Always On 가용성 그룹의 복구 큐 문제 해결
이 문서에서는 복구 큐와 관련된 문제에 대한 해결 방법을 제공합니다.
복구 큐란?
가용성 그룹 데이터베이스의 주 복제본에서 이루어진 변경 사항은 동일한 가용성 그룹 내 정의된 모든 보조 복제본으로 전송됩니다. 이러한 변경 내용이 보조 복제본에 도착하면 먼저 가용성 그룹 데이터베이스의 트랜잭션 로그 파일에 기록됩니다. 그런 다음 Microsoft SQL Server는 복구 또는 다시 실행 작업을 사용하여 데이터베이스 파일을 업데이트합니다.
가용성 그룹에 대한 변경 내용이 도착하여 데이터베이스 트랜잭션 로그 파일에서 복구할 수 있는 것보다 빠르게 강화되면 복구 큐가 형성됩니다. 이 큐는 데이터베이스에 복구 및 복원되지 않은 강화된 트랜잭션 로그 트랜잭션으로 구성됩니다.
복구(다시 실행) 큐의 증상 및 효과
주 복제본과 보조 복제본을 쿼리하면 다른 결과가 반환됩니다.
보조 복제본을 쿼리하는 읽기 전용 워크로드는 부실 데이터를 쿼리할 수 있습니다. 복구 큐가 발생하는 경우 동일한 데이터를 쿼리할 때 주 복제본 데이터베이스의 데이터 변경 내용이 보조 데이터베이스에 반영되지 않을 수 있습니다.
변경 내용은 보조 데이터베이스에 도착하여 데이터베이스 로그 파일에 기록되지만 변경 내용이 복구되고 데이터베이스 파일로 복원될 때까지 쿼리되지 않습니다. 복구 작업을 통해 이러한 변경 내용을 읽을 수 있습니다.
자세한 내용은 보조 복제본 의 데이터 대기 시간 섹션인 "Always On 가용성 그룹의 가용성 모드 간 차이점"을 참조하세요.
장애 조치(failover) 시간이 길거나 RTO가 초과됨
RTO(복구 시간 목표)는 조직에서 처리할 수 있는 최대 데이터베이스 가동 중지 시간입니다. 또한 RTO는 중단 후 조직에서 데이터베이스에 대한 액세스 권한을 얼마나 빨리 회복할 수 있는지도 설명합니다. 장애 조치(failover)가 발생할 때 보조 복제본에 상당한 복구 큐가 있는 경우 복구 시간이 더 오래 걸릴 수 있습니다. 복구 후 데이터베이스는 주 역할로 전환되고 장애 조치(failover) 전에 존재했던 데이터베이스의 상태를 나타냅니다. 복구 시간이 길면 장애 조치(failover) 후 프로덕션이 다시 시작하는 시간을 지연할 수 있습니다.
다양한 진단 기능 보고서 가용성 그룹 복구 큐
복구 큐의 경우 SSMS(SQL Server Management Studio)의 Always On 대시보드가 비정상 가용성 그룹을 보고할 수 있습니다.
복구(다시 실행) 큐를 확인하는 방법
복구 큐는 주 복제본에서 Always On 대시보드를 사용하거나 주 복제본 또는 보조 복제본에서 sys.dm_hadr_database_replica_states DMV(동적 관리 뷰)를 사용하여 확인할 수 있는 데이터베이스별 측정값입니다. 성능 모니터 카운터는 복구 큐 및 복구 속도를 확인합니다. 이러한 카운터는 보조 복제본에 대해 확인해야 합니다.
다음 몇 가지 섹션에서는 가용성 그룹 데이터베이스 복구 큐를 적극적으로 모니터링하는 방법을 제공합니다.
