WinMLRunner
WinMLRunner는 Windows ML API를 사용하여 평가할 때 모델이 성공적으로 실행되는지 테스트하는 도구입니다. GPU 및/또는 CPU에서 평가 시간 및 메모리 사용량을 캡처할 수도 있습니다. .onnx 또는 .pb 형식의 모델은 입력 및 출력 변수가 텐서 또는 이미지인 위치를 평가할 수 있습니다. WinMLRunner를 사용하는 방법에는 두 가지가 있습니다.
- 명령줄 python 도구를 다운로드합니다.
- WinML 대시보드 내에서 사용합니다. 자세한 내용은 WinML 대시보드 설명서를 참조하세요.
모델 실행
먼저 다운로드한 Python 도구를 엽니다. WinMLRunner.exe를 포함하는 폴더로 이동하고, 아래와 같이 실행 파일을 실행합니다. 설치 위치를 사용자와 일치하는 위치로 바꾸어야 합니다.
.\WinMLRunner.exe -model SqueezeNet.onnx
다음과 같은 명령을 통해 모델 폴더를 실행할 수도 있습니다.
WinMLRunner.exe -folder c:\data -perf -iterations 3 -CPU`\
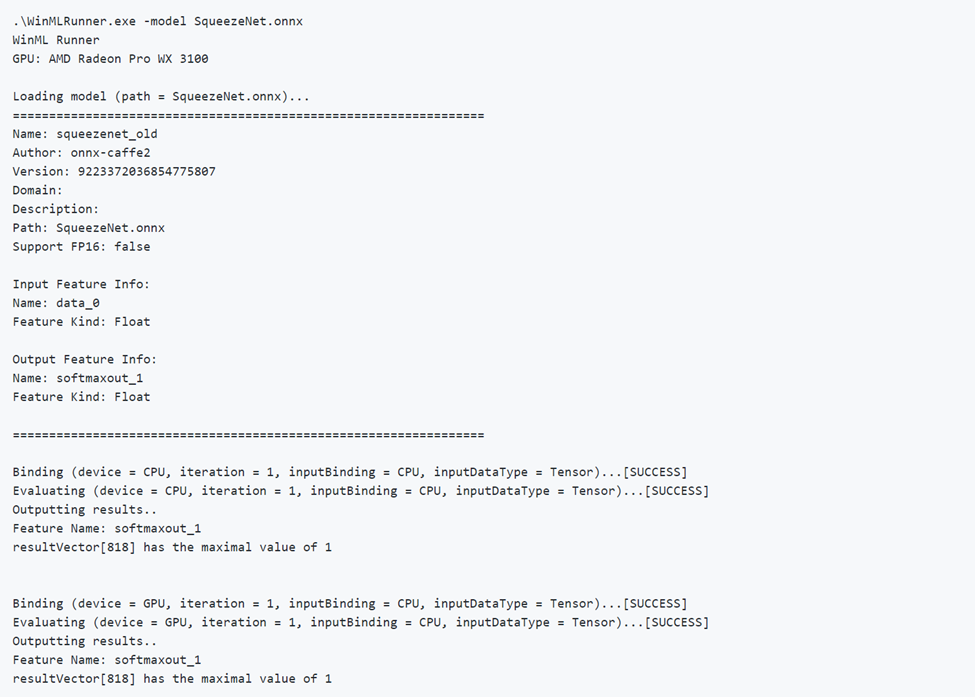
좋은 모델 실행
다음은 모델을 성공적으로 실행하는 예제입니다. 모델이 모델 메타데이터를 먼저 로드하고 출력하는 방법을 확인합니다. 그런 다음, 모델은 CPU 및 GPU에서 별도로 실행되어 바인딩 성공, 평가 성공 및 모델 출력을 출력합니다.
