미러 가속 패리티
저장소 공간 미러 및 패리티라는 두 가지 기본 기술을 사용하여 데이터에 내결함성을 제공할 수 있습니다. 저장소 공간 Direct에서 ReFS는 미러 가속 패리티를 도입하여 미러 복원력과 패리티 복원력을 모두 사용하는 볼륨을 만들 수 있습니다. 미러 가속 패리티는 성능을 희생하지 않고도 저렴하고 공간 효율적인 스토리지를 제공합니다.
배경
미러 및 패리티 복원력 체계에는 기본적으로 다른 스토리지 및 성능 특성이 있습니다.
- 미러 복원력을 통해 사용자는 빠른 쓰기 성능을 얻을 수 있지만 각 복사본에 대한 데이터를 복제하는 것은 공간 효율적이지 않습니다.
- 반면 패리티는 모든 쓰기에 대한 패리티를 다시 계산해야 하므로 임의 쓰기 성능이 저하됩니다. 그러나 패리티는 사용자가 더 큰 공간 효율성으로 데이터를 저장할 수 있도록 허용합니다. 자세한 내용은 스토리지 공간 내결함성을 참조하세요.
따라서 미러는 성능에 민감한 스토리지를 제공하는 데 걸리며 패리티는 향상된 스토리지 용량 사용률을 제공합니다. 미러 가속 패리티에서 ReFS는 각 복원력 유형의 이점을 활용하여 단일 볼륨 내에서 두 복원력 체계를 결합하여 용량 효율과 성능에 민감한 스토리지를 모두 제공합니다.
미러 가속 패리티의 데이터 회전
ReFS는 실시간으로 미러와 패리티 간에 데이터를 적극적으로 회전합니다. 이렇게 하면 들어오는 쓰기를 미러에 빠르게 쓴 다음 패리티로 회전하여 효율적으로 저장할 수 있습니다. 이렇게 하면 콜드 데이터가 패리티에 효율적으로 저장되는 동안 들어오는 IO가 미러에서 신속하게 서비스되어 동일한 볼륨 내에서 최적의 성능과 손실 비용 스토리지를 모두 제공합니다.
미러와 패리티 간에 데이터를 회전하기 위해 ReFS는 볼륨을 회전 단위인 64MiB 영역으로 논리적으로 나눕니다. 아래 이미지는 영역으로 나뉘어진 미러 가속 패리티 볼륨을 보여 줍니다.
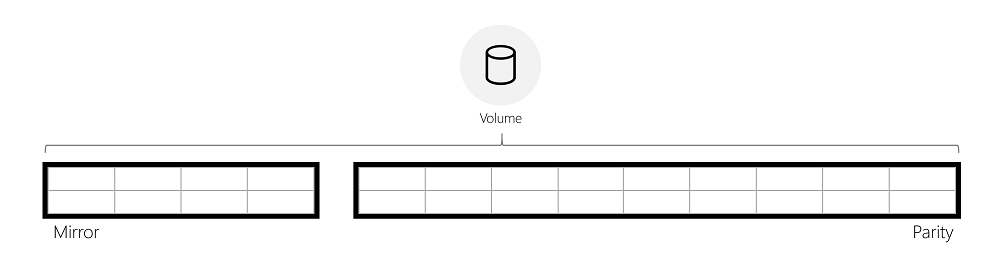
ReFS는 미러 계층이 지정된 용량 수준에 도달하면 전체 영역을 미러에서 패리티로 회전하기 시작합니다. ReFS는 데이터를 미러에서 패리티로 즉시 이동하는 대신 가능한 한 오랫동안 데이터를 미러에 유지하므로 ReFS가 데이터에 대한 최적의 성능을 계속 제공할 수 있습니다(아래 "IO 성능" 참조).
데이터가 미러에서 패리티로 이동되면 데이터를 읽고 패리티 인코딩을 계산한 다음 해당 데이터가 패리티에 기록됩니다. 아래 애니메이션에서는 회전하는 동안 지우기 코딩된 영역으로 변환되는 3방향 미러된 영역을 사용하여 이를 보여 줍니다.