쿼리 sys.dm_hadr_database_replica_states
DMV는 sys.dm_hadr_database_replica_states 각 가용성 그룹 데이터베이스에 대한 행을 보고합니다. 보고서의 한 열은 .입니다 redo_queue_size. 이 값은 킬로바이트 단위로 측정된 복구 큐 크기입니다. 다음 쿼리와 유사한 쿼리를 설정하여 30초마다 복구 큐 크기의 추세를 모니터링할 수 있습니다. 쿼리는 주 복제본에서 실행됩니다. 조건자를 is_local=0 사용하여 보조 복제본에 대한 데이터를 보고합니다. 여기서는 redo_rate 관련이 redo_queue_size 있습니다.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
출력의 모양은 다음과 같습니다.

Always On 대시보드에서 복구 큐 검토
복구 큐를 검토하려면 다음 단계를 수행합니다.
SSMS 개체 탐색기 가용성 그룹을 마우스 오른쪽 단추로 클릭하여 SSMS에서 Always On 대시보드를 엽니다.
대시보드 표시를 선택합니다.
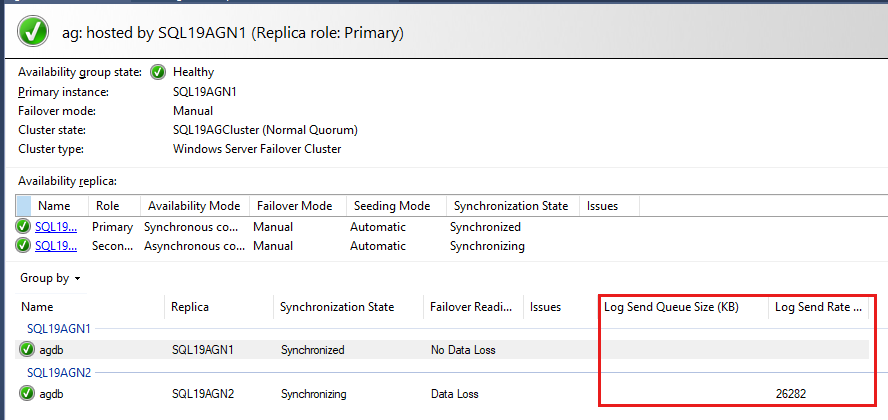
가용성 그룹 데이터베이스는 마지막으로 나열되며 데이터베이스에 보고된 일부 데이터가 있습니다. 다시 실행 큐 크기(KB) 및 다시 실행 속도(KB/초)는 기본적으로 나열되지 않지만 다음 단계의 스크린샷과 같이 이 보기에 추가할 수 있습니다.
이러한 카운터를 추가하려면 데이터베이스 보고서 위의 헤더를 마우스 오른쪽 단추로 클릭하고 사용 가능한 열 목록에서 선택합니다.
다시 실행 큐 크기(KB) 및 다시 실행 속도(KB/초)를 추가하려면 다음 스크린샷에서 빨간색으로 강조 표시된 헤더를 마우스 오른쪽 단추로 클릭합니다.
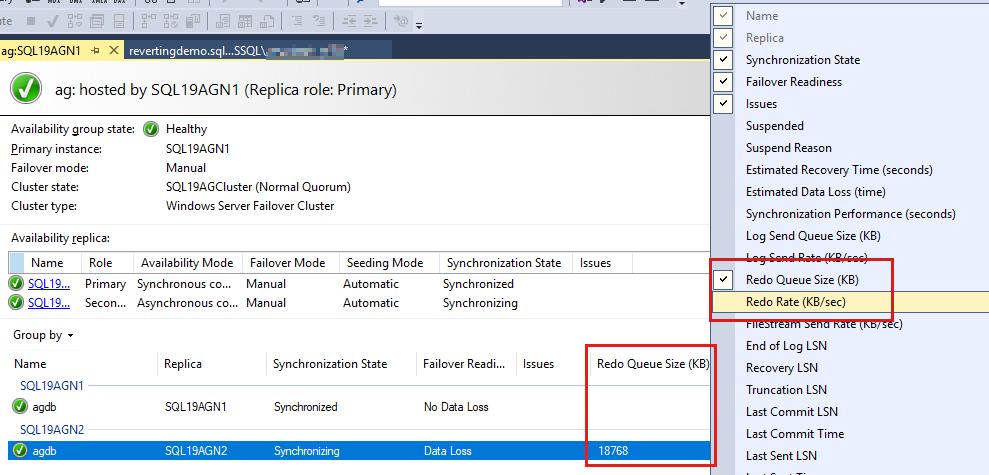
기본적으로 Always On 대시보드는 60초마다 다시 실행 큐 크기(KB) 및 다시 실행 속도(KB/초)를 자동으로 새로 고칩니다.


