Konfigurere arbeidsbelastninger i en Premium-kapasitet
Denne artikkelen viser arbeidsbelastningene for Power BI Premium, og beskriver kapasitetene deres.
Merk
Arbeidsbelastninger kan aktiveres og tilordnes til en kapasitet ved hjelp av REST-API-ene for kapasiteter .
Støttede arbeidsbelastninger
Spørringsarbeidsbelastninger optimaliseres for og begrenses av ressurser som bestemmes av SKU-en for Premium-kapasitet. Premium-kapasiteter støtter også ekstra arbeidsbelastninger som kan bruke kapasitetens ressurser.
Listen over arbeidsbelastninger nedenfor beskriver hvilke Premium SKU-er som støtter hver arbeidsbelastning:
AI – alle SKU-er støttes bortsett fra EM1/A1 SKU-er
Semantiske modeller – alle SKU-er støttes
Dataflyter – alle SKU-er støttes
Paginerte rapporter – alle SKU-er støttes
Konfigurer arbeidsbelastninger
Du kan justere virkemåten til arbeidsbelastningene ved å konfigurere arbeidsbelastningsinnstillinger for kapasiteten.
Viktig
Alle arbeidsbelastninger er alltid aktivert og kan ikke deaktiveres. Kapasitetsressursene administreres av Power BI i henhold til kapasitetsbruken.
Konfigurere arbeidsbelastninger i administrasjonsportalen for Power BI
Logg på Power BI ved hjelp av legitimasjonen for administratorkontoen.
Velg ... fra toppteksten på siden.>Administrasjonsportal for innstillinger>.
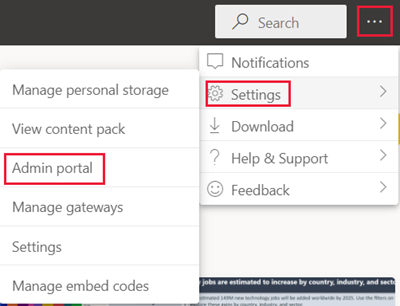
Gå til Kapasitetsinnstillinger , og velg en kapasitet fra Power BI Premium-fanen .
Utvid arbeidsbelastninger.
Angi verdiene for hver arbeidsbelastning i henhold til spesifikasjonene.
Velg Bruk.
Overvåk arbeidsbelastninger
Bruk Microsoft Fabric Capacity Metrics-appen til å overvåke kapasitetens aktivitet.
Viktig
Hvis Power BI Premium-kapasiteten opplever høy ressursbruk, noe som resulterer i ytelses- eller pålitelighetsproblemer, kan du motta varslings-e-postmeldinger for å identifisere og løse problemet. Dette kan være en strømlinjeformet måte å feilsøke overbelastede kapasiteter på. Hvis du vil ha mer informasjon, kan du se Varsler.
KUNSTIG INTELLIGENS (forhåndsversjon)
Ai-arbeidsbelastningen lar deg bruke kognitive tjenester og automatisert maskinlæring i Power BI. Bruk følgende innstillinger til å kontrollere arbeidsbelastningsvirkemåten.
| Angi navn | Bekrivelse |
|---|---|
| Maksimalt minne (%)1 | Den maksimale prosentandelen av tilgjengelig minne som AI-prosesser kan bruke i en kapasitet. |
| Tillat bruk fra Power BI Desktop | Denne innstillingen er reservert for fremtidig bruk og vises ikke i alle leiere. |
| Tillat bygging av maskinlæringsmodeller | Angir om forretningsanalytikere kan lære opp, validere og aktivere maskinlæringsmodeller direkte i Power BI. Hvis du vil ha mer informasjon, kan du se Automatisert maskinlæring i Power BI (forhåndsversjon). |
| Aktiver parallellitet for AI-forespørsler | Angir om AI-forespørsler kan kjøre parallelt. |
1 Premium krever ikke at minneinnstillingene endres. Minne i Premium administreres automatisk av det underliggende systemet.
