Maskinlæringsmodell scoring med PREDICT i Microsoft Fabric
Microsoft Fabric gjør det mulig for brukere å operasjonalisere maskinlæringsmodeller med den skalerbare PREDICT-funksjonen. Denne funksjonen støtter satsvis poengsum i alle databehandlingsmotorer. Brukere kan generere satsvise prognoser direkte fra en Microsoft Fabric-notatblokk eller fra elementsiden i en gitt ML-modell.
I denne artikkelen lærer du hvordan du bruker FORUTSI ved å skrive kode selv eller gjennom bruk av en veiledet brukergrensesnittopplevelse som håndterer satsvis poengsum for deg.
Forutsetning
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren til venstre på hjemmesiden for å bytte til Synapse Data Science-opplevelsen.

Begrensninger
- PREDICT-funksjonen støttes for øyeblikket for dette begrensede settet med ML-modellsmaker:
- CatBoost
- Keras
- LightGBM
- ONNX
- Profet
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT krever at du lagrer ML-modeller i MLflow-formatet, med signaturene utfylt
- PREDICT støtter ikke ML-modeller med inndata eller utganger med flere titalls enheter
Ringe FORUTSI fra en notatblokk
PREDICT støtter MLflow-pakkede modeller i Microsoft Fabric-registeret. Hvis det finnes en allerede opplært og registrert ML-modell i arbeidsområdet, kan du hoppe til trinn 2. Hvis ikke, gir trinn 1 eksempelkode for å veilede deg gjennom opplæring av en eksempellogistikk regresjonsmodell. Du kan bruke denne modellen til å generere satsvise prognoser på slutten av prosedyren.
Lær opp en ML-modell og registrer den med MLflow. Det neste kodeeksempelet bruker MLflow-API-en til å opprette et maskinlæringseksperiment, og starter deretter en MLflow-kjøring for en logistikkregresjonsmodell for scikit-learn. Modellversjonen lagres og registreres deretter i Microsoft Fabric-registeret. Gå til hvordan du lærer opp ML-modeller med scikit-learn-ressurs for mer informasjon om opplæringsmodeller og sporing av dine egne eksperimenter.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Last inn testdata som spark-dataramme. Hvis du vil generere satsvise prognoser med ML-modellen opplært i forrige trinn, må du teste data i form av en Spark DataFrame. I følgende kode erstatter du
testvariabelverdien med dine egne data.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Opprett et
MLFlowTransformerobjekt for å laste inn ML-modellen for inferencing. Hvis du vil opprette etMLFlowTransformerobjekt for å generere satsvise prognoser, må du utføre disse handlingene:testangi datarammekolonnene du trenger som modellinndata (i dette tilfellet alle)- velg et navn for den nye utdatakolonnen (i dette tilfellet