잘못된 모델 실행
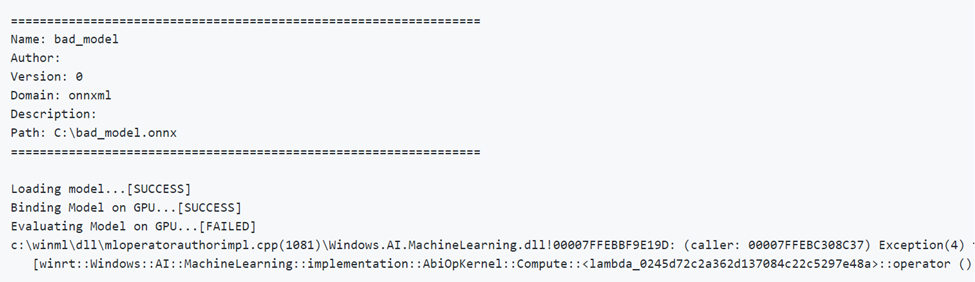
다음은 잘못된 매개 변수를 가진 모델을 실행하는 예제입니다. GPU에서 평가할 때 FAILED 출력을 확인합니다.
디바이스 선택 및 최적화
기본적으로 모델은 CPU 및 GPU에서 개별적으로 실행되지만 -CPU 또는 -GPU 플래그를 사용하는 디바이스를 지정할 수 있습니다. 다음은 CPU만 사용하여 모델을 3번 실행하는 예제입니다.
WinMLRunner.exe -model c:\data\concat.onnx -iterations 3 -CPU
로그 성능 데이터
성능 데이터를 캡처하려면 -perf 플래그를 사용합니다. 다음은 CPU 및 GPU의 데이터 폴더에 있는 모든 모델을 개별적으로 3번 실행하고 성능 데이터를 캡처하는 예제입니다.
WinMLRunner.exe -folder c:\data iterations 3 -perf
성능 측정
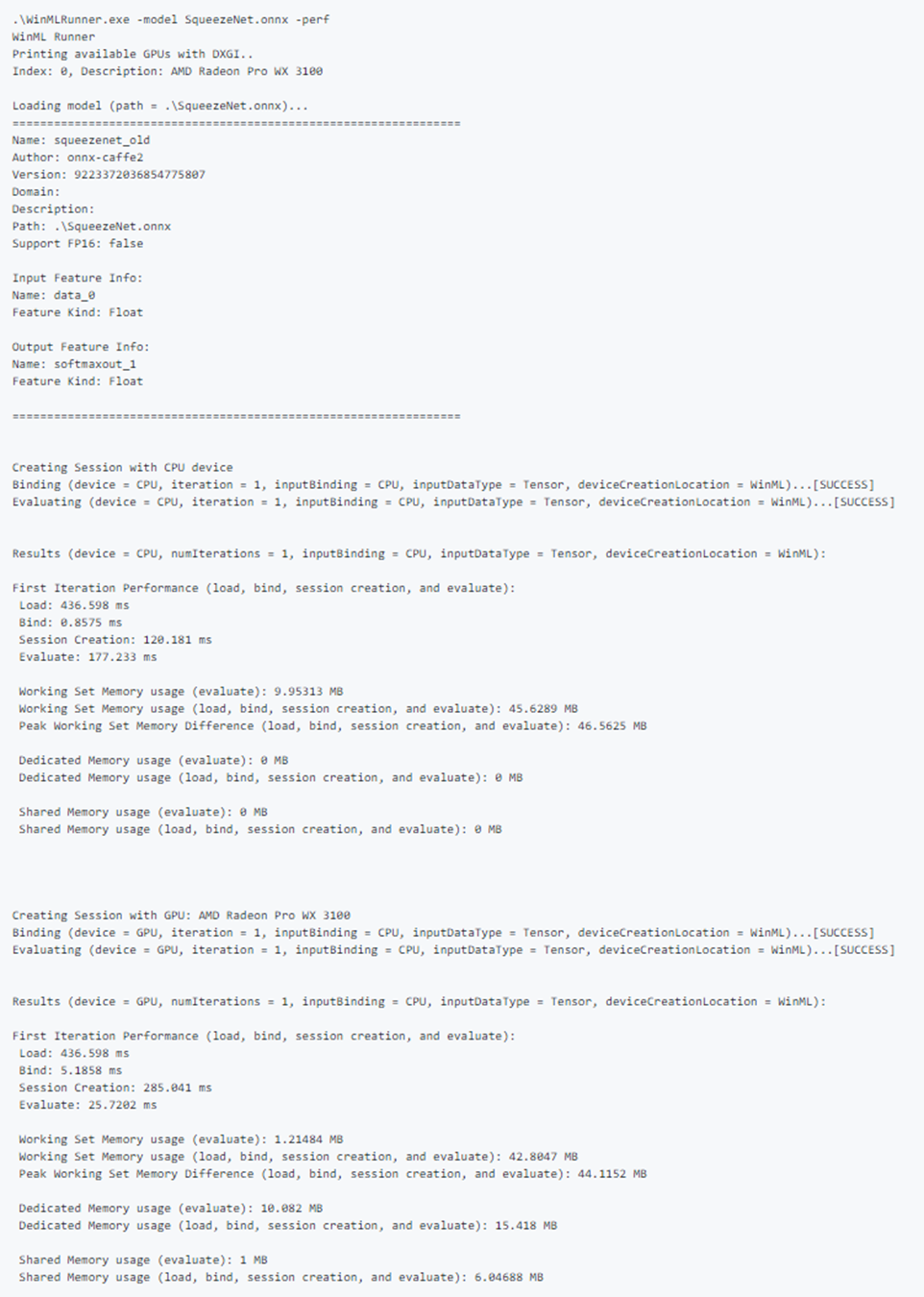
다음 성능 측정은 각 로드, 바인딩 및 평가 작업에 대한 명령줄 및 .csv 파일에 출력됩니다.
- 벽시계 시간(ms): 작업의 시작과 끝 사이의 경과된 실시간입니다.
- GPU 시간(ms): 작업이 CPU에서 GPU로 전달되고 GPU에서 실행되는 시간입니다(참고: Load()는 GPU에서 실행되지 않음).
- CPU 시간(ms): CPU에서 작업을 실행할 시간입니다.
- 전용 및 공유 메모리 사용량(MB): CPU 또는 GPU에서 평가하는 동안 평균 커널 및 사용자 수준 메모리 사용량(MB)입니다.
- 작업 집합 메모리(MB): 평가하는 동안 CPU의 프로세스에 필요한 DRAM 메모리 양입니다. 전용 메모리(MB) - 전용 GPU의 VRAM에서 사용된 메모리 양입니다.
- 공유 메모리(MB): GPU에서 DRAM에 사용한 메모리 양입니다.
