Veiledning for sammensatt modell i Power BI Desktop
Denne artikkelen er rettet mot datamodellerere som utvikler sammensatte Power BI-modeller. Den beskriver brukstilfeller for sammensatt modell, og gir deg utformingsveiledning. Veiledningen kan spesielt hjelpe deg med å finne ut om en sammensatt modell passer for løsningen. Hvis den er det, vil denne artikkelen også hjelpe deg med å utforme optimale sammensatte modeller og rapporter.
Merk
En innføring i sammensatte modeller dekkes ikke i denne artikkelen. Hvis du ikke er helt kjent med sammensatte modeller, anbefaler vi at du først leser artikkelen Bruk sammensatte modeller i Power BI Desktop .
Fordi sammensatte modeller består av minst én DirectQuery-kilde, er det også viktig at du har en grundig forståelse av modellrelasjoner, DirectQuery-modeller og veiledning for DirectQuery-modellutforming.
Brukstilfeller for sammensatt modell
Per definisjon kombinerer en sammensatt modell flere kildegrupper. En kildegruppe kan representere importerte data eller en tilkobling til en DirectQuery-kilde. En DirectQuery-kilde kan enten være en relasjonsdatabase eller en annen tabellmodell, som kan være en semantisk Modell for Power BI eller en Analysis Services-tabellmodell. Når en tabellmodell kobles til en annen tabellmodell, kalles den kjede. Hvis du vil ha mer informasjon, kan du se Bruke sammensatte modeller i Power BI Desktop.
Merk
Når en modell kobles til en tabellmodell, men ikke utvider den med flere data, er den ikke en sammensatt modell. I dette tilfellet er det en DirectQuery-modell som kobler til en ekstern modell, så den består av bare én kildegruppe. Du kan opprette denne typen modell for å endre objektegenskaper for kildemodell, for eksempel et tabellnavn, kolonnesorteringsrekkefølge, formatstreng eller andre.
Tilkobling til tabellmodeller er spesielt relevant når du utvider en semantisk organisasjonsmodell (når det er en Semantisk modell for Power BI eller Analysis Services-modell). En semantisk virksomhetsmodell er grunnleggende for utvikling og drift av et datalager. Det gir et abstraksjonslag over dataene i datalageret for å presentere forretningsdefinisjoner og terminologi. Det brukes ofte som en kobling mellom fysiske datamodeller og rapporteringsverktøy, for eksempel Power BI. I de fleste organisasjoner administreres det av et sentralt team, og derfor beskrives det som virksomhet. Hvis du vil ha mer informasjon, kan du se enterprise BI-bruksscenarioet .
Du kan vurdere å utvikle en sammensatt modell i følgende situasjoner:
- Modellen kan være en DirectQuery-modell, og du vil øke ytelsen. I en sammensatt modell kan du forbedre ytelsen ved å konfigurere riktig lagringsplass for hver tabell. Du kan også legge til brukerdefinerte aggregasjoner. Begge disse optimaliseringene er beskrevet senere i denne artikkelen.
- Du vil kombinere en DirectQuery-modell med mer data, som må importeres til modellen. Du kan laste inn importerte data fra en annen datakilde eller fra beregnede tabeller.
- Du vil kombinere to eller flere DirectQuery-datakilder til én enkelt modell. Disse kildene kan være relasjonsdatabaser eller andre tabellmodeller.
Merk
Sammensatte modeller kan ikke inkludere tilkoblinger til bestemte eksterne analytiske databaser. Disse databasene inkluderer SAP Business Warehouse og SAP HANA når du behandler SAP HANA som en flerdimensjonal kilde.
Evaluer andre alternativer for modellutforming
Selv om sammensatte Power BI-modeller kan løse bestemte utformingsutfordringer, kan de bidra til treg ytelse. I enkelte tilfeller kan det også oppstå uventede beregningsresultater (beskrevet senere i denne artikkelen). Av disse grunnene kan du evaluere andre alternativer for modellutforming når de finnes.
