Opplæring i Lakehouse: Klargjøre og transformere data i lakehouse
I denne opplæringen bruker du notatblokker med Spark-kjøretid til å transformere og klargjøre rådata i lakehouse.
Forutsetning
Hvis du ikke har et lakehouse som inneholder data, må du:
Klargjør data
Fra de forrige opplæringstrinnene har vi rådata inntatt fra kilden til Filer-delen av lakehouse. Nå kan du transformere dataene og klargjøre dem for å opprette Delta-tabeller.
Last ned notatblokkene fra mappen Kildekode for Lakehouse-opplæring.
Velg Dataingeniør nederst til venstre på skjermen fra bryteren som er plassert nederst til venstre på skjermen.

Velg Importer notatblokk fra Ny-delen øverst på målsiden.
Velg Last opp fra importstatusruten som åpnes på høyre side av skjermen.
Merk alle notatblokkene du lastet ned i første trinn i denne inndelingen.
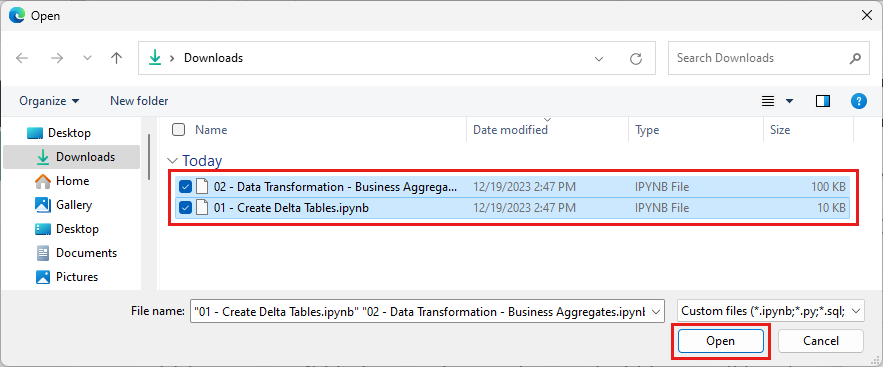
Velg Åpne. Et varsel som angir statusen for importen, vises øverst til høyre i nettleservinduet.
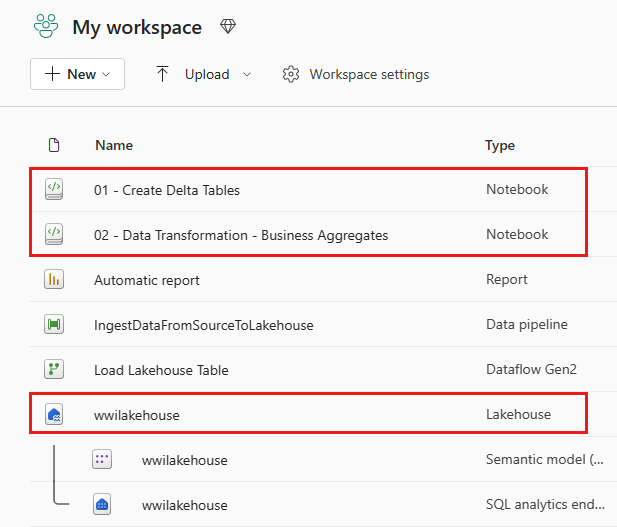
Når importen er vellykket, går du til elementer-visning av arbeidsområdet og ser de nylig importerte notatblokkene. Velg wwilakehouse lakehouse for å åpne den.
Når wwilakehouse lakehouse er åpnet, velger du Åpne notatblokk Eksisterende notatblokk> fra den øverste navigasjonsmenyen.
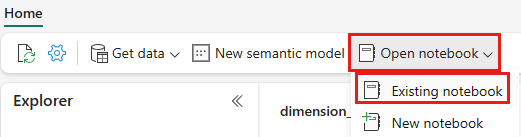
Velg notatblokken 01 – Opprett deltatabeller fra listen over eksisterende notatblokker, og velg Åpne.
I den åpne notatblokken i Lakehouse Explorer ser du at notatblokken allerede er koblet til det åpne lakehouse.
