Szybki start: rozpoznawanie intencji za pomocą usługi Conversational Language Understanding
Dokumentacja referencyjna Package (NuGet) | Dodatkowe przykłady w witrynie GitHub |
W tym przewodniku Szybki start użyjesz usług rozpoznawania mowy i języka do rozpoznawania intencji z danych dźwiękowych przechwyconych z mikrofonu. W szczególności użyjesz usługi Rozpoznawanie mowy do rozpoznawania mowy i modelu usługi Conversational Language Understanding (CLU) w celu zidentyfikowania intencji.
Ważne
Usługa Conversational Language Understanding (CLU) jest dostępna dla języków C# i C++ z zestawem Speech SDK w wersji 1.25 lub nowszej.
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób języka w witrynie Azure Portal.
- Pobierz klucz zasobu języka i punkt końcowy. Po wdrożeniu zasobu Language wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Konfigurowanie środowiska
Zestaw SPEECH SDK jest dostępny jako pakiet NuGet i implementuje platformę .NET Standard 2.0. Zestaw SPEECH SDK zostanie zainstalowany w dalszej części tego przewodnika, ale najpierw zapoznaj się z przewodnikiem instalacji zestawu SDK, aby uzyskać więcej wymagań.
Ustawianie zmiennych środowiskowych
W tym przykładzie wymagane są zmienne środowiskowe o nazwach LANGUAGE_KEY, , LANGUAGE_ENDPOINTSPEECH_KEYi SPEECH_REGION.
Aby uzyskać dostęp do zasobów usług Azure AI, aplikacja musi być uwierzytelniona. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
LANGUAGE_KEYśrodowiskową, zastąpyour-language-keyelement jednym z kluczy zasobu. - Aby ustawić zmienną
LANGUAGE_ENDPOINTśrodowiskową, zastąpyour-language-endpointelement jednym z regionów zasobu. - Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąpyour-speech-keyelement jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąpyour-speech-regionelement jednym z regionów zasobu.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennej środowiskowej w bieżącej uruchomionej konsoli, możesz ustawić zmienną środowiskową z wartością set setxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich uruchomionych programów, które będą musiały odczytać zmienną środowiskową, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Tworzenie projektu usługi Conversational Language Understanding
Po utworzeniu zasobu Language utwórz projekt language understanding języka konwersacyjnego w programie Language Studio. Projekt to obszar roboczy umożliwiający tworzenie niestandardowych modeli uczenia maszynowego na podstawie danych. Dostęp do projektu można uzyskać tylko do Ciebie i innych osób, które mają dostęp do używanego zasobu Language.
Przejdź do programu Language Studio i zaloguj się przy użyciu konta platformy Azure.
Tworzenie projektu interpretacji języka konwersacji
Na potrzeby tego przewodnika Szybki start możesz pobrać ten przykładowy projekt automatyzacji domu i zaimportować go. Ten projekt może przewidywać zamierzone polecenia na podstawie danych wejściowych użytkownika, takich jak włączanie i wyłączanie świateł.
W sekcji Informacje o pytaniach i języku konwersacyjnym w programie Language Studio wybierz pozycję Omówienie języka konwersacji.