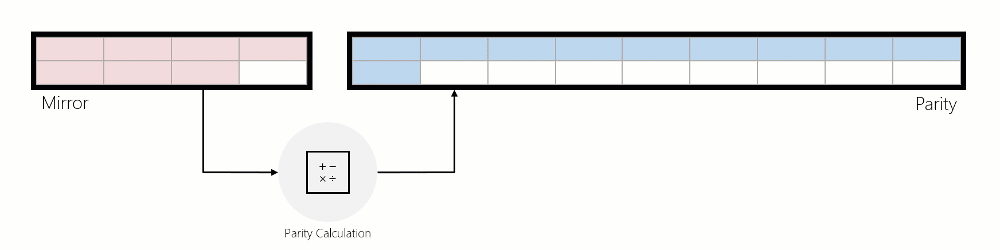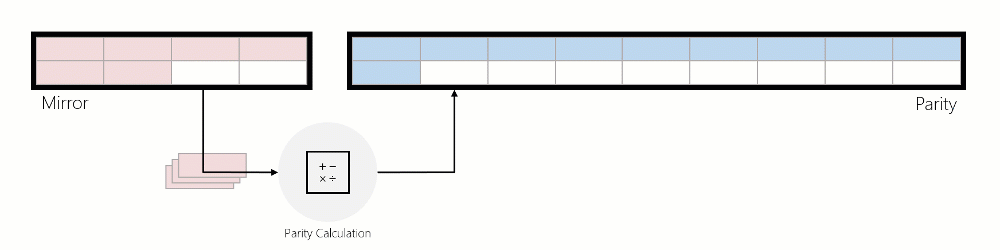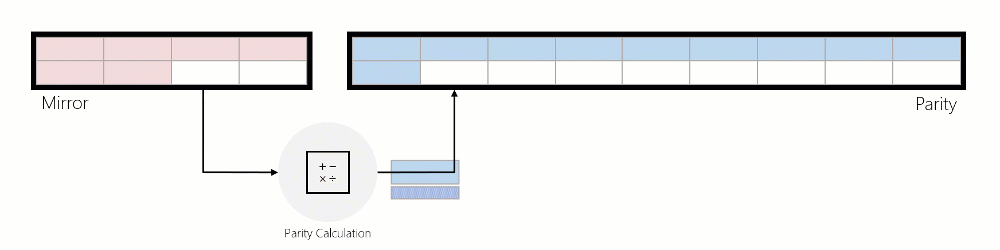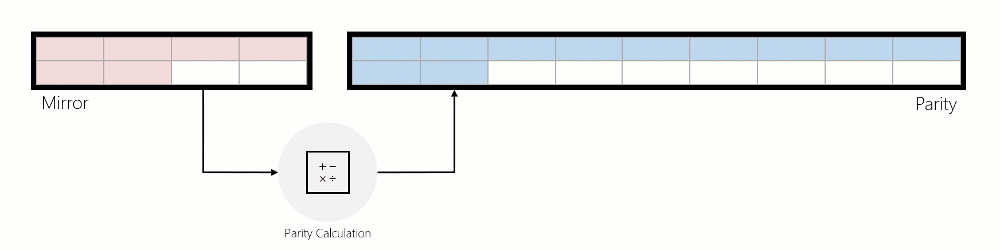
미러의 IO 가속된 패리티
IO 동작
쓰기: ReFS 서비스는 다음과 같은 세 가지 방법으로 들어오는 쓰기를 제공합니다.