Merk
Fabric gir V-ordrefunksjonen til å skrive optimaliserte Delta Lake-filer. V-rekkefølge forbedrer ofte komprimeringen med tre til fire ganger, og opptil 10 ganger, ytelsesakselerasjon over Delta Lake-filene som ikke er optimalisert. Spark in Fabric optimaliserer partisjoner dynamisk mens du genererer filer med en standard størrelse på 128 MB. Målfilstørrelsen kan endres per arbeidsbelastningskrav ved hjelp av konfigurasjoner.
Med optimalisering av skrivefunksjonen reduserer Apache Spark-motoren antall filer som er skrevet, og har som mål å øke den individuelle filstørrelsen på de skriftlige dataene.
Før du skriver data som Delta Lake-tabeller i Tabeller-delen av lakehouse, bruker du to Fabric-funksjoner (V-order og Optimize Write) for optimalisert dataskriving og for bedre leseytelse. Hvis du vil aktivere disse funksjonene i økten, angir du disse konfigurasjonene i den første cellen i notatblokken.
Hvis du vil starte notatblokken og kjøre alle cellene i rekkefølge, velger du Kjør alt på det øverste båndet (under Hjem). Hvis du bare vil kjøre kode fra en bestemt celle, velger du Kjør-ikonet som vises til venstre for cellen når du holder pekeren over cellen, eller trykker SKIFT+ ENTER på tastaturet mens kontrollen er i cellen.
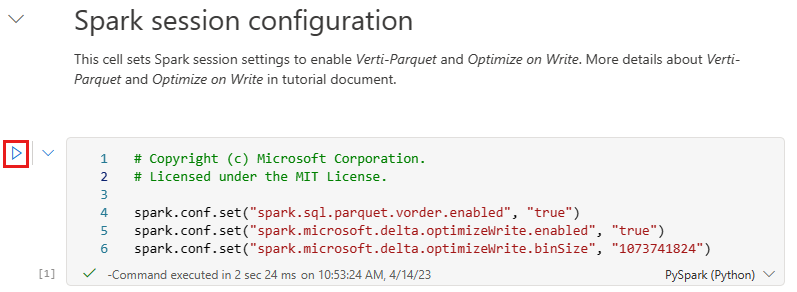
Når du kjører en celle, trengte du ikke å angi de underliggende Spark-utvalget eller klyngedetaljene fordi Fabric gir dem gjennom Live Pool. Hvert Fabric-arbeidsområde leveres med et standard Spark-basseng, kalt Live Pool. Dette betyr at når du oppretter notatblokker, trenger du ikke å bekymre deg for å angi spark-konfigurasjoner eller klyngedetaljer. Når du utfører den første notatblokkkommandoen, er det dynamiske utvalget oppe og går om noen sekunder. Spark-økten opprettes, og den starter kjøringen av koden. Etterfølgende kjøring av kode er nesten øyeblikkelig i denne notatblokken mens Spark-økten er aktiv.
Deretter leser du rådata fra Filer-delen av lakehouse, og legger til flere kolonner for ulike datodeler som en del av transformasjonen. Til slutt bruker du partisjonen By Spark API til å partisjonere dataene før du skriver dem som Delta-tabellformat basert på de nyopprettede datadelkolonnene (år og kvartal).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Etter at faktatabellene er lastet inn, kan du gå videre til innlasting av data for resten av dimensjonene. Følgende celle oppretter en funksjon for å lese rådata fra Filer-delen av lakehouse for hvert av tabellnavnene som sendes som en parameter. Deretter oppretter den en liste over dimensjonstabeller. Til slutt går den gjennom listen over tabeller og oppretter en Delta-tabell for hvert tabellnavn som leses fra inndataparameteren. Vær oppmerksom på at skriptet slipper kolonnen med navnet i dette eksemplet
Photofordi kolonnen ikke brukes.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Hvis du vil validere de opprettede tabellene, høyreklikker du og velger oppdater på wwilakehouse Lakehouse. Tabellene vises.
Gå til elementer-visningen av arbeidsområdet på nytt, og velg wwilakehouse lakehouse for å åpne det.
Åpne nå den andre notatblokken. Velg Åpne notatblokk>Eksisterende notatblokk fra båndet i lakehouse-visningen.
Fra listen over eksisterende notatblokker velger du 02 – Datatransformasjon – Forretningsnotatblokk for å åpne den.