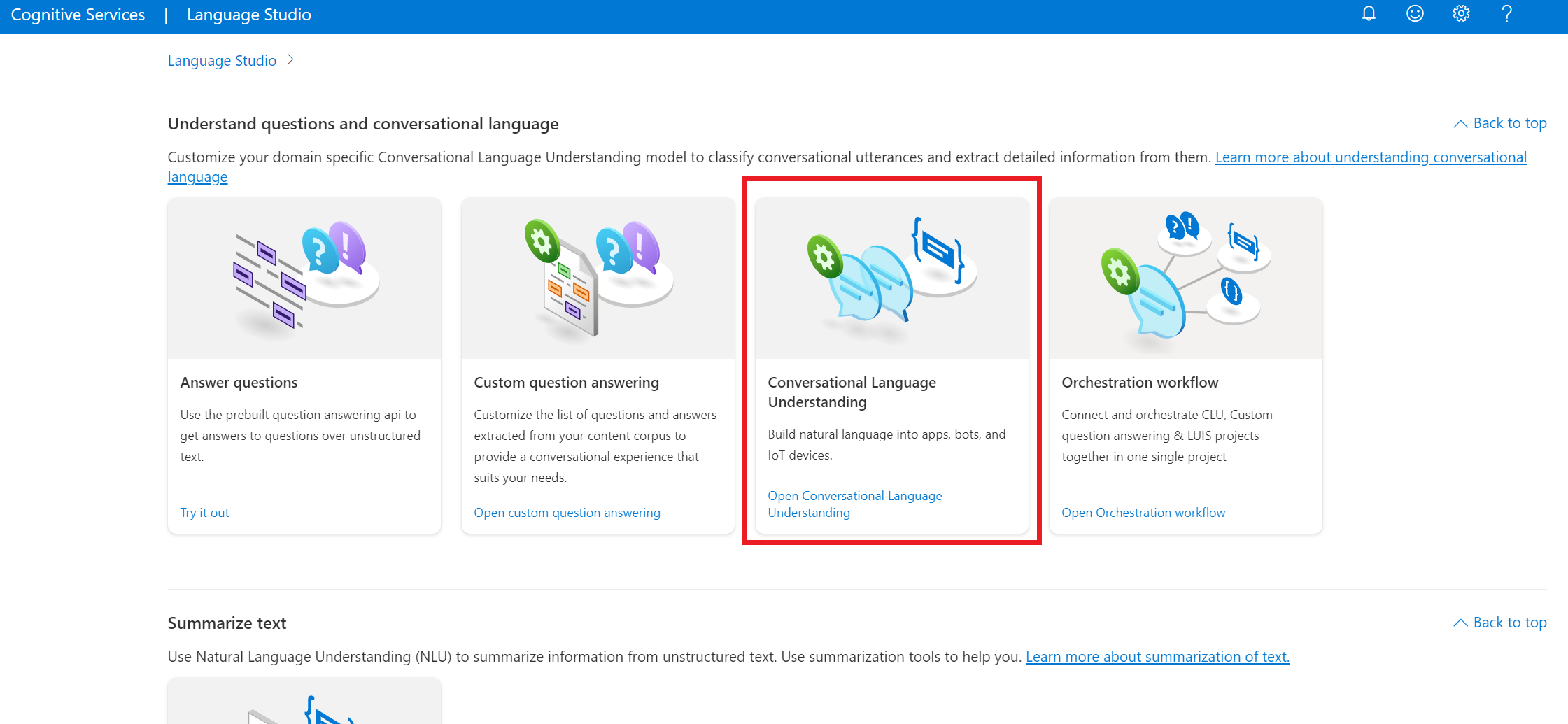
Spowoduje to wyświetlenie strony projektów interpretacji języka konwersacji. Obok przycisku Utwórz nowy projekt wybierz pozycję Importuj.

W wyświetlonym oknie przekaż plik JSON, który chcesz zaimportować. Upewnij się, że plik jest zgodny z obsługiwanym formatem JSON.


Po zakończeniu przekazywania zostanie wyświetlona strona Definicja schematu. W tym przewodniku Szybki start schemat został już skompilowany, a wypowiedzi są już oznaczone intencjami i jednostkami.
Szkolenie modelu
Zazwyczaj po utworzeniu projektu należy utworzyć wypowiedzi schematu i etykiet. Na potrzeby tego przewodnika Szybki start zaimportowaliśmy już gotowy projekt ze skompilowanym schematem i oznaczonymi etykietami wypowiedzi.
Aby wytrenować model, musisz rozpocząć zadanie szkoleniowe. Dane wyjściowe pomyślnego zadania szkoleniowego to wytrenowany model.
Aby rozpocząć trenowanie modelu z poziomu programu Language Studio:
Wybierz pozycję Train model (Trenowanie modelu ) z menu po lewej stronie.
Wybierz pozycję Start a training job (Rozpocznij zadanie szkoleniowe) z górnego menu.
Wybierz pozycję Train a new model (Trenowanie nowego modelu) i wprowadź nową nazwę modelu w polu tekstowym. W przeciwnym razie, aby zastąpić istniejący model modelem wytrenowanym na nowych danych, wybierz pozycję Zastąp istniejący model , a następnie wybierz istniejący model. Zastępowanie wytrenowanego modelu jest nieodwracalne, ale nie wpłynie to na wdrożone modele do momentu wdrożenia nowego modelu.