Semantiske modeller
Denne delen beskriver følgende arbeidsbelastningsinnstillinger for semantiske modeller:
Power BI-innstillinger
Bruk innstillingene i tabellen nedenfor til å kontrollere arbeidsbelastningsvirkemåten. Innstillinger med en kobling har tilleggsinformasjon som du kan se gjennom i angitte inndelinger under tabellen.
| Angi navn | Bekrivelse |
|---|---|
| Maksimalt minne (%)1 | Den maksimale prosentandelen av tilgjengelig minne som semantiske modeller kan bruke i en kapasitet. |
| XMLA-endepunkt | Angir at tilkoblinger fra klientprogrammer respekterer sikkerhetsgruppemedlemskapet som er angitt på arbeidsområde- og appnivå. Hvis du vil ha mer informasjon, kan du se Koble til semantiske modeller med klientprogrammer og verktøy. |
| Maksimalt antall mellomliggende radsett | Maksimalt antall mellomliggende rader som returneres av DirectQuery. Standardverdien er 1000000, og det tillatte området er mellom 10 0000 og 2147483646. Den øvre grensen må kanskje begrenses ytterligere basert på hva datakilden støtter. |
| Maksimal frakoblet semantisk modellstørrelse (GB) | Maksimal størrelse på den frakoblede semantiske modellen i minnet. Dette er den komprimerte størrelsen på disken. Standardverdien er 0, som er den høyeste grensen definert av SKU. Det tillatte området er mellom 0 og kapasitetsstørrelsesgrensen. |
| Maksimalt antall resultatrader | Maksimalt antall rader som returneres i en DAX-spørring. Standardverdien er 2147483647, og det tillatte området er mellom 10000 og 2147483647. |
| Minnegrense for spørring (%) | Den maksimale prosentandelen av tilgjengelig minne i arbeidsbelastningen som kan brukes til å kjøre en MDX- eller DAX-spørring. Standardverdien er 0, noe som resulterer i at SKU-spesifikke automatiske minnegrenser for spørring blir brukt. |
| Tidsavbrudd for spørring (sekunder) | Maksimal tid før en spørring blir tidsavbrutt. Standardverdien er 3600 sekunder (1 time). En verdi på 0 angir at spørringer ikke blir tidsavbrutt. |
| Automatisk sideoppdatering | På/av-veksleknappen for å tillate premium arbeidsområder å ha rapporter med automatisk sideoppdatering basert på faste intervaller. |
| Minimum oppdateringsintervall | Hvis automatisk sideoppdatering er aktivert, er minimumsintervallet tillatt for sideoppdateringsintervallet. Standardverdien er fem minutter, og minimum tillatt er ett sekund. |
| Endringsgjenkjenningsmål | På/av-veksleknappen for å tillate premium arbeidsområder å ha rapporter med automatisk sideoppdatering basert på endringsgjenkjenning. |
| Minimum kjøringsintervall | Hvis målet for endringsgjenkjenning er aktivert, kan minimumsintervallet for kjøring av data bli avspørrt. Standardverdien er fem sekunder, og minimum tillatt er ett sekund. |
1 Premium krever ikke at minneinnstillingene endres. Minne i Premium administreres automatisk av det underliggende systemet.
Maksimalt antall mellomliggende radsett
Bruk denne innstillingen til å kontrollere virkningen av ressurskrevende eller dårlig utformede rapporter. Når en spørring til en Semantisk DirectQuery-modell resulterer i et svært stort resultat fra kildedatabasen, kan det føre til en økning i minnebruk og behandling av indirekte kostnader. Denne situasjonen kan føre til at andre brukere og rapporter har lite ressurser. Med denne innstillingen kan kapasitetsadministratoren justere hvor mange rader en enkeltspørring kan hente fra datakilden.
Alternativt, hvis kapasiteten kan støtte mer enn én million radstandard, og du har en stor semantisk modell, kan du øke denne innstillingen for å hente flere rader.
Denne innstillingen påvirker bare DirectQuery-spørringer, mens antall rader med maksimalt resultat påvirker DAX-spørringer.
Maksimal størrelse på semantisk semantisk modell i frakoblet modus
Bruk denne innstillingen til å hindre at rapportopprettere publiserer en stor semantisk modell som kan påvirke kapasiteten negativt. Power BI kan ikke bestemme faktisk størrelse i minnet før den semantiske modellen er lastet inn i minnet. Det er mulig at en semantisk modell med en mindre frakoblet størrelse kan ha et større minneavtrykk enn en semantisk modell med en større frakoblet størrelse.