predictions) - angi riktig modellnavn og modellversjon for generering av disse prognosene.
Hvis du bruker din egen ML-modell, erstatter du verdiene for inndatakolonnene, navnet på utdatakolonnen, modellnavnet og modellversjonen.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )Generer prognoser ved hjelp av PREDICT-funksjonen. Hvis du vil aktivere PREDICT-funksjonen, bruker du Transformer-API-en, Spark SQL-API-en eller en brukerdefinert PySpark-funksjon (UDF). Avsnittene nedenfor viser hvordan du genererer satsvise prognoser med testdataene og ML-modellen som er definert i de forrige trinnene, ved hjelp av de ulike metodene for å aktivere PREDICT-funksjonen.
FORUTSI med Transformer-API-en
Denne koden aktiverer PREDICT-funksjonen med Transformer-API-en. Hvis du bruker din egen ML-modell, kan du erstatte verdiene for modellen og teste data.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
FORUTSI med Spark SQL-API-en
Denne koden aktiverer PREDICT-funksjonen med Spark SQL-API-en. Hvis du bruker din egen ML-modell, erstatter du verdiene for model_name, model_versionog features med modellnavn, modellversjon og funksjonskolonner.
Merk
Bruk av Spark SQL-API-en for forutsigelsesgenerering krever fremdeles oppretting av et MLFlowTransformer objekt (som vist i trinn 3).
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
FORUTSI med en brukerdefinert funksjon
Denne koden aktiverer PREDICT-funksjonen med en PySpark UDF. Hvis du bruker din egen ML-modell, kan du erstatte verdiene for modellen og funksjonene.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Generer PREDICT-kode fra elementsiden for en ML-modell
Fra elementsiden i en hvilken som helst ML-modell kan du velge ett av disse alternativene for å starte generering av satsvis prognose for en bestemt modellversjon, med PREDICT-funksjonen:
- Kopier en kodemal til en notatblokk, og tilpass parameterne selv
- Bruk en veiledet brukergrensesnittopplevelse til å generere PREDICT-kode
Bruk en veiledet brukergrensesnittopplevelse
Den veiledede brukergrensesnittopplevelsen veileder deg gjennom disse trinnene:
- Velg kildedataene for poengsum
- Tilordne dataene riktig til ML-modellinndataene
- Angi målet for modellutdataene
- Opprette en notatblokk som bruker PREDICT til å generere og lagre prognoseresultater
Hvis du vil bruke veiledet opplevelse,
Gå til elementsiden for en gitt ML-modellversjon.
Velg Bruk denne modellen i veiviseren fra rullegardinlisten Bruk denne versjonen.
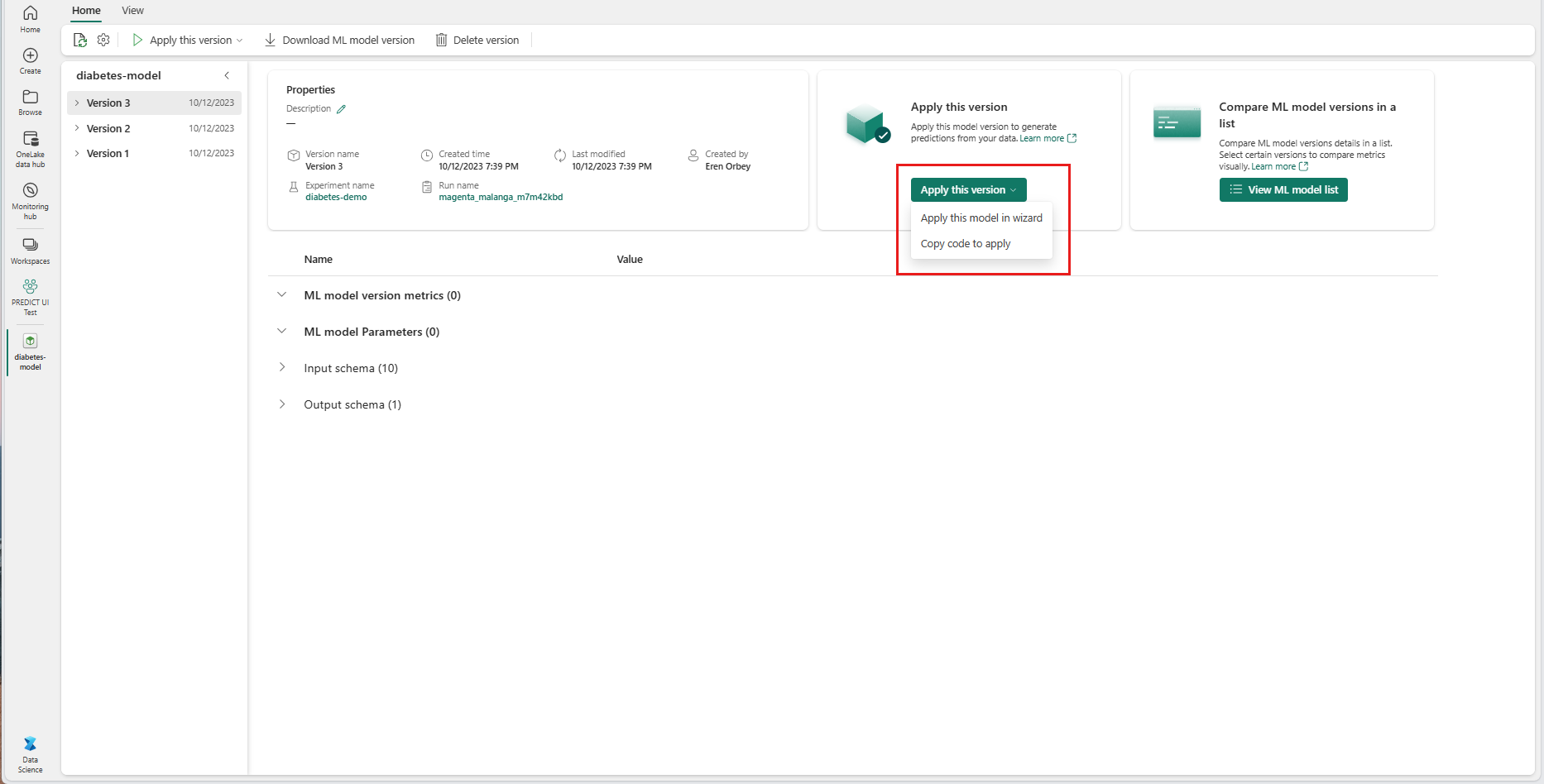
I trinnet Velg inndatatabell åpnes vinduet Bruk ML-modellprognoser.
Velg en inndatatabell fra et lakehouse i det gjeldende arbeidsområdet.