Wybierz tryb trenowania. Możesz wybrać standardowe szkolenie w celu szybszego szkolenia , ale jest dostępne tylko dla języka angielskiego. Możesz też wybrać opcję Zaawansowane szkolenie , które jest obsługiwane w przypadku innych języków i projektów wielojęzycznych, ale obejmuje dłuższe czasy trenowania. Dowiedz się więcej o trybach trenowania.
Wybierz metodę dzielenia danych. Możesz wybrać opcję Automatyczne dzielenie zestawu testów z danych treningowych, w których system podzieli wypowiedzi między zestawy treningowe i testowe, zgodnie z określonymi wartościami procentowymi. Możesz też użyć ręcznego podziału danych treningowych i testowych, ta opcja jest włączona tylko wtedy, gdy dodano wypowiedzi do zestawu testów po oznaczeniu wypowiedzi.
Wybierz przycisk Train (Trenuj).

Wybierz identyfikator zadania szkoleniowego z listy. Zostanie wyświetlony panel, w którym można sprawdzić postęp trenowania, stan zadania i inne szczegóły dotyczące tego zadania.
Uwaga
- Tylko pomyślnie ukończone zadania szkoleniowe będą generować modele.
- Trenowanie może potrwać od kilku minut do kilku godzin na podstawie liczby wypowiedzi.
- Jednocześnie może być uruchomione tylko jedno zadanie trenowania. Nie można uruchomić innych zadań szkoleniowych w tym samym projekcie, dopóki uruchomione zadanie nie zostanie ukończone.
- Uczenie maszynowe używane do trenowania modeli jest regularnie aktualizowane. Aby wytrenować poprzednią wersję konfiguracji, wybierz pozycję Wybierz tutaj, aby zmienić się na stronie Rozpocznij zadanie trenowania i wybierz poprzednią wersję.

Wdrażanie modelu
Zazwyczaj po trenowaniu modelu należy przejrzeć jego szczegóły oceny. W tym przewodniku Szybki start wdrożysz model i udostępnisz go do wypróbowania w programie Language Studio lub możesz wywołać interfejs API przewidywania.
Aby wdrożyć model z poziomu programu Language Studio:
Wybierz pozycję Deploying a model (Wdrażanie modelu ) z menu po lewej stronie.
Wybierz pozycję Dodaj wdrożenie , aby uruchomić Kreatora dodawania wdrożenia .

Wybierz pozycję Utwórz nową nazwę wdrożenia, aby utworzyć nowe wdrożenie i przypisać wytrenowany model z listy rozwijanej poniżej. W przeciwnym razie możesz wybrać pozycję Zastąp istniejącą nazwę wdrożenia, aby skutecznie zastąpić model używany przez istniejące wdrożenie.
Uwaga
Zastępowanie istniejącego wdrożenia nie wymaga zmian wywołania interfejsu API przewidywania, ale uzyskane wyniki będą oparte na nowo przypisanym modelu.

Wybierz wytrenowany model z listy rozwijanej Model .
Wybierz pozycję Wdróż , aby uruchomić zadanie wdrożenia.
Po pomyślnym wdrożeniu obok zostanie wyświetlona data wygaśnięcia. Wygaśnięcie wdrożenia jest wtedy, gdy wdrożony model będzie niedostępny do przewidywania, co zwykle występuje dwanaście miesięcy po wygaśnięciu konfiguracji trenowania.


W następnej sekcji użyjesz nazwy projektu i nazwy wdrożenia.
Rozpoznawanie intencji z mikrofonu
Wykonaj następujące kroki, aby utworzyć nową aplikację konsolową i zainstalować zestaw SPEECH SDK.