샘플 성능 출력:
샘플 입력 테스트
CPU 및 GPU에서 개별적으로 모델을 실행하고 입력을 CPU 및 GPU에 개별적으로 바인딩하여(총 4회 실행):
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPU -CPUBoundInput -GPUBoundInput
GPU에 바인딩되고 RGB 이미지로 로드된 입력을 사용하여 CPU에서 모델을 실행합니다.
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPUBoundInput -RGB
추적 로그 캡처
도구를 사용하여 추적 로그를 캡처하려는 경우 디버그 플래그와 함께 logman 명령을 사용할 수 있습니다.
logman start winml -ets -o winmllog.etl -nb 128 640 -bs 128logman update trace winml -p {BCAD6AEE-C08D-4F66-828C-4C43461A033D} 0xffffffffffffffff 0xff -ets WinMLRunner.exe -model C:\Repos\Windows-Machine-Learning\SharedContent\models\SqueezeNet.onnx -debuglogman stop winml -ets
winmllog.etl 파일은 WinMLRunner.exe와 동일한 디렉터리에 표시됩니다.
추적 로그 읽기
traceprt.exe를 사용하여 명령줄에서 다음 명령을 실행합니다.
tracerpt.exe winmllog.etl -o logdump.csv -of CSV
다음으로 logdump.csv 파일을 엽니다.
또는 Visual Studio에서 Windows Performance Analyzer를 사용할 수 있습니다. Windows Performance Analyzer를 시작하고 winmllog.etl을 엽니다.
