
Cluster.log 파일은 SQL Server가 진단 명령을 실행할 때 사용 권한 문제가 있다고 보고합니다. 이 예제에서는 자동 장애 조치(failover) 쌍의 보조 복제본을 호스팅하는 SQL Server 인스턴스의 로그인 계정에서 NT AUTHORITY\SYSTEM 서버 상태 보기 권한을 제거하여 오류가 발생했습니다.
해결 방법
이 문제를 해결하려면 SQL Server 데이터베이스 엔진 리소스 DLL의 상태 검색을 위해 로그인 계정에 충분한 권한을 NT AUTHORITY\SYSTEM 부여합니다.
사례 3: 가용성 데이터베이스가 SYNCHRONIZED 상태가 아닙니다.
자동으로 장애 조치(failover)하려면 가용성 그룹에 정의된 모든 가용성 데이터베이스가 주 복제본과 보조 복제본 사이의 상태여야 SYNCHRONIZED 합니다. 자동 장애 조치(failover)가 발생하면 데이터 손실이 없도록 하려면 이 동기화 조건을 충족해야 합니다. 따라서 가용성 그룹의 가용성 데이터베이스가 동기화 또는 NOT SYNCHRONIZED 상태에 있는 경우 자동 장애 조치(failover)는 보조 복제본을 주 역할로 성공적으로 전환하지 않습니다.
자동 장애 조치(failover)에 필요한 조건에 대한 자세한 내용은 자동 장애 조치(failover)에 필요한 조건을 참조하고 동기-커밋 복제본은 장애 조치(failover) 및 장애 조치(failover) 모드(Always On 가용성 그룹)의 두 설정 섹션을 지원합니다.
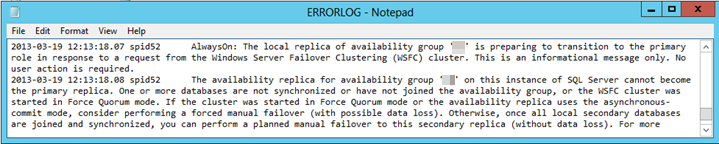
장애 조치(failover) 실패의 원인인지 조사하고 진단하려면 SQL Server 오류 로그를 검토합니다. 다음 텍스트와 유사한 오류 항목을 찾아야 합니다.
하나 이상의 데이터베이스가 동기화되지 않았거나 가용성 그룹에 조인되지 않았습니다.
가용성 데이터베이스 SYNCHRONIZED 가 상태에 있는지 확인하려면 다음 단계를 수행합니다.
보조 복제본에 연결합니다.
다음 SQL 스크립트를 실행하여 장애 조치(failover)하지 않은 가용성 그룹의 모든 가용성 데이터베이스에 대한 값을 확인
is_failover_ready합니다.참고 항목
가용성 데이터베이스의 값이 0이면 자동 장애 조치(failover)를 방지할 수 있습니다. 이 값은 가용성 데이터베이스가 아님
SYNCHRONIZED을 나타냅니다.SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.dm_hadr_availability_replica_states)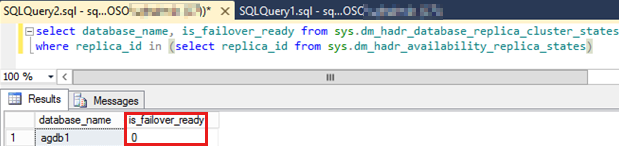
결론
가용성 그룹의 자동 장애 조치(failover)가 성공하려면 모든 가용성 데이터베이스가 상태에 있어야 합니다 SYNCHRONIZED . 가용성 모드에 대한 자세한 내용은 Always On 가용성 그룹의 가용성 모드를 참조 하세요.