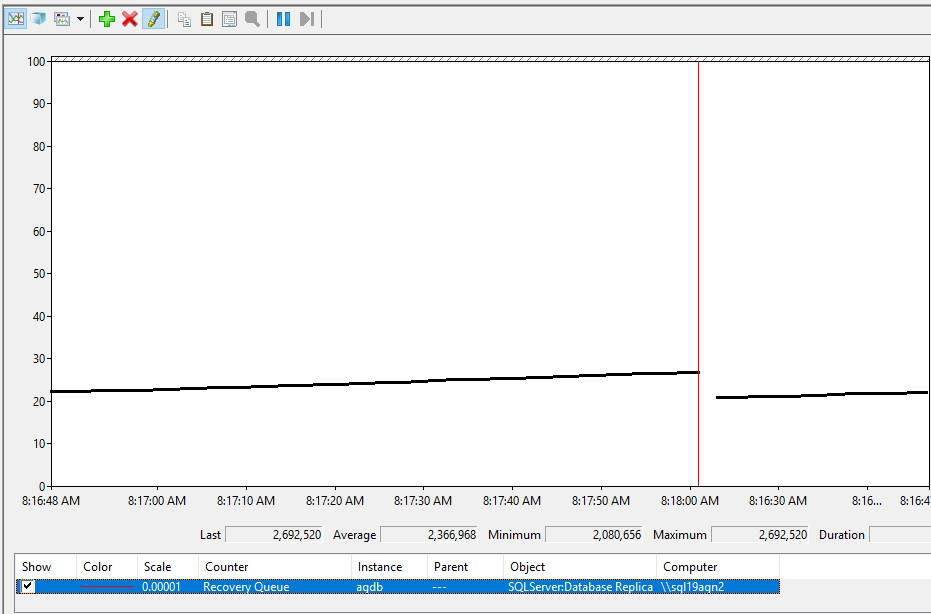
성능 모니터 복구 큐 검토
복구 큐 크기는 각 보조 복제본 및 데이터베이스에 고유합니다. 따라서 가용성 그룹 데이터베이스의 복구 큐를 검토하려면 다음 단계를 수행합니다.
보조 복제본에서 성능 모니터 엽니다.
추가(카운터) 단추를 선택합니다.
사용 가능한 카운터에서 SQLServer:Database 복제본을 선택한 다음, 복구 큐 및 다시 실행 바이트/초 카운터를 선택합니다.
인스턴스 목록 상자에서 복구 큐에 대해 모니터링할 가용성 그룹 데이터베이스를 선택합니다.
추가>확인을 선택합니다.
복구 큐를 늘리는 모양은 다음과 같습니다.

복구 큐 값 해석
이 섹션에서는 이전 섹션에서 결정한 복구 큐와 관련된 값을 해석하는 방법을 설명합니다.
복구 큐에 문제가 있는 경우는 언제인가요? 얼마나 많은 복구 큐를 허용해야 하나요?
복구 큐가 값 0을 보고하는 경우 해당 보고서 당시 복구 큐가 발생하지 않는다고 가정할 수 있습니다. 그러나 프로덕션 환경이 사용 중인 경우 복구 큐가 정상 AlwaysOn 환경에서도 0이 아닌 값을 자주 보고하는 것을 관찰해야 합니다. 일반적인 프로덕션 중에는 이 값이 0과 0이 아닌 값 사이에서 변동하는 것을 관찰해야 합니다.