Velg Neste for å gå til trinnet «Tilordne inndatakolonner».
Tilordne kolonnenavn fra kildetabellen til ML-modellens inndatafelt, som hentes fra signaturen til modellen. Du må angi en inndatakolonne for alle de nødvendige feltene i modellen. I tillegg må datatypene for kildekolonne samsvare med de forventede datatypene i modellen.
Tips
Veiviseren forhåndsutformer denne tilordningen hvis navnene på inndatatabellkolonnene samsvarer med kolonnenavnene som er logget i ML-modellsignaturen.

Velg Neste for å gå til trinnet Opprett utdatatabell.
Angi et navn for en ny tabell i det valgte lakehouse i gjeldende arbeidsområde. Denne utdatatabellen lagrer ML-modellens inndataverdier, og den tilføyer prognoseverdiene i tabellen. Som standard opprettes utdatatabellen i samme lakehouse som inndatatabellen. Du kan endre destinasjonen lakehouse.
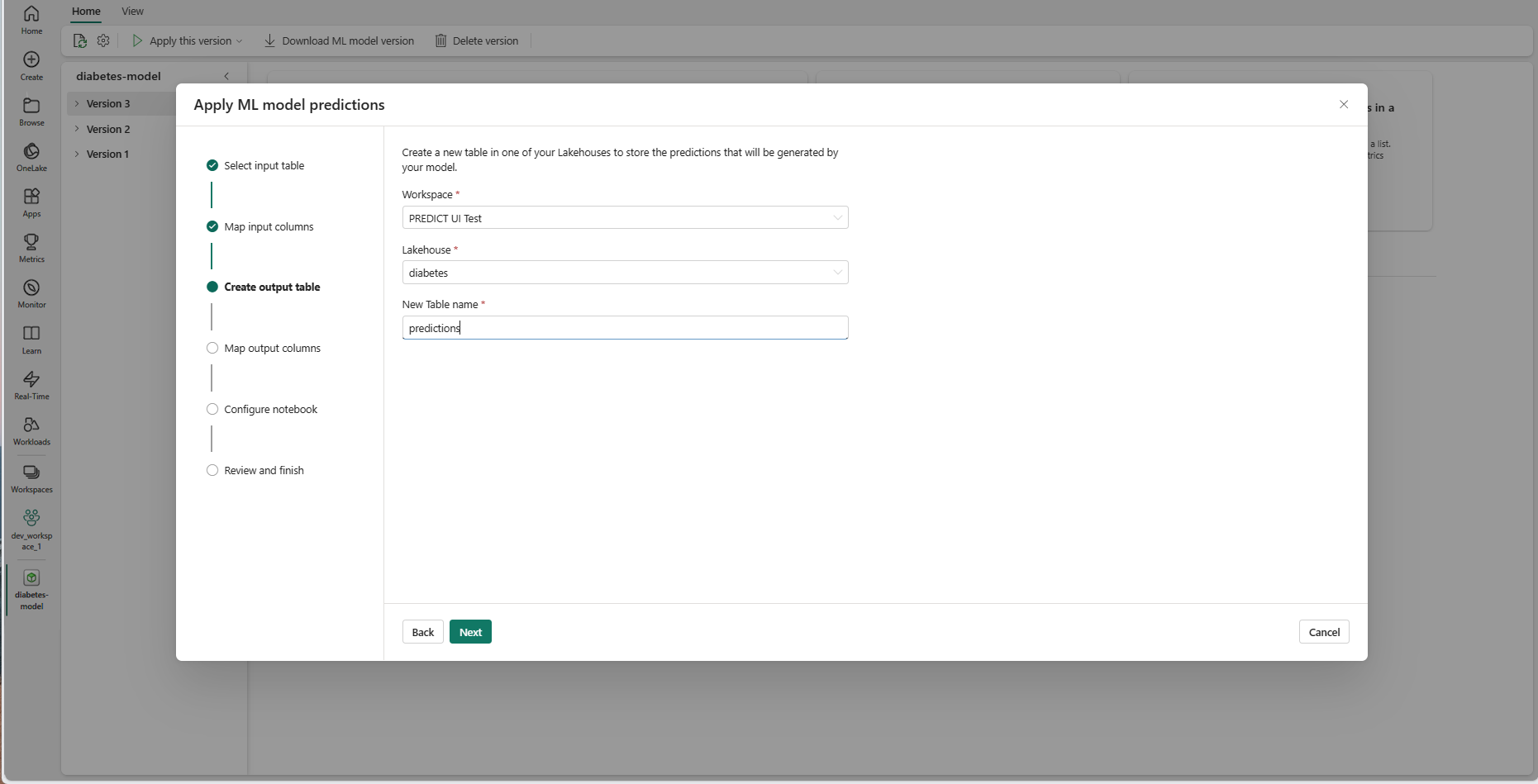
Velg Neste for å gå til trinnet «Tilordne utdatakolonner».
Bruk de angitte tekstfeltene til å gi navn til kolonnene i utdatatabellen som lagrer ML-modellprognosene.

Velg Neste for å gå til «Konfigurer notatblokk»-trinnet.
Angi et navn for en ny notatblokk som kjører den genererte PREDICT-koden. Veiviseren viser en forhåndsvisning av den genererte koden i dette trinnet. Hvis du vil, kan du kopiere koden til utklippstavlen og lime den inn i en eksisterende notatblokk.