Otwórz wiersz polecenia, w którym chcesz utworzyć nowy projekt, i utwórz aplikację konsolową przy użyciu interfejsu wiersza polecenia platformy .NET. Plik
Program.cspowinien zostać utworzony w katalogu projektu.dotnet new consoleZainstaluj zestaw SPEECH SDK w nowym projekcie przy użyciu interfejsu wiersza polecenia platformy .NET.
dotnet add package Microsoft.CognitiveServices.SpeechZastąp zawartość
Program.cspliku następującym kodem.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }W
Program.csustawieniucluProjectNamezmiennych icluDeploymentNamena nazwy projektu i wdrożenia. Aby uzyskać informacje o sposobie tworzenia projektu i wdrażania clu, zobacz Tworzenie projektu usługi Language Understanding konwersacji.Aby zmienić język rozpoznawania mowy, zastąp
en-USelement innym obsługiwanym językiem. Na przykłades-ESw przypadku języka hiszpańskiego (Hiszpania). Język domyślny toen-US, jeśli nie określisz języka. Aby uzyskać szczegółowe informacje na temat identyfikowania jednego z wielu języków, które mogą być mówione, zobacz identyfikacja języka.
Uruchom nową aplikację konsolową, aby rozpocząć rozpoznawanie mowy z mikrofonu:
dotnet run
Ważne
Upewnij się, że ustawiono LANGUAGE_KEYzmienne środowiskowe , LANGUAGE_ENDPOINT, SPEECH_KEYi SPEECH_REGION zgodnie z powyższym opisem. Jeśli te zmienne nie zostaną ustawione, przykład zakończy się niepowodzeniem z komunikatem o błędzie.
Po wyświetleniu monitu porozmawiaj z mikrofonem. To, co mówisz, powinno być danymi wyjściowymi jako tekst:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Uwaga
Obsługa odpowiedzi JSON dla clu za pośrednictwem właściwości LanguageUnderstandingServiceResponse_JsonResult została dodana w zestawie Speech SDK w wersji 1.26.
Intencje są zwracane w kolejności prawdopodobieństwa, która najprawdopodobniej będzie najmniej prawdopodobna. Oto sformatowana wersja danych wyjściowych JSON, w której topIntent znajduje HomeAutomation.TurnOn się wskaźnik ufności 0,97712576 (97,71%). Drugą najbardziej prawdopodobną intencją może być HomeAutomation.TurnOff współczynnik ufności 0,8985081 (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Uwagi
Teraz, po ukończeniu przewodnika Szybki start, poniżej przedstawiono kilka dodatkowych zagadnień:
- W tym przykładzie użyto
RecognizeOnceAsyncoperacji do transkrypcji wypowiedzi do 30 sekund lub do momentu wykrycia ciszy. Aby uzyskać informacje na temat ciągłego rozpoznawania dłuższego dźwięku, w tym konwersacji wielojęzycznych, zobacz Jak rozpoznawać mowę. - Aby rozpoznać mowę z pliku audio, użyj polecenia
FromWavFileInputzamiastFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - W przypadku skompresowanych plików audio, takich jak MP4, zainstaluj GStreamer i użyj polecenia
PullAudioInputStreamlubPushAudioInputStream. Aby uzyskać więcej informacji, zobacz Jak używać skompresowanego dźwięku wejściowego.
Czyszczenie zasobów
Aby usunąć utworzone zasoby języka i mowy, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
Dokumentacja referencyjna Package (NuGet) | Dodatkowe przykłady w witrynie GitHub |
W tym przewodniku Szybki start użyjesz usług rozpoznawania mowy i języka do rozpoznawania intencji z danych dźwiękowych przechwyconych z mikrofonu. W szczególności użyjesz usługi Rozpoznawanie mowy do rozpoznawania mowy i modelu usługi Conversational Language Understanding (CLU) w celu zidentyfikowania intencji.
Ważne
Usługa Conversational Language Understanding (CLU) jest dostępna dla języków C# i C++ z zestawem Speech SDK w wersji 1.25 lub nowszej.
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Utwórz zasób języka w witrynie Azure Portal.
- Pobierz klucz zasobu języka i punkt końcowy. Po wdrożeniu zasobu Language wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
- Utwórz zasób usługi Mowa w witrynie Azure Portal.
- Pobierz klucz zasobu usługi Mowa i region. Po wdrożeniu zasobu usługi Mowa wybierz pozycję Przejdź do zasobu , aby wyświetlić klucze i zarządzać nimi.
Konfigurowanie środowiska
Zestaw SPEECH SDK jest dostępny jako pakiet NuGet i implementuje platformę .NET Standard 2.0. Zestaw SPEECH SDK zostanie zainstalowany w dalszej części tego przewodnika, ale najpierw zapoznaj się z przewodnikiem instalacji zestawu SDK, aby uzyskać więcej wymagań.