시간이 지남에 따라 복구 큐가 증가하는 것을 관찰하는 경우 추가 조사가 보장됩니다. 이 추가 작업은 무언가가 변경되었음을 나타냅니다. 복구 큐의 급격한 증가를 관찰하는 경우 다음 측정값이 문제 해결에 유용합니다.
- 로그 다시 실행 속도(KB/초) (AlwaysOn 대시보드)
- DMV sys.dm_hadr_database_replica_states Redo_rate
다시 실행 속도에 대한 기준 요금 가져오기
정상 AlwaysOn 성능 중에 사용 중인 가용성 그룹 데이터베이스의 다시 실행 속도를 모니터링합니다. 일반적으로 바쁜 업무 시간에는 어떤 모습일까요? 대규모 트랜잭션(인덱스 다시 작성, ETL 프로세스)이 시스템에서 더 높은 트랜잭션 처리량을 유도하는 유지 관리 기간 동안 이러한 비율은 어떻게 됩니까? 복구 큐 증가를 관찰할 때 이러한 값을 비교하여 변경된 내용을 확인할 수 있습니다. 워크로드가 평소보다 클 수 있습니다. 다시 실행 속도가 낮으면 이유를 확인하기 위해 추가 조사가 필요할 수 있습니다.
워크로드 볼륨이 중요합니다.
대규모 워크로드(예: 100만 행에 대한 UPDATE 문, 1테라바이트 테이블의 인덱스 다시 작성 또는 수백만 개의 행을 삽입하는 ETL 일괄 처리)가 있는 경우 즉시 또는 시간이 지남에 따라 일부 복구 큐가 증가해야 합니다. 이는 가용성 그룹 데이터베이스에서 갑자기 많은 수의 변경이 수행될 때 발생합니다.
복구(다시 실행) 큐를 진단하는 방법
특정 보조 복제본 가용성 그룹 데이터베이스에 대한 복구 큐를 식별한 후 보조 복제본에 연결한 다음 쿼리 sys.dm_exec_requests 하여 복구 스레드를 wait_time 확인 wait_type 합니다. 루프에서 실행할 수 있는 쿼리는 다음과 같습니다. 하나 이상의 대기 유형에 대한 빈도가 높고 이러한 대기 유형에 대한 대기 시간도 찾고 있습니다. 다음은 매 초마다 실행되고 가용성 그룹 "agdb"에 대한 대기 유형 및 대기 시간을 보고하는 샘플 쿼리입니다.
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
Important
의미 있는 대기 유형 출력의 경우 이전에 설명한 방법 중 하나를 사용하여 이 조건을 모니터링할 때 복구 큐가 증가하는 것을 관찰해야 합니다.
이 예제에서는 일부 I/O 관련 대기 유형이 보고됩니다(PAGEIOLATCH_UP, PAGEIOATCH_EX). 모니터링하여 다음 열에 보고된 대로 이러한 대기 유형에 가장 wait_times 큰 값이 계속 있는지 확인합니다.

SQL Server 다시 실행 대기 유형
대기 유형이 식별되면 다음 문서 SQL Server 2016/2017: 가용성 그룹 보조 복제본 다시 실행 모델 및 성능 - Microsoft Tech Community 를 복구 큐를 유발하는 일반적인 대기 유형에 대한 상호 참조로 검토하고 문제를 해결하는 데 도움을 요청합니다.
보조 보고 서버에서 차단된 다시 실행 스레드
솔루션이 보조 복제본의 가용성 그룹 데이터베이스에 대해 보고(쿼리)를 지시하는 경우 이러한 읽기 전용 쿼리는 스키마 안정성(Sch-S) 잠금을 획득합니다. 이러한 Sch-S 잠금은 다시 실행 스레드가 스키마 수정(Sch-M) 잠금("스키마 수정 잠금"이라고도 함)을 획득하거나 LCK_M_SCH_MDDL(데이터 정의 언어)을 변경하는 ALTER TABLE 것을 차단할 ALTER INDEX수 있습니다. 차단된 다시 실행 스레드는 차단이 해제될 때까지 로그 레코드를 적용할 수 없습니다. 이로 인해 복구 큐가 발생할 수 있습니다.