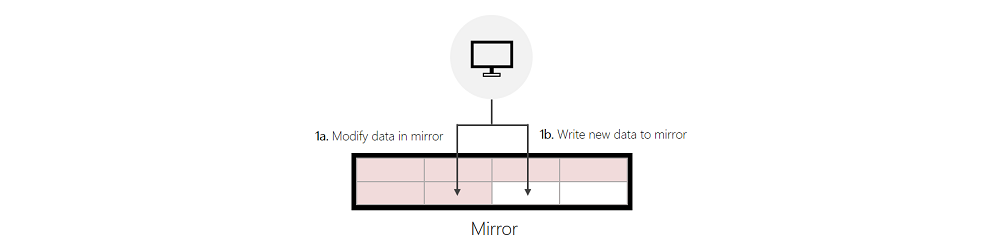
미러에 쓰기:
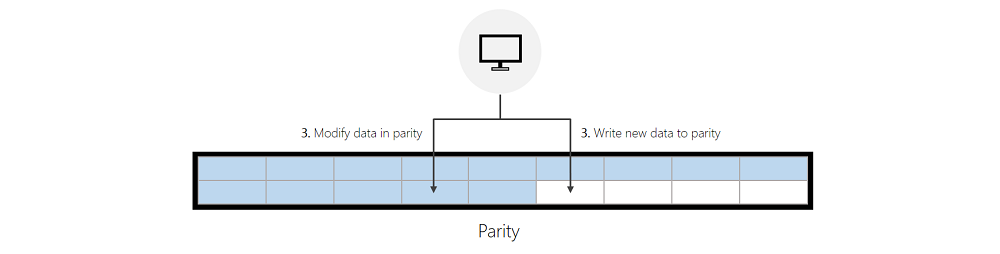
- 1a. 들어오는 쓰기가 미러의 기존 데이터를 수정하는 경우 ReFS는 현재 위치에서 데이터를 수정합니다.
- 1b. 들어오는 쓰기가 새 쓰기이고 ReFS가 이 쓰기를 서비스하기 위해 미러에서 충분한 여유 공간을 성공적으로 찾을 수 있는 경우 ReFS는 미러에 씁니다.
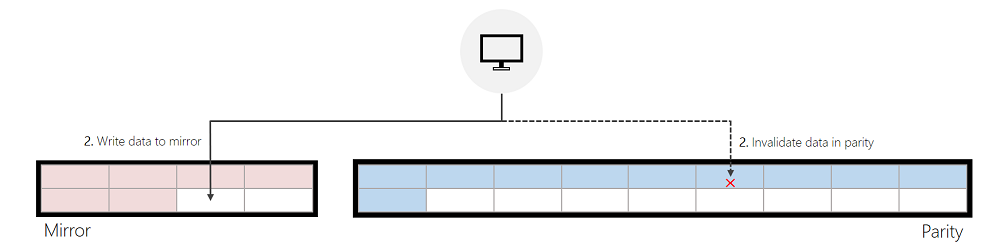
패리티에서 다시 할당된 미러에 쓰기:
들어오는 쓰기가 패리티에 있는 데이터를 수정하고 ReFS가 들어오는 쓰기를 서비스하기 위해 미러에서 충분한 여유 공간을 성공적으로 찾을 수 있는 경우 ReFS는 먼저 이전 데이터를 패리티로 무효화한 다음 미러에 씁니다. 이 무효화는 패리티에 대한 쓰기 성능을 의미 있게 개선하는 데 도움이 되는 빠르고 저렴한 메타데이터 작업입니다.
패리티에 쓰기:
ReFS가 미러에서 충분한 여유 공간을 찾을 수 없는 경우 ReFS는 패리티에 새 데이터를 쓰거나 패리티에서 기존 데이터를 직접 수정합니다. 아래의 "성능 최적화" 섹션에서는 패리티에 대한 쓰기를 최소화하는 데 도움이 되는 지침을 제공합니다.
읽기: ReFS는 관련 데이터를 포함하는 계층에서 직접 읽습니다. 패리티가 HDD로 생성되는 경우 저장소 공간 Direct의 캐시는 이 데이터를 캐시하여 향후 읽기를 가속화합니다.
참고 항목
읽기는 ReFS가 데이터를 미러 계층으로 다시 회전하지 않습니다.
IO 성능
쓰기: 위에서 설명한 각 쓰기 유형에는 고유한 성능 특성이 있습니다. 대략적으로 미러 계층에 대한 쓰기는 재할당된 쓰기보다 훨씬 빠르며 재할당된 쓰기는 패리티 계층에 직접 만든 쓰기보다 훨씬 빠릅니다. 이 관계는 아래의 같지 않음을 보여 줍니다.