Når det er mulig, er det best å utvikle en modell i importmodus. Denne modusen gir størst utformingsfleksibilitet og best ytelse. Utfordringer relatert til store datavolumer, eller rapportering om data i nær sanntid, kan imidlertid ikke alltid løses av importmodeller. I begge disse tilfellene kan du vurdere en DirectQuery-modell, forutsatt at dataene lagres i én enkelt datakilde som støttes av DirectQuery-modus. Hvis du vil ha mer informasjon, kan du se DirectQuery-modeller i Power BI Desktop.
Tips
Hvis målet ditt bare er å utvide en eksisterende tabellmodell med mer data, legger du til dataene i den eksisterende datakilden når det er mulig.
Tabelllagringsmodus
I en sammensatt modell kan du angi lagringsmodus for hver tabell (unntatt beregnede tabeller).
- DirectQuery: Vi anbefaler at du angir denne modusen for tabeller som representerer store datavolumer, eller som må levere nær sanntidsresultater. Data vil aldri bli importert til disse tabellene. Vanligvis vil disse tabellene være faktatabeller, som er tabeller som oppsummeres.
- Importer: Vi anbefaler at du angir denne modusen for tabeller som ikke brukes til filtrering og gruppering av faktatabeller i DirectQuery- eller Hybrid-modus. Det er også det eneste alternativet for tabeller basert på kilder som ikke støttes av DirectQuery-modus. Beregnede tabeller importerer alltid tabeller.
- Dobbel: Vi anbefaler at du angir denne modusen for dimensjonstabeller, når det er en mulighet for at de blir spurt sammen med DirectQuery-faktatabeller fra samme kilde.
- Hybrid: Vi anbefaler at du angir denne modusen ved å legge til importpartisjoner og én DirectQuery-partisjon i en faktatabell når du vil inkludere de nyeste dataendringene i sanntid, eller når du vil gi rask tilgang til de mest brukte dataene gjennom importpartisjoner, samtidig som du forlater mesteparten av mer sjeldent brukte data i datalageret.
Det finnes flere mulige scenarioer når Power BI spør en sammensatt modell.
- Bare importer eller doble tabeller: Power BI henter alle data fra modellhurtigbufferen. Det vil levere raskest mulig ytelse. Dette scenarioet er vanlig for dimensjonstabeller som spørres etter filtre eller slicervisualobjekter.
- Spørringer med to tabeller eller DirectQuery-tabeller fra samme kilde: Power BI henter alle data ved å sende én eller flere opprinnelige spørringer til DirectQuery-kilden. Det vil gi god ytelse, spesielt når det finnes riktige indekser i kildetabellene. Dette scenarioet er vanlig for spørringer som relaterer tabeller med to dimensjoner og directquery-faktatabeller. Disse spørringene er intrakildegruppe, og derfor evalueres alle én-til-én- eller én-til-mange-relasjoner som vanlige relasjoner.
- Spørringer med to tabeller eller hybridtabeller fra samme kilde: Dette scenarioet er en kombinasjon av de to foregående scenarioene. Power BI henter data fra modellhurtigbufferen når den er tilgjengelig i importpartisjoner, ellers sender den én eller flere opprinnelige spørringer til DirectQuery-kilden. Den gir raskest mulig ytelse fordi bare en del av dataene spørres i datalageret, spesielt når det finnes riktige indekser i kildetabellene. Når det gjelder de doble dimensjonstabellene og DirectQuery-faktatabellene, er disse spørringene intrakildegrupper, og derfor evalueres alle én-til-én- eller én-til-mange-relasjoner som vanlige relasjoner.
- Alle andre spørringer: Disse spørringene omfatter grupperelasjoner på tvers av kilder. Det er enten fordi en importtabell er knyttet til en DirectQuery-tabell, eller en dobbel tabell er knyttet til en DirectQuery-tabell fra en annen kilde , i så fall fungerer den som en importtabell. Alle relasjoner evalueres som begrensede relasjoner. Det betyr også at grupperinger som brukes på ikke-DirectQuery-tabeller, må sendes til DirectQuery-kilden som materialiserte delspørringer (virtuelle tabeller). I dette tilfellet kan den opprinnelige spørringen være ineffektiv, spesielt for store grupperingssett.