차단된 다시 실행의 기록 증거를 확인하려면 SSMS를 사용하여 보조 복제본에서 AlwaysOn_health Xevent 추적 파일을 엽니다. lock_redo_blocked 이벤트를 찾습니다.

성능 모니터 사용하여 복구 큐에 대한 차단된 다시 실행 영향을 적극적으로 모니터링합니다. SQL Server::D atabase Replica::Redo blocked/sec 및 SQL Server::D atabase Replica::Recovery Queue 카운터를 추가합니다. 다음 스크린샷은 주 복제본에 대해 실행되는 명령을 보여 ALTER TABLE ALTER COLUMN 주며 장기 실행 쿼리는 보조 복제본의 동일한 테이블에 대해 실행됩니다. Redo blocked/sec 카운터는 명령이 실행됨을 ALTER TABLE ALTER COLUMN 나타냅니다. 장기 실행 쿼리가 보조 복제본의 동일한 테이블에서 실행되는 동안 주 복제본의 후속 변경으로 인해 복구 큐가 증가합니다.

다시 실행 스레드가 획득하려고 시도하는 스키마 수정 잠금 대기 유형을 모니터링합니다. 이렇게 하려면 앞에서 설명한 쿼리를 사용하여 다시 실행 작업에 대해 보고된 대기 유형을 확인합니다 sys.dm_exec_requests. 진행 중인 다시 실행 차단에서 증가하는 대기 시간을 LCK_M_SCH_M 관찰할 수 있습니다.

단일 스레드 다시 실행
SQL Server는 Microsoft SQL Server 2016에서 보조 복제본 데이터베이스에 대한 병렬 복구를 도입했습니다. SQL Microsoft Server 2012 또는 Microsoft SQL Server 2014를 실행할 때 복구 큐가 발생하는 경우 이후 버전의 프로그램으로 업그레이드하여 프로덕션 환경에서 다시 실행 성능을 향상시킬 수 있습니다.
단일 스레드 다시 실행은 병렬 복구 아키텍처가 사용되는 고급 SQL Server 버전에서도 발생할 수 있습니다. 이러한 버전에서 SQL Server 인스턴스는 병렬 다시 실행에 최대 100개의 스레드를 사용할 수 있습니다. 프로세서 및 가용성 그룹 데이터베이스의 수에 따라 병렬 다시 실행 스레드는 최대 100개의 총 스레드까지 할당됩니다. 100개 스레드 다시 실행 제한에 도달하면 가용성 그룹의 일부 데이터베이스에 단일 다시 실행 스레드가 할당됩니다.
가용성 그룹 데이터베이스가 병렬 복구를 사용하고 있는지 확인하려면 보조 복제본에 연결하고 다음 쿼리를 사용하여 가용성 그룹 데이터베이스에 대한 복구를 적용하는 행(스레드) 수를 확인합니다. 다음 예제에서 "agdb" 데이터베이스가 단일 스레드이고 해당 명령인 DB STARTUP경우 복구 워크로드가 병렬 복구의 이점을 누릴 수 있습니다.
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

데이터베이스에서 단일 스레드 다시 실행을 사용하는지 확인하는 경우 앞에서 설명한 알고리즘을 검토하여 SQL Server가 병렬 복구 전용 작업자 스레드 100개 수를 초과하는지 확인합니다. 이러한 조건은 "agdb" 데이터베이스가 복구를 위해 단일 스레드만 사용하는 이유일 수 있습니다.
이제 SQL Server 2022는 워크로드에 따라 병렬 복구를 위해 작업자 스레드가 할당되도록 새 병렬 복구 알고리즘을 사용합니다. 이렇게 하면 사용 중인 데이터베이스가 단일 스레드 복구에 남아 있을 가능성이 없습니다. 자세한 내용은 "Always On 가용성 그룹에 대한 필수 구성 요소, 제한 및 권장 사항"의 가용성 그룹 별 스레드 사용량 섹션을 참조하세요.