Ustawianie zmiennych środowiskowych
W tym przykładzie wymagane są zmienne środowiskowe o nazwach LANGUAGE_KEY, , LANGUAGE_ENDPOINTSPEECH_KEYi SPEECH_REGION.
Aby uzyskać dostęp do zasobów usług Azure AI, aplikacja musi być uwierzytelniona. W tym artykule pokazano, jak używać zmiennych środowiskowych do przechowywania poświadczeń. Następnie możesz uzyskać dostęp do zmiennych środowiskowych z kodu w celu uwierzytelnienia aplikacji. W przypadku środowiska produkcyjnego użyj bezpieczniejszego sposobu przechowywania poświadczeń i uzyskiwania do nich dostępu.
Ważne
Zalecamy uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi dla zasobów platformy Azure, aby uniknąć przechowywania poświadczeń przy użyciu aplikacji uruchamianych w chmurze.
Jeśli używasz klucza interfejsu API, zapisz go bezpiecznie w innym miejscu, na przykład w usłudze Azure Key Vault. Nie dołączaj klucza interfejsu API bezpośrednio do kodu i nigdy nie publikuj go publicznie.
Aby uzyskać więcej informacji na temat zabezpieczeń usług sztucznej inteligencji, zobacz Uwierzytelnianie żądań w usługach Azure AI.
Aby ustawić zmienne środowiskowe, otwórz okno konsoli i postępuj zgodnie z instrukcjami dotyczącymi systemu operacyjnego i środowiska programistycznego.
- Aby ustawić zmienną
LANGUAGE_KEYśrodowiskową, zastąpyour-language-keyelement jednym z kluczy zasobu. - Aby ustawić zmienną
LANGUAGE_ENDPOINTśrodowiskową, zastąpyour-language-endpointelement jednym z regionów zasobu. - Aby ustawić zmienną
SPEECH_KEYśrodowiskową, zastąpyour-speech-keyelement jednym z kluczy zasobu. - Aby ustawić zmienną
SPEECH_REGIONśrodowiskową, zastąpyour-speech-regionelement jednym z regionów zasobu.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Uwaga
Jeśli musisz uzyskać dostęp tylko do zmiennej środowiskowej w bieżącej uruchomionej konsoli, możesz ustawić zmienną środowiskową z wartością set setxzamiast .
Po dodaniu zmiennych środowiskowych może być konieczne ponowne uruchomienie wszystkich uruchomionych programów, które będą musiały odczytać zmienną środowiskową, w tym okno konsoli. Jeśli na przykład używasz programu Visual Studio jako edytora, uruchom ponownie program Visual Studio przed uruchomieniem przykładu.
Tworzenie projektu usługi Conversational Language Understanding
Po utworzeniu zasobu Language utwórz projekt language understanding języka konwersacyjnego w programie Language Studio. Projekt to obszar roboczy umożliwiający tworzenie niestandardowych modeli uczenia maszynowego na podstawie danych. Dostęp do projektu można uzyskać tylko do Ciebie i innych osób, które mają dostęp do używanego zasobu Language.
Przejdź do programu Language Studio i zaloguj się przy użyciu konta platformy Azure.
Tworzenie projektu interpretacji języka konwersacji
Na potrzeby tego przewodnika Szybki start możesz pobrać ten przykładowy projekt automatyzacji domu i zaimportować go. Ten projekt może przewidywać zamierzone polecenia na podstawie danych wejściowych użytkownika, takich jak włączanie i wyłączanie świateł.
W sekcji Informacje o pytaniach i języku konwersacyjnym w programie Language Studio wybierz pozycję Omówienie języka konwersacji.
Spowoduje to wyświetlenie strony projektów interpretacji języka konwersacji. Obok przycisku Utwórz nowy projekt wybierz pozycję Importuj.
W wyświetlonym oknie przekaż plik JSON, który chcesz zaimportować. Upewnij się, że plik jest zgodny z obsługiwanym formatem JSON.
Po zakończeniu przekazywania zostanie wyświetlona strona Definicja schematu. W tym przewodniku Szybki start schemat został już skompilowany, a wypowiedzi są już oznaczone intencjami i jednostkami.