Sammendrag anbefaler vi at du:
- Vurder nøye at en sammensatt modell er den riktige løsningen – selv om den tillater integrering på modellnivå av ulike datakilder, introduserer den også utformingskompleksiteter med mulige konsekvenser (beskrevet senere i denne artikkelen).
- Angi lagringsmodusen til DirectQuery når en tabell er en faktatabell som lagrer store datavolumer, eller når den må levere nær sanntidsresultater.
- Vurder å bruke hybridmodus ved å definere en trinnvis oppdateringspolicy og sanntidsdata, eller ved å partisjonere faktatabellen ved hjelp av TOM, TMSL eller et tredjepartsverktøy. Hvis du vil ha mer informasjon, kan du se Trinnvis oppdatering og sanntidsdata for semantiske modeller og bruksscenarioet for administrasjon av avansert datamodell.
- Angi lagringsmodusen til Dobbel når en tabell er en dimensjonstabell, og den vil bli spurt sammen med DirectQuery- eller hybridfaktatabeller som er i samme kildegruppe.
- Angi passende oppdateringsfrekvenser for å beholde modellhurtigbufferen for to og hybride tabeller (og eventuelle avhengige beregnede tabeller) synkronisert med kildedatabasen(e).
- Prøv å sikre dataintegritet på tvers av kildegrupper (inkludert modellbufferen) fordi begrensede relasjoner vil eliminere rader i spørringsresultater når relaterte kolonneverdier ikke samsvarer.
- Når det er mulig, optimaliserer du DirectQuery-datakilder med riktige indekser for effektive sammenføyninger, filtrering og gruppering.
Brukerdefinerte aggregasjoner
Du kan legge til brukerdefinerte aggregasjoner i DirectQuery-tabeller. Deres formål er å forbedre ytelsen for spørringer med høyere korn .
Når aggregasjoner bufres i modellen, fungerer de som importtabeller (selv om de ikke kan brukes som en modelltabell). Hvis du legger til importaggregasjoner i en DirectQuery-modell, resulterer det i en sammensatt modell.
Merk
Hybridtabeller støtter ikke aggregasjoner fordi noen av partisjonene fungerer i importmodus. Det er ikke mulig å legge til aggregasjoner på nivået til en individuell DirectQuery-partisjon.
Vi anbefaler at en aggregasjon følger en grunnleggende regel: Radantallet bør være minst en faktor på 10 mindre enn den underliggende tabellen. Hvis den underliggende tabellen for eksempel lagrer 1 milliard rader, bør ikke aggregasjonstabellen overskride 100 millioner rader. Denne regelen sikrer at det er en tilstrekkelig ytelsesgevinst i forhold til kostnadene ved å opprette og vedlikeholde aggregasjonen.
Grupperelasjoner på tvers av kilder
Når en modellrelasjon strekker seg over kildegrupper, kalles den en grupperelasjon på tvers av kilder. Relasjoner på tvers av kildegrupper er også begrensede relasjoner fordi det ikke er noen garantert «én»-side. Hvis du vil ha mer informasjon, kan du se Relasjonsevaluering.
Merk
I enkelte situasjoner kan du unngå å opprette en grupperelasjon på tvers av kilder. Se emnet Bruk synkroniser slicere senere i denne artikkelen.
Når du definerer grupperelasjoner på tvers av kilder, bør du vurdere følgende anbefalinger.
- Bruke relasjonskolonner med lav kardinalitet: For best ytelse anbefaler vi at relasjonskolonnene har lav kardinalitet, noe som betyr at de bør lagre mindre enn 50 000 unike verdier. Denne anbefalingen gjelder spesielt når du kombinerer tabellmodeller, og for kolonner som ikke er tekst.