Hvis du har en eksisterende semantisk modell som er større enn størrelsen du angir for denne innstillingen, vil den semantiske modellen ikke lastes inn når en bruker prøver å få tilgang til den. Den semantiske modellen kan også mislykkes hvis den er større enn maksimalt minne som er konfigurert for arbeidsbelastningen for semantiske modeller.
Denne innstillingen gjelder for modeller i både lite semantisk modelllagringsformat (ABF-format) og stort semantisk modelllagringsformat (PremiumFiles), selv om den frakoblede størrelsen på samme modell kan variere når den lagres i ett format kontra et annet. Hvis du vil ha mer informasjon, kan du se Store modeller i Power BI Premium.
For å sikre ytelsen til systemet, brukes et ekstra SKU-spesifikt hardt tak for maksimal frakoblet semantisk modellstørrelse, uavhengig av den konfigurerte verdien. Det ekstra SKU-spesifikke harde taket i tabellen nedenfor gjelder ikke for Semantiske Power BI-modeller som er lagret i stort semantisk modelllagringsformat.
| Lagerføringsenhet | Grense1 |
|---|---|
| F2 | 1 GB |
| F4 | 2 GB |
| F8/EM1/A1 | 3 GB |
| F16/EM2/A2 | 5 GB |
| F32/EM3/A3 | 6 GB |
| F64/P1/A4 | 10 GB |
| F128/P2/A5 | 10 GB |
| F256/P3/A6 | 10 GB |
| F512/P4/A7 | 10 GB |
| F1024/P5/A8 | 10 GB |
| F2048 | 10 GB |
1Hardt tak for maksimal frakoblet semantisk modellstørrelse (lite lagringsformat).
Maksimalt antall radsett for resultat
Bruk denne innstillingen til å kontrollere virkningen av ressurskrevende eller dårlig utformede rapporter. Hvis denne grensen nås i en DAX-spørring, ser en rapportbruker følgende feil. De bør kopiere feildetaljene og kontakte en administrator.
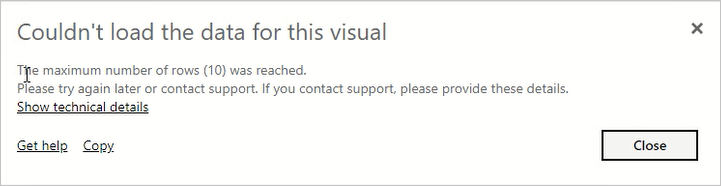
Denne innstillingen påvirker bare DAX-spørringer, mens maksimalt antall mellomliggende radsett påvirker DirectQuery-spørringer.
Minnegrense for spørring
Bruk denne innstillingen til å kontrollere virkningen av ressurskrevende eller dårlig utformede rapporter. Noen spørringer og beregninger kan resultere i mellomliggende resultater som bruker mye minne på kapasiteten. Denne situasjonen kan føre til at andre spørringer kjøres svært sakte, forårsaker utestengelse av andre semantiske modeller fra kapasiteten og fører til minnefeil for andre brukere av kapasiteten.
Denne innstillingen gjelder for alle DAX- og MDX-spørringer som utføres av Power BI-rapporter, Analyser i Excel-rapporter og andre verktøy som kan kobles til over XMLA-endepunktet.
Dataoppdateringsoperasjoner kan også kjøre DAX-spørringer som en del av oppdatering av instrumentbordfliser og visuelle hurtigbuffere etter at dataene i den semantiske modellen er oppdatert. Slike spørringer kan også potensielt mislykkes på grunn av denne innstillingen, og dette kan føre til at dataoppdateringsoperasjonen vises i en mislykket tilstand, selv om dataene i den semantiske modellen ble oppdatert.
Standardinnstillingen er 0, noe som resulterer i at følgende SKU-spesifikke automatiske minnegrense for spørring blir brukt.
| Lagerføringsenhet | Minnegrense for automatisk spørring |
|---|---|
| F2 | 1 GB |
| F4 | 1 GB |
| F8/EM1/A1 | 1 GB |
| F16/EM2/A2 | 2 GB |
| F32/EM3/A3 | 5 GB |
| F64/P1/A4 | 10 GB |
| F128/P2/A5 | 10 GB |
| F256/P3/A6 | 10 GB |
| F512/P4/A7 | 20 GB |
| F1024/P5/A8 | 40 GB |
| F2048 | 40 GB |
Spørringsgrensen for et arbeidsområde som ikke er tilordnet en Premium-kapasitet, er 1 GB.