사례 4: 복제본이 암호화용으로 구성되지 않았지만 보조 복제본(대상 주 복제본)의 클라이언트 프로토콜에 대해 "프로토콜 암호화 강제 적용" 구성이 선택됨
장애 조치(failover) 중에 주 서버가 상태 문제를 감지하면 장애 조치(failover) 파트너(보조 복제본)의 클러스터 DLL이 로컬 복제본에 연결하여 상태 모니터링을 시작하려고 합니다. 이는 기본 역할로의 전환의 일부입니다. 보조 복제본이 암호화용으로 구성되지 않았지만 강제 프로토콜 암호화 설정이 클라이언트 구성에서 실수로 설정된 경우 연결이 실패하고 장애 조치(failover)가 발생할 수 없습니다.
이 구성을 확인하려면 다음을 수행합니다.
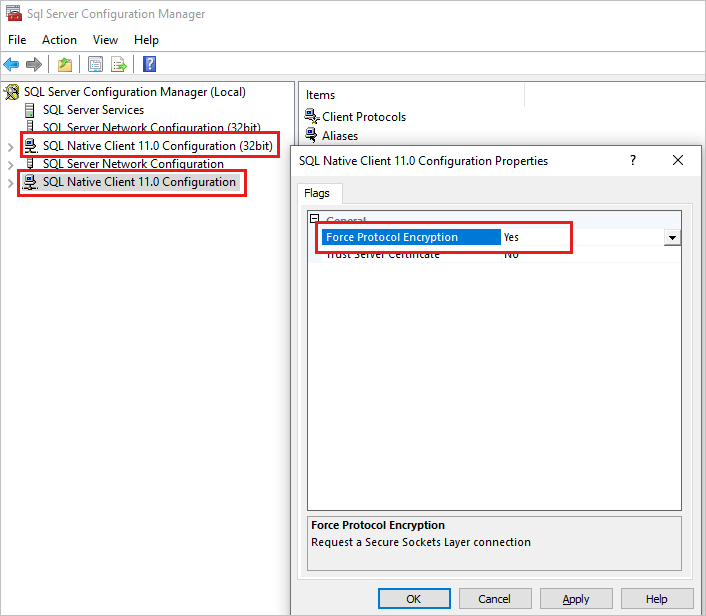
- SQL Server 구성 관리자를 시작합니다.
- 왼쪽 창에서 SQL Native Client 11.0 구성을 마우스 오른쪽 단추로 클릭한 다음 속성을 선택합니다.
- 대화 상자에서 프로토콜 암호화 강제 설정을 선택합니다. 예로 설정된 경우 값을 아니요로 변경합니다.
- 장애 조치(failover)를 다시 테스트합니다.
결론
SQL Server Always On 상태 모니터링은 로컬 ODBC 연결을 사용하여 SQL Server 상태를 모니터링합니다. SQL Server 네트워크 구성 섹션의 SQL Server 구성 관리자 암호화를 강제 적용하도록 SQL Server 자체가 구성된 경우에만 SQL Server 구성 관리자 클라이언트 구성 섹션에서 프로토콜 암호화 강제 적용을 사용하도록 설정해야 합니다. 자세한 내용은 데이터베이스 엔진에 대해 암호화 연결 사용을 참조하세요.
사례 5: 보조 복제본 또는 노드의 성능 문제로 인해 Always On 상태 검사가 실패합니다.
주 복제본에서 보조 복제본으로 장애 조치하기 전에 SQL Server 데이터베이스 엔진 리소스 DLL이 보조 복제본에 연결하여 복제본의 상태를 확인합니다. 보조 복제본의 성능 문제로 인해 이 연결이 실패하면 자동 장애 조치(failover)가 발생하지 않습니다.
이것이 원인인지 조사하고 진단하려면 다음 단계를 수행합니다.
보조 복제본의 클러스터 로그를 검토하여 "서버 연결 열기 지연으로 인해 로그인 프로세스를 완료할 수 없습니다."라는 오류 메시지를 확인합니다.