Velg Neste for å gå til trinnet Se gjennom og fullfør.
Se gjennom detaljene på sammendragssiden, og velg Opprett notatblokk for å legge til den nye notatblokken med den genererte koden i arbeidsområdet. Du blir tatt direkte til notatblokken, der du kan kjøre koden for å generere og lagre prognoser.








Bruk en kodemal som kan tilpasses
Slik bruker du en kodemal for generering av satsvise prognoser:
- Gå til elementsiden for en gitt ML-modellversjon.
- Velg Kopier kode som skal brukes fra rullegardinlisten Bruk denne versjonen . Utvalget lar deg kopiere en kodemal som kan tilpasses.
Du kan lime inn denne kodemalen i en notatblokk for å generere satsvise prognoser med ML-modellen. Hvis du vil kjøre kodemalen, må du manuelt erstatte følgende verdier:
<INPUT_TABLE>: Filbanen for tabellen som gir inndata til ML-modellen<INPUT_COLS>: En matrise med kolonnenavn fra inndatatabellen som skal mates til ML-modellen<OUTPUT_COLS>: Et navn på en ny kolonne i utdatatabellen som lagrer prognoser<MODEL_NAME>: Navnet på ML-modellen som skal brukes for generering av prognoser<MODEL_VERSION>: Versjonen av ML-modellen som skal brukes til å generere prognoser<OUTPUT_TABLE>: Filbanen for tabellen som lagrer prognosene

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)