Tidsavbrudd for spørring
Bruk denne innstillingen til å opprettholde bedre kontroll over langvarige spørringer, noe som kan føre til at rapporter lastes inn sakte for brukere.
Denne innstillingen gjelder for alle DAX- og MDX-spørringer som utføres av Power BI-rapporter, Analyser i Excel-rapporter og andre verktøy som kan kobles til over XMLA-endepunktet.
Dataoppdateringsoperasjoner kan også kjøre DAX-spørringer som en del av oppdatering av instrumentbordfliser og visuelle hurtigbuffere etter at dataene i den semantiske modellen er oppdatert. Slike spørringer kan også potensielt mislykkes på grunn av denne innstillingen, og dette kan føre til at dataoppdateringsoperasjonen vises i en mislykket tilstand, selv om dataene i den semantiske modellen ble oppdatert.
Denne innstillingen gjelder for én enkelt spørring, og ikke hvor lang tid det tar å kjøre alle spørringene som er knyttet til oppdatering av en semantisk modell eller rapport. Vurder følgende eksempel:
- Innstillingen for tidsavbrudd for spørring er 1200 (20 minutter).
- Det er fem spørringer å utføre, og hver kjører 15 minutter.
Den kombinerte tiden for alle spørringer er 75 minutter, men innstillingsgrensen er ikke nådd fordi alle individuelle spørringer kjører i mindre enn 20 minutter.
Vær oppmerksom på at Power BI-rapporter overstyrer denne standarden med et mye mindre tidsavbrudd for hver spørring til kapasiteten. Tidsavbruddet for hver spørring er vanligvis omtrent tre minutter.
Automatisk sideoppdatering
Når den er aktivert, tillater automatisk sideoppdatering brukere i Premium-kapasiteten å oppdatere sider i rapporten med et definert intervall, for DirectQuery-kilder. Som kapasitetsadministrator kan du gjøre følgende:
- Aktivere og deaktivere automatisk sideoppdatering
- Definer et minimum oppdateringsintervall
Slik finner du innstillingen for automatisk sideoppdatering:
Velg Kapasitetsinnstillinger i administrasjonsportalen for Power BI.
Velg kapasiteten, og rull deretter nedover og utvid Arbeidsbelastninger-menyen .
Rull ned til inndelingen Semantiske modeller .
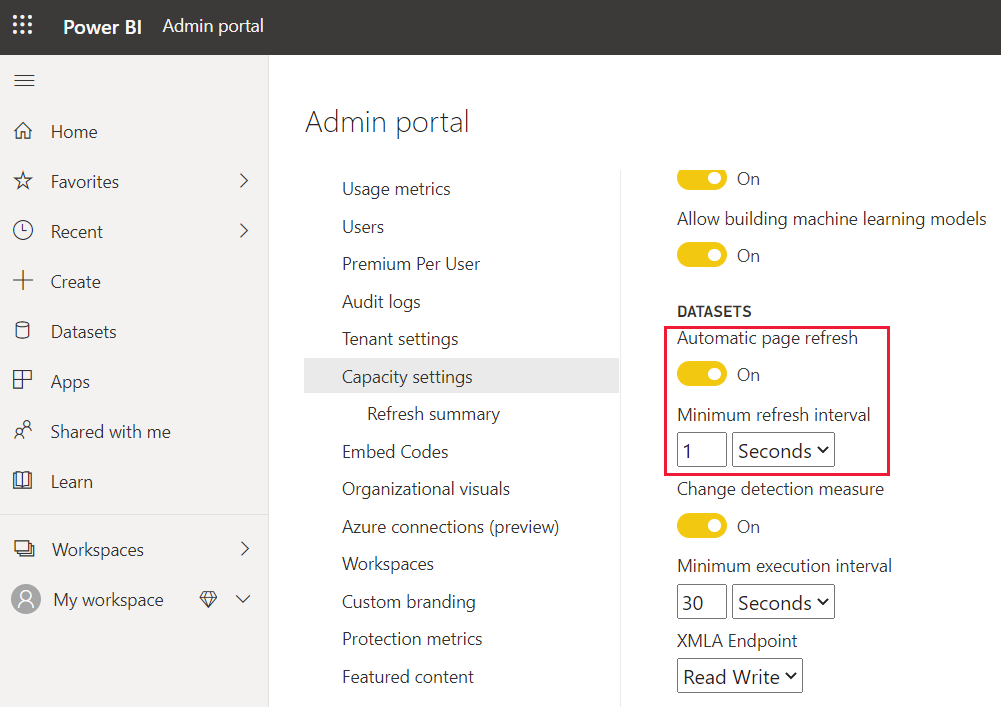
Spørringer som opprettes av automatisk sideoppdatering, går direkte til datakilden, så det er viktig å vurdere pålitelighet og laste inn på disse kildene når du tillater automatisk sideoppdatering i organisasjonen.