- Unngå å bruke store tekstrelasjonskolonner: Hvis du må bruke tekstkolonner i en relasjon, beregner du den forventede tekstlengden for filteret ved å multiplisere kardinaliteten med den gjennomsnittlige lengden på tekstkolonnen. Den mulige tekstlengden bør ikke overstige 1 000 000 tegn.
- Øk relasjonstettheten: Hvis det er mulig, oppretter du relasjoner på et høyere nivå av detaljnivå. I stedet for å relatere en datotabell på datonøkkelen, bruker du for eksempel månedsnøkkelen i stedet. Denne utformingstilnærmingen krever at den relaterte tabellen inneholder en månedsnøkkelkolonne, og rapporter kan ikke vise daglige fakta.
- Strebe etter å oppnå en enkel relasjonsutforming: Opprett bare en grupperelasjon på tvers av kilder når det er nødvendig, og prøv å begrense antall tabeller i relasjonsbanen. Denne utformingstilnærmingen bidrar til å forbedre ytelsen og unngå tvetydige relasjonsbaner.
Advarsel!
Siden Power BI Desktop ikke validerer relasjoner på tvers av kildegrupper grundig, er det mulig å opprette tvetydige relasjoner.
Relasjonsscenario for krysskildegruppe 1
Vurder et scenario med en kompleks relasjonsutforming og hvordan den kan produsere ulike – men likevel gyldige – resultater.
I dette scenarioet har Region tabellen i kildegruppen A en relasjon til Date tabellen og Sales tabellen i kildegruppen B. Relasjonen mellom Region-tabellen og den Date tabellen er aktiv, mens relasjonen mellom Region tabellen og Sales tabellen er inaktiv. Det finnes også en aktiv relasjon mellom Region-tabellen og Sales tabellen, som begge er i kildegruppe B. Tabellen Sales inneholder et mål med navnet TotalSales, og Region tabellen inneholder to mål med navnet RegionalSales og RegionalSalesDirect.
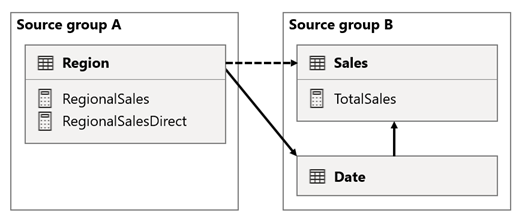
Her er måldefinisjonene.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Legg merke til hvordan RegionalSales-målet refererer til TotalSales målet, mens RegionalSalesDirect ikke gjør det. I stedet bruker RegionalSalesDirect målet uttrykket SUM(Sales[Sales]), som er uttrykket for TotalSales målet.
Forskjellen i resultatet er subtil. Når Power BI evaluerer RegionalSales målet, bruker det filteret fra Region-tabellen på både Sales-tabellen og Date-tabellen. Filteret overføres derfor også fra Date tabellen til Sales tabellen. Når Power BI evaluerer RegionalSalesDirect mål, overfører det derimot bare filteret fra Region tabellen til Sales tabellen. Resultatene som returneres av RegionalSales mål og RegionalSalesDirect målet kan variere, selv om uttrykkene er semantisk like.
Viktig
Når du bruker CALCULATE funksjonen med et uttrykk som er et mål i en ekstern kildegruppe, tester du beregningsresultatene grundig.
Relasjonsscenario for krysskildegruppe 2
Vurder et scenario når en grupperelasjon på tvers av kilder har relasjonskolonner med høy kardinalitet.
I dette scenarioet er den Date tabellen relatert til Sales tabellen i DateKey kolonnene. Datatypen for de DateKey kolonnene er heltall, og lagrer heltall som bruker yyymmdd-format. Tabellene tilhører ulike kildegrupper. Videre er det en høykardinalitetsrelasjon fordi den tidligste datoen i den Date tabellen er 1. januar 1900, og den siste datoen er 31. desember 2100, så det er totalt 73 414 rader i tabellen (én rad for hver dato i tidsperioden 1900-2100).