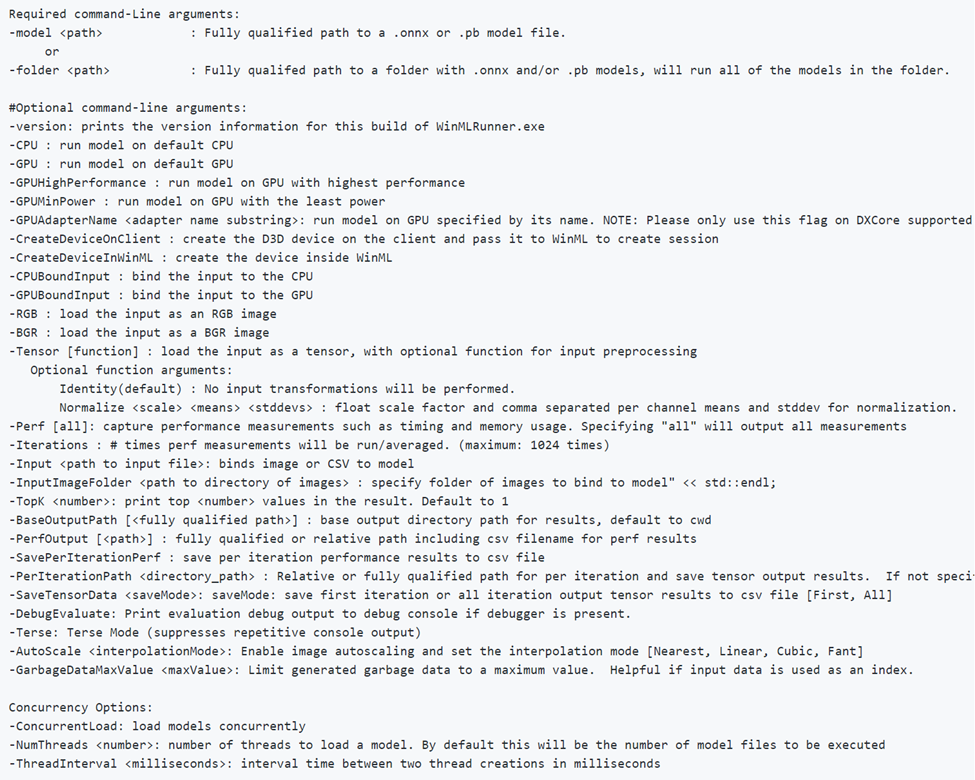
-CPU, -GPU, -GPUHighPerformance, -GPUMinPower -BGR, -RGB, -tensor, -CPUBoundInput, -GPUBoundInput은 함께 사용할 수 없습니다.(즉, 다양한 구성으로 모델을 실행하려는 만큼 결합할 수 있습니다.)
동적 DLL 로드
WinMLRunner를 다른 버전의 WinML과 함께 실행하려는 경우(예: 이전 버전과 성능 비교 또는 최신 버전 테스트) windows.ai.machinelearning.dll 및 directml.dll 파일을 WinMLRunner.exe와 동일한 폴더에 배치하면 됩니다. WinMLRunner는 먼저 이러한 DLL을 찾고 찾을 수 없는 경우 C:/Windows/System32로 돌아갑니다.
알려진 문제
- 시퀀스/맵 입력은 아직 지원되지 않습니다(모델을 건너뛰므로 폴더의 다른 모델을 차단하지 않음).
- 실제 데이터가 있는 -folder 인수를 통해 여러 모델을 안정적으로 실행할 수 없습니다. 입력을 1개만 지정할 수 있으므로 입력 크기가 대부분의 모델과 일치하지 않습니다. 현재 -folder 인수를 사용하는 것은 가비지 데이터에서만 잘 작동합니다.
- Gray 또는 YUV로 가비지 입력을 생성하는 것은 현재 지원되지 않습니다. 이상적으로 WinMLRunner의 가비지 데이터 파이프라인은 winml에 제공할 수 있는 모든 입력 유형을 지원해야 합니다.