0000110c.00002bcc::2020/08/06-01:17:54.943 INFO [RCM] move of group AOCProd01AG from CO2ICMV3SQL09(1) to CO2ICMV3SQL10(2) of type MoveType::Manual is about to succeed, failoverCount=3, lastFailoverTime=2020/08/05-02:08:54.524 targeted=true 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]Unable to complete login process due to delay in opening server connection (0) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Could not connect to SQL Server (rc -1) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] SQLDisconnect returns following information 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08003] [Microsoft][ODBC Driver Manager] Connection not open (0) 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Failed to connect to SQL Server 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RHS] Online for resource AOCProd01AG failed.이 상황은 사용량이 많은 기존 워크로드가 있는 SQL Server 보조 복제본에 장애 조치(failover)가 수행되는 경우에 발생할 수 있습니다. 이로 인해 HADR 상태 연결 요청 시도에 대한 SQL Server의 응답이 지연되고 장애 조치(failover) 시도가 실패할 수 있습니다.
시스템 스케줄러에 부담이 있는지 확인하려면 SQL Server Management Studio를 사용하여 보조 복제본에서 다음 스크립트를 실행합니다.
USE MASTER GO WHILE 1=1 BEGIN PRINT convert(varchar(20), getdate(),120) DECLARE @max INT; SELECT @max = max_workers_count FROM sys.dm_os_sys_info; SELECT GETDATE() AS 'CurrentDate', @max AS 'TotalThreads', SUM(active_Workers_count) AS 'CurrentThreads', @max - SUM(active_Workers_count) AS 'AvailableThreads', SUM(runnable_tasks_count) AS 'WorkersWaitingForCpu', SUM(work_queue_count) AS 'RequestWaitingForThreads' --SUM(current_workers_count) AS 'AssociatedWorkers' FROM sys.dm_os_Schedulers WHERE STATUS = 'VISIBLE ONLINE'; wait for delay '0:0:15' END다음은 이전 쿼리의 샘플 출력입니다.
CurrentDate TotalThreads CurrentThreads AvailableThreads WorkersWaitingForCpu RequestWaitingForThreads 2020-10-06 01:27:01.337 1,612 361 855 33 0 2020-10-06 01:27:08.340 1,612 1412 -196 22 76 2020-10-06 01:27:15.340 1,612 1304 -88 2 161 2020-10-06 01:27:22.340 1,612 1242 -26 21 185 2020-10-06 01:27:29.343 1,612 13:46 -130 19 476 2020-10-06 01:27:36.350 1,612 1350 -134 9 630 2020-10-06 01:27:43.353 1,612 13:46 -130 13 539 2020-10-06 01:27:50.360 1,612 1378 -162 5 328 2020-10-06 01:27:57.360 1,612 197 1019 0 0 높은 값이 보고
WorkersWaitingForCpu되고RequestWaitingForThreads일정 경합이 발생하고 SQL Server가 적시에 현재 워크로드를 서비스할 수 없음을 나타냅니다.
해결 방법
이 문제가 발생하는 경우 보조 복제본에서 워크로드의 균형을 조정하거나 이러한 워크로드를 실행하는 컴퓨터에서 처리 능력(프로세서 추가)을 늘리는 것이 좋습니다.
다른 실패한 장애 조치(failover) 이벤트 문제 해결
장애 조치(failover) 중에 새 주 복제본의 상태를 모니터링하려면 주 역할로 전환하는 SQL Server 인스턴스에 AlwaysOn 상태 모니터링을 로컬로 연결해야 합니다.
이 문서에서 설명하는 일반적인 이유 외에도 이 연결 시도가 실패할 수 있는 다른 많은 이유가 있습니다. 실패한 장애 조치(failover) 시도를 추가로 조사하려면 장애 조치(failover) 파트너(장애 조치(failover)할 수 없는 복제본)에서 클러스터 로그를 검토합니다.
Windows PowerShell을 사용하여 클러스터 노드에서 Windows 클러스터 로그를 생성합니다. 이렇게 하려면 주 역할로 전환되지 않은 보조 복제본을 호스팅하는 SQL Server 인스턴스의 관리자 권한 PowerShell 창에서 다음 cmdlet을 실행합니다. 클러스터 로그는 최근 60분 동안 생성됩니다.