- 미러 계층 > 재할당 쓰기 >> 패리티 계층
읽기: 패리티에서 읽을 때 의미 있고 부정적인 성능 영향은 없습니다.
- 미러 및 패리티가 동일한 미디어 형식으로 생성되는 경우 읽기 성능은 동일합니다.
- 미러 및 패리티가 다른 미디어 유형(예: 미러된 SSD, 패리티 HDD)으로 구성된 경우 저장소 공간 Direct의 캐시는 핫 데이터를 캐시하여 패리티에서 읽기를 가속화하는 데 도움이 됩니다.
ReFS 압축
ReFS용 압축은 Windows Server 2019 이상 버전에서 사용할 수 있으며, 이는 90% 전체 미러 가속 패리티 볼륨의 성능을 크게 향상시킵니다.
배경: 이전에는 미러 가속 패리티 볼륨이 가득 차면서 이러한 볼륨의 성능이 저하될 수 있습니다. 볼륨 초과 작업 동안 핫 및 콜드 데이터가 혼합되므로 성능이 저하됩니다. 즉, 콜드 데이터는 핫 데이터에서 사용할 수 있는 미러 공간을 차지하기 때문에 더 적은 핫 데이터를 미러에 저장할 수 있습니다. 미러에 직접 쓰는 쓰기는 패리티에 직접 쓰는 것보다 크기가 큰 재할당된 쓰기 및 순서보다 훨씬 빠르기 때문에 핫 데이터를 미러에 저장하는 것은 고성능을 유지하는 데 매우 중요합니다. 따라서 미러에 콜드 데이터가 있으면 ReFS가 미러에 직접 쓰기를 수행할 수 있는 가능성이 줄어들기 때문에 성능이 저하됩니다.
ReFS 압축은 핫 데이터에 대한 미러 공간을 확보하여 이러한 성능 문제를 해결합니다. 압축은 먼저 미러 및 패리티의 모든 데이터를 패리티로 통합합니다. 이렇게 하면 볼륨 내의 조각화가 줄어들고 미러에서 주소 지정 가능한 공간의 양이 증가합니다. 더 중요한 것은 이 프로세스를 통해 ReFS가 핫 데이터를 미러로 다시 통합할 수 있습니다.
- 새 쓰기가 들어오면 미러로 서비스됩니다. 따라서 새로 작성된 핫 데이터는 미러에 상주합니다.
- 패리티의 데이터에 대한 수정 쓰기가 수행되면 ReFS는 재할당된 쓰기를 수행하므로 이 쓰기는 미러에서도 처리됩니다. 따라서 압축하는 동안 패리티로 이동된 핫 데이터는 미러로 다시 할당됩니다.
성능 최적화
Important
쓰기가 많은 VHD를 다른 하위 디렉터리에 배치하는 것이 좋습니다. ReFS는 디렉터리 및 해당 파일 수준에서 메타데이터 변경 내용을 작성하기 때문입니다. 따라서 쓰기가 많은 파일을 디렉터리에 분산하는 경우 메타데이터 작업이 더 작고 병렬로 실행되어 앱의 대기 시간이 줄어듭니다.
성능 카운터
ReFS는 미러 가속 패리티의 성능을 평가하는 데 도움이 되는 성능 카운터를 유지 관리합니다.
패리티에 쓰기 섹션에서 위에서 설명한 대로 ReFS는 미러에서 여유 공간을 찾을 수 없을 때 패리티에 직접 씁니다. 일반적으로 이는 ReFS가 데이터를 패리티로 회전할 수 있는 것보다 미러된 계층이 더 빠르게 채워질 때 발생합니다. 즉, ReFS 회전은 수집 속도를 따라갈 수 없습니다. 아래 성능 카운터는 ReFS가 패리티에 직접 쓰는 시기를 식별합니다.