I den åpne notatblokken i Lakehouse Explorer ser du at notatblokken allerede er koblet til det åpne lakehouse.
En organisasjon kan ha datateknikere som arbeider med Scala/Python og andre datateknikere som arbeider med SQL (Spark SQL eller T-SQL), som alle arbeider med samme kopi av dataene. Fabric gjør det mulig for disse forskjellige gruppene, med variert erfaring og preferanse, å arbeide og samarbeide. De to ulike tilnærmingene transformerer og genererer forretningsaggregater. Du kan velge den som passer for deg eller mikse og samsvare med disse tilnærmingene basert på dine preferanser uten å gå på akkord med ytelsen:
Tilnærming #1 – Bruk PySpark til å koble sammen og aggregere data for generering av forretningsaggregater. Denne fremgangsmåten er å foretrekke fremfor noen med programmeringsbakgrunn (Python eller PySpark).
Tilnærming #2 – Bruk Spark SQL til å koble sammen og aggregere data for generering av forretningsaggregater. Denne fremgangsmåten er å foretrekke for noen med SQL-bakgrunn, overgang til Spark.
Tilnærming #1 (sale_by_date_city) – Bruk PySpark til å koble sammen og aggregere data for generering av forretningsaggregater. Med følgende kode oppretter du tre forskjellige Spark-datarammer, som hver refererer til en eksisterende Delta-tabell. Deretter kobler du sammen disse tabellene ved hjelp av datarammene, grupperer etter for å generere aggregasjon, gir nytt navn til noen av kolonnene, og til slutt skriver du det som en Delta-tabell i Tabeller-delen av lakehouse for å fortsette med dataene.
I denne cellen oppretter du tre forskjellige Spark-datarammer, som hver refererer til en eksisterende Delta-tabell.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Legg til følgende kode i samme celle for å koble sammen disse tabellene ved hjelp av datarammene som ble opprettet tidligere. Grupper etter for å generere aggregasjon, gi nytt navn til noen av kolonnene, og skriv den til slutt som en Delta-tabell i Tabeller-delen av lakehouse.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Tilnærming #2 (sale_by_date_employee) – Bruk Spark SQL til å koble sammen og aggregere data for generering av forretningsaggregater. Med følgende kode oppretter du en midlertidig Spark-visning ved å bli med i tre tabeller, gruppere etter for å generere aggregasjon og gi nytt navn til noen av kolonnene. Til slutt leser du fra den midlertidige Spark-visningen og skriver den til slutt som en Delta-tabell i Tabeller-delen av lakehouse for å fortsette med dataene.
I denne cellen oppretter du en midlertidig Spark-visning ved å bli med i tre tabeller, gruppere etter for å generere aggregasjon og gi nytt navn til noen av kolonnene.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCI denne cellen leser du fra den midlertidige Spark-visningen som ble opprettet i den forrige cellen, og til slutt skriver du den som en Delta-tabell i Tabeller-delen av lakehouse.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Hvis du vil validere de opprettede tabellene, høyreklikker du og velger Oppdater på wwilakehouse Lakehouse. De aggregerte tabellene vises.
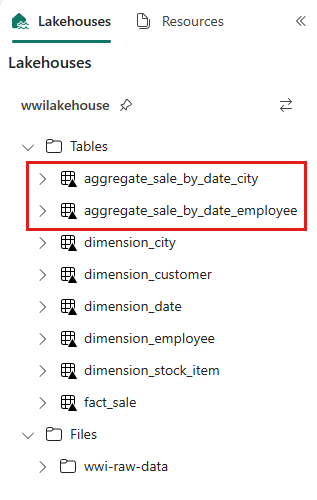
De to tilnærmingene gir et lignende resultat. Hvis du vil minimere behovet for å lære en ny teknologi eller gå på akkord med ytelsen, velger du fremgangsmåten som passer best til bakgrunnen og preferansen din.
Du legger kanskje merke til at du skriver data som Delta Lake-filer. Den automatiske tabelloppdagelsen og registreringsfunksjonen i Fabric plukker opp og registrerer dem i metabutikken. Du trenger ikke eksplisitt å kalle opp CREATE TABLE setninger for å opprette tabeller som skal brukes med SQL.