Get-ClusterLog -Node <SQLServerNodeName> -TimeSpan 60Windows 클러스터 로그를 검토하려면 메모장에서 Cluster.log 파일을 엽니다.
실패한 장애 조치(failover) 이벤트 중에 나타나는 "SQL Server에 연결" 문자열을 검색합니다.
스레드 ID(다음 스크린샷 참조)를 사용하여 후속 로그인 메시지를 검토하여 로그인 이벤트와 관련된 이벤트의 상관 관계를 지정합니다. 다음 예제에서는 "SQL Server에 연결"에 대한 검색을 보여줍니다. 또한 스레드 ID(왼쪽)를 사용하여 연결 시도가 실패한 이유를 설명하는 다른 진단을 찾는 방법을 보여 줍니다.
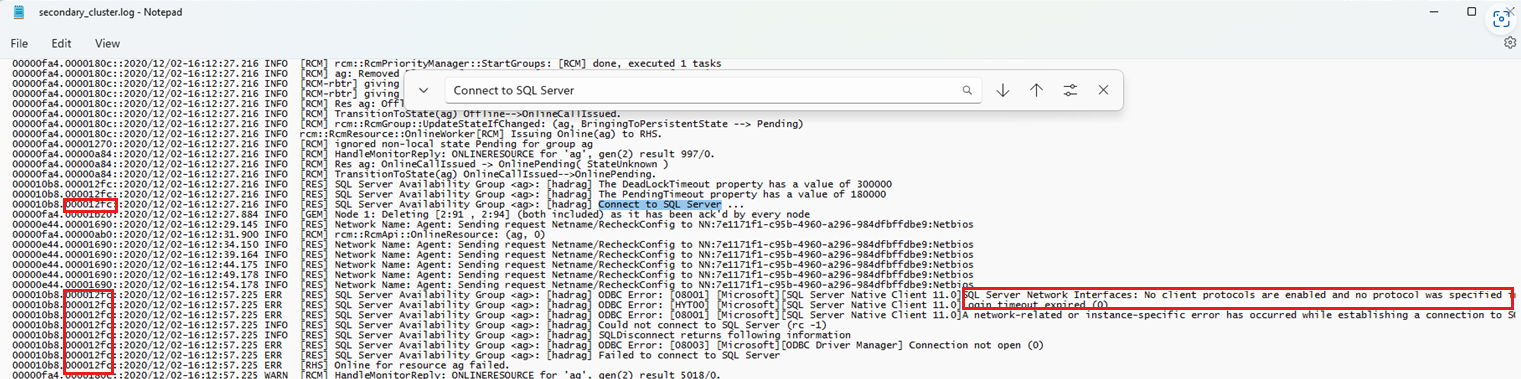

다음 예제에서는 새 주 복제본에 대한 연결 실패를 보여 줍니다.
예제 집합 1
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: No client protocols are enabled and no protocol was specified in the connection
string [xFFFFFFFF]. (268435455)
해결 방법
SQL Server 구성 관리자 시작한 다음 SQL Native Client Configuration에 대한 클라이언트 프로토콜에서 공유 메모리 또는 TCP/IP가 사용하도록 설정되어 있는지 확인합니다.
예제 집합 2
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: Server doesn't support requested protocol [xFFFFFFFF]. (268435455)
해결 방법
SQL Server 구성 관리자 시작한 다음 SQL Native Client Configuration에 대한 클라이언트 프로토콜에서 공유 메모리 또는 TCP/IP가 사용하도록 설정되어 있는지 확인합니다.
예제 집합 3
000010b8.00001764::2020/12/02-16:52:49.808 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Cannot alter the availability
group 'ag', because it does not exist or you do not have permission. (15151)
000010b8.00000fd0::2020/12/02-17:01:14.821 ERR [RES] SQL Server Availability Group: [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297)
000010b8.00001838::2020/12/02-17:10:04.427 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Login failed for user
'SQLREPRO\NODE2$'. Reason: The account is disabled. (18470)
해결 방법