Egenskaper for Analysis Services-server
Power BI Premium støtter flere Analysis Services-serveregenskaper. Hvis du vil se gjennom disse egenskapene, kan du se Serveregenskaper i Analysis Services.
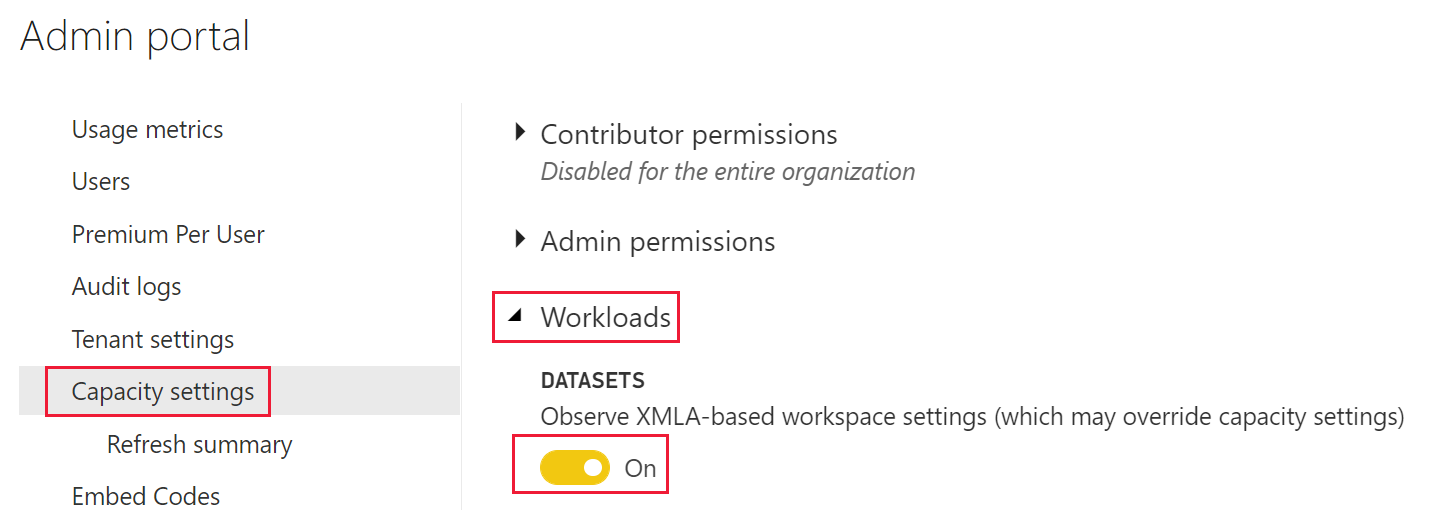
Bryter for administrasjonsportal
Innstillingen for XMLA-baserte serveregenskaper for Analysis Services er aktivert som standard. Når dette er aktivert, kan administratorer for arbeidsområder endre virkemåter for et individuelt arbeidsområde. Endrede egenskaper gjelder bare for arbeidsområdet. Følg fremgangsmåten nedenfor for å aktivere innstillingen for egenskapene for Analysis Services-serveren.
Velg kapasiteten du vil deaktivere egenskapene for Analysis Services-serveren i.
Utvid arbeidsbelastninger.
Velg innstillingen du vil bruke for bryteren Observer XMLA-baserte innstillinger for arbeidsområde (som kan overstyre kapasitetsinnstillinger) under semantiske modeller.