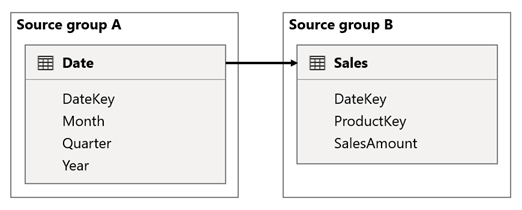
Det er to tilfeller av bekymring.
Først, når du bruker Date tabellkolonner som filtre, filtrerer filteroverføring den DateKey kolonnen i den Sales tabellen for å evaluere mål. Når du filtrerer etter ett enkelt år, for eksempel 2022, vil DAX-spørringen inneholde et filteruttrykk som Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Tekststørrelsen for spørringen kan vokse til å bli svært stor når antall verdier i filteruttrykket er stort, eller når filterverdiene er lange strenger. Det er dyrt for Power BI å generere den lange spørringen og for at datakilden skal kjøre spørringen.
For det andre, når du bruker Date tabellkolonner, for eksempel Year, Quartereller Month, som grupperingskolonner, resulterer det i filtre som inkluderer alle unike kombinasjoner av år, kvartal eller måned, ogDateKey kolonneverdier. Strengstørrelsen for spørringen, som inneholder filtre i grupperingskolonnene og relasjonskolonnen, kan bli svært stor. Det er spesielt sant når antall grupperingskolonner og/eller kardinaliteten til sammenføyningskolonnen (den DateKey kolonnen) er stor.
Hvis du vil løse eventuelle ytelsesproblemer, kan du:
- Legg til
Datetabellen i datakilden, noe som resulterer i en enkelt kildegruppemodell (det vil si at den ikke lenger er en sammensatt modell). - Øk relasjonstettheten. Du kan for eksempel legge til en
MonthKeykolonne i begge tabellene og opprette relasjonen på disse kolonnene. Ved å øke relasjonstettheten mister du imidlertid muligheten til å rapportere om daglig salgsaktivitet (med mindre du bruker kolonnenDateKeyfraSalestabellen).
Relasjonsscenario for krysskildegruppe 3
Vurder et scenario når det ikke er samsvarende verdier mellom tabeller i en grupperelasjon på tvers av kilder.
I dette scenarioet har Date tabellen i kildegruppen B en relasjon til den Sales tabellen i kildegruppen, og også til Target-tabellen i kildegruppen A. Alle relasjoner er én-til-mange fra den Date tabellen som relaterer de Year kolonnene. Tabellen Sales inneholder en SalesAmount kolonne som lagrer salgsbeløp, mens Target-tabellen inneholder en TargetAmount kolonne som lagrer målbeløp.
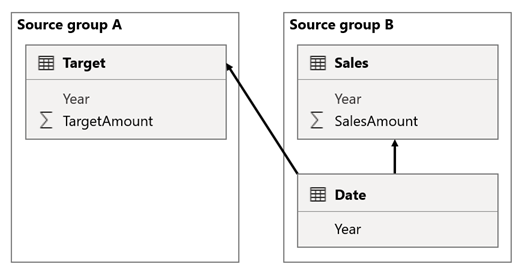
Tabellen Date lagrer årene 2021 og 2022. Tabellen Sales lagrer salgsbeløp for år 2021 (100) og 2022 (200), mens den Target tabellen lagrer målbeløp for 2021 (100), 2022 (200), og 2023 (300)– et fremtidig år.
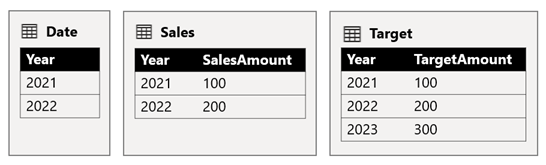
Når et power BI-tabellvisualobjekt spør den sammensatte modellen ved å gruppere på Year-kolonnen fra Date-tabellen og summere SalesAmount- og TargetAmount-kolonnene, viser den ikke et målbeløp for 2023. Det er fordi relasjonen mellom kilder er en begrenset relasjon, og dermed bruker INNER JOIN den semantikk, som eliminerer rader der det ikke finnes noen samsvarende verdi på begge sider. Det vil imidlertid produsere et riktig målbeløp totalt (600), fordi et Date tabellfilter ikke gjelder for evalueringen.