Szkolenie modelu
Zazwyczaj po utworzeniu projektu należy utworzyć wypowiedzi schematu i etykiet. Na potrzeby tego przewodnika Szybki start zaimportowaliśmy już gotowy projekt ze skompilowanym schematem i oznaczonymi etykietami wypowiedzi.
Aby wytrenować model, musisz rozpocząć zadanie szkoleniowe. Dane wyjściowe pomyślnego zadania szkoleniowego to wytrenowany model.
Aby rozpocząć trenowanie modelu z poziomu programu Language Studio:
Wybierz pozycję Train model (Trenowanie modelu ) z menu po lewej stronie.
Wybierz pozycję Start a training job (Rozpocznij zadanie szkoleniowe) z górnego menu.
Wybierz pozycję Train a new model (Trenowanie nowego modelu) i wprowadź nową nazwę modelu w polu tekstowym. W przeciwnym razie, aby zastąpić istniejący model modelem wytrenowanym na nowych danych, wybierz pozycję Zastąp istniejący model , a następnie wybierz istniejący model. Zastępowanie wytrenowanego modelu jest nieodwracalne, ale nie wpłynie to na wdrożone modele do momentu wdrożenia nowego modelu.
Wybierz tryb trenowania. Możesz wybrać standardowe szkolenie w celu szybszego szkolenia , ale jest dostępne tylko dla języka angielskiego. Możesz też wybrać opcję Zaawansowane szkolenie , które jest obsługiwane w przypadku innych języków i projektów wielojęzycznych, ale obejmuje dłuższe czasy trenowania. Dowiedz się więcej o trybach trenowania.
Wybierz metodę dzielenia danych. Możesz wybrać opcję Automatyczne dzielenie zestawu testów z danych treningowych, w których system podzieli wypowiedzi między zestawy treningowe i testowe, zgodnie z określonymi wartościami procentowymi. Możesz też użyć ręcznego podziału danych treningowych i testowych, ta opcja jest włączona tylko wtedy, gdy dodano wypowiedzi do zestawu testów po oznaczeniu wypowiedzi.
Wybierz przycisk Train (Trenuj).
Wybierz identyfikator zadania szkoleniowego z listy. Zostanie wyświetlony panel, w którym można sprawdzić postęp trenowania, stan zadania i inne szczegóły dotyczące tego zadania.
Uwaga
- Tylko pomyślnie ukończone zadania szkoleniowe będą generować modele.
- Trenowanie może potrwać od kilku minut do kilku godzin na podstawie liczby wypowiedzi.
- Jednocześnie może być uruchomione tylko jedno zadanie trenowania. Nie można uruchomić innych zadań szkoleniowych w tym samym projekcie, dopóki uruchomione zadanie nie zostanie ukończone.
- Uczenie maszynowe używane do trenowania modeli jest regularnie aktualizowane. Aby wytrenować poprzednią wersję konfiguracji, wybierz pozycję Wybierz tutaj, aby zmienić się na stronie Rozpocznij zadanie trenowania i wybierz poprzednią wersję.
Wdrażanie modelu
Zazwyczaj po trenowaniu modelu należy przejrzeć jego szczegóły oceny. W tym przewodniku Szybki start wdrożysz model i udostępnisz go do wypróbowania w programie Language Studio lub możesz wywołać interfejs API przewidywania.
Aby wdrożyć model z poziomu programu Language Studio:
Wybierz pozycję Deploying a model (Wdrażanie modelu ) z menu po lewej stronie.
Wybierz pozycję Dodaj wdrożenie , aby uruchomić Kreatora dodawania wdrożenia .
Wybierz pozycję Utwórz nową nazwę wdrożenia, aby utworzyć nowe wdrożenie i przypisać wytrenowany model z listy rozwijanej poniżej. W przeciwnym razie możesz wybrać pozycję Zastąp istniejącą nazwę wdrożenia, aby skutecznie zastąpić model używany przez istniejące wdrożenie.
Uwaga
Zastępowanie istniejącego wdrożenia nie wymaga zmian wywołania interfejsu API przewidywania, ale uzyskane wyniki będą oparte na nowo przypisanym modelu.
Wybierz wytrenowany model z listy rozwijanej Model .
Wybierz pozycję Wdróż , aby uruchomić zadanie wdrożenia.