Dataflyt
Med arbeidsbelastningen for dataflyter kan du bruke dataflyter for selvbetjent dataforberedelse, til å innta, transformere, integrere og berike data. Bruk følgende innstillinger til å kontrollere arbeidsbelastningsvirkemåten i Premium. Power BI Premium krever ikke at minneinnstillingene endres. Minne i Premium administreres automatisk av det underliggende systemet.
Utvidet dataflytdatabehandlingsmotor
Hvis du vil dra nytte av den nye databehandlingsmotoren, deler du inn inntak av data i separate dataflyter og setter transformasjonslogikk i beregnede enheter i forskjellige dataflyter. Denne fremgangsmåten anbefales fordi databehandlingsmotoren fungerer på dataflyter som refererer til en eksisterende dataflyt. Det fungerer ikke på inntaksdataflyter. Etter denne veiledningen sikrer du at den nye databehandlingsmotoren håndterer transformasjonstrinn, for eksempel sammenføyninger og flettinger, for optimal ytelse.
Paginerte rapporter
Med arbeidsbelastningen for paginerte rapporter kan du kjøre paginerte rapporter, basert på standard sql server Reporting Services-format, i Power Bi-tjeneste.
Paginerte rapporter har de samme funksjonene som SQL Server Reporting Services (SSRS) rapporterer i dag, inkludert muligheten for rapportforfattere til å legge til egendefinert kode. Dette gjør det mulig for forfattere å endre rapporter dynamisk, for eksempel endre tekstfarger basert på kodeuttrykk.
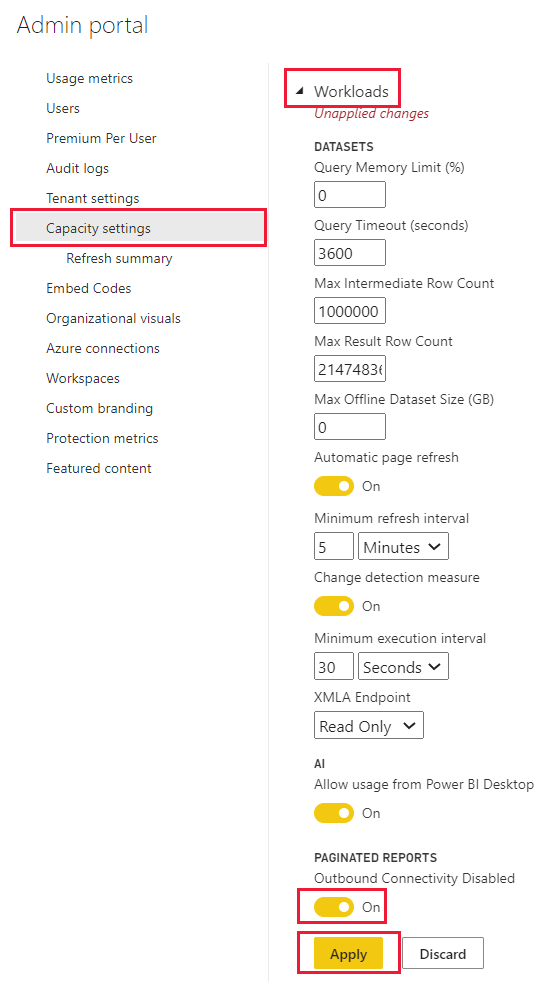
Utgående tilkobling
Utgående tilkobling er aktivert som standard. Det gjør det mulig for paginerte rapporter å sende forespørsler om å hente eksterne ressurser, for eksempel bilder, og kalle eksterne API-er og Azure-funksjoner definert ved hjelp av egendefinert kode i paginerte rapporter. En Fabric-administrator kan deaktivere denne innstillingen i administrasjonsportalen for Power BI.
Følg disse trinnene for å gå til innstillingene for utgående tilkobling:
Velg kapasiteten du vil deaktivere utgående forespørsler for paginerte rapporter for, fra Power BI Premium-fanen.
Utvid arbeidsbelastninger.
Den utgående tilkoblingsbryteren er i delen sideformaterte rapporter .
Når deaktivering av utgående tilkobling er deaktivert, er utgående tilkobling aktivert.
Når deaktivering av utgående tilkobling er aktivert, deaktiveres utgående tilkobling.
Når du har gjort en endring, velger du Bruk.
Arbeidsbelastningen for paginerte rapporter aktiveres automatisk, og er alltid aktivert.