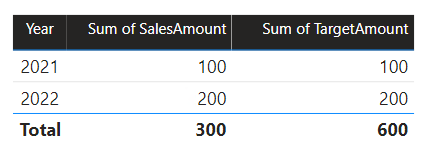
Hvis relasjonen mellom Date-tabellen og Target-tabellen er en intrakildegrupperelasjon (forutsatt at Target tabellen tilhørte kildegruppen B), vil visualobjektet inkludere en (tom) år for å vise målbeløpet for 2023 (og eventuelle andre uovertruffen år).
Viktig
Hvis du vil unngå feilrapportering, må du kontrollere at det finnes samsvarende verdier i relasjonskolonnene når dimensjons- og faktatabeller befinner seg i ulike kildegrupper.
Hvis du vil ha mer informasjon om begrensede relasjoner, kan du se Relasjonsevaluering.
Beregninger
Du bør vurdere bestemte begrensninger når du legger til beregnede kolonner og beregningsgrupper i en sammensatt modell.
Beregnede kolonner
Beregnede kolonner som legges til i en DirectQuery-tabell som henter dataene fra en relasjonsdatabase, for eksempel Microsoft SQL Server, er begrenset til uttrykk som opererer på én enkelt rad om gangen. Disse uttrykkene kan ikke bruke DAX-gjentakelsesfunksjonerCALCULATE
Merk
Det er ikke mulig å legge til beregnede kolonner eller beregnede tabeller som er avhengige av kjedede tabellmodeller.
Et beregnet kolonneuttrykk i en ekstern DirectQuery-tabell er bare begrenset til evaluering av intrarader. Du kan imidlertid skrive et slikt uttrykk, men det vil resultere i en feil når det brukes i et visualobjekt. Hvis du for eksempel legger til en beregnet kolonne i en ekstern DirectQuery-tabell med navnet DimProduct ved hjelp av uttrykket [Product Sales] / SUM (DimProduct[ProductSales]), kan du lagre uttrykket i modellen. Det vil imidlertid resultere i en feil når den brukes i et visualobjekt fordi det bryter med begrensningen for evaluering av intrarader.
Beregnede kolonner som er lagt til i en ekstern DirectQuery-tabell som er en tabellmodell, som enten er en semantisk Modell for Power BI eller Analysis Services-modell, er derimot mer fleksible. I dette tilfellet tillates alle DAX-funksjoner fordi uttrykket evalueres i kildefanemodellen.
Mange uttrykk krever at Power BI materialiserer den beregnede kolonnen før du bruker den som en gruppe eller et filter, eller aggregerer den. Når en beregnet kolonne materialiseres over en stor tabell, kan den være kostbar når det gjelder CPU og minne, avhengig av kardinaliteten til kolonnene som den beregnede kolonnen er avhengig av. I dette tilfellet anbefaler vi at du legger til de beregnede kolonnene i kildemodellen.
Merk
Når du legger til beregnede kolonner i en sammensatt modell, må du teste alle modellberegninger. Oppstrømsberegninger fungerer kanskje ikke som de skal fordi de ikke vurderte sin innflytelse på filterkonteksten.
Beregningsgrupper
Hvis det finnes beregningsgrupper i en kildegruppe som kobler til en semantisk Power BI-modell eller en Analysis Services-modell, kan Power BI returnere uventede resultater. Hvis du vil ha mer informasjon, kan du se Beregningsgrupper, spørring og målevaluering.
Modellutforming
Du bør alltid optimalisere en Power BI-modell ved å ta i bruk en utforming av stjerneskjema.