# Windows Server 2016 ReFS\Data allocations slow tier/sec ReFS\Metadata allocations slow tier/sec # Windows Server 2019 ReFS\Allocation of Data Clusters on Slow Tier/sec ReFS\Allocation of Metadata Clusters on Slow Tier/sec이러한 카운터가 0이 아닌 경우 ReFS가 데이터를 미러에서 충분히 빠르게 회전하지 않음을 나타냅니다. 이를 완화하기 위해 회전 공격성을 변경하거나 미러된 계층의 크기를 늘릴 수 있습니다.
회전 공격성
ReFS는 미러가 지정된 용량 임계값에 도달하면 데이터 회전을 시작합니다.
- 이 회전 임계값이 높을수록 ReFS는 미러 계층에 데이터를 더 오래 보존합니다. 핫 데이터를 미러 계층에 두는 것이 성능에 최적이지만 ReFS는 대량의 들어오는 IO를 효과적으로 처리할 수 없습니다.
- 값을 낮추면 ReFS에서 데이터를 사전에 분해하고 들어오는 IO를 더 효율적으로 수집할 수 있습니다. 이는 보관 스토리지와 같이 많은 워크로드를 수집하는 데 적용됩니다. 그러나 값이 낮을수록 범용 워크로드의 성능이 저하됩니다. 미러 계층에서 데이터를 불필요하게 회전하면 성능이 저하됩니다.
ReFS는 레지스트리 키를 사용하여 구성할 수 있는 이 임계값을 조정하기 위해 튜닝 가능한 매개 변수를 도입합니다. 이 레지스트리 키는 저장소 공간 직접 배포의 각 노드에서 구성해야 하며 변경 내용을 적용하려면 다시 시작해야 합니다.
- 키: HKEY_LOCAL_MACHINE\System\CurrentControlSet\Policies
- ValueName(DWORD): DataDestageSsdFillRatioThreshold
- 값 종류: 백분율
이 레지스트리 키가 설정되지 않은 경우 ReFS는 기본값인 85%를 사용합니다. 이 기본값은 대부분의 배포에 권장되며 50% 미만의 값은 권장되지 않습니다. 아래 PowerShell 명령은 값이 75%인 이 레지스트리 키를 설정하는 방법을 보여 줍니다.
Set-ItemProperty -Path HKLM:\SYSTEM\CurrentControlSet\Policies -Name DataDestageSsdFillRatioThreshold -Value 75
저장소 공간 직접 배포의 각 노드에서 이 레지스트리 키를 구성하려면 아래 PowerShell 명령을 사용할 수 있습니다.
$Nodes = 'S2D-01', 'S2D-02', 'S2D-03', 'S2D-04'
Invoke-Command $Nodes {Set-ItemProperty -Path HKLM:\SYSTEM\CurrentControlSet\Policies -Name DataDestageSsdFillRatioThreshold -Value 75}
미러된 계층의 크기 늘리기
미러 계층의 크기를 늘리면 ReFS가 작업 집합의 더 큰 부분을 미러로 유지할 수 있습니다. 이렇게 하면 ReFS가 미러에 직접 쓸 가능성이 높아져 성능 향상에 도움이 됩니다. 아래 PowerShell cmdlet은 미러된 계층의 크기를 늘리는 방법을 보여 줍니다.
Resize-StorageTier -FriendlyName "Performance" -Size 20GB
Resize-StorageTier -InputObject (Get-StorageTier -FriendlyName "Performance") -Size 20GB
팁
StorageTier 크기를 조정한 후 파티션 및 볼륨 의 크기를 조정해야 합니다. 자세한 내용 및 예제는 기본 볼륨 확장을 참조 하세요.
미러 가속 패리티 볼륨 만들기
아래 PowerShell cmdlet은 미러:패리티 비율이 20:80인 미러 가속 패리티 볼륨을 만듭니다. 이는 대부분의 워크로드에 권장되는 구성입니다. 자세한 내용 및 예제는 저장소 공간 Direct에서 볼륨 만들기를 참조하세요.
New-Volume -FriendlyName "TestVolume" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName "StoragePoolName" -StorageTierFriendlyNames Performance, Capacity -StorageTierSizes 200GB, 800GB