Po pomyślnym wdrożeniu obok zostanie wyświetlona data wygaśnięcia. Wygaśnięcie wdrożenia jest wtedy, gdy wdrożony model będzie niedostępny do przewidywania, co zwykle występuje dwanaście miesięcy po wygaśnięciu konfiguracji trenowania.
W następnej sekcji użyjesz nazwy projektu i nazwy wdrożenia.
Rozpoznawanie intencji z mikrofonu
Wykonaj następujące kroki, aby utworzyć nową aplikację konsolową i zainstalować zestaw SPEECH SDK.
Utwórz nowy projekt konsoli języka C++ w programie Visual Studio Community 2022 o nazwie
SpeechRecognition.Zainstaluj zestaw SPEECH SDK w nowym projekcie za pomocą menedżera pakietów NuGet.
Install-Package Microsoft.CognitiveServices.SpeechZastąp zawartość
SpeechRecognition.cppnastępującym kodem:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }W
SpeechRecognition.cppustawieniucluProjectNamezmiennych icluDeploymentNamena nazwy projektu i wdrożenia. Aby uzyskać informacje o sposobie tworzenia projektu i wdrażania clu, zobacz Tworzenie projektu usługi Language Understanding konwersacji.Aby zmienić język rozpoznawania mowy, zastąp
en-USelement innym obsługiwanym językiem. Na przykłades-ESw przypadku języka hiszpańskiego (Hiszpania). Język domyślny toen-US, jeśli nie określisz języka. Aby uzyskać szczegółowe informacje na temat identyfikowania jednego z wielu języków, które mogą być mówione, zobacz identyfikacja języka.
Skompiluj i uruchom nową aplikację konsolową, aby rozpocząć rozpoznawanie mowy z mikrofonu.
Ważne
Upewnij się, że ustawiono LANGUAGE_KEYzmienne środowiskowe , LANGUAGE_ENDPOINT, SPEECH_KEYi SPEECH_REGION zgodnie z powyższym opisem. Jeśli te zmienne nie zostaną ustawione, przykład zakończy się niepowodzeniem z komunikatem o błędzie.
Po wyświetleniu monitu porozmawiaj z mikrofonem. To, co mówisz, powinno być danymi wyjściowymi jako tekst:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Uwaga
Obsługa odpowiedzi JSON dla clu za pośrednictwem właściwości LanguageUnderstandingServiceResponse_JsonResult została dodana w zestawie Speech SDK w wersji 1.26.
Intencje są zwracane w kolejności prawdopodobieństwa, która najprawdopodobniej będzie najmniej prawdopodobna. Oto sformatowana wersja danych wyjściowych JSON, w której topIntent znajduje HomeAutomation.TurnOn się wskaźnik ufności 0,97712576 (97,71%). Drugą najbardziej prawdopodobną intencją może być HomeAutomation.TurnOff współczynnik ufności 0,8985081 (84,31%).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Uwagi
Teraz, po ukończeniu przewodnika Szybki start, poniżej przedstawiono kilka dodatkowych zagadnień:
- W tym przykładzie użyto
RecognizeOnceAsyncoperacji do transkrypcji wypowiedzi do 30 sekund lub do momentu wykrycia ciszy. Aby uzyskać informacje na temat ciągłego rozpoznawania dłuższego dźwięku, w tym konwersacji wielojęzycznych, zobacz Jak rozpoznawać mowę. - Aby rozpoznać mowę z pliku audio, użyj polecenia
FromWavFileInputzamiastFromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - W przypadku skompresowanych plików audio, takich jak MP4, zainstaluj GStreamer i użyj polecenia
PullAudioInputStreamlubPushAudioInputStream. Aby uzyskać więcej informacji, zobacz Jak używać skompresowanego dźwięku wejściowego.
Czyszczenie zasobów
Aby usunąć utworzone zasoby języka i mowy, możesz użyć witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
| Dokumentacja referencyjna Dodatkowe przykłady w usłudze GitHub
Zestaw SPEECH SDK dla języka Java nie obsługuje rozpoznawania intencji za pomocą interpretacji języka konwersacyjnego (CLU). Wybierz inny język programowania lub odwołanie do języka Java i przykłady połączone na początku tego artykułu.