Tips
Hvis du vil ha mer informasjon, kan du se Forstå stjerneskjema og viktigheten for Power BI.
Pass på å opprette dimensjonstabeller som er atskilt fra faktatabeller, slik at Power BI kan tolke sammenføyninger riktig og produsere effektive spørringsplaner. Selv om denne veiledningen gjelder for alle Power BI-modeller, gjelder det spesielt for modeller som du gjenkjenner, blir en kildegruppe av en sammensatt modell. Det vil gi enklere og mer effektiv integrering av andre tabeller i nedstrømsmodeller.
Når det er mulig, unngår du å ha dimensjonstabeller i én kildegruppe som er relatert til en faktatabell i en annen kildegruppe. Det er fordi det er bedre å ha intrakildegrupperelasjoner enn relasjoner på tvers av kildegrupper, spesielt for relasjonskolonner med høy kardinalitet. Som beskrevet tidligere, er relasjoner på tvers av kildegrupper avhengige av å ha samsvarende verdier i relasjonskolonnene, ellers kan uventede resultater vises i visualobjekter for rapporter.
Sikkerhet på radnivå
Hvis modellen inneholder brukerdefinerte aggregasjoner, beregnede kolonner i importtabeller eller beregnede tabeller, må du kontrollere at sikkerhet på radnivå (RLS) er riktig konfigurert og testet.
Hvis den sammensatte modellen kobles til andre tabellmodeller, brukes RLS-regler bare på kildegruppen (lokal modell) der de er definert. De brukes ikke på andre kildegrupper (eksterne modeller). Du kan heller ikke definere RLS-regler i en tabell fra en annen kildegruppe, og du kan heller ikke definere RLS-regler i en lokal tabell som har en relasjon til en annen kildegruppe.
Rapportutforming
I enkelte situasjoner kan du forbedre ytelsen til en sammensatt modell ved å utforme et optimalisert rapportoppsett.
Visualobjekter for enkeltkildegruppe
Når det er mulig, kan du opprette visualobjekter som bruker felt fra én enkelt kildegruppe. Det er fordi spørringer generert av visualobjekter vil fungere bedre når resultatet hentes fra én enkelt kildegruppe. Vurder å opprette to visualobjekter plassert side ved side som henter data fra to forskjellige kildegrupper.
Bruke synkroniseringsslicere
I enkelte situasjoner kan du konfigurere synkroniseringsslicere for å unngå å opprette en grupperelasjon på tvers av kilder i modellen. Det kan gi deg mulighet til å kombinere kildegrupper visuelt som kan yte bedre.
Vurder et scenario når modellen har to kildegrupper. Hver kildegruppe har en produktdimensjonstabell som brukes til å filtrere forhandler- og Internett-salg.
I dette scenarioet inneholder kildegruppen A den Product tabellen som er relatert til ResellerSales tabellen. Kildegruppe B inneholder Product2 tabellen som er relatert til InternetSales tabellen. Det finnes ingen grupperelasjoner på tvers av kilder.
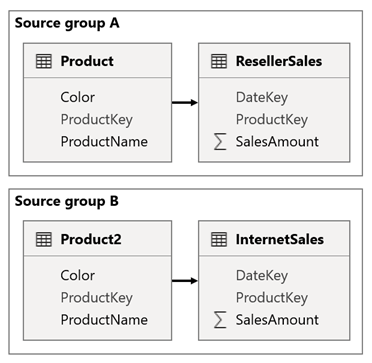
I rapporten legger du til en slicer som filtrerer siden ved hjelp av den Color kolonnen i Product tabellen. Sliceren filtrerer som standard ResellerSales tabellen, men ikke InternetSales tabellen. Deretter legger du til en skjult slicer ved hjelp av den Color kolonnen i Product2 tabellen. Ved å angi et identisk gruppenavn (funnet i avanserte alternativer for synkroniseringsslicere), overføres filtre som brukes på den synlige sliceren automatisk til den skjulte sliceren.
Merk
Selv om du bruker synkroniseringsslicere kan unngå behovet for å opprette en grupperelasjon på tvers av kilder, øker det kompleksiteten i modellutformingen. Sørg for å lære andre brukere hvorfor du utformet modellen med dupliserte dimensjonstabeller. Unngå forvirring ved å skjule dimensjonstabeller som du ikke vil at andre brukere skal bruke. Du kan også legge til beskrivelsestekst i de skjulte tabellene for å dokumentere formålet.
Hvis du vil ha mer informasjon, kan du se Synkronisere separate slicere.
Annen veiledning
Her er noen andre veiledninger for å hjelpe deg med å utforme og vedlikeholde sammensatte modeller.
- Ytelse og skalering: Hvis rapportene tidligere var koblet til en semantisk modell eller Analysis Services-modell i Power BI, kan Power BI-tjenesten bruke visuelle hurtigbuffere på nytt på tvers av rapporter. Når du konverterer live-tilkoblingen til å opprette en lokal DirectQuery-modell, vil rapporter ikke lenger dra nytte av disse hurtigbufferne. Som et resultat kan du oppleve langsommere ytelse eller til og med oppdateringsfeil. Arbeidsbelastningen for Power Bi-tjeneste vil også øke, noe som kan kreve at du skalerer opp kapasiteten eller distribuerer arbeidsbelastningen på tvers av andre kapasiteter. Hvis du vil ha mer informasjon om dataoppdatering og hurtigbufring, kan du se Dataoppdatering i Power BI.
- Gi nytt navn til: Vi anbefaler ikke at du gir nytt navn til semantiske modeller som brukes av sammensatte modeller, eller gir nytt navn til arbeidsområdene. Det er fordi sammensatte modeller kobler til Semantiske Power BI-modeller ved hjelp av arbeidsområdet og semantiske modellnavn (og ikke de interne unike identifikatorene). Hvis du gir nytt navn til en semantisk modell eller et arbeidsområde, kan tilkoblingene som brukes av den sammensatte modellen, brytes.
- Governance: Vi anbefaler ikke at din enkeltversjon av sannheten modellen er en sammensatt modell. Det er fordi det vil være avhengig av andre datakilder eller modeller, som hvis de oppdateres, kan føre til at den sammensatte modellen brytes. I stedet anbefalte vi at du publiserer en semantisk organisasjonsmodell som enkeltversjon av sannheten. Vurder denne modellen som et pålitelig grunnlag. Andre datamodellerere kan deretter opprette sammensatte modeller som utvider grunnmodell for å opprette spesialiserte modeller.
- Dataavstamming: Bruk dataavstamming og semantisk modelleffektanalyse funksjoner før du publiserer sammensatte modellendringer. Disse funksjonene er tilgjengelige i Power Bi-tjeneste, og de kan hjelpe deg med å forstå hvordan semantiske modeller er relatert og brukt. Det er viktig å forstå at du ikke kan utføre konsekvensanalyse på eksterne semantiske modeller som vises i avstammingsvisning, men faktisk befinner seg i et annet arbeidsområde. Hvis du vil utføre konsekvensanalyse på en ekstern semantisk modell, må du navigere til kildearbeidsområdet.
- skjemaoppdateringer: Du bør oppdatere den sammensatte modellen i Power BI Desktop når skjemaendringer gjøres i oppstrøms datakilder. Du må deretter publisere modellen på nytt til Power Bi-tjeneste. Pass på å teste beregninger og avhengige rapporter grundig.
Relatert innhold
Hvis du vil ha mer informasjon om denne artikkelen, kan du se følgende ressurser.
- Bruk av sammensatte modeller i Power BI Desktop
- Modellrelasjoner i Power BI Desktop
- DirectQuery-modeller i Power BI Desktop
- Bruke DirectQuery i Power BI Desktop
- Lagringsmodus i Power BI Desktop
- Brukerdefinerte aggregasjoner
- Spørsmål? Prøv å spørre Fabric Community
- Forslag? Bidra med ideer for å forbedre Fabric